If you can’t find it, it might as well not exist — that’s the takeaway for all organizations providing content or products to their users. It’s become a practical requirement to allow ways to search for and discover data records, or “documents,” amongst a large collection.
Thus, in this highly competitive world, applications must have search functionality so users can find what they are looking for as easily as possible, or they will assume you don’t have it and visit your competitors.
Implementing a great search feature deserves attention to detail. How lenient is the system to typos or voice misinterpretations? Can it provide context-sensitive guided/faceted navigation? Are matches highlighted for clear visibility? And ultimately, are the results relevant to the user’s query?
Beyond end-user keyword search, we also want to be able to perform analytics of our query and system logs so that we can make the right business decisions. Analytics encompasses security auditing and anomaly detection too. And hence, performing analytics on the data easily is another important aspect of building any software today.
What is Elasticsearch?
The Elasticsearch search engine provides powerful, scalable search and analytics capabilities for all types of data, including structured and unstructured text, numerics, vectors, and geospatial shapes and coordinates. It is used for full-text search, structured search, analytics, and many forms of data exploration. The code itself lives within an open-source project and the company behind it provides a fully supported commercial offering for on-premise deployment or SaaS hosting.
Built upon the well-known Apache Lucene search engine library, Elasticsearch is able to quickly provide search results over large volumes of data. Lucene indexes content into, primarily, an inverted-index structure, which facilitates quickly matching queries to content. An inverted index is built by tokenizing text into terms (which are usually single words) and building a lexicographically ordered data structure, as in the diagram below.
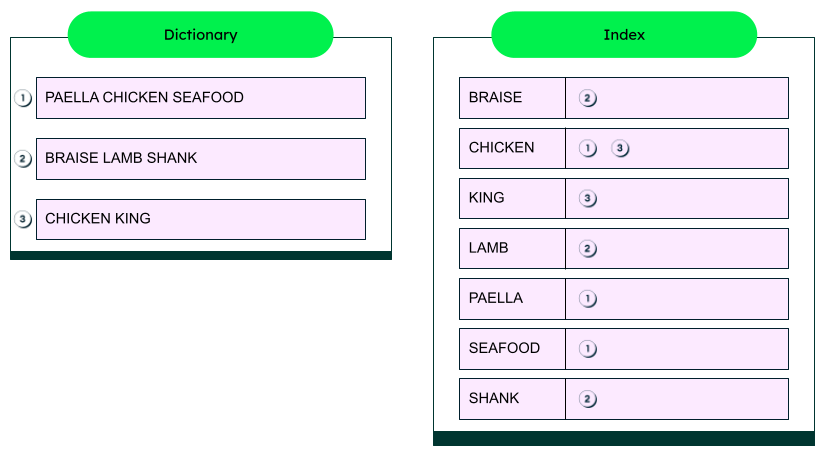
Lucene, and thus Elasticsearch, supports the majority of written/textual languages and many query types, including fuzzy and partial matching, boolean operators, phrases and proximity, numerical ranges, and geospatial proximity. A key differentiating feature of Elasticsearch, again thanks to its Lucene heart, is relevancy ranking. Results are scored based on how well they match the query, which may also include boosting criteria to provide the best documents for the query, user, and context.
Relevancy scoring includes content-based factors such as term frequency (how many times the word occurs in a product description, for example) and document frequency (how many products in your catalog contain the query term). The more unique the term is, the more weight it carries, and likewise, the more common a term is, the less weight it carries. The length of the matching field is also a content-based scoring factor, where matches in shorter (title-like) fields carry more weight than the same word in a longer (description-like) field.
The Elasticsearch ecosystem includes other complementary tools: Logstash, Kibana, and Beats. These tools, known as the Elastic Stack and originally called the ELK stack (Elasticsearch, Logstash, and Kibana), provide a powerful combination of tools for ingesting and visualizing large volumes of data.
Logstash is used to collect, parse, transform, enrich, and index logs from various sources, including system logs, web server logs, application logs, and event logs.
Kibana is an open-source data visualization tool that allows you to interact with data in Elasticsearch through charts, graphs, and maps that can be combined into custom dashboards that help you understand complex datasets.
Beats provides lightweight data shipping agents installed on your servers, whereas Logstash provides a more sophisticated framework for input, filtering, and output plugins.
Why use Elasticsearch?
Developers have flocked to Elasticsearch because it combines the power of Lucene behind a scalable, distributed infrastructure with a developer-centric API. Using JSON as the ubiquitous format for all interactions, a robust ecosystem of client-side libraries is available.
Along with the designed-for-developers APIs, Elasticsearch defaults to accepting and indexing your data without requiring up-front schema design, making it easy to get started and straightforward to configure as your application grows. With this flexibility, different types of content can be indexed into a single collection (sometimes referred to as “multi-type”). For example, content from a relational database could be indexed alongside documents crawled from Google Drive and logging events extracted from log files. Or, each type of data could be indexed into separate collections and queried independently or searched together (called “multi-index”).
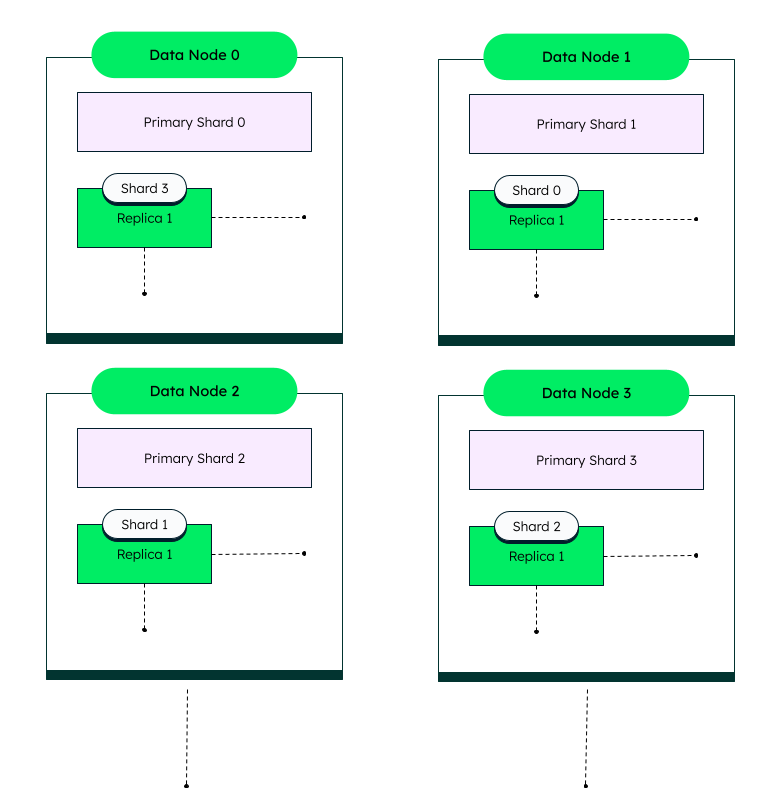
Elasticsearch can scale horizontally to handle massive amounts of content and provide fault tolerance and heavy query loads. Horizontal scaling is achieved by sharding collections, breaking the collection into smaller indexes deployed across multiple nodes in a cluster. The diagram below illustrates data nodes that distribute host primary and replica shards across an Elasticsearch cluster.