MongoDB.local San Francisco 2026: Ship Production AI, Faster
Today at MongoDB.local San Francisco, we announced capabilities that collapse the distance between AI prototype and production.
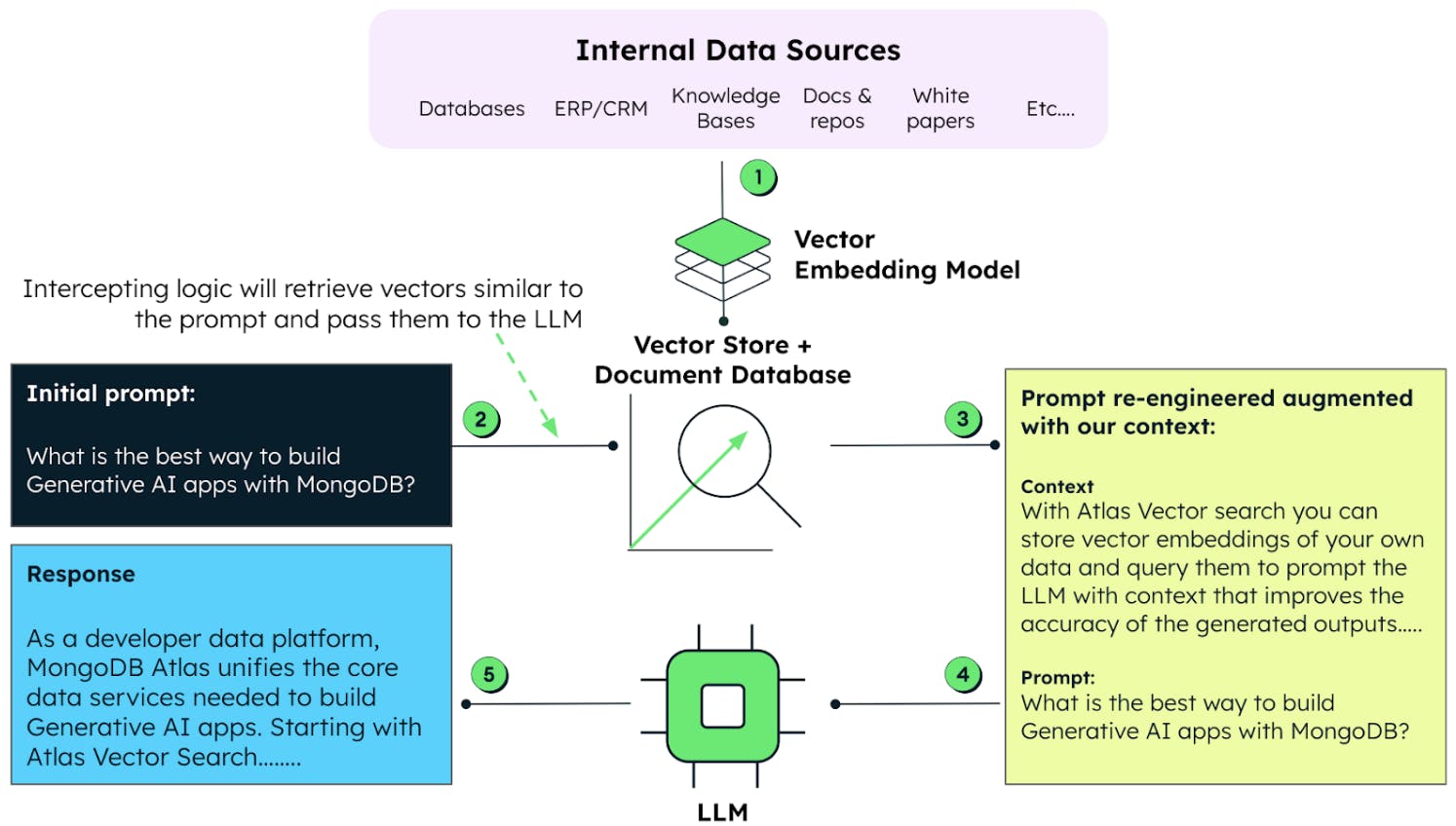
Building AI applications means solving real problems: keeping conversational context clean and queryable, retrieving the right information from thousands of past interactions, connecting AI agents to your data without custom plumbing. These aren't theoretical challenges, they're the friction points that slow teams down every day.
The AI era demands more from your data platform. MongoDB gives you everything you need to build quickly.
Voyage AI: the best gets better
Embedding models can make or break AI search experiences. We're proud that voyage-3-large has been the world's top-performing embedding model on Hugging Face's RTEB benchmark since its inception.
But we didn’t rest on our laurels. There’s a new model at the top of the charts.
Today, we're pleased to announce that the Voyage 4 model family is now generally available. The best just got better. The voyage-4 series models operate in a shared embedding space, allowing for cross-model compatibility and unprecedented flexibility to optimize for accuracy, speed, or cost. This release also includes voyage-4-nano, our first open-weight model available on HuggingFace, perfect for local development.
Additionally, we're launching the new voyage-multimodal-3.5 model, which has been specifically trained to support video content alongside text and images. For developers building multimodal AI applications, this represents a significant leap forward in handling diverse content types within a single retrieval system. Best of all, upgrading is remarkably straightforward—you can simply change the model parameter to "voyage-multimodal-3.5" in your API call, instantly unlocking video capabilities without needing to refactor your existing codebase or change your application architecture.
