Building AI Graphs with Rivet and MongoDB Atlas Vector Search to Power AI Applications



Cai GoGwilt, Andrew Rothwell, Pavel Duchovny10 min read • Published Dec 13, 2023 • Updated Apr 02, 2024





Rate this tutorial


In the rapidly advancing realm of database technology and artificial intelligence, the convergence of intuitive graphical interfaces and powerful data processing tools has created a new horizon for developers and data scientists. MongoDB Compass, with its rich features and user-friendly design, stands out as a flagship database management tool. The integration of AI capabilities, such as those provided by Rivet AI's graph builder, pushes the envelope further, offering unprecedented ease and efficiency in managing and analyzing data.
This article delves into the synergy between MongoDB Atlas, a database as a service, and Rivet AI’s graph builder, exploring how this integration facilitates the visualization and manipulation of data. Rivet is a powerful tool developed by Ironclad, a partner that together with MongoDB wishes to make AI flows as easy and intuitive as possible.
We will dissect the high-level architecture that allows users to interact with their database in a more dynamic and insightful manner, thereby enhancing their ability to make data-driven decisions swiftly.
The high-level architecture of the MongoDB Atlas and Rivet AI graph builder integration is centered around a seamless workflow that caters to both the extraction of data and its subsequent analysis using AI-driven insights.
Data extraction and structuring: At the core of the workflow is the ability to extract and structure data within the MongoDB Atlas database. Users can define and manipulate documents and collections, leveraging MongoDB's flexible schema model. The MongoDB Compass interface allows for real-time querying and indexing, making the retrieval of specific data subsets both intuitive and efficient.
AI-enhanced analysis: Once the data is structured, Rivet AI’s graph builder comes into play. It provides a visual representation of operations such as object path extraction, which is crucial for understanding the relationships within the data. The graph builder enables the construction of complex queries and data transformations without the need to write extensive code.
Vectorization and indexing: A standout feature is the ability to transform textual or categorical data into vector form using AI, commonly referred to as embedding. These embeddings capture the semantic relationships between data points and are stored back in MongoDB. This vectorization process is pivotal for performing advanced search operations, such as similarity searches and machine learning-based predictions.
Interactive visualization: The entire process is visualized interactively through the graph builder interface. Each operation, from matching to embedding extraction and storage, is represented as nodes in a graph, making the data flow and transformation steps transparent and easy to modify.
Search and retrieval: With AI-generated vectors stored in MongoDB, users can perform sophisticated search queries. Using techniques like k-nearest neighbors (k-NN), the system can retrieve documents that are semantically close to a given query, which is invaluable for recommendation systems, search engines, and other AI-driven applications.


Install Rivet: To begin using Rivet, visit the official Rivet installation page and follow the instructions to download and install the Rivet application on your system.
Obtain an OpenAI API key: Rivet requires an OpenAI API key to access certain AI features. Register for an OpenAI account if you haven't already, and navigate to the API section to generate your key.
Configure Rivet with OpenAI: After installing Rivet, open the application and navigate to the settings. Enter your OpenAI API key in the OpenAI settings section. This will allow you to use OpenAI's features within Rivet.

Install the MongoDB plugin in Rivet: Within Rivet, go to the plugins section and search for the MongoDB plugin. Install the plugin to enable MongoDB functionality within Rivet. This will involve entering your MongoDB Atlas connection string to connect to your database.

