Hi Kevin,
First and foremost thank you for helping and welcoming me.
We are currently running load tests, and as it happened before, Mongo started stalling, but our gp2 disks are not utilized that much. It seems that they are being utilized in (few) bursts. We also tried watching io with iotop directly which confirmed metrics we have on Prometheus, meaning io was there in bursts and by aws metrics disks were underutilized.
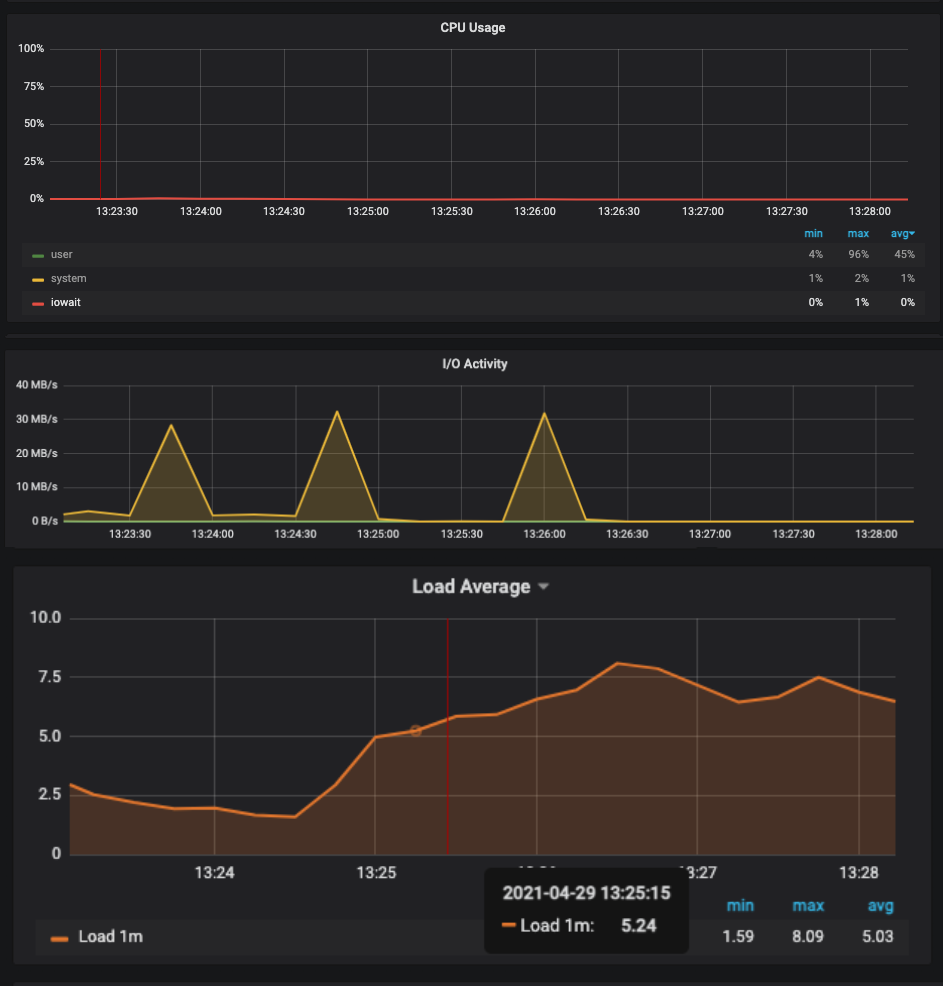
We tried bumping our instance to m5.2xlarge (double the previous one) but after the first successful test, it also started stalling when we ran the second one.
We also tried limiting our transactions to 60 seconds but that also did not help.
Yesterday we tried lowering write concern in an effort to eliminate replication as an issue and bulk inserting our records in an unordered way instead of ordered but neither of those showed any improvement.
Again thanks for pointing out the problem with the percentage of dirty pages and in case you have more insights we would appreciate them very much.
Best,
Sasha