Add Memory to Your JavaScript RAG Application Using MongoDB and LangChain





Rate this tutorial


AI applications with generative AI capabilities, such as text and image generation, require more than just the base large language models (LLMs). This is because LLMs are limited to their parametric knowledge, which can be outdated and not context-specific to a user query. The retrieval-augmented generation (RAG) design pattern solves the problem experienced with naive LLM systems by adding relevant information and context retrieved from an information source, such as a database, to the user's query before obtaining a response from the base LLM. The RAG architecture design pattern for AI applications has seen wide adoption due to its ease of implementation and effectiveness in grounding LLM systems with up-to-date and relevant data.
For developers creating new AI projects that use LLMs and this kind of advanced AI, it's important to think about more than just giving smart answers. Before they share their RAG-based projects with the world, they need to add features like memory. Adding memory to your AI systems can help by lowering costs, making them faster, and handling conversations in a smarter way.
Chatbots that use LLMs are now a regular feature in many online platforms, from customer service to personal assistants. However, one of the keys to making these chatbots more effective lies in their ability to recall and utilize previous conversations. By maintaining a detailed record of interactions, AI systems can significantly improve their understanding of the user's needs, preferences, and context. This historical insight allows the chatbot to offer responses that are not only relevant but also tailored to the individual user, enhancing the overall user experience.
Consider, for example, a customer who contacts an online bookstore's chatbot over several days, asking about different science fiction novels and authors. On the first day, the customer asks for book recommendations based on classic science fiction themes. The next day, they return to ask about books from specific authors in that genre. If the chatbot keeps a record of these interactions, it can connect the dots between the customer's various interests. By the third interaction, the chatbot could suggest new releases that align with the customer's demonstrated preference for classic science fiction, even recommending special deals or related genres the customer might not have explored yet.
This ability goes beyond simple question-and-answer dynamics; it creates a conversational memory for the chatbot, making each interaction more personal and engaging. Users feel understood and valued, leading to increased satisfaction and loyalty. In essence, by keeping track of conversations, chatbots powered by LLMs transform from impersonal answering machines into dynamic conversational partners capable of providing highly personalized and meaningful engagements.
MongoDB Atlas Vector Search and the new LangChain-MongoDB integration make adding these advanced data handling features to RAG projects easier.
What’s covered in this article:
- How to add memory and save records of chats using LangChain and MongoDB
- How adding memory helps in RAG projects
This article outlines how to add memory to a JavaScript-based RAG application. See how it’s done in Python and even add semantic caching!
You may be used to notebooks that use Python, but you may have noticed that the notebook linked above uses JavaScript, specifically Deno.
To run this notebook, you will need to install Deno and set up the Deno Jupyter kernel. You can also follow the instructions.
Because Deno does not require any packages to be “installed,” it’s not necessary to install anything with npm.
Here is a breakdown of the dependencies for this project:
- mongodb: official Node.js driver from MongoDB
- nodejs-polars: JavaScript library for data analysis, exploration, and manipulation
- @langchain: JavaScript toolkit for LangChain
- @langchain/openai: JavaScript library to use OpenAI with LangChain
- @langchain/mongodb: JavaScript library to use MongoDB as a vector store and chat history store with LangChain
You’ll also need an OpenAI API key since we’ll be utilizing OpenAI for embedding and base models. Save your API key as an environment variable.
For this tutorial, we’ll use a free tier cluster on Atlas. If you don’t already have an account, register, then follow the instructions to deploy your first cluster.
We’re going to use MongoDB’s sample dataset called embedded_movies. This dataset contains a wide variety of movie details such as plot, genre, cast, and runtime. Embeddings on the full_plot field have already been created using OpenAI’s
text-embedding-ada-002 model and can be found in the plot_embedding field.After loading the dataset, we’ll use Polars to convert it into a DataFrame, which will allow us to manipulate and analyze it easily.
The code above executes the following operations:
- Import the nodejs-polars library for data management.
- fetch the sample_mflix.embedded_movies.json file directly from HuggingFace.
- The df variable parses the JSON into a DataFrame.
- The DataFrame is cleaned up to keep only the records that have information in the fullplot field. This guarantees that future steps or analyses depending on the fullplot field, like the embedding procedure, are not disrupted by any absence of data.
