For developers coming from a relational database background, the concept of a "join" is a fundamental part of the data model. But in a document database like MongoDB, this approach is often an anti-pattern. While MongoDB offers the $lookup aggregation stage, relying on it for every read operation can lead to performance bottlenecks and create fragile architectures.
From relational thinking to document thinking
In relational databases, query optimization often revolves around minimizing or optimizing joins. In a normalized relational schema, data is split into multiple related tables, and the optimizer’s job is to figure out how to pull that data together efficiently at query time. Because joins are built into the relational model and cost is reduced through indexing strategies, database architects spend a lot of effort making joins fast.
In MongoDB—and most NoSQL document databases—the philosophy is different: it is perfectly acceptable, and often recommended, to duplicate data when it serves an application's query patterns. Instead of joining related entities on every read, MongoDB encourages data models where data that is accessed together is stored together in the same document, pre-aggregated or denormalized to match access needs.
Avoiding excessive joins (or $lookup stages) isn’t a limitation—it’s a deliberate design choice that trades some extra storage for dramatically reduced query latency, simpler query logic, and predictable performance at scale. This is why patterns like materializing “query‑optimized” collections, whether batch‑computed or stream‑updated, are so powerful in the MongoDB world: instead of computing the relationship at read time, you store the relationship in exactly the form your application needs.
In the past, a common solution for generating data summaries was to precompute and store them (often called “materializing” the data) through a scheduled batch job. This pre-aggregated data was useful for reports but suffered from data staleness, making it unsuitable for real-time applications. So, how do you handle complex data relationships and serve real-time insights without a heavy reliance on expensive joins or stale, batch-processed data? The answer lies in a modern approach that leverages event-driven architecture and a powerful pattern: continuously updated, query‑optimized collections (essentially materializing enriched data in real time) with MongoDB Atlas Stream Processing.
The core problem: Why we avoid joins in MongoDB
MongoDB is built on the principle that "data that is accessed together should be stored together." This means that denormalization is not only acceptable but is often the recommended practice for achieving high performance. When data for a single logical entity is scattered across multiple documents, developers often face two key problems:
1. The "fragmented data" problem
As applications evolve, their data models can become more complex. What starts as a simple, one-document-per-entity model can turn into a web of interconnected data. To get a complete picture of an entity, your application must perform multiple queries or a $lookup to join these pieces of information. If you need to update this complete entity, you're faced with the complexity of a multi-document transaction to ensure data consistency. This overhead adds latency to both read and write operations, slowing down your application and complicating your code.
The diagram below illustrates this problematic, join-heavy architecture, which we consider an anti-pattern in MongoDB.
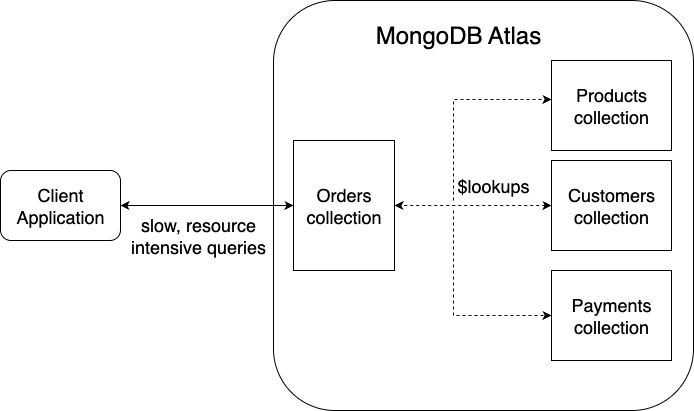
2. The "microservice" problem
In a microservice architecture, each service often owns its own database, oftentimes running in its own MongoDB cluster, promoting autonomy and decoupling. But this creates a new challenge for data sharing. One service might need data owned by another, and the classic join approach doesn't work. While federated databases might seem like a solution for joining data across different clusters, they are typically designed for ad-hoc queries and analytics rather than high-performance, real-time application queries. MongoDB's $lookup stage has a crucial constraint: it cannot work across different databases, which is a common scenario in this architecture. This forces developers into inefficient synchronous API calls or complex, manual data synchronization pipelines.
