Vector Search y Conceptos Básicos de LLM: Qué, Cuándo y Por Qué
November 16, 2023
Vector Search y, más ampliamente, la Inteligencia Artificial (IA) son más populares ahora que nunca. Estos términos están surgiendo en todas partes. Las empresas de tecnología de todo el mundo están luchando por adoptar versiones de búsqueda vectorial y características de IA en un esfuerzo por ser parte de esta creciente tendencia. Como resultado, es inusual encontrar una página de inicio para un negocio basado en datos y no ver una referencia a la vector search o a modelos de lenguaje grande (LLM). En este blog, cubriremos lo que MEAN estos términos mientras examinamos los eventos que llevaron a su tendencia actual.
Consulte nuestra página de recursos de IA para obtener más información sobre cómo crear aplicaciones basadas en IA con MongoDB.
¿Qué es la búsqueda vectorial?
Los vectores son representaciones codificadas de datos no estructurados como texto, imágenes y audio en forma de abanico de números.
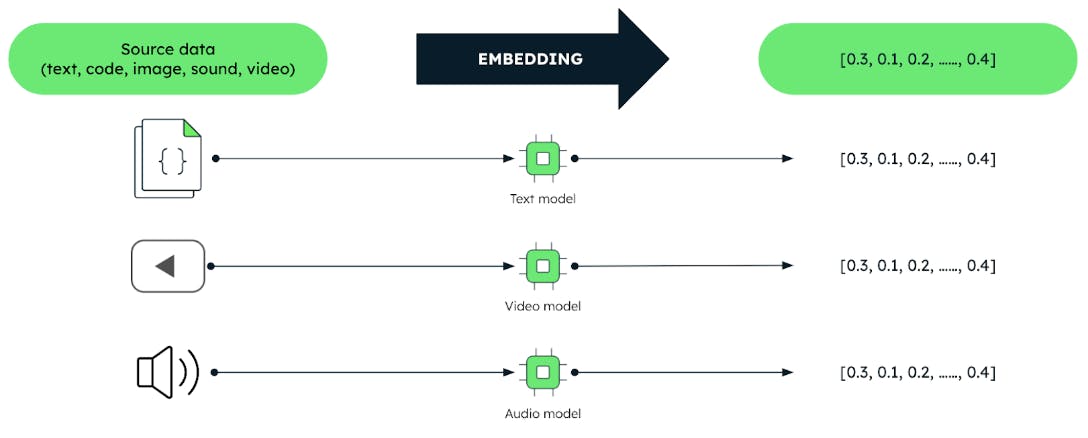
Estos vectores son producidos por técnicas de aprendizaje automático (ML) llamadas modelos " de " incrustación. Estos modelos están entrenados en grandes volúmenes de datos. Los modelos de incrustación capturan de manera efectiva las relaciones significativas y las similitudes entre los datos. Esto permite a los usuarios consultar datos basados en el significado en lugar de los datos en sí. Este hecho desbloquea tareas de análisis de datos más eficientes como sistemas de recomendación, comprensión del lenguaje y reconocimiento de imágenes.
Cada búsqueda comienza con una consulta y, en la búsqueda vectorial, la consulta está representada por un vector. El trabajo de la vector search es encontrar, a partir de los vectores almacenados en una base de datos, aquellos que son más similares al vector de la consulta. Esta es la premisa básica. Se trata de similitud. Esta es la razón por la que la búsqueda vectorial a menudo se llama búsqueda de similitud. Nota: la similitud también se aplica a algoritmos de clasificación que funcionan con datos no vectoriales.
Para entender el concepto de similitud vectorial, imaginemos un espacio tridimensional. En este espacio, la ubicación de un punto de datos está completamente determinada por tres coordenadas.
