Evergreen Continuous Integration: Why We Reinvented The Wheel
July 27, 2016 | Updated: June 23, 2025
We’ve all been there: you’re pitching a solution when one of your team members interjects, “let’s not reinvent the wheel, here.” Whether it’s based on fear or wisdom, the charge of reinventing the wheel is a death sentence for ideas. It typically isn’t worth the time and resources to implement a new version of an old, ubiquitous idea—though you’d never know that with all the different kinds of actual, literal wheels you use every day.
For most developers, continuous integration (CI)—the automated building and testing of new code pushed into your repository—is one of those never-reinvented wheels. You set up one of a few long-standing solutions like Travis or Jenkins, rejigger your test code to fit into that solution’s organizational model, and then avoid messing with it too much. Here at MongoDB, challenging this approach rewarded us incredibly.
Instead of working around an off-the-shelf solution that didn’t fit our needs, we wound up reinventing the wheel and built our own continuous integration system called Evergreen. It gives us a powerful, efficient infrastructure that lets us test changes quickly -- and keeps our engineers happy as well. Our journey to creating Evergreen was born of necessity and stalked by uncertainty, but we don’t regret it. Reinventing the wheel allowed us to build a near-perfect CI tool for our use case, seriously evaluate powerful new technologies, and have a lot of fun doing it.
So how did we get here?
Like most tech companies, we make continuous integration a cornerstone of our development practices. Also like most tech companies, continuous integration has been a big headache for us -- in truth more of a throbbing migraine. Most CI users only need to test code on a single operating system, a single machine architecture, a single stack. At MongoDB, we need to ensure the codebase runs on many different operating system and architecture combinations (right now, we test on over 50 configurations). A rarer and tougher problem is: We have close to 20 hours of tests to run on each platform if we truly want to validate the correctness of a build. In my experience at other companies, even two hours to test a change would be an eternity. Today, in spite of those constraints, we are able to quickly get thorough feedback on the state of our codebase. We iterate aggressively and release with confidence.
It wasn’t always like this. In the early days of MongoDB, we relied on BuildBot as our CI system of choice. BuildBot was effective when our team consisted of a half dozen engineers and it allowed us to monitor the correctness of builds on multiple platforms at once. But as we hired more people, the flow of commits and new tests increased -- and the system started to buckle. BuildBot works by running tasks for a commit on a set group of buildslaves. If multiple commits come in while tests for a previous commit are running, the changes are queued up, and the next run could be testing multiple commits. That means whenever a test fails, you won’t necessarily know which commit caused it.
Knowing the source of a failure is just as important as knowing what’s failing. We had some success reining this in by moving tests into extended nightly and weekly suites. While that allowed for quicker turnaround on single commits, it introduced the brand new problem of not knowing your commit from Monday broke an obscure replication test until Saturday afternoon. Our engineers were spending too much time debugging both our server code and our buildbot configuration. Releases became a weeks-long process of committing a few minor bug fixes, then sitting on our hands for an entire afternoon, sweating, and waiting for tests to validate them. We needed a new approach.
The CI tool of our dreams
So we went looking for one. Our dream CI system was a tool that would unbind us from the restrictions that were suffocating our developers. First, because MongoDB runs in so many places, it would have to support a wide range of architectures and operating systems. Second, we were sick of long build queues as commits piled up, so a new system would need the ability to allocate elastic machines to cope with demand.
Tools like Jenkins do a lot of things well, but with Evergreen we can do a few things spectacularly.
Many tools offered some of these features to varying degrees, but none offered all of them. The solutions that offered us the most platform flexibility were closed-source or too slow; the most elastic solutions had limited platform support. The best options available would have required us to glue multiple, possibly incompatible plugins for a CI platform together. But the reality of implementing such a system is trickier than it appears. While plugins for, say, Jenkins, would have allowed us to define the complicated dependency structures of our tests, enable pre-commit testing, and allow for parallelization on EC2 machines, those plugins often don’t always play well with each other.
Such a solution would undoubtedly still require multiple full time engineers. To quote our CTO, Eliot Horowitz: “We tried a whole bunch of options: Buildbot, Jenkins, Bamboo, and none could do what we needed. The combination of many platforms and configurations, plus parallelization, plus EC2, plus static hosts, plus patch builds was something we couldn't find anywhere. We tried very hard to get something off the shelf.”
