GridFS
On this page
- Overview
- How GridFS Works
- Create a GridFS Bucket
- Store Files
- Upload a File Using an Input Stream
- Upload a File Using an Output Stream
- Retrieve File Information
- Download Files
- File Revisions
- Download a File to an Output Stream
- Download a File to an Input Stream
- Rename Files
- Delete Files
- Delete a GridFS Bucket
- Additional Resources
Overview
In this guide, you can learn how to store and retrieve large files in MongoDB using GridFS. GridFS is a specification implemented by the driver that describes how to split files into chunks when storing them and reassemble them when retrieving them. The driver implementation of GridFS is an abstraction that manages the operations and organization of the file storage.
You should use GridFS if the size of your files exceed the BSON document size limit of 16MB. For more detailed information on whether GridFS is suitable for your use case, see the GridFS server manual page.
See the following sections that describe GridFS operations and how to perform them:
How GridFS Works
GridFS organizes files in a bucket, a group of MongoDB collections that contain the chunks of files and information describing them. The bucket contains the following collections, named using the convention defined in the GridFS specification:
The
chunkscollection stores the binary file chunks.The
filescollection stores the file metadata.
When you create a new GridFS bucket, the driver creates the preceding
collections, prefixed with the default bucket name fs, unless
you specify a different name. The driver also creates an index on each
collection to ensure efficient retrieval of the files and related
metadata. The driver only creates the GridFS bucket on the first write
operation if it does not already exist. The driver only creates indexes if
they do not exist and when the bucket is empty. For more information on
GridFS indexes, see the server manual page on GridFS Indexes.
When storing files with GridFS, the driver splits the files into smaller
chunks, each represented by a separate document in the chunks collection.
It also creates a document in the files collection that contains
a file id, file name, and other file metadata. You can upload the file from
memory or from a stream. See the following diagram to see how GridFS splits
the files when uploaded to a bucket.

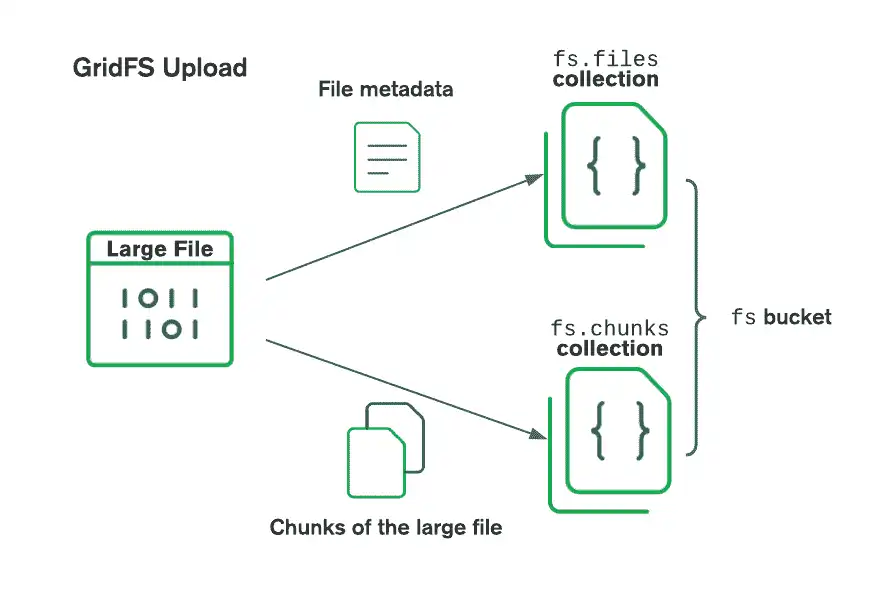
When retrieving files, GridFS fetches the metadata from the files
collection in the specified bucket and uses the information to reconstruct
the file from documents in the chunks collection. You can read the file
into memory or output it to a stream.
Create a GridFS Bucket
To store or retrieve files from GridFS, create a bucket or get a reference
to an existing one on a MongoDB database. Call the GridFSBuckets.create()
helper method with a MongoDatabase instance as the parameter to
instantiate a GridFSBucket. You can use the GridFSBucket instance to
call read and write operations on the files in your bucket.
