Einführung von Atlas Stream Processing – Vereinfachung der Reise zu reaktiven, reaktionsfähigen, ereignisgesteuerten Apps
Wir freuen uns, heute den Private Preview von Atlas Stream Processing ankündigen zu können!
Die Welt wird immer schneller und Ihre Anwendungen müssen mithalten. Reaktionsfähige, ereignisgesteuerte Anwendungen erwecken digitale Erlebnisse für Ihre Kunden zum Leben und verkürzen die Zeit, in der das Unternehmen Einblicke erhält und Maßnahmen ergreifen kann. Denken Sie mal darüber nach:
Benachrichtigung Ihrer Benutzer, sobald sich ihr Lieferstatus ändert,
Blockierung betrügerischer Transaktionen während der Zahlungsabwicklung,
Analyse der erzeugten Sensortelemetrie, um potenzielle Geräteausfälle zu erkennen und zu beheben, bevor es zu kostspieligen Ausfällen kommt.
In jedem dieser Beispiele verlieren die Daten im Laufe der Sekunden ihren Wert. Es muss kontinuierlich und mit geringer Latenz abgefragt und ausgeführt werden. Um dies zu erreichen, greifen Entwickler zunehmend auf ereignisgesteuerte Anwendungen zurück, die durch Streaming-Daten betrieben werden, damit sie sofort agieren und auf die sich ständig verändernde Welt um sie herum reagieren können. Atlas Stream Processing wird Entwicklern dabei helfen, schneller auf ereignisgesteuerte Apps umzusteigen.
Im Laufe der Jahre haben Entwickler die MongoDB Datenbank übernommen, weil sie die Flexibilität und Benutzerfreundlichkeit des Dokumentmodells sowie die
MongoDB Query API
lieben, die es ihnen ermöglicht, mit Daten als Code zu arbeiten. Diese Grundprinzipien verringern die Reibungsverluste bei der Entwicklung von Software und Anwendungen erheblich. Jetzt übertragen wir dieselben Prinzipien auf das Streaming von Daten. Atlas Stream Processing definiert die Entwicklererfahrung für die Arbeit mit komplexen Streams mit hoher Geschwindigkeit und sich schnell ändernden Daten neu und vereinheitlicht die Art und Weise, wie Entwickler mit Daten in Motion und at Rest arbeiten.
Während bestehende Produkte und Technologien viele Innovationen für Streaming und Stream-Verarbeitung mit sich gebracht haben, glauben wir, dass MongoDB natürlich gut geeignet ist, Entwicklern bei einigen wichtigen verbleibenden Herausforderungen zu helfen. Zu diesen Herausforderungen gehört die Schwierigkeit, mit variablen, großen Datenmengen und schnell getakteten Daten zu arbeiten; der Overhead beim Erlernen neuer Tools, Sprachen und APIs; und die zusätzliche betriebliche Wartung und Fragmentierung, die durch Punkttechnologien in komplexe Stack eingeführt werden können.
Einführung in die Atlas Stream Processing
Atlas Stream Processing ermöglicht die Verarbeitung von High Velocity Streams komplexer Daten mit einigen einzigartigen Vorteilen für das Entwicklererlebnis:
Es basiert auf dem Dokumentmodell und ermöglicht Flexibilität beim Umgang mit den verschachtelten und komplexen Datenstrukturen, die im Event Streaming üblich sind. Dies verringert die Notwendigkeit von Vorverarbeitungsschritten und ermöglicht Entwicklern gleichzeitig, natürlich und einfach mit Daten zu arbeiten, die komplexe Strukturen aufweisen. So wie es die Datenbank zulässt.
Es vereint die Erfahrung der Arbeit mit allen Daten und bietet eine einzige Plattform – für alle APIs, Abfragesprachen und Tools –, um umfangreiche, komplexe Streaming-Daten neben den kritischen Anwendungsdaten in Ihrer Datenbank zu verarbeiten.
Und es wird vollständig in
MongoDB Atlas
verwaltet und basiert auf einer bereits soliden Auswahl an integrierten Diensten. Mit nur wenigen API-Aufrufen und Codezeilen können Sie einen Stream-Prozessor, eine Datenbank und eine API-Deployment-Schicht bei jedem der großen Cloud-Anbieter einrichten.
Wie funktioniert Atlas Stream Processing?