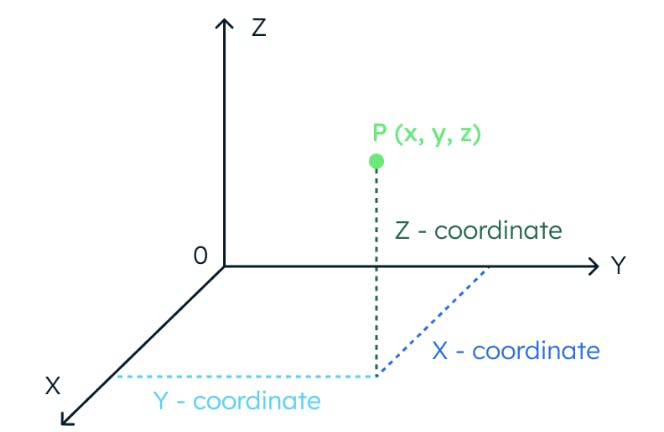
De la misma manera, si un espacio tiene 1024 dimensiones, se necesitan 1024 coordenadas para localizar un punto de datos.
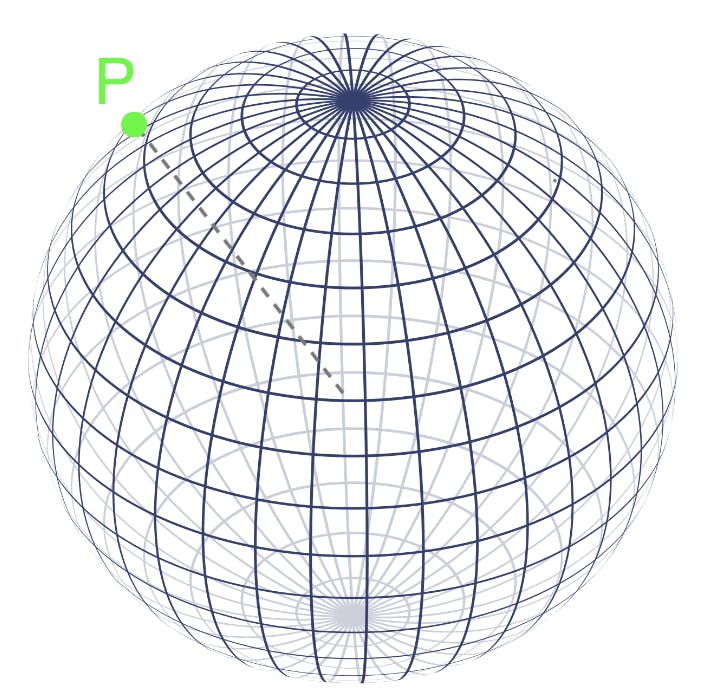
Los vectores también proporcionan la ubicación de los puntos de datos en espacios multidimensionales. De hecho, podemos tratar los valores de un vector como un abanico de coordenadas. Una vez que tenemos la ubicación de los puntos de datos, los vectores, su similitud entre ellos se calcula midiendo la distancia entre ellos en el espacio vectorial. Los puntos que están más cerca unos de otros en el espacio vectorial representan conceptos que son más similares en significado.
