Series:
- Part 1 – Introduction
- Part 2 – Worked Examples
- Part 3 - Adding Some Code Glue and Geolocation
This is the first of a three part blog series looking at the aggregation enhancements being introduced in MongoDB 3.2 – most notably $lookup which implements left-outer equi-joins in the MongoDB Aggregation Framework.
This post starts with an introduction to analyzing data with MongoDB. We then explain why joins are sometimes useful for MongoDB – in spite of the strengths of the document model – and how developers have been working without them.
The second post in the series works through examples of building aggregation pipelines – including using the operators added in MongoDB 3.2.
The third and final post shows how geolocation data can be included as well as what to do when you reach the limit of what can be done using a single pipeline – including adding wrapper code. That post also summarizes some of the limitations of the Aggregation Framework and reasons why you might supplement it with a full visualization solution such as Tableau together with MongoDB's Connector for BI (Business Intelligence) – also new in MongoDB 3.2.
Disclaimer
MongoDB's product plans are for informational purposes only. MongoDB's plans may change and you should not rely on them for delivery of a specific feature at a specific time.
Real-Time Analytics and Search
With the emergence of new data sources such as social media, mobile applications and sensor-equipped “Internet of Things” networks, organizations can extend analytics to deliver real-time insight and discovery into such areas as operational performance, customer satisfaction, and competitor behavior.
Time to value is everything. For example, having access to real-time customer sentiment or fleet tracking is of little benefit unless the data can be analyzed and reported in real-time.
MongoDB 3.2 aims to extend the options for performing analytics on the live, operational database – ensuring that answers are delivered quickly, and reflect current data. Work that would previously have needed to be done on the client side can now be performed by the database – freeing the developer to focus on new features.
The Case for Joins
MongoDB’s document data model is flexible and provides developers many options in terms of modeling their data. Most of the time all the data for a record tends to be located in a single document. For the operational application, accessing data is simple, high performance, and easy to scale with this approach.