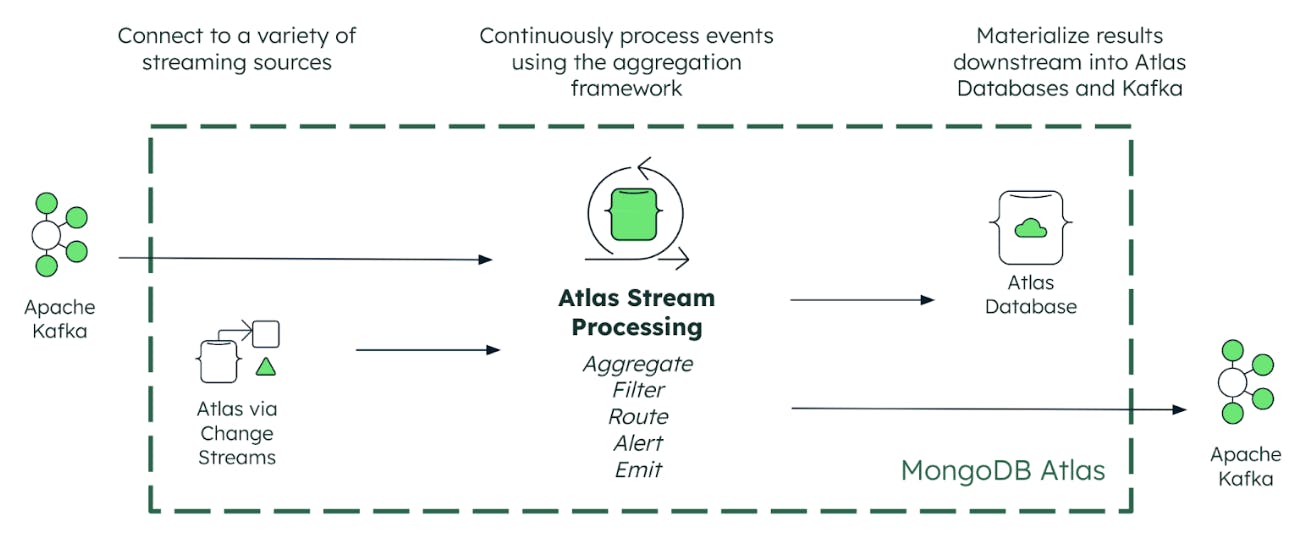
Atlas Stream Processing stellt eine Verbindung zu Ihren kritischen Daten her, unabhängig davon, ob diese in MongoDB (über
change streams
) oder in einer Event-Streaming-Plattform wie Apache Kafka gespeichert sind. Entwickler können mithilfe des Kafka-Wire-Protokolls einfach und nahtlos eine Verbindung zu Confluent Cloud, Amazon MSK, Redpanda, Azure Event Hubs oder Managed Kafka herstellen. Und durch die Integration mit dem nativen Kafka-Treiber bietet Atlas Stream Processing als Grundlage eine native Leistung mit geringer Latenz.
Zusätzlich zu unserer langjährigen strategischen Partnerschaft mit Confluent freuen wir uns, zum Start auch Partnerschaften mit AWS, Microsoft, Redpanda und Google bekannt zu geben.
Atlas Stream Processing bietet dann drei Schlüsselfunktionen, die erforderlich sind, um aus Ihrer Fülle an Streaming-Daten eine differenzierte Kundenerfahrung zu machen. Lassen Sie uns diese einzeln durchgehen.
Kontinuierliche Verarbeitung
Erstens können Entwickler jetzt das Aggregation Framework Framework von MongoDB verwenden, um umfangreiche und komplexe Datenströme von Event-Streaming-Plattformen wie Apache Kafka kontinuierlich zu verarbeiten. Dadurch werden leistungsstarke neue Möglichkeiten eröffnet, Streaming-Daten kontinuierlich abzufragen, zu analysieren und darauf zu reagieren , ohne dass es zu Verzögerungen kommt, die mit Batch Processing einhergehen. Mit dem Aggregation Framework können Sie Daten filtern und gruppieren, High Velocity Event Streams über Stateful-Time- Windows zu umsetzbaren Erkenntnissen aggregieren und so umfassendere Echtzeit-Anwendungserlebnisse ermöglichen.
