Overview
In this guide, you can learn how to store and retrieve large files in MongoDB by using GridFS. GridFS is a specification that describes how to split files into chunks during storage and reassemble them during retrieval. The Rust driver implementation of GridFS manages the operations and organization of the file storage.
Use GridFS if the size of your file exceeds the BSON document size limit of 16 MB. GridFS also helps you access files without loading the entire file into memory. For more detailed information about whether GridFS is suitable for your use case, see the GridFS page in the Server manual.
To learn more about GridFS, navigate to the following sections in this guide:
How GridFS Works
GridFS organizes files in a bucket, which is a group of MongoDB collections containing file chunks and descriptive information. Buckets contain the following collections, named according to the convention defined in the GridFS specification:
chunks, which stores the binary file chunksfiles, which stores the file metadata
When you create a new GridFS bucket, the Rust driver performs the following actions:
Creates the
chunksandfilescollections, prefixed with the default bucket namefs, unless you specify a different nameCreates an index on each collection to ensure efficient retrieval of files and related metadata
You can create a reference to a GridFS bucket by following the steps in the Reference a GridFS Bucket section of this page. However, the driver does not create a new GridFS bucket and its indexes until the first write operation. For more information on GridFS indexes, see the GridFS Indexes page in the Server manual.
When storing a file in a GridFS bucket, the Rust driver creates the following documents:
One document in the
filescollection that stores a unique file ID, file name, and other file metadataOne or more documents in the
chunkscollection that store the content of the file, which the driver splits into smaller pieces
The following diagram describes how GridFS splits files when uploading to a bucket:

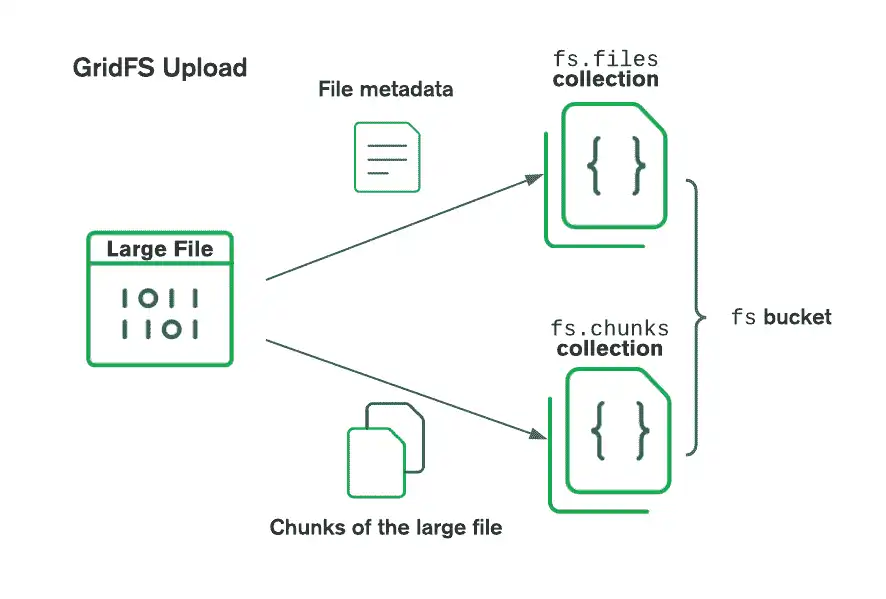
When retrieving files, GridFS fetches the metadata from the files collection in the
specified bucket and uses the information to reconstruct the file from documents in the
chunks collection. You can read the file into memory or output it to a stream.
Reference a GridFS Bucket
Before storing files in a GridFS bucket, create a bucket reference or get a reference to an existing bucket.
The following example calls the gridfs_bucket() method on a database instance, which
creates a reference to either a new or existing GridFS bucket:
let bucket = my_db.gridfs_bucket(None);
You can specify a custom bucket name by setting the bucket_name field of the
GridFsBucketOptions struct.
Note
Instantiating Structs
The Rust driver implements the Builder design pattern for the
creation of some struct types, including GridFsBucketOptions. You can
use the builder() method to construct an instance of each type
by chaining option builder methods.
