MongoDB and IIoT: Data Streaming With Kafka
Event streaming has become a cornerstone of the industrial internet of things (IIoT) because it allows people to unleash the power of real-time operational data to drive applications and analytics. In this article, we share how MongoDB Atlas helps you move data seamlessly from the MQTT protocol into MongoDB time series collections using the Apache Kafka MQTT source and MongoDB sink connectors deployed in a cloud environment.
Data streaming is the second step in our framework for end-to-end data integration in the manufacturing sector. The “connect” step of this framework deals with establishing an interface for interaction with IoT devices. The methodology discussed in this blog was developed and tested using a model factory created by Fischertechnik, but these steps are applicable to any environment that uses the standard MQTT protocol. All the source code for this project, along with a detailed deployment guide, can be found on our public Github repository.
The challenge of collecting data
On the shop floor, devices and components are continuously generating data related to their activity and environmental conditions at regular time intervals, typically known as time series data. In our factory model production line, there are a variety of sensors collecting data about temperature, pressure, humidity, brightness, camera positions, device/inventory status, and movements. This data is vital to monitor the health and effectiveness of factory equipment and its ability to continue to function without failure. The resulting datasets are often huge and must be efficiently stored and analyzed to detect anomalies or provide insight into overall equipment efficiency.
With the advent of powerful event streaming platforms like Apache Kafka — and the wide variety of connectors for all sorts of protocols — it has become increasingly simple to handle the consolidation and export of real-time data feeds. However, dealing with such large volumes of data comes with added challenges regarding scalable storage, cost implications, and data archiving.
This is where MongoDB’s time series collections come into play. Time series collections are a distinct type of MongoDB collections, optimized to efficiently store and process time series data by leveraging clustered indexes, columnar compression, and aggregation pipeline stages to facilitate real-time analytics.
Learn more about time series collections on our tutorial page.
Dream team: MQTT + Kafka + MongoDB
Our recipe for collecting real-time sensor data (using the MQTT protocol) combines an MQTT source connector developed by Confluent and a native MongoDB sink connector deployed in a containerized environment.
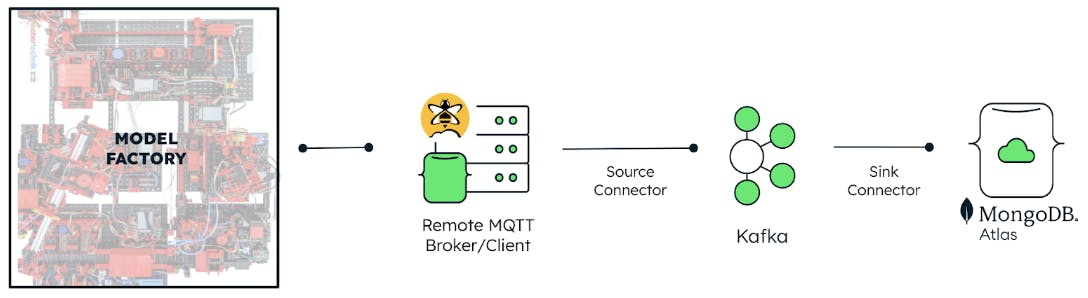
In this instance, we used a similar stack that includes Kafka Connect, a Kafka broker, and ZooKeeper deployed as containers in a single Docker compose file. This setup can be deployed locally, on a serverless backend or even Confluent Cloud. In our case, we have it deployed on an AWS EC2 Linux instance.
Read our tutorial on how to set up a Kafka development environment with MongoDB connectors.
Here’s a brief explanation of what each container does in this environment:
Zookeeper: Acts a centralized controller that manages and organizes all the Kafka brokers.
Kafka broker: Allows Kafka consumers to fetch messages by topic, partition, and offset. Kafka brokers can create a Kafka cluster by sharing information between each other.
Kafka Connect: Serves as the runtime environment where you can configure connectors to ingest data into Kafka topics, making the data available for stream processing with low latency.
It is worth noting that Kafka allows any number of sink and source connectors to be created in its environment as long as there are no server resource restrictions. Once the development environment is set up, all the necessary parameters are configured in the source and sink connectors.