The solution: Enabling CQRS with event processing
The answer to these problems—the reliance on joins, fragmented data, and microservice coupling—lies in an event-driven architecture paired with the power of materialized views. This architectural pattern is a well-established concept known as Command Query Responsibility Segregation (CQRS).
At its core, CQRS separates a system's "Command" side (the write model) from its "Query" side (the read model).
Commands are actions that change the state of the system, such as CreateOrder or UpdateProduct.
Queries are requests that retrieve data, like GetOrderDetails.
By embracing this pattern, your core application can handle commands with a transactional, write-focused data model. For all your read-heavy use cases, you can build separate, highly optimized read models.
This is where event processing becomes the crucial link. When a command is executed, your write model publishes an event to a stream (e.g., OrderCreated). This event is an immutable record of what happened. MongoDB Atlas's native are the perfect tool for generating this event stream directly from your primary data collection.
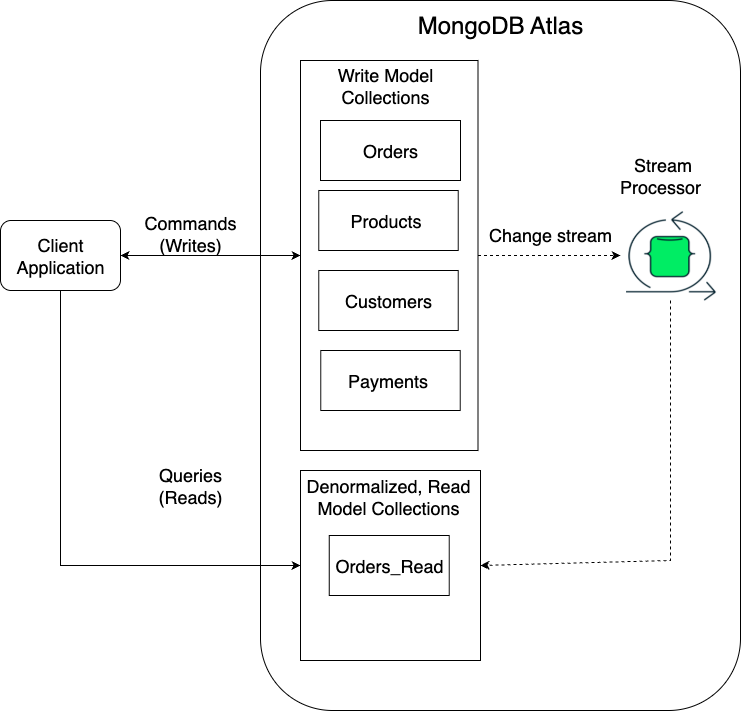
A separate process—our stream processor—continuously listens to this event stream. It consumes the OrderCreated event, along with any other related events such as changes in Product, Customers and Payments, and uses this information to build a denormalized, query-optimized collection — effectively materializing enriched data for fast queries. This view becomes the query side of your CQRS pattern.
As you can see in the diagram below, this modern CQRS architecture directly solves the problems of fragmentation and joins by separating the read and write concerns entirely.
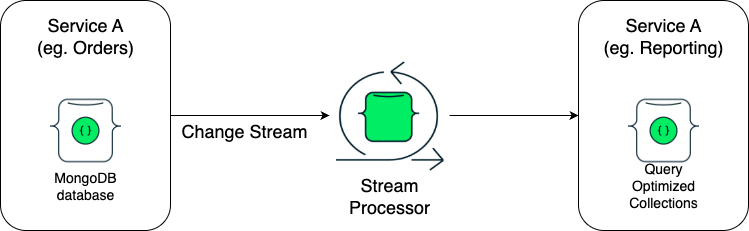
For a microservice architecture, here is what the CQRS pattern would look like:
The tangible benefits: Why this approach matters
Embracing this event-driven, real-time data materialization pattern is not just about elegant architecture—it provides real, measurable benefits for your applications and your bottom line.
Blazing-fast queries: Since the data is already pre-joined and shaped to your query requirements, there is no need for expensive, real-time $lookup or aggregation operations. Queries against this continuously updated, query‑optimized collection become simple, fast reads, resulting in significantly lower latency and a more responsive user experience.