- Additionally, the plot_embedding column within the DataFrame is renamed to embedding. This step is necessary since LangChain requires an input field named “embedding.”
After finishing the steps in this part, we end up with a complete dataset that serves as the information base for the chatbot. Next, we’ll add the data into our MongoDB database and set up our first RAG chain using it.
We’ll start by creating a simple RAG chain using LangChain, with MongoDB as the vector store. Once we get this set up, we’ll add chat history to optimize it even further.
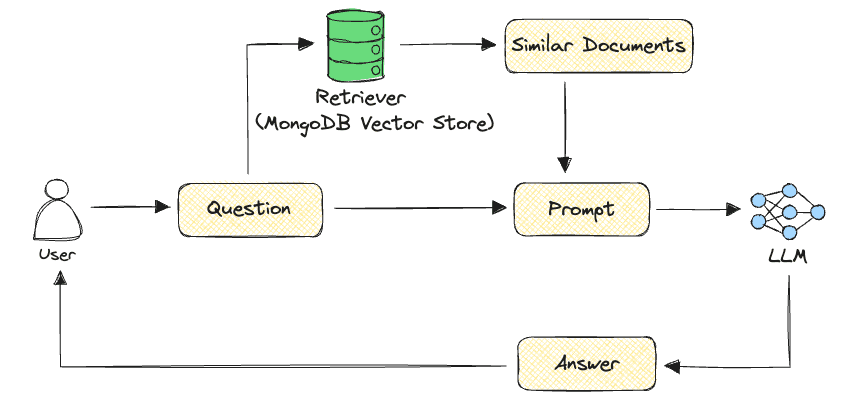
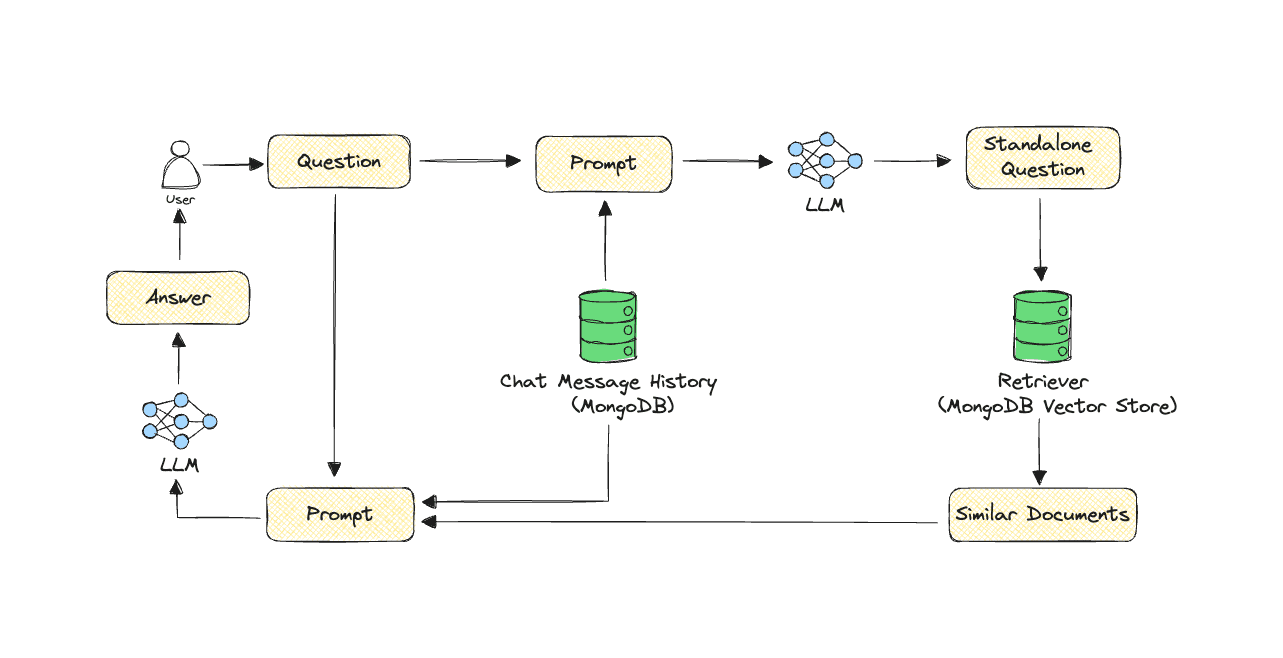
In this naive RAG chain, the user’s question is converted to an embedding, and then relevant documents from the MongoDB vector store can be effectively searched using vector search. This additional context is then passed along to the LLM in the form of a prompt, which generates an answer to the original question utilizing the additional context.