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database);
To create or reference a bucket with a custom name other than the default name
fs, pass your bucket name as the second parameter to the create()
method as shown below:
GridFSBucket gridFSBucket = GridFSBuckets.create(database, "myCustomBucket");
Note
When you call create(), MongoDB does not create the bucket if it
does not exist. Instead, MongoDB creates the bucket as necessary such
as when you upload your first file.
For more information on the classes and methods mentioned in this section, see the following API Documentation:
Store Files
To store a file in a GridFS bucket, you can either upload it from an instance
of InputStream or write its data to a GridFSUploadStream.
For either upload process, you can specify configuration information such
as file chunk size and other field/value pairs to store as metadata. Set
this information on an instance of GridFSUploadOptions as shown in the
following code snippet:
GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) // 1MB chunk size .metadata(new Document("myField", "myValue"));
See the GridFSUploadOptions API Documentation for more information.
Important
Use a MAJORITY Write Concern
When storing files in a GridFS bucket, ensure that you use the WriteConcern.MAJORITY
write concern. If you specify a different write concern, replica set elections that occur
during a GridFS file upload might interrupt the upload process and cause some file chunks
to be lost.
For more information about write concerns, see the Write Concern page in the Server manual.
Upload a File Using an Input Stream
This section shows you how to upload a file to a GridFS bucket using an input
stream. The following code example shows how you can use a FileInputStream to
read data from a file in your filesystem and upload it to GridFS by performing
the following operations:
Read from the filesystem using a
FileInputStream.Set the chunk size using
GridFSUploadOptions.Set a custom metadata field called
typeto the value "zip archive".Upload a file called
project.zip, specifying the GridFS file name as "myProject.zip".
String filePath = "/path/to/project.zip"; try (InputStream streamToUploadFrom = new FileInputStream(filePath) ) { // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); // Uploads a file from an input stream to the GridFS bucket ObjectId fileId = gridFSBucket.uploadFromStream("myProject.zip", streamToUploadFrom, options); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + fileId.toHexString()); }
This code example prints the file id of the uploaded file after it is successfully saved in GridFS.
For more information, see the API Documentation on uploadFromStream().
Upload a File Using an Output Stream
This section shows you how to upload a file to a GridFS bucket by writing to
an output stream. The following code example shows how you can write to a
GridFSUploadStream to send data to GridFS by performing the following
operations:
Read a file named "project.zip" from the filesystem into a byte array.
Set the chunk size using
GridFSUploadOptions.Set a custom metadata field called
typeto the value "zip archive".Write the bytes to a
GridFSUploadStream, assigning the file name "myProject.zip". The stream reads data into a buffer until it reaches the limit specified in thechunkSizesetting, and inserts it as a new chunk in thechunkscollection.
Path filePath = Paths.get("/path/to/project.zip"); byte[] data = Files.readAllBytes(filePath); // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); try (GridFSUploadStream uploadStream = gridFSBucket.openUploadStream("myProject.zip", options)) { // Writes file data to the GridFS upload stream uploadStream.write(data); uploadStream.flush(); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + uploadStream.getObjectId().toHexString()); // Prints a message if any exceptions occur during the upload process } catch (Exception e) { System.err.println("The file upload failed: " + e); }
This code example prints the file id of the uploaded file after it is successfully saved in GridFS.
Note
If your file upload is not successful, the operation throws an exception
and any uploaded chunks become orphaned chunks. An orphaned chunk is a
document in a GridFS chunks collection that does not reference any file id
in the GridFS files collection. File chunks can become orphaned chunks
when an upload or delete operation is interrupted. To remove orphaned
chunks, you must identify them using read operations and remove them using
write operations.
For more information, see the API Documentation on GridFSUploadStream.
Retrieve File Information
In this section, you can learn how to retrieve file metadata stored in the
files collection of the GridFS bucket. The metadata contains information
about the file it refers to, including:
The id of the file
The name of the file
The length/size of the file
The upload date and time
A
metadatadocument in which you can store any other information
To retrieve files from a GridFS bucket, call the find() method on
the GridFSBucket instance. The method returns a GridFSFindIterable
from which you can access the results.
