Connecting Python and MongoDB Atlas
PyMongo has a set of packages for Python MongoDB interaction. For the following tutorial, start by creating a virtual environment, and activate it.
Now that you are in your virtual environment, you can install PyMongo. In your terminal, type:
Now, we can use PyMongo as a Python MongoDB library in our code with an import statement.
Creating a MongoDB database in Python
The first step to connect Python to Atlas is to create a cluster. You can follow the instructions from the documentation to learn how to create and set up your cluster.
Next, create a file named pymongo_get_database.py in any folder to write PyMongo code. You can use any simple text editor, like Visual Studio Code.
Create the mongodb client by adding the following:
To create a MongoClient, you will need a connection string to your database. If you are using Atlas, you can follow the steps from the documentation to get that connection string. Use the connection_string to create the mongoclient and get the MongoDB database connection. Change the username, password, and cluster name.
In this python mongodb tutorial, we will create a shopping list and add a few items. For this, we created a database user_shopping_list.
MongoDB doesn’t create a database until you have collections and documents in it. So, let’s create a collection next.
Creating a collection in Python
To create a collection, pass the collection name to the database. In a new file called pymongo_test_insert.py file, add the following code.
This creates a collection named user_1_items in the user_shopping_list database.
Inserting documents in Python
For inserting many documents at once, use the pymongo insert_many() method.
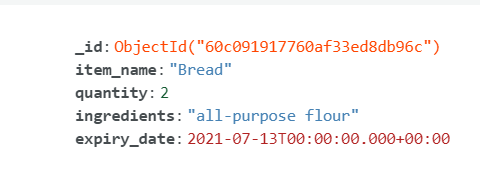
Let’s insert a third document without specifying the _id field. This time, we add a field of data type ‘date’. To add date using PyMongo, use the Python dateutil package.
Start by installing the package using the following command:
Add the following to pymongo_test_insert.py:
We use the insert_one() method to insert a single document.
Open the command line and navigate to the folder where you have saved pymongo_test_insert.py.
Execute the file using the command:
Let’s connect to MongoDB Atlas UI and check what we have so far.
Log in to your Atlas cluster and click on the collections button.
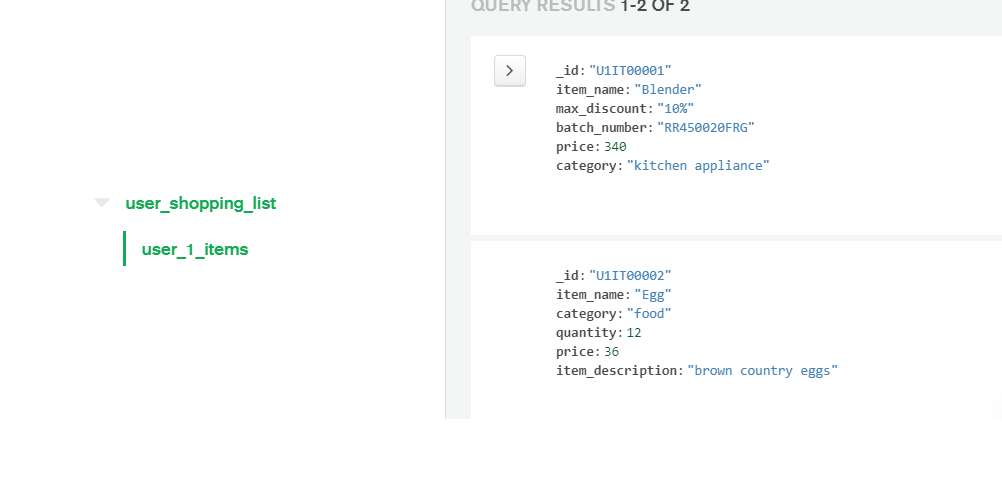
On the left side, you can see the database and collection name that we created. If you click on the collection name, you can view the data as well:
The _id field is of ObjectId type by default. If we don't specify the _id field, MongoDB automatically generates one. Documents within a collection can have different fields, allowing for a flexible schema. MongoDB's dynamic schema design enables you to add or modify fields without requiring all documents to have the same structure.
If we insert item_3 again, MongoDB will insert a new document, with a new _id value. However, the first two inserts will throw an error because of the _id field, the unique identifier.
Querying in Python
Let’s view all the documents together using find(). For that, we will create a separate file pymongo_test_query.py:
Open the command line and navigate to the folder where you have saved pymongo_test_query.py. Execute the file using the command:
We get the list of dictionary object as the output:
We can view the data but the format is not all that great. So, let’s print the item names and their category by replacing the print line with the following:
Although MongoDB gets the entire data, we get a Python ‘KeyError’ on the third document.
To handle missing data errors in python, use pandas.DataFrames. DataFrames are 2D data structures used for data processing tasks. Pymongo find() method returns dictionary objects which can be converted into a dataframe in a single line of code.