First, we’ll need to set up our MongoDB database connection.
Here, we initialize our MongoDB client using the official MongoDB Node.js driver. (Yes! The Node.js driver works in Deno! 😀) Next, we define our database variables, such as the name, collection, and index name. Then, we combine them to get our collection.
You might be wondering where this database and collection come from. Even though you may be starting with a blank cluster, these will be automatically created for you if they do not exist.
Now, it’s time to ingest the dataset into our database collection.
Ideally, we’ll only run this ingest once, but just in case, we are clearing out the collection by calling
deleteMany({}) to prevent any data duplication.To insert the data, we convert the DataFrame into records and pass those into our
insertMany() method. I don’t want to log all of the returned IDs (1500), so I’m omitting those and only returning the rest of the results.If all goes well, you should see this:
Before we begin building our vector store for our RAG chain, we’ll need to create a vector search index in MongoDB Atlas. This is what enables our RAG application to query semantically similar records to use as additional context in our LLM prompts.
Be sure to create your vector search index on the
data collection and name it vector_index. Here is the index definition you’ll need:NOTE: We set
numDimensions to 1536 because we use OpenAI’s text-embedding-ada-002 model to create embeddings.Now, we can start constructing the vector store for our RAG chain.
We’ll use
OpenAIEmbeddings from LangChain and define the model used. Again, it’s the text-embedding-ada-002 model, which was used in the original embeddings of this dataset.Next, we define our configuration by identifying the collection, index name, text key (full-text field of the embedding), and embedding key (which field contains the embeddings).
Then, pass everything into our
MongoDBAtlasVectorSearch() method to create our vector store.Now, we can “do stuff” with our vector store. We need a way to return the documents that get returned from our vector search. For that, we can use a retriever. (Not the golden kind.)
We’ll use the retriever method on our vector store and identify the search type and the number of documents to retrieve represented by k.
This will return the five most similar documents that match our vector search query.
The final step is to assemble everything into a RAG chain.
KNOWLEDGE: In LangChain, the concept of chains refers to a sequence that may include interactions with an LLM, utilization of a specific tool, or a step related to processing data. To effectively construct these chains, it is advised to employ the LangChain Expression Language (LCEL). Within this structure, each part of a chain is called a Runnable, allowing for independent operation or streaming, separate from the chain's other components.
Here’s the breakdown of the code above:
- retrieve: Utilizes the user's input to retrieve similar documents using the retriever. The input (question) also gets passed through using a RunnablePassthrough().
- prompt: ChatPromptTemplate allows us to construct a prompt with specific instructions for our AI bot or system, passing two variables: context and question. These variables are populated from the retrieve stage above.
- model: Here, we can specify which model we want to use to answer the question. The default is currently gpt-3.5-turbo if unspecified.
- naiveRagChain: Using a RunnableSequence, we pass each stage in order: retrieve, prompt, model, and finally, we parse the output from the LLM into a string using StringOutputParser().
It’s time to test! Let’s ask it a question. We’ll use the invoke() method to do this.
That was a simple, everyday RAG chain. Next, let’s take it up a notch and implement persistent chat message history. Here is what that could look like.
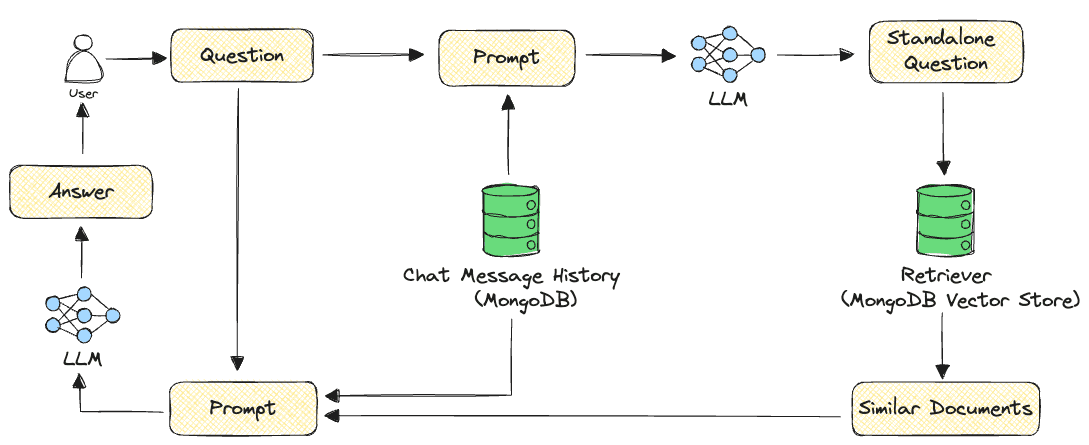
First, we use the question from the user and any chat history we have to make a single question that helps us get documents from the vector store. Then, we take the user's question, the documents we found, and the chat history, and put them all into an LLM to come up with an answer.