Kontinuierliche Validierung
Zunächst bietet Atlas Stream Processing Entwicklern robuste und native Mechanismen zur Bewältigung Probleme mit falschen Daten, die andernfalls zu Schäden in Anwendungen führen könnten. Zu den potenziellen Problemen gehören die Weitergabe ungenauer Ergebnisse an die App, Datenverlust und Ausfallzeiten der Anwendung. Atlas Stream Processing löst diese Probleme, um sicherzustellen, dass Streaming-Daten zuverlässig verarbeitet und zwischen ereignisgesteuerten Anwendungen geteilt werden können.
Atlas Stream Processing:
Bietet eine kontinuierliche Schemavalidierung, um vor der Verarbeitung zu überprüfen, ob Ereignisse ordnungsgemäß gebildet werden – beispielsweise das Ablehnen von Ereignissen mit fehlenden Feldern oder ungültigen Wertebereichen
Erkennen von Nachrichtenbeschädigungen
Erkennt verspätet eintreffende Daten, die ein Verarbeitungsfenster verpasst haben.
Atlas Stream Processing Pipelines können mit einer integrierten Dead Letter Queue (DLQ) konfiguriert werden, in die Ereignisse, die die Validierung nicht bestehen, weitergeleitet werden. Dadurch wird vermieden, dass Entwickler ihre eigenen benutzerdefinierten Implementierungen erstellen und verwalten müssen. Probleme können schnell behoben werden, während das Risiko fehlender oder beschädigter Daten, die zum Ausfall der gesamten Anwendung führen, minimiert wird.
Kontinuierlicher Merge
Ihre verarbeiteten Daten können dann kontinuierlich in Ansichten materialisiert werden, die in der Atlas Collection verwaltet werden. Wir können uns das als Push-Abfrage vorstellen. Anwendungen können Ergebnisse (über Pull-Abfragen) aus der Ansicht abrufen, indem sie entweder die MongoDB Query API oder die Atlas SQL-Schnittstelle verwenden. Das kontinuierliche Zusammenführen von Aktualisierungen der Collection ist eine wirklich effiziente Möglichkeit, neue analytische Ansichten der Daten zu erhalten und so automatisierte und menschliche Entscheidungen und Maßnahmen zu unterstützen. Neben materialisierten Ansichten haben Entwickler auch die Flexibilität, verarbeitete Ereignisse wieder in Streaming-Systemen wie Apache Kafka zu veröffentlichen.
Erstellen eines Stream-Prozessors