Finally, we’re announcing the public preview of the Embedding and Reranking API on MongoDB Atlas, providing API support for Voyage AI models. While enabling standalone usage of the models with any technology stack, the API benefits from the robust security and scalability standards of MongoDB. By bringing critical components into a single control plane and interface, it eliminates the need to manage separate vendors and significantly reduces operational overhead.
Automated Embedding, convenience built into MongoDB Community
Persistence matters. An AI with amnesia isn’t helpful; users need systems to remember context from minutes, hours, and weeks ago. Every interaction is a goldmine of preferences, patterns, and behavior that should make the next interaction smarter.
But storing conversation history in a database isn't enough. Simple storage solves nothing if you can't retrieve the right information at the right time. The real challenge is intelligent retrieval: finding relevant context across thousands of past interactions, filtered by metadata and user attributes, without your system buckling under production load. This is where vector search becomes critical—enabling semantic search that captures meaning, not just keywords, while operating on your real-time operational data. And this is where MongoDB's approach eliminates a major pain point: the need to sync data between separate systems for vectors and application data.
Until now, generating and storing these vectors required overhead—development time, infrastructure management, and cognitive load. No longer.
We're introducing Automated Embedding for MongoDB Community Edition in public preview. MongoDB Community Edition now handles the complexity of managing embedding models automatically, giving developers high-accuracy semantic search in the database while maintaining flexibility to use any LLM provider or orchestration framework. Automated Embedding offers one-click automatic embedding directly inside MongoDB, which eliminates the need to sync data and manage external models. It’s an easy way to get high quality embedding natively.
Best-in-class retrieval shouldn't require infrastructure work—Automated Embedding in MongoDB Vector Search delivers on that promise. Automated Embedding in MongoDB Vector Search is available now in Community Edition, with Atlas access coming soon.
Precise text filtering for advanced search use cases
Today, we announced the launch of Lexical Prefilters for Vector Search. This addresses a long-standing request from developers building semantic search interfaces who need advanced text filtering alongside vector operations.
The new syntax enables powerful text filtering capabilities—fuzzy matching, phrase search, wildcards, and geospatial filtering—as prefilters for vector search. This leverages full text analysis capabilities while maintaining the semantic power of vector search. We've introduced a new vector data type in $search index definitions and a vectorSearch operator within the $search aggregation stage to make this work seamlessly.
This replaces the knnBeta operator with a cleaner, more powerful approach. For teams already using lexical and vector search together, this provides a simplified migration path with significantly expanded capabilities.
Intelligent assistance wherever you work
MongoDB’s intelligent assistant is generally available in MongoDB Compass. The assistant provides in-app guidance for debugging connection errors, optimizing query performance, and learning best practices, all without leaving your development environment. You can even query your database using natural language through read-only database tools that require your approval before execution, allowing for deeper contextual awareness of your data.
The assistant was built to address real friction: developers switching between multiple tools and documentation tabs, waiting for support responses, or getting generic advice from general-purpose AI chatbots that don't understand MongoDB-specific contexts. Now, tailored guidance is available instantly, right where you're working.
The modernized Atlas Data Explorer interface brings the Compass experience directly into the Atlas web UI, addressing a critical gap for teams with security policies that restrict desktop application usage. Users can now perform sophisticated query development, optimization, bulk operations, and complex aggregations—all with AI assistance—across all MongoDB Atlas clusters in a unified web interface.
Whether you're troubleshooting a connection issue, optimizing a slow query, or learning how to structure an aggregation pipeline, the intelligent assistant delivers MongoDB-specific expertise without context switching. Try the intelligent assistant in the modernized Atlas Data Explorer now.
The engine behind MongoDB Search and Vector Search is now available under SSPL
Finally, mongot, the engine powering MongoDB Search and Vector Search, is now publicly available under SSPL. While still in preview, after years of development and investment, we're making the source code of this core technology available to the community, expanding our unified search architecture beyond Atlas to every MongoDB deployment.
mongot runs separately from mongod, MongoDB's core database process, and is the foundation that makes powerful search native to MongoDB. Releasing mongot under SSPL means full transparency for security audits and debugging complex edge cases. Developers can dive into mongot's architecture, understand how search and vector operations work under the hood, and help shape the future of search at MongoDB.
A modern data platform that evolves with your needs
These announcements reflect our commitment to anticipating what developers need as AI development matures. Vector search, time series, stream processing, queryable encryption, Atlas itself—we've consistently delivered on emerging requirements. "If you're building an early-stage company that is going to scale very rapidly, you need a database solution that isn't going to break under the load of a huge volume of users," said Eno Reyes, Co-founder and CTO of Factory. "You need a fast-moving team with a reliable solution, and there really is one option in this space—and it's MongoDB."
Rabi Shanker Guha, CEO of Thesys, put it this way: “MongoDB helps us move fast in an ever-changing world. The best database is the one you don’t have to think about—it just works exactly where and how you need it. That’s MongoDB for us.”
Ship faster, scale confidently
Each capability we announced today addresses real friction in the AI development workflow and in the developer experience. We're not asking developers to choose between structured data and vectors, between performance and flexibility, or between rapid iteration and production readiness.
The promise is straightforward: ship faster, scale confidently, and focus on what makes your AI application unique—not on managing database infrastructure. In an ecosystem crowded with point solutions and retrofitted legacy systems, MongoDB is a modern data platform built for the long haul.
January 15, 2026