When it comes to analytics and reporting, however, it is possible that the data you need to access spans multiple collections. This is illustrated in Figure 1, where the _id field of multiple documents from the products collection is included in a document from the orders collection. For a query to analyze orders and details about their associated products, it must fetch the order document from the orders collection and then use the embedded references to read multiple documents from the products collection. Prior to MongoDB 3.2, this work is implemented in application code. However, this adds complexity to the application and requires multiple round trips to the database, which can impact performance.
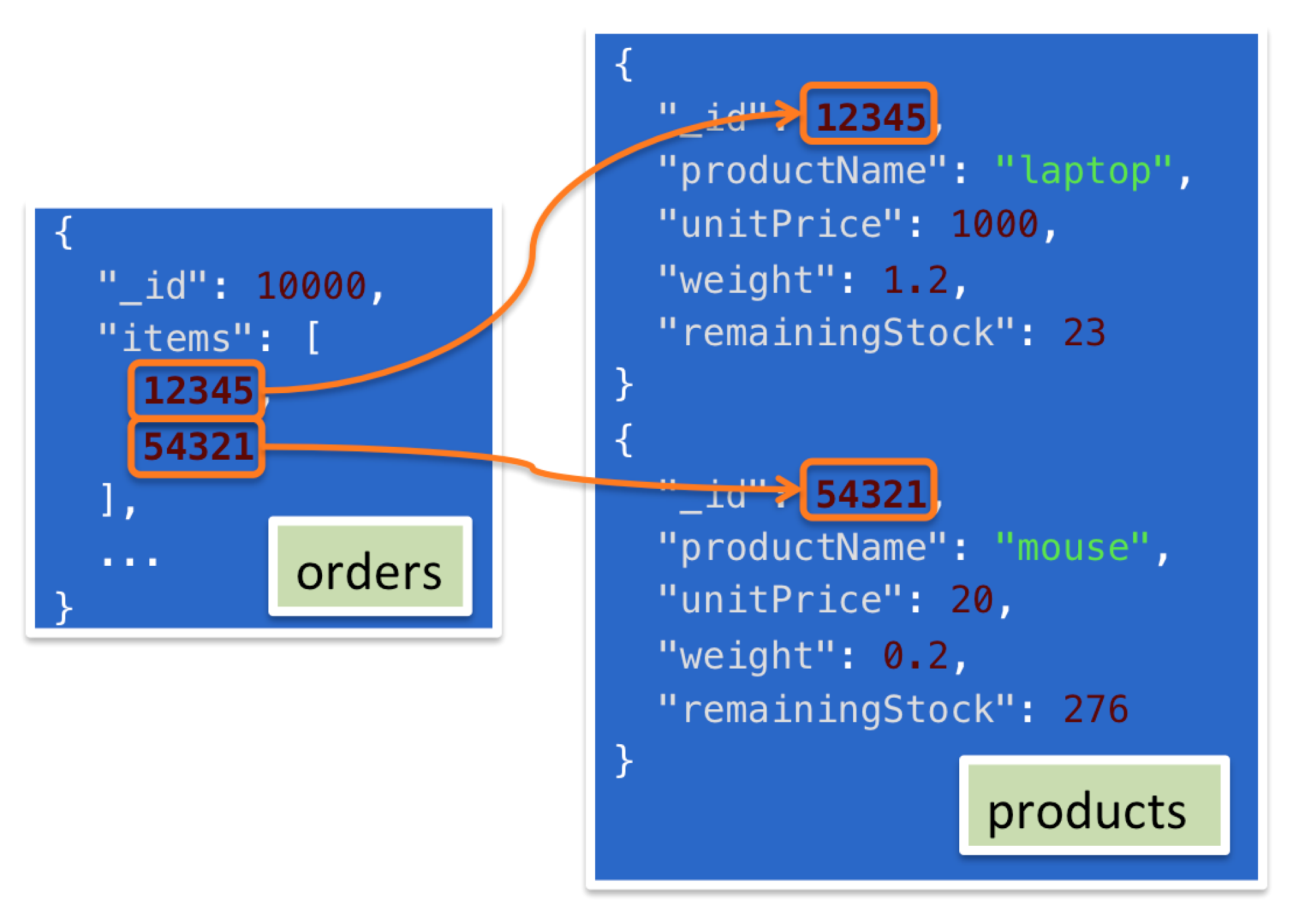
Figure 1: Application-Layer simulation of joins between documents
MongoDB 3.2 introduces the $lookup operator that can now be included as a stage in an aggregation pipeline. With this approach, the work of combining data from the orders and products collections is implemented within the database, and as part of a broader aggregation pipeline that performs other processing in a single query. As a result, there is less work to code in the application, and fewer round trips to the database. You can think about $lookup as equivalent to a left outer equi-join.
Aside - What is a Left Outer Equi-Join?
A left outer equi-join produces a result set that contains data for all documents from the left table (collection) together with data from the right table (collection) for documents where there is a match with documents from the left table (collection). This is illustrated in Figure 2.
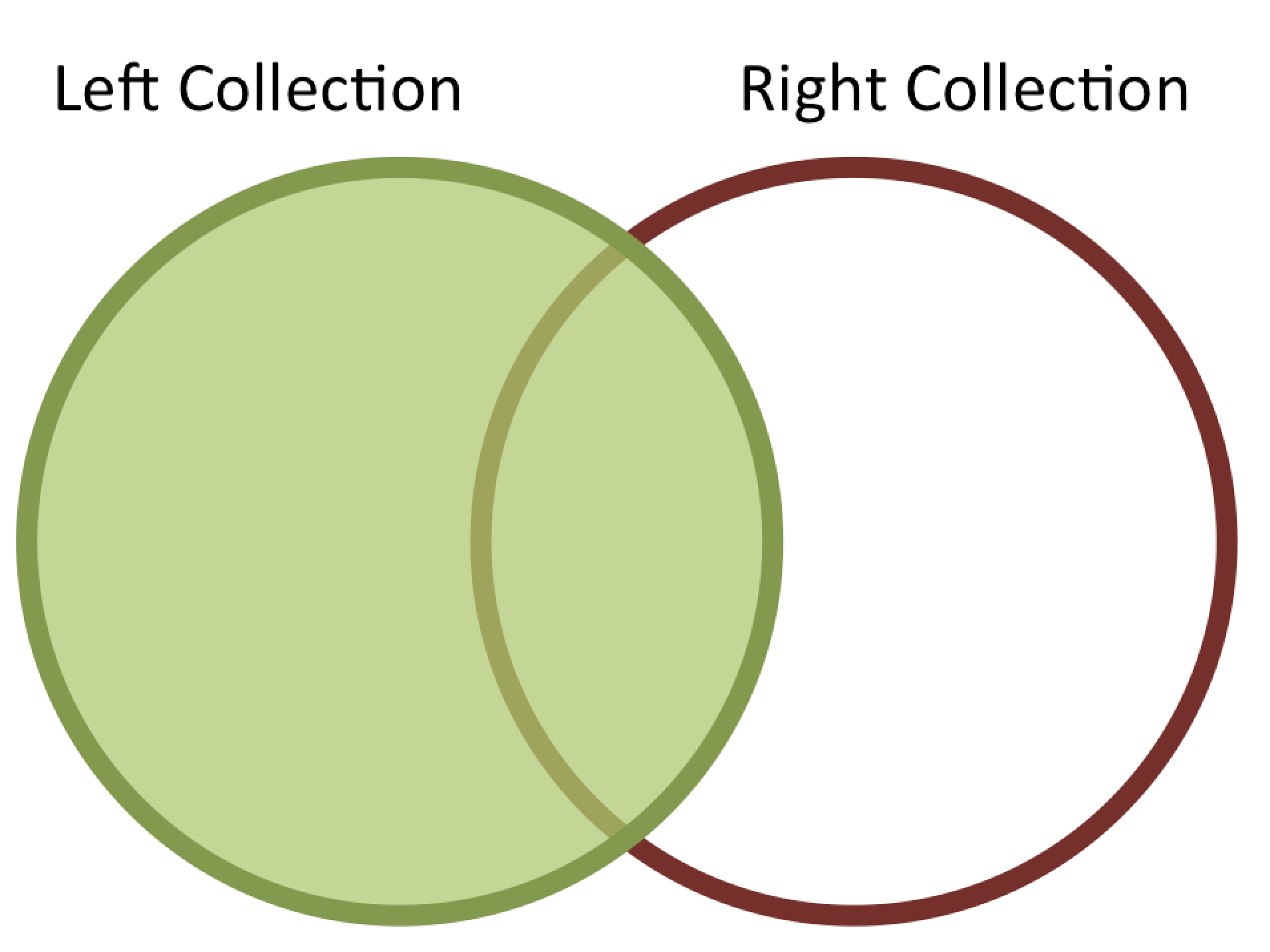
Figure 2: Left-Outer join between collections
MongoDB's Aggregation Framework
The Aggregation Framework is a pipeline for data aggregation modeled on the concept of data processing pipelines. Documents enter a multi-stage pipeline that transforms the documents into aggregated results. The pipeline consists of stages; each stage transforms the documents as they pass through.
In general, each successive stage reduces the volume of data; removing information that isn't needed and combining other data to produce summarized results.
Figure 3 shows a conceptual model for the Aggregation Framework pipeline. This is what's happening at each stage:
- On the left-hand side/start of the pipeline is the original collection contents – each record (document) containing a number of shapes (keys), each with a particular color (value)
- The $match stage filters out any documents that don't contain a red diamond
- The $project stage adds a new “square” attribute with a value computed from the value (color) of the snowflake and triangle attributes
- The $lookup stage (new in 3.2 - more details later) performs a left-outer join with another collection, with the star being the comparison key. This creates new documents which contain everything from the previous stage but augmented with data from any document from the second collection containing a matching colored star (i.e., the blue and yellow stars had matching “lookup” values, whereas the red star had none).
- Finally, the $group stage groups the data by the color of the square and produces statistics (sum, average and standard deviation) for each group.
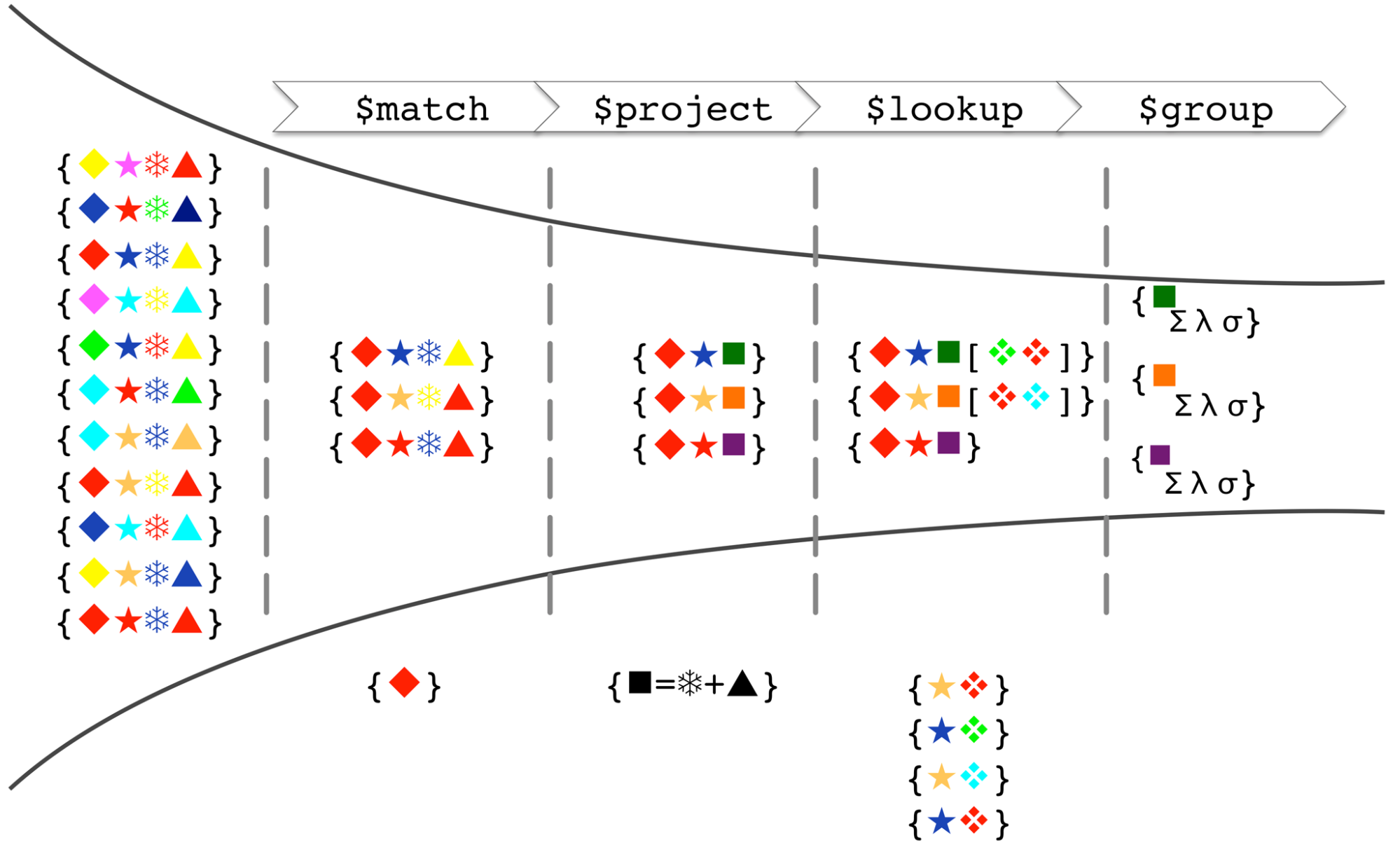
Figure 3: MongoDB Aggregation Framework pipeline
This is the full set of aggregation stages:
- $match – Filter documents
- $geoNear – Sort documents based on geographic proximity
- $project – Reshape documents (remove or rename keys or add new data based on calculations on the existing data)
- $lookup – Coming in 3.2 – Left-outer joins
- $unwind – Expand documents (for example create multiple documents where each contains one element from an array from the original document)
- $group – Summarize documents
- $sample – Randomly selects a subset of documents
- $sort – Order documents
- $skip – Jump over a number of documents
- $limit – Limit number of documents
- $redact – Restrict sensitive content from documents
- $out – Coming in 3.2* – store the results in a new collection
The details can be found in the documentation.
New Aggregation Operators in MongoDB 3.2
There are operators used within each stage and this set is being extended in MongoDB 3.2 to include:
- Array operations
- $slice, $arrayElemAt, $concatArrays, $isArray, $filter, $min, $max, $avg and $sum (some of these were previously available in a $group stage but not in $project
- Standard Deviations
- $stdDevSamp (based on a sample) and $stdDevPop (based on the complete population)
- Square Root
- $sqrt
- Absolute (make +ve) value
- $abs
- Rounding numbers