The source connector
The source connector allows the Kafka broker to subscribe to MQTT topics. It serves to map the MQTT topics that contain the desired data parameters to a chosen Kafka topic. For simplicity, we’ve used Confluent’s MQTT source connector, which supports any kind of MQTT broker connection (self-hosted or otherwise). We’ve also used a managed MQTT service from HiveMQ as our remote broker.
In the sample source connector configuration below, we’ve streamed sensor readings from multiple MQTT topics on the factory to a single Kafka topic called sensors using a string list of MQTT topics. We added the necessary access details to the remote broker from which Kafka will consume messages from the MQTT topic and save them as JSON values. Mapping several MQTT topics to the same Kafka topic does not affect the performance of the connector.
{
"name": "mqtt-source",
"config": {
"connector.class": "io.confluent.connect.mqtt.MqttSourceConnector",
"tasks.max": "1",
"mqtt.server.uri": "ssl://<REMOTE BROKER ADDRESS>:8883",
"mqtt.username": "<REMOTE BROKER CLIENT>",
"mqtt.password": "<REMOTE BROKER CLIENT PASSWORD>",
"mqtt.topics": "i/ldr,i/bme680,i/cam",
"kafka.topic": "sensors",
"value.converter":"org.apache.kafka.connect.converters.ByteArrayConverter",
"confluent.topic.bootstrap.servers": "broker:9092",
"confluent.license": "",
"topic.creation.enable": true,
"topic.creation.default.replication.factor": -1,
"topic.creation.default.partitions": -1
}}
The sink connector
While the source connector specifies the location from which data is retrieved, the sink connector specifies the destination to which data is sent. We used the MongoDB Kafka Sink Connector, which allowed us to connect to a MongoDB Atlas cluster with the right access information and choose which database and collection the streaming data was stored in. To receive the brightness readings captured in the source connector, the topics property in this connector must be set to match the name of the kafka.topic property in the former.
{
"name": "mongodb-sink",
"config": {
"connector.class":"com.mongodb.kafka.connect.MongoSinkConnector",
"tasks.max":1,
"topics":"sensors",
"connection.uri":"mongodb+srv://user:password@address.mongodb.net/database?retryWrites=true&w=majority",
"database":"<database name>",
"collection":"<collection name>",
"key.converter":"org.apache.kafka.connect.storage.StringConverter",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":"false",
"timeseries.timefield":"ts",
"timeseries.timefield.auto.convert":"true",
"timeseries.timefield.auto.convert.date.format":"yyyy-MM-dd'T'HH:mm:ss'Z'",
"transforms": "RenameField,InsertTopic",
"transforms.RenameField.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.RenameField.renames": "h:humidity, p:pressure, t:temperature”,
"transforms.InsertTopic.type":"org.apache.kafka.connect.transforms.InsertField$Value",
"transforms.InsertTopic.topic.field":"Source"
}}
The converter properties in Figure 4 instruct the connector on how to translate data from Kafka. This configuration also automatically creates a time series collection in the requested database using the timeseries.timefield properties, which allowed us to choose which field in the original MQTT message qualifies as the timestamp and auto-convert that to a MongoDB-compatible date/time value format. Find out more about the configurable properties of our Kafka connectors in our detailed documentation.
Smooth sailing with MongoDB Atlas
Once the connectors have been configured and launched, Kafka listens on the mapped topics for any change events and translates this to documents in a time series collection. As long as the Kafka environment is running and connection with the MQTT broker remains unbroken, the time series collection is updated in real time and highly compressed (often more than 90%) to accommodate the continuous influx of data. See a sample of the time series collection we created in Figure 5.