Let’s construct another chain that gets the chat history separated by sessions from MongoDB.
We’ll define our chat history collection and call it history. I know — unique. 😀
Next, we’ll use the MongoDBChatMessageHistory method to define a session. We pass it the history collection along with a unique session identifier. Then, for good measure, we’ll clear the history in case we run this multiple times for testing. The proceeding functions will add to this history.
Next, we’ll define the chain. This one will take the chat message history and a follow-up question as input and rephrase it into a standalone question.
Here, we’ll construct another ChatPromptTemplate similar to the one before. This time, we also include the history as a MessagesPlaceholder.
The retriever uses RunnablePassthrough.assign(...) to add additional arguments before passing on to the next stage. Here, we are adding the context from the retriever to the user input before continuing on to the prompt.
This prompt contains the user’s question, the retrieved context, and the session's chat history.
In the last step, we put together a RAG chain and placed it inside RunnableWithMessageHistory. This is a type of Runnable that handles the history of chat messages for another Runnable, and this includes making any updates.
In the RunnableWithMessageHistory method, we include the following:
- runnable: the base runnable
- getMessageHistory: the function used to get chat message history
- inputMessagesKey: the key used to identify the input message
- historyMessagesKey: the key used to identify the message history
Now, let’s test the final implementation:
When we call the
invoke command, we specify the question and sessionId. These must correspond to the keys set earlier.The journey of advancing AI from simple question-and-answer models to systems that can remember and use past conversations is groundbreaking. Integrating MongoDB and LangChain into JavaScript RAG applications significantly pushes the boundary forward, making AI responsive and genuinely insightful. These technologies enable developers to build AI systems that understand and grow smarter with each interaction, offering a personalized experience reminiscent of human interaction.
However, creating a compelling modern application extends beyond merely setting up a basic RAG framework. As we've explored, enhancing how applications communicate with users by personalizing responses and tracking conversation history is crucial. These elements should be considered from the onset, even during the preliminary proof of concept phase.
This guide has simplified the process of incorporating memory into RAG applications through MongoDB and LangChain. It provided a clear, step-by-step approach to setting up a RAG application, including database creation, collection and index configuration, and utilizing LangChain to construct a RAG chain and application.
For further exploration and to access all the code examples mentioned in this guide, you can visit the provided repository.
- What is retrieval-augmented generation (RAG)?RAG is a way of making big computer brain models (like LLMs) smarter by giving them the latest and most correct information. This is done by mixing in extra details from outside the model's built-in knowledge, helping it give better and more right answers.
- How does integrating memory and chat history enhance RAG applications?Adding memory and conversation history to RAG apps lets them keep and look back at past messages between the large language model (LLM) and people. This feature makes the model more aware of the context, helping it give answers that fit the current question and match the ongoing conversations flow. By keeping track of a chat history, RAG apps can give more personal and correct answers, greatly making the experience better for the user and improving how well the app works overall.
- How does MongoDB Atlas support RAG applications?MongoDB's vector search capabilities enable RAG applications to become smarter and provide more relevant responses. It enhances memory functions, streamlining the storage and recall of conversations. This boosts context awareness and personalizes user interactions. The result is a significant improvement in both application performance and user experience, making AI interactions more dynamic and user-centric.
- What benefits does the LangChain-MongoDB integration offer?This setup makes it easier to include meaning-based memory in RAG apps. It allows for the easy handling of past conversation records through MongoDB's strong vector search tools, leading to a better running app and a nicer experience for the user.