MongoDB Atlas Vector search empowers developers to build powerful semantic search engines. Semantic search revolutionizes content discovery by understanding the true meaning of a query, rather than just matching keywords. This AI technology enhances user engagement by intelligently matching search intent with relevant content, transforming how users explore and interact with information.
Table of contents
- What is semantic search?
- How does semantic search work?
- What is an embedding model?
- Common text search techniques
- Semantic search vs. text search
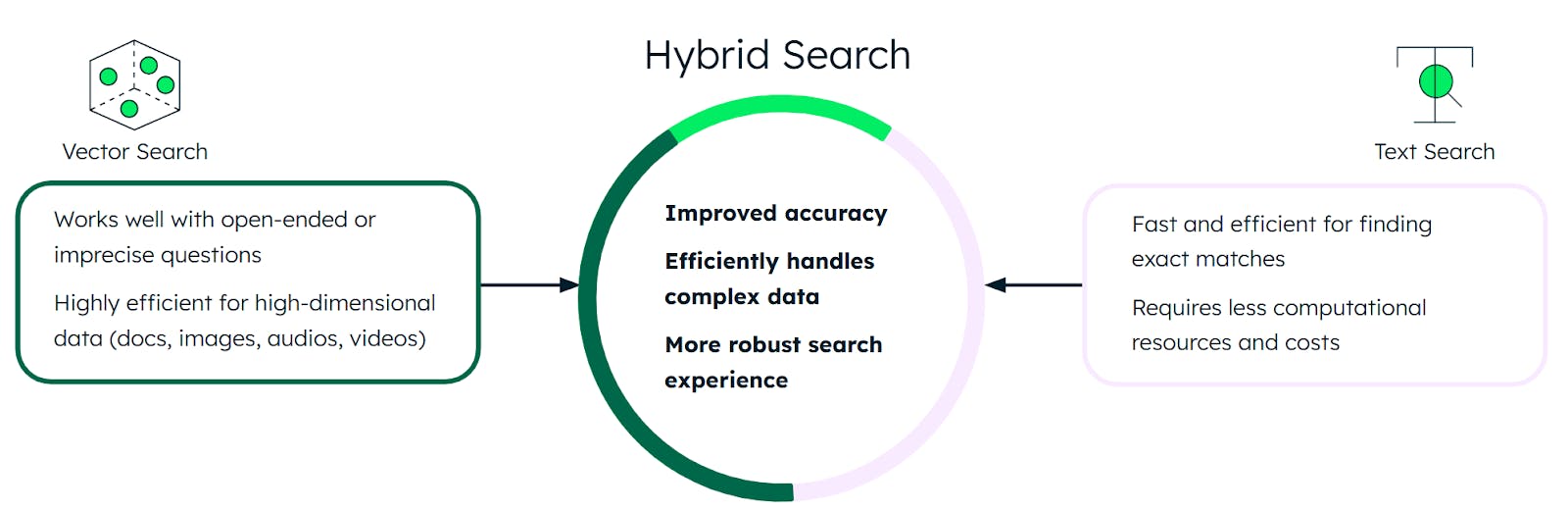
- Hybrid search
- Real-world use cases and examples where semantic search is making a difference
- Semantic search for retrieval-augmented generation
- Multimodal semantic search
- Improve your search with MongoDB Atlas Vector Search and Voyage AI
What is semantic search?
Semantic search is an advanced search methodology that uses the context and intent of user queries to retrieve relevant content. Traditional search techniques compare the keywords in a search query with the keywords that appear in the searchable content. By contrast, semantic search compares the underlying semantic meaning of the query and content to deliver more intelligent results. This ensures a more natural and effective search experience for users.
How does semantic search work?
Semantic search is a two-phase process of data indexing and retrieval, transforming raw content into meaningful, searchable numeric vectors.
Data indexing: Unstructured data is converted into vectors by an embedding model. The vectors are stored in a vector-capable database like MongoDB Atlas, creating a searchable index of content.
Retrieval: A search query is converted into a vector by the same embedding model. The system performs a nearest neighbor search (k-NN) to find the stored content vectors that are most semantically similar to the query vector, returning the most relevant results to the user.
What is an embedding model?