Connect Rivet to MongoDB Atlas: Once your Atlas Search index is configured, return to Rivet and use the MongoDB plugin to connect to your MongoDB Atlas cluster by providing the necessary connection string and credentials.
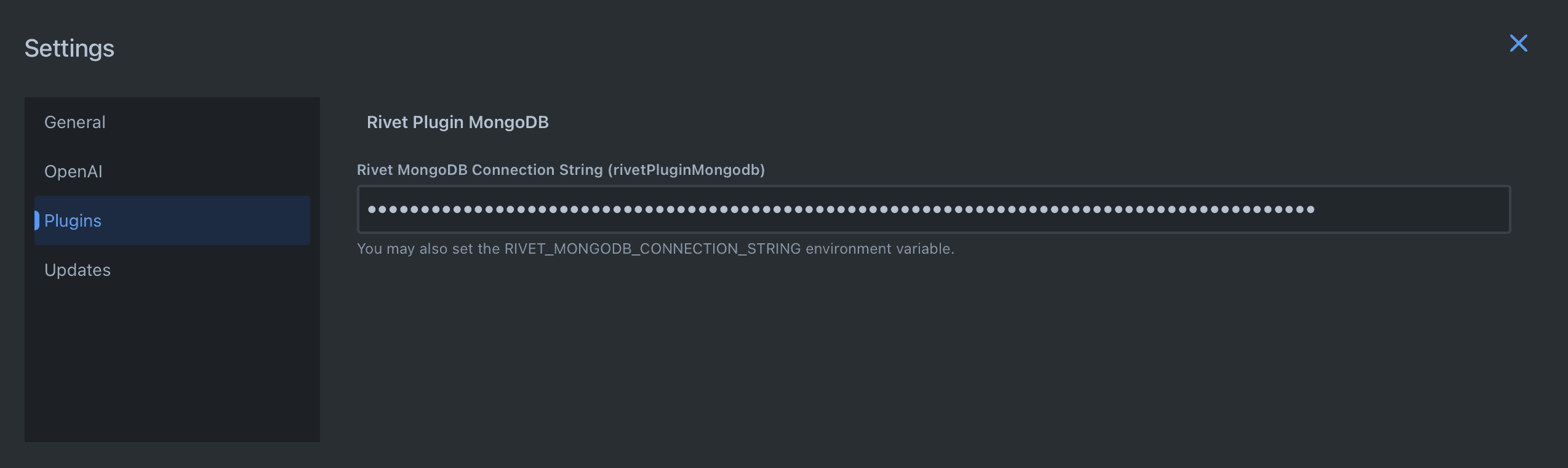
Get your Atlas cluster connection string and place under "Settings" => "Plugins":
Set up MongoDB Atlas Search: Log in to your MongoDB Atlas account and select the cluster where your collection resides. Use MongoDB Compass to connect to your cluster and navigate to the collection you want to index.
Create a search index in Compass: In Compass, click on the "Indexes" tab within your collection view. Create a new search index by selecting the "Create Index" option. Choose the fields you want to index, and configure the index options according to your search requirements.
Example:

