At MongoDB Research, we’re exploring how to make cutting‑edge AI models smaller, faster, and more flexible.
In this blog post, we present LEAF (Lightweight Embedding Alignment Framework), a new knowledge distillation framework for text embedding models.
We’re also releasing two best‑in‑class embedding models trained with LEAF:
mdbr-leaf-ir—23M parameter model optimized for retrieval‑focused tasks like semantic search and retrieval‑augmented generation (RAG).
mdbr-leaf-mt—23M parameter model tailored for broader NLP applications such as classification, clustering, and sentence similarity.
These models are suitable for CPU-only deployments (no GPU), as well as IoT and mobile devices, with no internet connection required.
Note: We are publishing these models and the recipe used to train them as a contribution to the open source community. They have been developed by the ML team of MongoDB Research. The models are published under a permissive Apache 2.0 license and offered as is, without any explicit or implied support. At the time of writing, they are not used in any of MongoDB's commercial products or service offerings.
The challenges
Modern text embedding models have delivered huge gains in natural language processing tasks, from question‑answering to RAGs. But these gains come at a cost:
Model sizes are exploding. State‑of‑the‑art open‑weight embedding models can range from hundreds of millions to billions of parameters (e.g., 1B or 7B+). While these models can offer high accuracy, they typically need to run on GPU servers, making them impractical for many deployments.
Inflexible deployments. In information retrieval (IR) systems, the same large model is typically used for both document indexing and query encoding—even though these steps have very different performance requirements. Document indexing happens infrequently and tolerates high latency, while query-time embedding must meet strict latency targets—often expressed as P99 or tail latency—where even the slowest queries must return results within a few hundred milliseconds.
No easy swaps. Existing embedding models aren’t compatible with each other—even different sizes within the same family—so swapping models requires recomputing every document embedding from scratch.
These constraints make it hard to scale high‑performance retrieval systems, especially when operating at a large scale or under tight hardware and latency requirements.
How LEAF works
LEAF is a knowledge distillation technique that takes a larger "teacher" model and outputs a smaller version of it—a "student" model.
What’s innovative about LEAF is that the student models it produces are compatible with their larger teachers, meaning that the text embeddings produced by the two are interoperable.
This is achieved by a training scheme that has, as its sole goal, the objective of making the student model approximate the embedding space produced by the teacher model. Initial works [1] proposing distillation strategies attempted to maximize the number of internals of teacher and student models to be aligned. This included aligning attention matrices as well as hidden states of all the layers and all attention heads of the student. Later works [2, 3] realized that better results could be achieved by avoiding excessive alignment of all layers by, e.g., focusing on the last layer of the Transformer backbone only. We take this lesson further and propose to align only the outputs of the teacher and the student. Namely, we propose to use the following L2 loss on the approximation error between the student and teacher’s output embeddings:

Earlier this year, we published details about the model architecture, training data, and training regime in our technical report [4].
Model compatibility unlocks new flexible asymmetric architectures in which, for example, documents can be embedded with larger and more expensive models, while queries can be encoded by local, fast LEAF models, as shown in Figure 1.