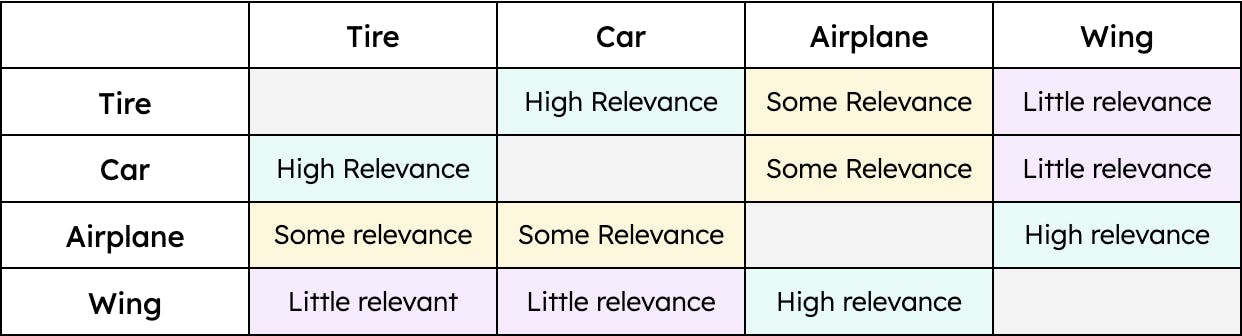
Por ejemplo, la " llanta " tiene una mayor similitud con el " auto " y una menor con el " avión. " Sin embargo, el " ala solo " tendría una similitud con el " avión. " Por lo tanto, la distancia entre los vectores para “neumático” y “auto” sería menor que la distancia entre los vectores para “neumático” y “avión”. Sin embargo, la distancia entre “ala” y “auto” sería enorme. En otras palabras, “neumático” es relevante cuando hablamos de un “auto” y, en menor medida, de un “avión”. Sin embargo, un “ala” solo es relevante cuando hablamos de un “avión” y nada relevante cuando hablamos de un “automóvil” (al menos hasta que los autos voladores sean un modo de transporte viable). La contextualización de los datos, independientemente del tipo, permite la vector search para recuperar los resultados más relevantes para una consulta determinada.
Un ejemplo simple de similitud
¿Qué son los modelos de lenguaje grande?
Los LLM son lo que lleva la IA a la ecuación de búsqueda vectorial. Los LLM y las mentes humanas entienden y asocian conceptos para realizar ciertas tareas del lenguaje natural, como seguir una conversación o comprender un artículo. Los LLM, como los humanos, necesitan entrenamiento para entender diferentes conceptos. Por ejemplo, ¿sabe a qué se refiere el término “corium”? A menos que sea ingeniero nuclear, probablemente no. Lo mismo sucede con los LLM: si no están capacitados en un dominio específico, no son capaces de entender los conceptos y, por lo tanto, tienen un desempeño deficiente. Veamos un ejemplo.
Los LLM entienden fragmentos de texto gracias a su capa de incrustación. Aquí es donde las palabras u oraciones se convierten en vectores. Para visualizar vectores vamos a utilizar cloud de palabras. cloud de palabras están estrechamente relacionadas con los vectores en el sentido de que son representaciones de conceptos y su contexto. Primero, veamos la cloud de palabras que generaría un modelo de incrustación para el término “corium” si fuera entrenado con datos de ingeniería nuclear:

Como se muestra en la imagen de arriba, la cloud de palabras indica que el corio es un material radiactivo que tiene algo que ver con las estructuras de seguridad y contención. Pero, corium es un término especial que también se puede aplicar a otro dominio. Veamos la cloud de palabras resultante de un modelo de incrustación que ha sido entrenado en biología y anatomía:
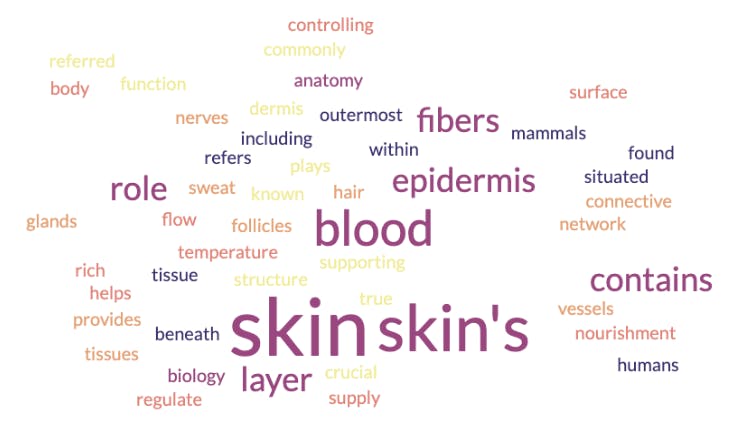
En este caso, la cloud de palabras indica que corium es un concepto relacionado con la piel y sus capas. ¿Qué pasó aquí? ¿Está equivocado uno de los modelos de incrustación? No. Ambos han sido entrenados con diferentes datos para establecer. Por eso es crucial encontrar el modelo más apropiado para un caso de uso específico. Una práctica común en la industria es adoptar un modelo de incrustación previamente entrenado con un sólido conocimiento de fondo. Uno toma este modelo y luego lo ajusta con el conocimiento específico del dominio necesario para realizar tareas particulares.