Reduced resource consumption: By offloading the computational work of joins and aggregations to the continuous stream processor, you dramatically reduce the workload on your primary operational database. The highly efficient queries against the materialized view consume far less CPU and RAM.
More economical deployments: The reduced resource consumption translates directly into more economical deployments. Since your primary database is no longer burdened with complex read queries, you can often run on smaller, less expensive instances. You are trading more costly CPU and RAM for cheaper storage, which is a highly favorable economic trade-off in modern cloud environments.
Improved performance predictability: With a consistent and low-resource query model, you eliminate the performance spikes and variability that often come with complex, on-demand queries. This leads to a more stable and predictable application load, making it easier to manage and scale your services.
How MongoDB Atlas Stream Processing can help
Building a custom stream processing pipeline from scratch can be complex and expensive, requiring you to manage multiple systems like Apache Flink or Kafka Streams.
MongoDB Atlas Stream Processing is a fully managed service that brings real-time stream processing directly into the MongoDB ecosystem. It takes on the responsibility of the "Query Side" of your CQRS architecture, allowing you to implement this powerful pattern without the operational overhead.
With MongoDB Atlas Stream Processing, you can use a continuous aggregation pipeline to:
Ingest events from a MongoDB Change Stream or an external source like Apache Kafka.
Transform and enrich the data on the fly.
Continuously materialize the data into a target collection using the $merge stage. Crucially, $merge can either create a new collection or continuously update an existing one. It intelligently inserts new documents including starting with an initial sync, replaces or updates existing ones, and even deletes documents from the target collection when a corresponding deletion event is detected in the source stream.
The diagram below provides a detailed look at the stream processing pipeline, showing how data flows through various stages to produce a final, query-optimized target collection.
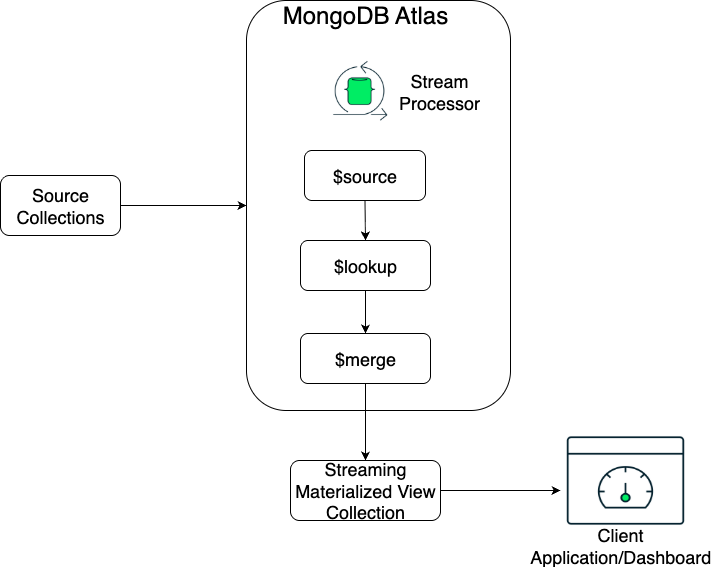
This gives you an elegant way to implement a CQRS pattern, ensuring your read and write models are decoupled and optimized for their specific tasks, all within the integrated MongoDB Atlas platform. It allows you to get the best of both worlds: a clean, normalized model for your writes and a high-performance, denormalized model for all your reads, without the manual complexity of a separate ETL process. It’s a modern way to apply the core principles of MongoDB data modeling at scale, even across disparate databases.
By moving away from join-heavy query patterns and embracing real-time, query‑optimized collections with MongoDB Atlas Stream Processing, you can dramatically cut query latency, reduce resource usage, and build applications that deliver consistent, lightning‑fast experiences at scale. Whether you’re modernizing a monolith, scaling microservices, or rethinking your data model for performance, Atlas Stream Processing makes it easy to adopt a CQRS architecture without the overhead of managing complex stream processing infrastructure yourself.
Start building your continuously updated, high-performance read models today with MongoDB Atlas Stream Processing.