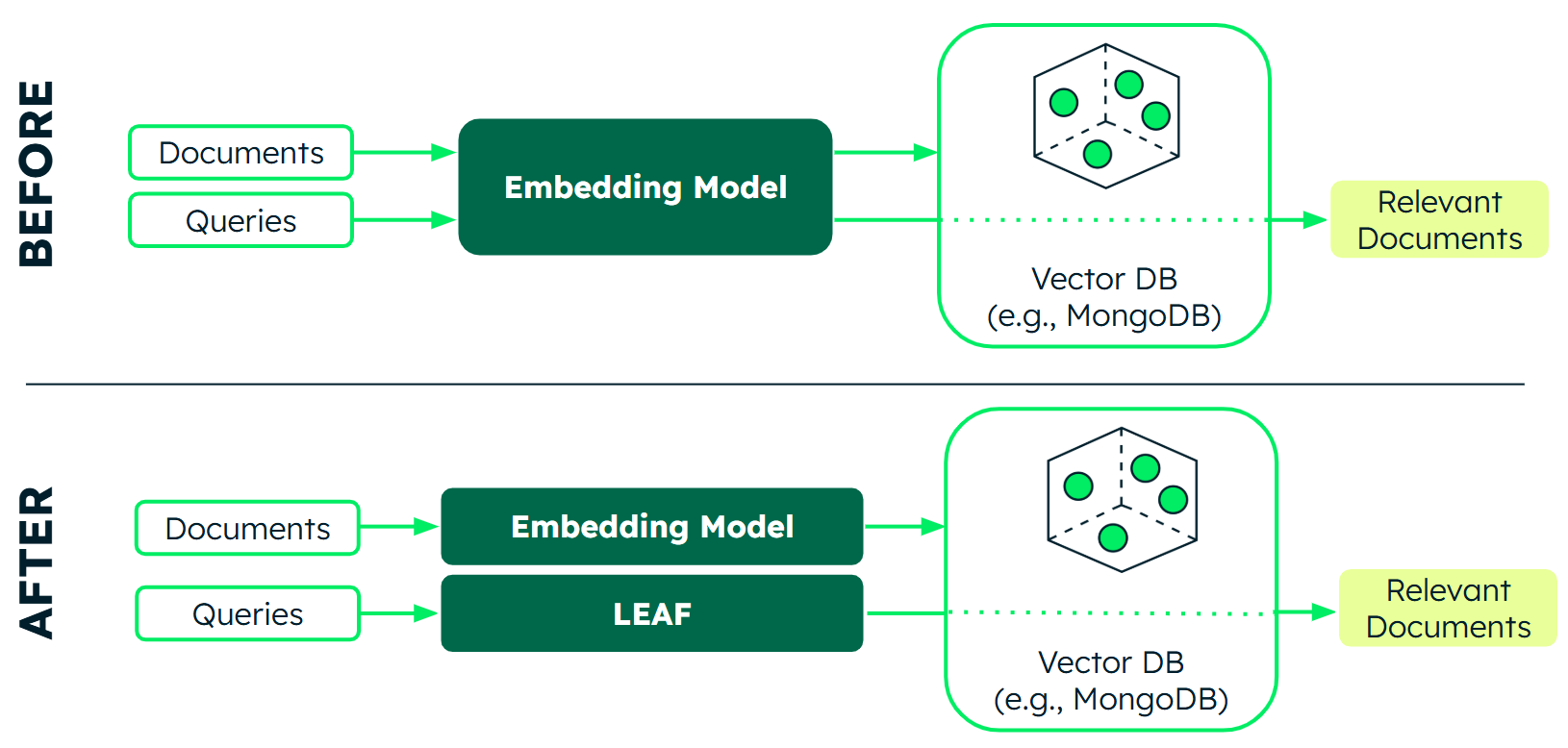
Further key advantages of LEAF:
- No need for labeled data. With LEAF, obtaining training data is extremely simple. This is in contrast to traditional training techniques based on contrastive loss, which require so-called judgments and hard negatives.
- Modest training infrastructure requirements. While previous methods prefer or even require working with large batch sizes—meaning they need a cluster of GPUs to train—LEAF favors small batches. As a consequence, we were able to train our distillations on a single A100 GPU.
- Automatic inheritance of advanced features. LEAF models automatically inherit properties like MRL and robustness to output quantization from the teacher, without explicitly training for them.
Below we demonstrate that LEAF can produce models retaining up to 97% of their teacher’s performance, while being 5×–15× smaller and 7×–24× faster.
Two models, two state‑of‑the‑art results
To demonstrate LEAF in action, we’re releasing two new compact, best-in-class text embedding models, both available on Hugging Face under the Apache 2.0 license.
mdbr-leaf-ir is specifically designed for Information Retrieval (IR) tasks, such as the retrieval stage of RAG pipelines. It currently ranks #1 on the public MTEB leaderboards of the BEIR and RTEB benchmarks for models with ≤100M parameters. It has been distilled from snowflake-arctic-embed-m-v1.5.
Table 1. mdbr-leaf-ir scores against comparison models on the BEIR benchmark.
mdbr-leaf-mt, on the other hand, excels at general purpose tasks like classification, clustering, sentence similarity and summarization. It currently ranks #1 on the public leaderboard for the MTEB v2 (Eng) benchmark for models with ≤30M parameters. It has been distilled from mxbai-embed-large-v1.
Table 2. mdbr-leaf-mt scores against comparison models on the MTEB v2 (Eng) benchmark.
These models are an excellent choice in deployment scenarios where a GPU is not available or is not cost-effective. This includes CPU-only servers, as well as IoT and mobile devices. Since they run on your hardware, they do not require an internet connection.
Typical throughputs obtained on a 2vCPUs instance are 120 queries/sec and 20 docs/sec, respectively. The memory footprint of the full-precision versions is 87MB. Several quantizations are available to further increase throughput and reduce memory footprint.
Besides offering state-of-the-art retrieval performance for their size, both models are equipped with MRL and robustness to output quantization. They can be fine‑tuned on domain‑specific data to further boost performance.
They are well-suited to work with a vector DB (such as MongoDB Vector Search in Community Edition) to power your next AI-enabled application.
Next Steps
Try it and learn more!
Both mdbr-leaf-ir and mdbr-leaf-mt are publicly available today on Hugging Face under Apache‑2.0. They can be used via sentence_transformers, Transformers.js, and Transformers.
We encourage the research community to also check out our proposed training paradigm, which is detailed in our technical report [4]. Let us know what you think!
References
[1] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang
Wang, and Qun Liu. TinyBERT: Distilling BERT for Natural Language Understanding. In Findings of the Association for Computational Linguistics: EMNLP, 2020.[2] Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. Advances in neural information processing systems, 2020.
[3] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. https://arxiv.org/abs/1910.01108, 2020.
[4] Vujanic, Robin, and Thomas Rueckstiess. "LEAF: Knowledge Distillation of Text Embedding Models with Teacher-Aligned Representations." arXiv preprint arXiv:2509.12539 (2025).
Hugging Face Models: mdbr-leaf-ir and mdbr-leaf-mt
*In throughput terms (documents or queries per second), measured on a EC2 i3.large instance. Details are in the technical report.