La cantidad y calidad de los datos utilizados para entrenar un modelo también son relevantes. Podemos estar de acuerdo en que una persona que haya leído solo un artículo sobre aerodinámica estará menos informada sobre el tema que una persona que estudió física e ingeniería aeroespacial. De manera similar, los modelos que se entrenan con una gran cantidad de datos de alta calidad comprenderán mejor los conceptos y generarán vectores que los representen con mayor precisión. Esto crea las bases para un éxito (en este contexto, por ejemplo, «éxito de la innovación»); en otros contextos: sistema de búsqueda de vectores correctos.
Vale la pena señalar que aunque los LLM usan modelos de incrustación de texto, la vector search va más allá de eso. Puede tratar con audio, imágenes y más. Es importante recordar que los modelos de incrustación utilizados para estos casos de acción (en este contexto empresarial particular) siguen el mismo enfoque. También necesitan ser entrenados con datos (imágenes, sonidos, etc.) para poder entender el significado detrás de esto y crear los vectores de similitud apropiados.
¿Cuándo se creó la vector search?
MongoDB Atlas Vector Search actualmente proporciona tres enfoques para calcular la similitud de vectores. Estas también se denominan métricas de distancia y consisten en:
-
distancia euclidiana
-
producto coseno
-
producto punto
Si bien cada métrica es diferente, a los efectos de este blog nos centraremos en el hecho de que todas miden la distancia. Atlas Vector Search introduce estas métricas de distancia en un algoritmo de vecino más cercano (ANN) aproximado para encontrar los vectores almacenados que sean más similares al vector de la consulta. Para acelerar este proceso, los vectores se clasifican utilizando un algoritmo llamado mundo pequeño navegable jerárquico (HNSW). HNSW guía la búsqueda a través de una red de puntos de datos interconectados para que solo se consideren los puntos de datos más relevantes.
El uso de una de las tres métricas de distancia junto con los algoritmos HNSW y KNN constituye la base para realizar búsquedas vectoriales en MongoDB Atlas. Pero, ¿cuántos años tienen estas tecnologías? Pensaríamos que son invenciones recientes de un laboratorio de computación cuántica de vanguardia, pero la verdad está lejos de eso.
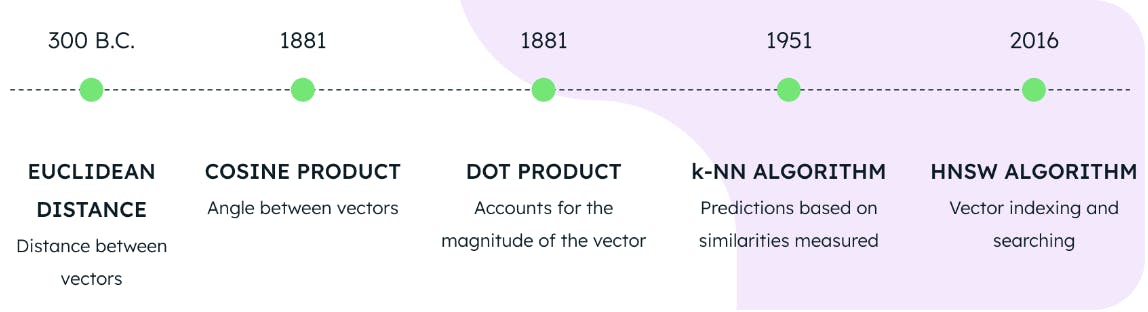
La distancia euclidiana se formuló en el año 300 a.C., el coseno y el producto punto en 1881, el algoritmo KNN en 1951 y el algoritmo HNSW en 2016. Lo que esto significa es que las bases para la búsqueda vectorial de última generación estaban completamente disponibles en 2016. Entonces, aunque la búsqueda vectorial es el tema candente de hoy, ha sido posible implementarla durante varios años.