Build and execute queries: With the setup complete, you can now build queries in Rivet to retrieve and manipulate data in your MongoDB Atlas collection using the search index you created.
By following these steps, you'll be able to harness the power of MongoDB Atlas Search with the advanced AI capabilities provided by Rivet. Make sure to refer to the official documentation for detailed instructions and troubleshooting tips.
In this example, we have a basic Rivet graph that processes data to be stored in a MongoDB database using the
rivet-plugin-mongodb. The graph follows these steps: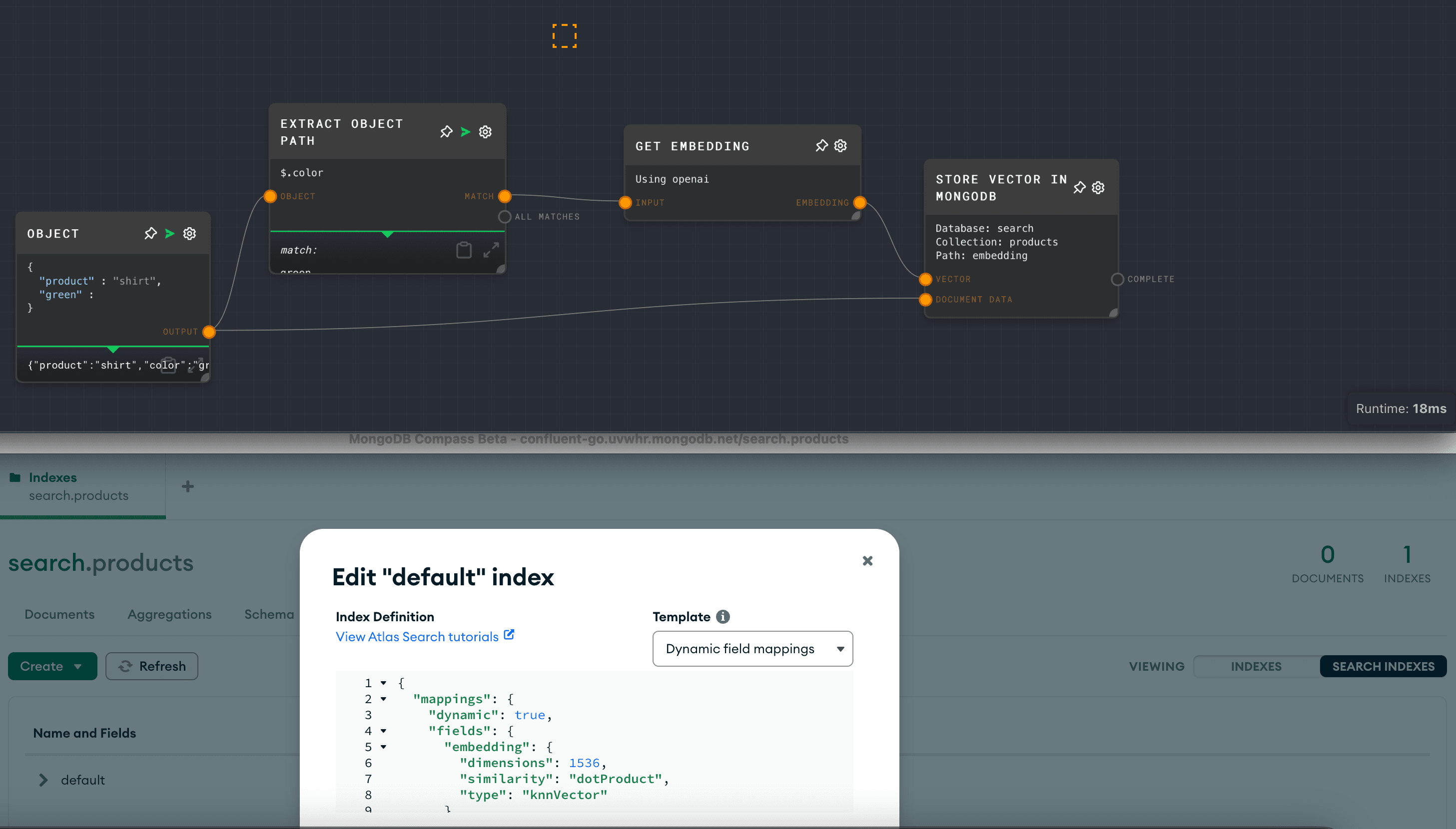
Extract object path: The graph starts with an object containing product information — for example, { "product": "shirt", "color": "green" }. This data is then passed to a node that extracts specific information based on the object path, such as $.color, to be used in further processing.
Get embedding: The next node in the graph, labeled 'GET EMBEDDING', uses the OpenAI service to generate an embedding vector from the input data. This embedding represents the extracted feature (in this case, the color attribute) in a numerical form that can be used for machine learning or similarity searches.
Store vector in MongoDB: The resulting embedding vector is then sent to the 'STORE VECTOR IN MONGODB' node. This node is configured with the database name search and collection products, where it stores the embedding in a field named embedding. The operation completes successfully, as indicated by the 'COMPLETE' status.
In MongoDB Compass, we see the following actions and configurations:
Index creation: Under the search.products index, a new index is created for the embedding field. This index is configured for vector searches, with 1536 dimensions and using the
DotProduct similarity measure. This index is of the type “knnVector,” which is suitable for k-nearest neighbors searches.Atlas Search index: The bottom right corner of the screenshot shows the MongoDB Compass interface for editing the “default” index. The provided JSON configuration sets up the index for Atlas Search, with dynamic field mappings.
With this graph and MongoDB set up, the Rivet application is capable of storing vector data in MongoDB and performing efficient vector searches using MongoDB's Atlas Search feature. This allows users to quickly retrieve documents based on the similarity of vector data, such as finding products with similar characteristics.
In this Rivet graph setup, we see the process of creating an embedding from textual input and using it to perform a vector search within a MongoDB database:

Text input: The graph starts with a text node containing the word "forest." This input could represent a search term or a feature of interest.
Get embedding: The 'GET EMBEDDING' node uses OpenAI's service to convert the text input into a numerical vector. This vector has a length of 1536, indicating the dimensionality of the embedding space.
Search MongoDB for closest vectors with KNN: With the embedding vector obtained, the graph then uses a node labeled “SEARCH MONGODB FOR CLOSEST VECTORS WITH KNN.” This node is configured with the following parameters:
This configuration indicates that the node will perform a k-nearest neighbor search to find the single closest vector within the products collection of the search database, comparing against the embedding field of the documents stored there.
Different colors and their associated embeddings. Each document contains an embedding array, which is compared against the input vector to find the closest match based on the chosen similarity measure (not shown in the image).
This section delves into a sophisticated workflow that leverages Rivet's graph processing capabilities, MongoDB's robust searching features, and the power of machine learning embeddings. To facilitate that, we have used a workflow demonstrated in another tutorial: AI Shop with MongoDB Atlas. Through this workflow, we aim to transform a user's grocery list into a curated selection of products, optimized for relevance and personal preferences. This complex graph workflow not only improves user engagement but also streamlines the path from product discovery to purchase, thus offering an enhanced grocery shopping experience.
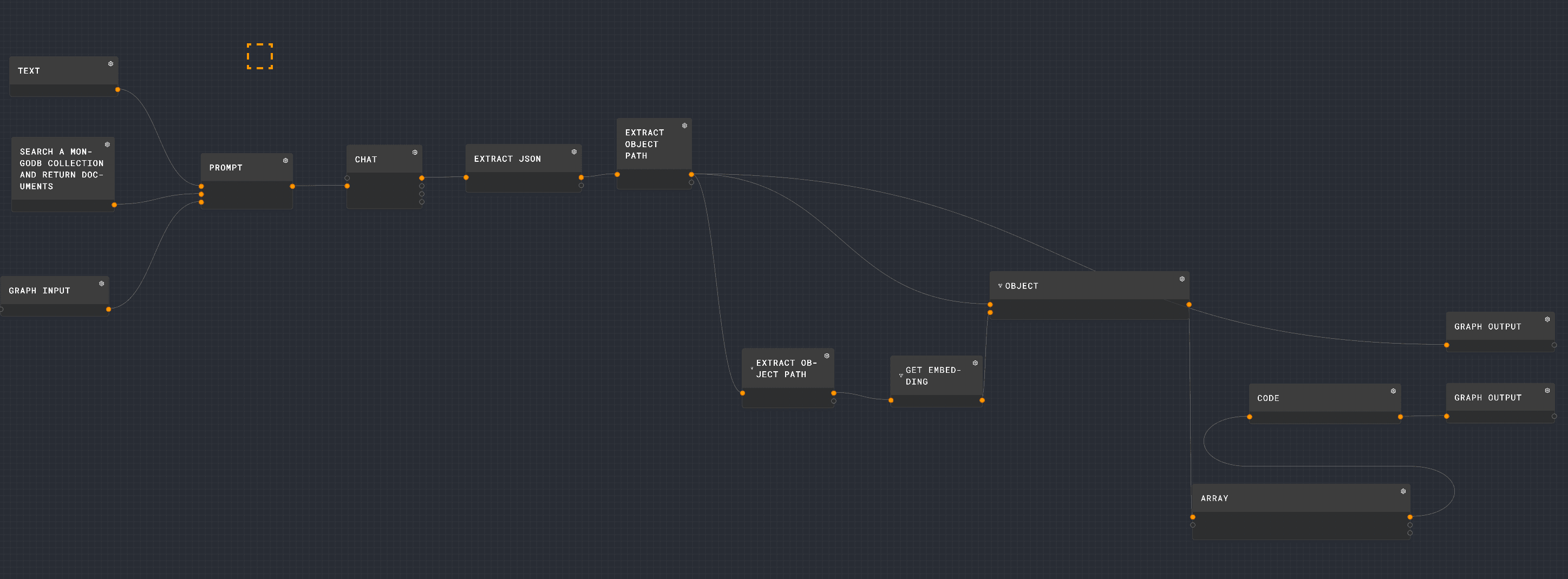
Graph input: The user provides input, presumably a list of items or recipes they want to purchase.
Search MongoDB collection: The graph retrieves the available categories as a bounding box to the engineered prompt.
Prompt creation: A prompt is generated based on the user input, possibly to refine the search or interact with the user for more details.
Chat interaction: The graph accesses OpenAI chat capabilities to produce an AI-based list of a structured JSON.
JSON extraction and object path extraction: The relevant data is extracted from the JSON response of the OpenAI Chat.
Embedding generation: The data is then processed to create embeddings, which are high-dimensional representations of the items.
Union of searches: These embeddings are used to create a union of $search queries in MongoDB, which allows for a more sophisticated search mechanism that can consider multiple aspects of the items, like similarity in taste, price range, or brand preference.
Graph output: The built query is outputted back from the graph.
Part 1: Input to MongoDB Search
 The user input is taken and used to query the MongoDB collection directly. A chat system might be involved to refine this query or to interact with the user. The result of the query is then processed to extract relevant information using JSON and object path extraction methods.
The user input is taken and used to query the MongoDB collection directly. A chat system might be involved to refine this query or to interact with the user. The result of the query is then processed to extract relevant information using JSON and object path extraction methods.
The user input is taken and used to query the MongoDB collection directly. A chat system might be involved to refine this query or to interact with the user. The result of the query is then processed to extract relevant information using JSON and object path extraction methods.Part 2: Embedding to union of searches