No matter what we chose, to get things working effectively would require an incredible amount of effort and new code. But we realized that building an in-house CI tool to test just MongoDB itself was a feasible undertaking for a small team of engineers – maybe even the same small team of engineers that would have been maintaining our frankenstein off-the-shelf solution. Given that reality, we opted to spend our time and resources on a built-from-the-ground-up CI tool of our own -- Evergreen. (We’ve subsequently extended what we use Evergreen for. It not only tests MongoDB, but also several of the drivers, our Compass product, and even Evergreen itself).
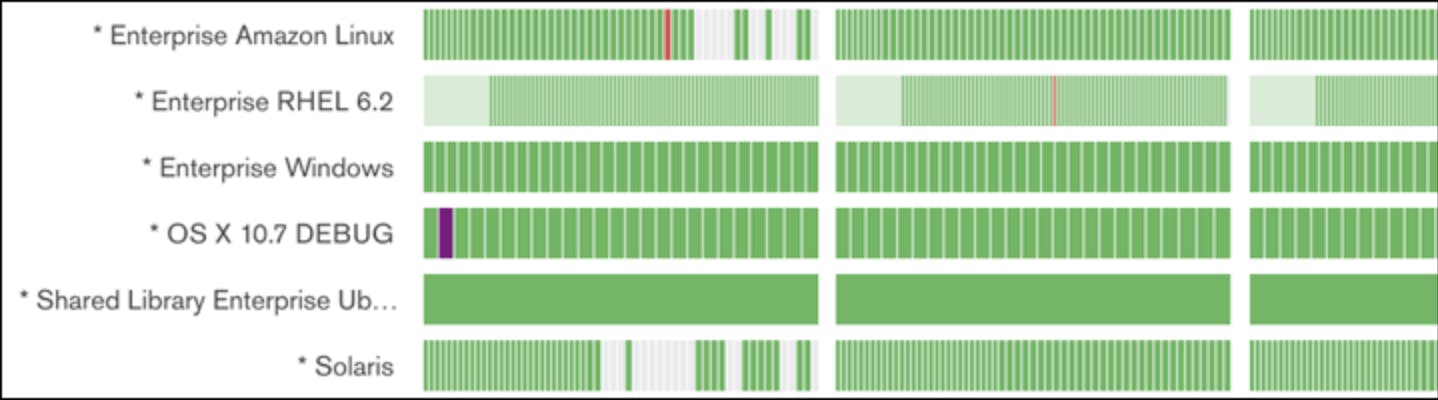
Evergreen is designed with dynamic parallelization in mind: We can automatically spin up hosts when demand is high and decommission them when that demand goes away, giving us access to virtually limitless parallelization for our builds. Our homebrew CI tool enables us to easily submit changesets for testing on any subset of configurations before we commit, getting hours of test feedback in minutes – all without interrupting our regular testing of committed code. And gone are the days of figuring out which commits on BuildBot’s blamelist actually broke the build: if Evergreen has skipped ahead over several commits, and then a test fails, Evergreen searches backwards testing previous commits in order to pinpoint exactly which one is at fault. No more guessing; no more local git bisect.
With parallelization, we finish all of our tests for a single configuration in a time frame our engineers can work with. For example, one of our Red Hat Enterprise 6.2 configurations takes over 17 hours to run in serial, but Evergreen can do that work in under three.
Evergreen’s scheduling model spins up hosts to finish tasks within a defined timeframe. When running multiple tasks during the lifespan of a host, our algorithms takes a task’s priority and dependencies into account so we can have complicated dependency pipelines and efficient parallelization. There’s no guarantee we’d be able to do something like this by joining systems between plugins developed by independent users in the Jenkins community. Tools like Jenkins do a lot of things well, but with Evergreen we can do a few things spectacularly. When building your own system, you don’t have to make compromises for the features you need most.