¿Cuándo se crearon las LLM?
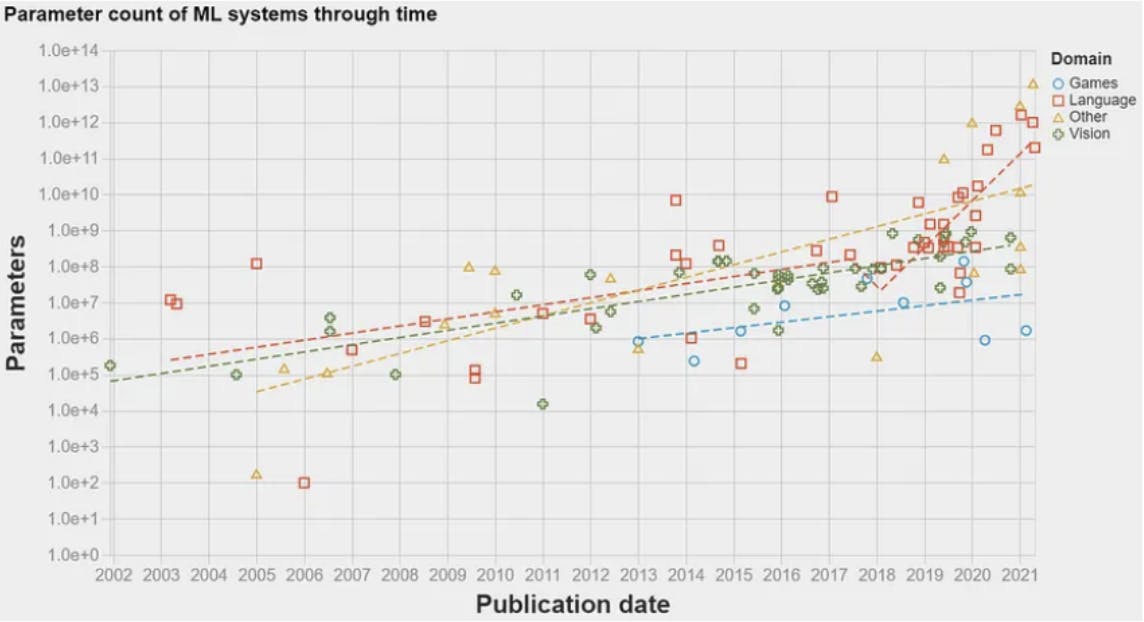
En 2017, hubo un gran avance: la arquitectura del transformador. Presentado en el famoso periódico Attention is all you need, esta arquitectura introdujo un modelo de red neuronal para las tareas de procesamiento del lenguaje natural (PNL). Esto permitió que los algoritmos de ML procesaran datos de lenguaje en un orden de magnitud mayor de lo que antes era posible. Como resultado, la cantidad de información que podría usarse para entrenar a los modelos aumentó exponencialmente. Esto allanó el camino para que aparezca el primer LLM en 2018: GPT -1 de OpenAI. Los LLM utilizan modelos de incrustación para comprender fragmentos de texto y realizar ciertas tareas de lenguaje natural, como responder preguntas o traducción automática. Las LLM son esencialmente modelos de PNL que fueron rebautizados debido a la gran cantidad de datos con los que están entrenados, de ahí la palabra grande en LLM. El siguiente gráfico muestra la cantidad de datos (parámetros) utilizados para entrenar modelos de ML a lo largo de los años. Se puede observar un aumento dramático en 2017 después de que se publicara la arquitectura del transformador.
¿Por qué son tan populares la búsqueda vectorial y los LLM?
Como se indicó anteriormente, la tecnología para la búsqueda vectorial estaba completamente disponible en 2016. Sin embargo, no se hizo particularmente popular hasta finales de 2022. ¿Por qué?