The following code example shows you how to retrieve and print file metadata
from all your files in a GridFS bucket. Among the different ways that you can
traverse the retrieved results from the GridFSFindIterable, the example
uses a Consumer functional interface to print the following results:
gridFSBucket.find().forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
The next code example shows you how to retrieve and print the file names
for all files that match the fields specified in the query filter. The example
also calls sort() and limit() on the returned GridFSFindIterable
to specify the order and maximum number of results:
Bson query = Filters.eq("metadata.type", "zip archive"); Bson sort = Sorts.ascending("filename"); // Retrieves 5 documents in the bucket that match the filter and prints metadata gridFSBucket.find(query) .sort(sort) .limit(5) .forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
Since metadata is an embedded document, the query filter specifies the
type field within the document using dot notation. See the server manual
guide on how to Query on Embedded/Nested Documents
for more information.
For more information on the classes and methods mentioned in this section, see the following resources:
GridFSFindIterable API Documentation
GridFSBucket.find() API Documentation
Download Files
You can download a file from GridFS directly to a stream or you can save it to memory from a stream. You can specify the file to retrieve using either the file id or file name.
File Revisions
When your bucket contains multiple files that share the same file name, GridFS chooses the latest uploaded version of the file by default. To differentiate between each file that shares the same name, GridFS assigns files that share the same filename a revision number, ordered by upload time.
The original file revision number is "0" and the next most recent file revision number is "1". You can also specify negative values which correspond to the recency of the revision. The revision value "-1" references the most recent revision and "-2" references the next most recent revision.
The following code snippet shows how you can specify the second revision
of a file in an instance of GridFSDownloadOptions:
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(1);
For more information on the enumeration of revisions, see the API documentation for GridFSDownloadOptions.
Download a File to an Output Stream
You can download a file in a GridFS bucket to an output stream. The following
code example shows you how you can call the downloadToStream() method to
download the first revision of the file named "myProject.zip" to an
OutputStream.
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(0); // Downloads a file to an output stream try (FileOutputStream streamToDownloadTo = new FileOutputStream("/tmp/myProject.zip")) { gridFSBucket.downloadToStream("myProject.zip", streamToDownloadTo, downloadOptions); streamToDownloadTo.flush(); }
For more information on this method, see the downloadToStream() API Documentation.
Download a File to an Input Stream
You can download a file in a GridFS bucket to memory by using an input
stream. You can call the openDownloadStream() method on the GridFS
bucket to open a GridFSDownloadStream, an input stream from which you
can read the file.
The following code example shows you how to download a file referenced by
the fileId variable into memory and print its contents as a string:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Opens an input stream to read a file containing a specified "_id" value and downloads the file try (GridFSDownloadStream downloadStream = gridFSBucket.openDownloadStream(fileId)) { int fileLength = (int) downloadStream.getGridFSFile().getLength(); byte[] bytesToWriteTo = new byte[fileLength]; downloadStream.read(bytesToWriteTo); // Prints the downloaded file's contents as a string System.out.println(new String(bytesToWriteTo, StandardCharsets.UTF_8)); }
For more information on this method, see the openDownloadStream(). API Documentation.
Rename Files
You can update the name of a GridFS file in your bucket by calling the
rename() method. You must specify the file to rename by its file id
rather than its file name.
Note
The rename() method only supports updating the name of one file at
a time. To rename multiple files, retrieve a list of files matching the
file name from the bucket, extract the file id values from the files you
want to rename, and pass each file id in separate calls to the rename()
method.
The following code example shows you how to update the name of the file referenced
by the fileId variable to "mongodbTutorial.zip":
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Renames the file that has a specified "_id" value to "mongodbTutorial.zip" gridFSBucket.rename(fileId, "mongodbTutorial.zip");
For more information on this method, see the rename() API Documentation.
Delete Files
You can remove a file from your GridFS bucket by calling the delete()
method. You must specify the file by its file id rather than its file name.
Note
The delete() method only supports deleting one file at a time. To
delete multiple files, retrieve the files from the bucket, extract
the file id values from the files you want to delete, and pass each file id
in separate calls to the delete() method.
The following code example shows you how to delete the file referenced by the
fileId variable:
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Deletes the file that has a specified "_id" value from the GridFS bucket gridFSBucket.delete(fileId);
For more information on this method, see the delete() API Documentation.
Delete a GridFS Bucket
The following code example shows you how to delete the default GridFS bucket on the database named "mydb". If you need to reference a custom named bucket, see the section of this guide on how to create a custom bucket.
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database); gridFSBucket.drop();
For more information on this method, see the drop() API Documentation.
Additional Resources
Runnable example GridFSTour.java from the MongoDB Java Driver repository.