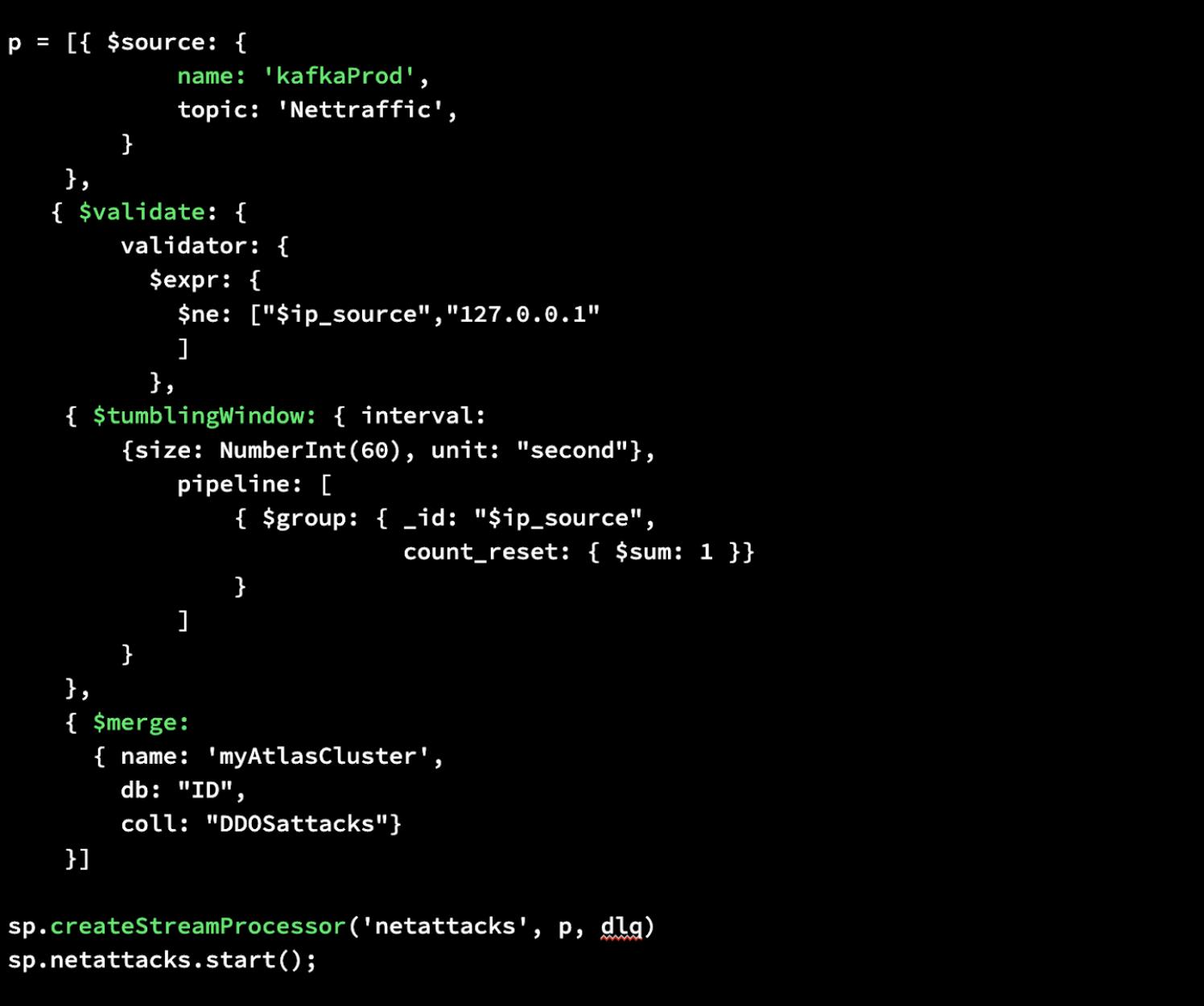
Wir zeigen Ihnen, wie einfach es ist, einen Stream-Prozessor in MongoDB Atlas zu erstellen. Mit Atlas Stream Processing können Sie für einen Stream-Prozessor dieselbe Aggregation Pipeline Syntax verwenden, die Sie aus der Datenbank kennen. Im Folgenden stellen wir eine einfache Stream Processing Instanz von Anfang bis Ende vor. Es sind nur wenige Codezeilen erforderlich.
Zuerst schreiben wir eine Aggregation Pipeline , die eine Quelle für Ihre Daten definiert, eine Validierung durchführt, um sicherzustellen, dass die Daten nicht von der IP-Adresse localhost/127.0.0.1 stammen, ein rollierendes Fenster erstellt, um jede Minute gruppierte Nachrichtendaten zu sammeln, und diese dann zusammenführt neu verarbeitete Daten in eine MongoDB Collection in Atlas.
Dann erstellen wir unseren Stream-Prozessor namens „netattacks“ und geben dabei unsere neu definierte Pipeline p sowie dlq als Argumente an. Dadurch wird unsere gewünschte Verarbeitung durchgeführt und mithilfe einer Dead Letter Queue (DLQ) werden alle ungültigen Daten sicher zur späteren Überprüfung, Fehlerbehebung oder erneuten Verarbeitung gespeichert.
Zuletzt können wir das Ganze starten. Das ist alles, was Sie brauchen, um einen Stream-Prozessor in MongoDB Atlas zu erstellen.
Fordern Sie den Private Preview an
Wir freuen uns, dieses Produkt in Ihre Hände zu bekommen und zu sehen, was Sie damit entwickeln. Erfahren Sie mehr über Atlas Stream Processing und fordern Sie hier frühzeitig Zugang an, um am Private Preview teilzunehmen, sobald er für Entwickler geöffnet ist.
Neu bei MongoDB? Beginnen Sie noch heute kostenlos, indem Sie sich für
MongoDB Atlas
anmelden.
Absicherungserklärung
Entwicklung, Freigabe und zeitliche Planung der beschriebenen Funktionen oder Features für unsere Produkte liegen in unserem alleinigen Ermessen. Diese Informationen dienen lediglich dazu, unsere allgemeine Produktrichtung zu umreißen, und sollten nicht als Grundlage für eine Kaufentscheidung herangezogen werden. Dies ist auch keine Selbstverpflichtung, Zusage oder rechtliche Verpflichtung zur Lieferung von Material, Code oder Funktionalität irgendwelcher Art.
September 14, 2023