- $trunc, $ceil, $floor
- Logarithms
- $log, $log10, $ln
- Raise to power
- $pow
- Natural Exponent
- $exp
Further details on these new operators can be found in the MongoDB 3.2 Release Notes.
$lookup – Left Outer Equi-Joins
Figure 4 illustrates the syntax for performing the join:
- leftCollection is the collection that the aggregation is being performed on and is the left collection in the join
- from identifies the collection that it will be joined with – the right collection (rightCollection in this case)
- localField specifies the key from the original/left collection – leftVal
- foreignField specifies the key from the right collection – rightVal
- as indicates that the data from the right collection should be embedded within the resulting documents as an array called embeddedData

Figure 4: $lookup – Left-Outer Joins for MongoDB
In the follow-on blogs in this series, you’ll see how the data from a home sales collection (containing details of each home sale, including the property’s postal code) is joined with data from a postal code collection (containing postal codes and their geographical location). This produces documents that contain the original home sale information augmented with the coordinates of the property. In this case, the “homesales” collection is the left-collection and “postcodes” the right-collection; the “postcode” field from each collection is the localField which is matched with the foreignField.
Next Steps
To learn more about what's coming up in MongoDB 3.2, register for the What's new in MongoDB 3.2 webinar and review the MongoDB 3.2 development documentation.
To get the best understanding of the new features then you should experiment with the software, which is available in the MongoDB 3.2 release. It will be available in both the MongoDB Enterprise Advanced and Community Editions (GA coming soon).
The reason MongoDB releases development releases is to give the community a chance to try out the new software – and we hope that you'll give us feedback, whether it be by joining the MongoDB 3.2 bug hunt or commenting on this post.
About the Author - Andrew Morgan
Andrew is a Principal Product Marketing Manager working for MongoDB. He joined at the start of this summer from Oracle where he’d spent 6+ years in product management, focussed on High Availability. He can be contacted @andrewmorgan or through comments on his blog (clusterdb.com).