The extracted object from Part 1 is taken and an embedding is generated using OpenAI's service. This embedding is used to create a more complex MongoDB $search query. The code node likely contains the logic to perform an aggregation query in MongoDB that uses the generated embeddings to find the best matches. The output is then formatted, possibly as a list of grocery items that match the user's initial input, enriched by the embeddings.
This graph demonstrates a sophisticated integration of natural language processing, database querying, and machine learning embedding techniques to provide a user with a rich set of search results. It takes simple text input and transforms it into a detailed query that understands the nuances of user preferences and available products. The final output would be a comprehensive and relevant set of grocery items tailored to the user's needs.
This code snippet defines an Express.js route that handles
POST requests to the endpoint /aiRivetSearch. The route's purpose is to provide an AI-enhanced search functionality for a grocery shopping application, utilizing Rivet for graph operations and MongoDB for data retrieval.Here’s a step-by-step explanation:
Endpoint initialization:
- An asynchronous POST route /aiRivetSearch is set up to handle incoming search queries. MongoDB connection:
- The server establishes a connection to MongoDB using a custom connectToDb function. This function is presumably defined elsewhere in the codebase and handles the specifics of connecting to the MongoDB instance. Request handling:
- The server extracts the query variable from the request's body. This query is the text input from the user, which will be used to perform the search. Logging for debugging:
- The query and relevant environment variables, such as GRAPH_ID (which likely identifies the specific graph to be used within Rivet), are logged to the console. This is useful for debugging purposes, ensuring the server is receiving the correct inputs. Graph loading and execution:
- The server loads a Rivet project graph from a file in the server's file system.
- Using Rivet's runGraph function, the loaded graph is executed with the provided inputs (the user's query) and plugin settings. The settings include the openAiKey and the MongoDB connection string from environment variables. Response processing:
- The result of the graph execution is logged, and the server parses the MongoDB aggregation pipeline from the result. The pipeline defines a sequence of data aggregation operations to be performed on the MongoDB collection. MongoDB aggregation:
- The server connects to the “products’ collection within MongoDB.
- It then runs the aggregation pipeline against the collection and waits for the results, converting the cursor returned by the aggregate function to an array with toArray(). Response generation:
- Finally, the server responds to the client's POST request with a JSON object. This object includes the results of the aggregation, the user's original search list, the prompt used for the search, and the aggregation pipeline itself. The inclusion of the prompt and pipeline in the response can be particularly helpful for front-end applications to display the query context or for debugging.
This code combines AI and database querying to create a powerful search tool within an application, giving the user relevant and personalized results based on their input.
The integration of MongoDB with Rivet presents a unique opportunity to build sophisticated search solutions that are both powerful and user-centric. MongoDB's flexible data model and powerful aggregation pipeline, combined with Rivet's ability to process and interpret complex data structures through graph operations, pave the way for creating dynamic, intelligent applications.
By harnessing the strengths of both MongoDB and Rivet, developers can construct advanced search capabilities that not only understand the intent behind user queries but also deliver personalized results efficiently. This synergy allows for the crafting of seamless experiences that can adapt to the evolving needs of users, leveraging the full spectrum of data interactions from input to insight.
As we conclude, it's clear that this fusion of database technology and graph processing can serve as a cornerstone for future software development — enabling the creation of applications that are more intuitive, responsive, and scalable. The potential for innovation in this space is vast, and the continued exploration of this integration will undoubtedly yield new methodologies for data management and user engagement.