An embedding model is a natural language processing (NLP) model that uses machine learning (ML) to convert content into numerical vectors representing the meaning and characteristics of that content. Closely related content will produce similar vectors. For example, a text embedding model recognizes that “eco-friendly” and “sustainable” convey similar meanings and generates closely aligned vectors to represent them.
Embedding models are trained on massive datasets, allowing them to understand complex patterns and relationships in language and content. While many embedding models focus on text, specialized models can also process other input types, including images, audio, and video, making them versatile tools for representing different forms of data.
Domain-specific embedding models can be trained on specialized datasets to better understand industry language and concepts. For example, a medical embedding model would understand clinical terminology, medical procedures, and pharmaceuticals. These domain models can understand nuanced relationships that general-purpose models may miss and will often outperform generic models when applied to relevant use cases.
Common text search techniques
Common text search techniques can be combined to improve search performance and handle variations in queries. However, while using these methods together can create a performant search engine, it still falls short of AI-driven techniques like semantic search.
Keyword search
Sometimes called “lexical search,” this technique looks for exact word matches between search queries and content. The top results for “New York City” will be documents with the highest number of total mentions of “New,” “York,” or “City.”
N-gram analysis
N-gram analysis is a technique that also considers sequences of words in the search text. In addition to searching for individual words, the search results will consider combinations of words as well. The top results for “New York City” will provide additional weight to documents that contain “New York,” “York City,” and even more weight to the full text “New York City.”
Term frequency/Iinverse document frequency (TF/IDF)
Term frequency/inverse document frequency (TF/IDF) is a statistical method that provides additional weight to terms (or sequences of terms) that appear less frequently in the searchable content. The results for “The best restaurants in New York City” would focus more on “restaurants” if the document set is all about New York City tourism. Conversely, if the document set is centered around the top restaurants in the United States, then “New York City” would be heavily weighted in the results. Common words like “the” would receive very low weight because they appear frequently in every document.
Knowledge graph
Knowledge graph is a method that maps relationships between entities to provide contextual search results. Unlike traditional text search techniques that focus on word matches, knowledge graphs create a network of interconnected information. These graphs can be complex and challenging to build and maintain, requiring significant computational resources and expert knowledge to develop, update, and use effectively.
Stop words
Common words like "the," "and," "in," and "of" that do not provide relevance to the results are filtered out entirely.
Stemming
Stemming is a process that reduces words to their root form. For example, "running," "runs," and "ran" would all match documents containing any form of "run.
Normalization
Normalization is aA preprocessing step that standardizes text to improve search consistency. Normalization would convert “NYC” into “New York City” to ensure that it is understood correctly.
Fuzzy matching
Fuzzy matching is a method for finding approximate matches to account for misspellings or variations. A search for "New Yrok" would score highly with "New York," while a search for “colour” would recognize “color.”
Semantic search vs. text search
Text search can use various techniques to improve retrieval results, but it ultimately relies on finding content that contains exact matches or slight variations of the search terms. While advanced techniques like TF/IDF can create a more sophisticated search engine, these systems still do not understand meaning.
Semantic search seeks to understand the meaning of the content rather than matching words. It understands that “New York” and “New York City” are highly related but also that they are distinct entities from one another. Additionally, terms like “NYC,” “Manhattan,” or “The Big Apple” are inherently understood as a result of the contextual understanding that it learns from massive training datasets. This nuanced approach delivers more relevant results that better match user intent.
Let’s explore additional scenarios that compare text search to semantic search.
| Text Search | Semantic Search | |
|---|---|---|
| Word Variations | Must explicitly handle "color" vs. "colour" and other variations | Understands that “color” and “colour” are identical concepts |
| Synonyms and Related Terms | Requires a predefined list to know that “NYC” is the same as “New York City | Understands related terms from its training data |
| Conceptual Relationships | Will not understand that “Brooklyn” is a borough in “New York City” | Understands geographical and conceptual relationships |
| Contextual Understanding | "New York minute" and "New York pizza" are treated as similar because they share words | Understands one is an expression about speed while the other is about food |
| Intent Matching | "Where to stay in NYC" only matches content with those exact terms | Finds content about hotels, accommodations, rentals, Airbnb, etc. in New York City |