Aunque la industria del aprendizaje automático ha estado muy activa desde 2018, los LLM no estuvieron ampliamente disponibles ni fueron fáciles de usar hasta la versión OpenAI de ChatGPT en noviembre de 2022. El hecho de que OpenAI permitiera a todos interactuar con un LLM con una simple charla es la clave de su éxito. ChatGPT revolucionó la industria al permitir que la persona promedio interactúe con algoritmos de PNL de una manera que de otro modo habría sido reservada para investigadores y científicos. Como se puede ver en la siguiente figura, el avance de OpenAI llevó a que la popularidad de los LLM se disparara. Al mismo tiempo, ChatGPT se convirtió en una herramienta convencional utilizada por el público en general. La influencia de OpenAI en la popularidad de los LLM también se evidencia por el hecho de que tanto OpenAI como LLM tuvieron su primer pico de popularidad simultáneamente. (Vea la figura 8.)
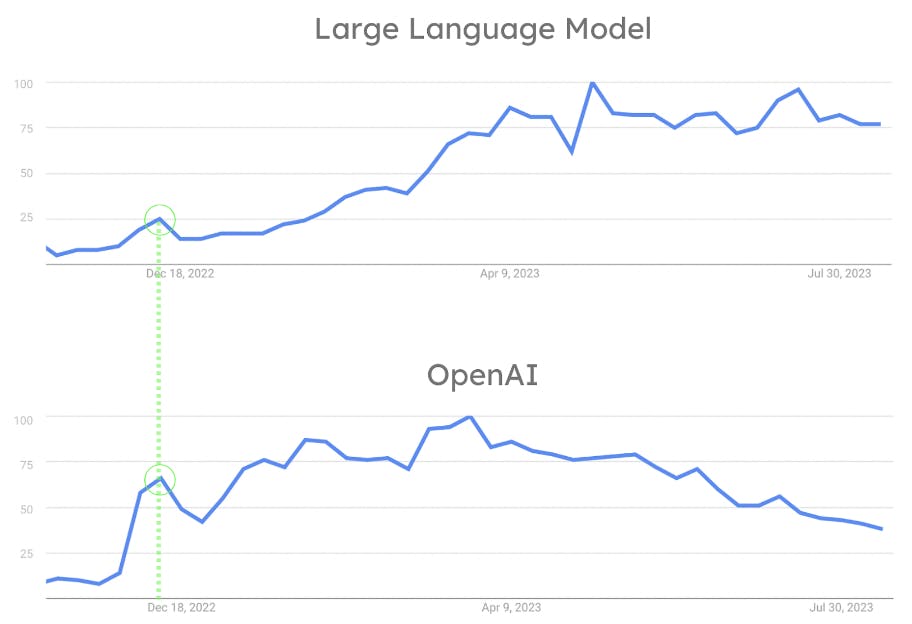
Aquí está el por qué. Los LLM son tan populares porque OpenAI los hizo famosos con la versión de ChatGPT. Buscar y almacenar grandes cantidades de vectores se convirtió en un desafío. Esto se debe a que los LLM funcionan con incrustaciones. Así, la adopción de la búsqueda vectorial aumentó en tándem. Este es el mayor factor que contribuye al cambio de la industria. Este cambio resultó en que muchas empresas de datos introdujeran asistencia técnica para la búsqueda de vectores y otras funcionalidades relacionadas con los LLM y la IA detrás de ellos.
Conclusión
La búsqueda vectorial es un disruptor moderno. El creciente valor tanto de las incrustaciones vectoriales como de los procesos de búsqueda matemática avanzada ha catalizado la adopción de la búsqueda vectorial para transformar el campo de la recuperación de información. La generación de vectores y la búsqueda de vectores pueden ser procesos independientes, pero cuando trabajan juntos, su potencial es ilimitado.
Para obtener más información, visite nuestra página de producto Atlas Vector Search . Para comenzar a utilizar Vector Search, regístrese en Atlas o acesso en su cuenta.