Install pandas library as:
Now import the pandas library by adding the following line at the top of the file:
And replace the code in the loop with the following to handle KeyError in one step:
The errors are replaced by NaN and NaT for the missing values.
Indexing in Python MongoDB
The number of documents and collections in a real-world database always keeps increasing. It can take a very long time to search for specific documents — for example, documents that have “all-purpose flour” among their ingredients — in a very large collection. Indexes make database search faster and more efficient, and reduce the cost of querying on operations such as sort, count, and match.
MongoDB defines indexes at the collection level.
For the index to make more sense, add more documents to our collection. Insert many documents at once using the insert_many() method. For sample documents, copy the code from github and execute python pymongo_test_insert_more_items.py in your terminal.
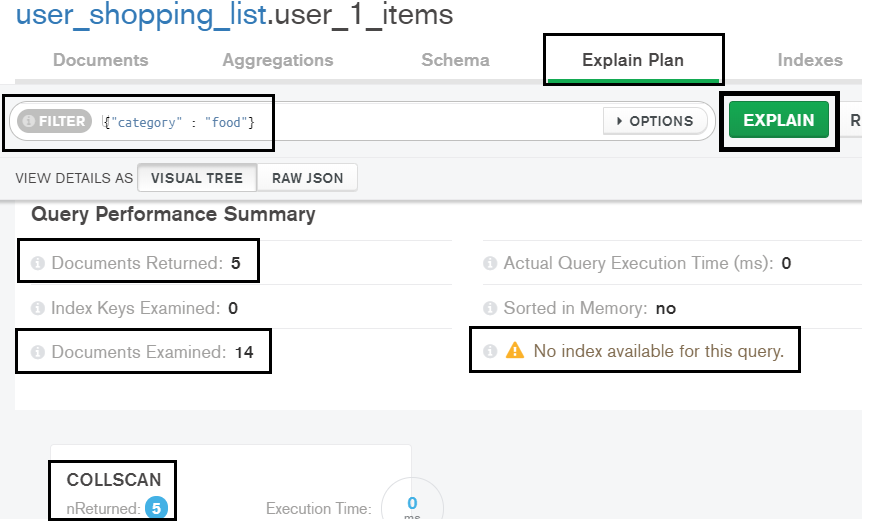
Let’s say we want the items that belong to the category ‘food’:
To execute the above query, MongoDB has to scan all the documents. To verify this, download Compass. Connect to your cluster using the connection string. Open the collection and go to the Explain Plan tab. In ‘filter’, give the above criteria and view the results:
Note that the query scans 14 documents to get five results.
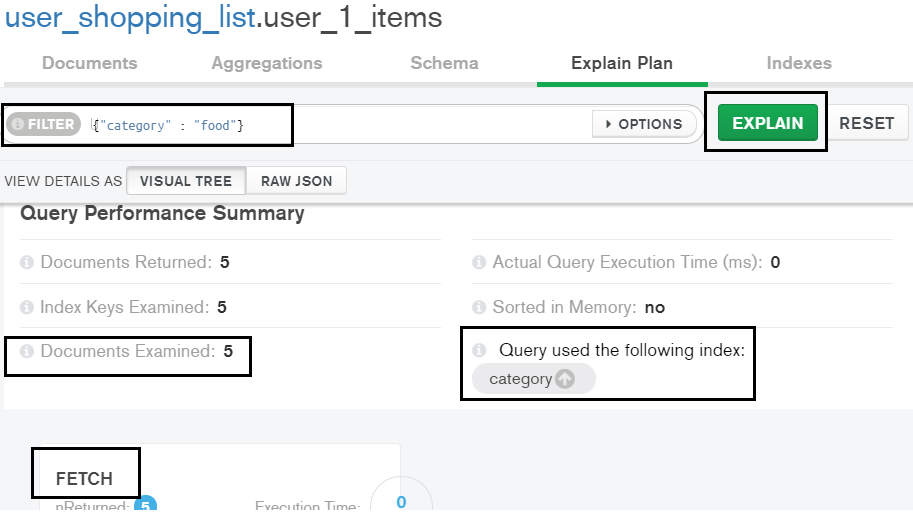
Let's create a single index on the ‘category’ field. In a new file named pymongo_index.py, add the following code.
Explain the same filter again on Compass UI:
This time, only five documents are scanned because of the category index. We don’t see a significant difference in execution time because of the small number of documents. But we see a huge reduction in the number of documents scanned for the query. Indexes help in performance optimization for aggregations, as well. Aggregations are out of scope for this tutorial, but here’s an overview.
Conclusion
In this Python MongoDB tutorial, we learned the basics of PyMongo and performed simple database operations. As a next step, explore using PyMongo to perform CRUD operations with business data. If you did not work along with this tutorial, start now by installing MongoDB Atlas for free. There is also a course available on that specific topic at MongoDB University.