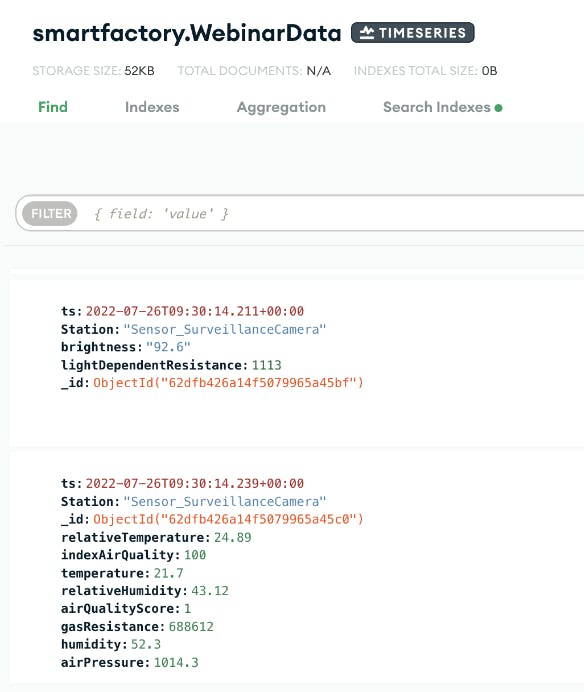
As the expectations of consumability vary across organizations and personas, the underlying data structure can be further tailored for different use cases by using materialized views and simple aggregations.
Since time series data is hardly ever changed and “cools down” over time, storing it in a hot data tier can become costly. To optimize costs, MongoDB Atlas provides Online Archive, which allows you to configure filter criteria to trigger automatic offloading of “cold” data to cheaper storage while maintaining its queryability.
Once you start to receive accurate real-time data from the factory floor, a world of opportunity opens up in terms of getting insights from the collected data.
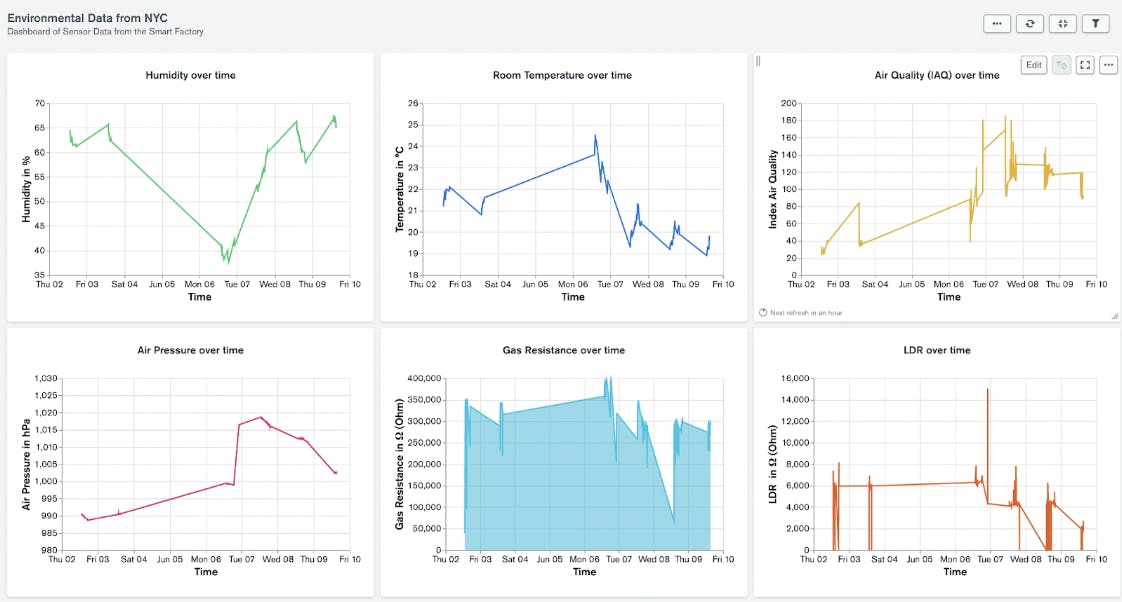
In our next post, we will show you how to leverage the rest of the MongoDB Atlas product suite to run analytics on operational data, including using Atlas Charts for instant seamless data visualizations (see Figure 6).
All the source code used in this project, along with a detailed deployment guide, is available on our public Github repo. Feel free to clone it and play around with configuring Kafka and its connectors. Most of the principles discussed in this post are applicable to any device that uses MQTT as a communication protocol.
To learn more, watch our webinar session to see the full reference architecture, get tips for configuring your Kafka connectors, and see a live demonstration. If you have questions about other communication protocols or would like to consult with someone from our team about your project, please contact us.
Read Part 2 of this series on a 4-Step Data Integration.