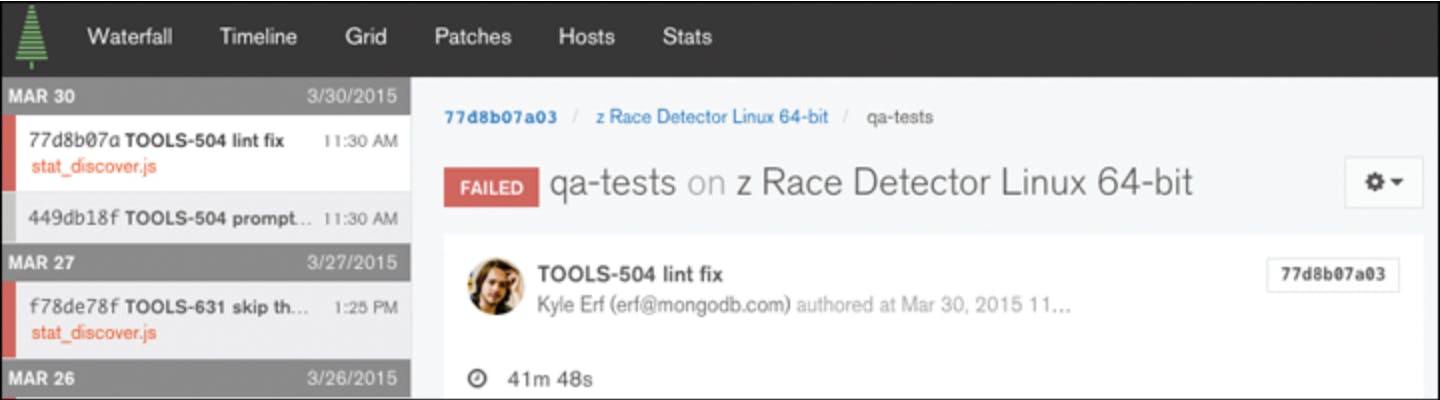
Evergreen has been a runaway success as a CI solution. On a typical work day, our systems leverage hundreds of elastic machines to run thousands of hours of tests, amounting to well over 2 million discrete test results. We’re running several days worth of tests against a commit in a couple hours, which means our engineers can get feedback on their code and iterate like never before. We have an omniscient perspective on the state of our codebase.
The path to Go
But beyond its utility for building and testing code, Evergreen gave our company an opportunity to evaluate Go. We’d been aware of Go from the beginning, enticed by its static compilation, multi-platform support, and concurrency primitives. In 2013, when Eliot was building the simple proof-of-concept that eventually became Evergreen, it was as much of an experiment in Go as it was an experiment in dynamic testing infrastructure.
Our entry into the world of CI tools had a less technical benefit: It’s been a hell of a lot of fun.
We knew Go could support the many platforms MongoDB runs on. We were confident that its concurrency primitives would help us develop a distributed architecture with speed and simplicity. It was time to put our testing where our mouth was. A custom CI tool was a small enough project that a team could get something working within a couple months, but large enough that it would provide a broad, realistic trial of Go as language.
One of Go’s killer features is static compilation. It allows us to compile all of our agent code and libraries into a single binary, so we can run dependency-free agent programs on all of our test hosts. Anyone who has had to manage Python library dependencies or Java VMs on build machines knows how convenient that is.
The symbiosis of static compilation and cross-platform support has worked out better than we could have hoped. For example, as we add support to MongoDB for more exotic architectures like PowerPC and zSeries chips, getting Evergreen agents running on those new machines has been the easiest part of the process. Leveraging both Go’s broad support for cross-compilation and the virtually universal GCCGO compiler, our agents just work.
Go proved itself so useful in building Evergreen that we went on to rewrite our Cloud agents and the MongoDB tools (mongodump, mongoimport, etc.) using it. Our adoption of Go was like a hidden shortcut in the kart race of software development; we would’ve passed it right by if we hadn’t given ourselves permission to reinvent the wheel. Today, Go is one of the first tools engineers at MongoDB reach for when we’re solving a new problem.
Lastly, it’s worth mentioning our entry into the world of CI tools had a less technical benefit: It’s been a hell of a lot of fun. While this may seem trivial, I promise it isn’t. When engineers have something fun and interesting to work on, they’re happier, write better code, and work faster. Working on Evergreen is a blast. It combines the thrills of getting a distributed system up and running, making things faster, and genuinely helping our colleagues with the stuff they’re working on.
What’s more is this undertaking didn’t even require much investment. Evergreen has been the product of a small group (no more than 3 or 4 people at a time) over the past three years, with many of those engineers working on other projects concurrently. But we’ve gained incredible value as a company and llearned something important: When approaching new problems, do not be afraid to consider starting from scratch. You might get way more out of it than just that final product.
If you want to see it in action, our builds are publicly available at evergreen.mongodb.com. Last year, we released Evergreen as open source software with the goal of collaborating with teams in similar circumstances to ours. Join us as we continue to make Evergreen more powerful, more generalized, and, in the near future, a strong competitor for tools like Jenkins and Travis.