The following table describes the methods that you can use to set GridFsBucketOptions
fields:
Method | Possible Values | Description |
|---|---|---|
bucket_name() | Any String value | Specifies a bucket name, which is set to fs by default |
| Any | Specifies the chunk size used to break the file into chunks, which is 255 KB by default |
write_concern() | WriteConcern::w(),WriteConcern::w_timeout(),WriteConcern::journal(),WriteConcern::majority() | Specifies the bucket's write concern, which is set to the database's write concern by default |
|
| Specifies the bucket's read concern, which is set to the database's read concern by default |
selection_criteria() | SelectionCriteria::ReadPreference,SelectionCriteria::Predicate | Specifies which servers are suitable for a bucket operation, which is set to the database's selection criteria by default |
The following example specifies options in a GridFsBucketOptions instance to configure
a custom bucket name and a five-second time limit for write operations:
let wc = WriteConcern::builder().w_timeout(Duration::new(5, 0)).build(); let opts = GridFsBucketOptions::builder() .bucket_name("my_bucket".to_string()) .write_concern(wc) .build(); let bucket_with_opts = my_db.gridfs_bucket(opts);
Upload Files
You can upload a file to a GridFS bucket by opening an upload stream and
writing your file to the stream. Call the open_upload_stream() method on
your bucket instance to open the stream. This method returns an instance of
GridFsUploadStream to which you can write the file contents. To upload
the file contents to the GridFsUploadStream, call the write_all() method
and pass your file bytes as a parameter.
Tip
Import the Required Module
The GridFsUploadStream struct implements the futures_io::AsyncWrite trait.
To use the AsyncWrite write methods, such as write_all(), import the
AsyncWriteExt module into your application file with the following use
declaration:
use futures_util::io::AsyncWriteExt;
The following example uses an upload stream to upload a file called "example.txt"
to a GridFS bucket:
let bucket = my_db.gridfs_bucket(None); let file_bytes = fs::read("example.txt").await?; let mut upload_stream = bucket.open_upload_stream("example").await?; upload_stream.write_all(&file_bytes[..]).await?; println!("Document uploaded with ID: {}", upload_stream.id()); upload_stream.close().await?;
Download Files
You can download a file from a GridFS bucket by opening a download stream and
reading from the stream. Call the open_download_stream() method on
your bucket instance, specifying the desired file's _id value as a parameter.
This method returns an instance GridFsDownloadStream from which you can access
the file. To read the file from the GridFsDownloadStream, call the read_to_end()
method and pass a vector as a parameter.
Tip
Import the Required Module
The GridFsDownloadStream struct implements the futures_io::AsyncRead trait.
To use the AsyncRead read methods, such as read_to_end(), import the
AsyncReadExt module into your application file with the following use
declaration:
use futures_util::io::AsyncReadExt;
The following example uses a download stream to download a file with an _id value
of 3289 from a GridFS bucket:
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let mut buf = Vec::new(); let mut download_stream = bucket.open_download_stream(Bson::ObjectId(id)).await?; let result = download_stream.read_to_end(&mut buf).await?; println!("{:?}", result);
Note
The GridFS streaming API cannot load partial chunks. When a download stream needs to pull a chunk from MongoDB, it pulls the entire chunk into memory. The 255 KB default chunk size is usually sufficient, but you can reduce the chunk size to reduce memory overhead.
Retrieve File Information
You can retrieve information about the files stored in the files collection of
the GridFS bucket. Each file is stored as an instance of the FilesCollectionDocument
type, which includes the following fields that represent file information:
_id: the file IDlength: the file sizechunk_size_bytes: the size of the file's chunksupload_date: the file's upload date and timefilename: the name of the filemetadata: a document that stores user-specified metadata
Call the find() method on a GridFS bucket instance to retrieve
files from the bucket. The method returns a cursor instance
from which you can access the results.
The following example retrieves and prints the length of each file in a GridFS bucket:
let bucket = my_db.gridfs_bucket(None); let filter = doc! {}; let mut cursor = bucket.find(filter).await?; while let Some(result) = cursor.try_next().await? { println!("File length: {}\n", result.length); };
Tip
To learn more about the find() method, see the Retrieve Data
guide. To learn more about retrieving data from a cursor, see the Access Data by Using a Cursor
guide.
Rename Files
You can update the name of a GridFS file in your bucket by calling the rename() method
on a bucket instance. Pass the target file's _id value and the new file name as
parameters to the rename() method.
Note
The rename() method only supports updating the name of one file at
a time. To rename multiple files, retrieve a list of files matching the
file name from the bucket, extract the _id field from the files you
want to rename, and pass each value in separate calls to the rename()
method.
The following example updates the filename field of the file containing an _id value
of 3289 to "new_file_name":
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let new_name = "new_file_name"; bucket.rename(Bson::ObjectId(id), new_name).await?;
Delete Files
You can use the delete() method to remove a file from your bucket. To remove a
file, call delete() on your bucket instance and pass the file's _id value
as a parameter.
Note
The delete() method only supports deleting one file at a time. To
delete multiple files, retrieve the files from the bucket, extract
the _id field from the files you want to delete, and pass each _id
value in separate calls to the delete() method.
The following example deletes the file in which the value of the _id field is
3289:
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); bucket.delete(Bson::ObjectId(id)).await?;
Delete a GridFS Bucket
You can use the drop() method to delete a bucket, which removes a bucket's
files and chunks collections. To delete the bucket, call drop() on
your bucket instance.
The following example deletes a GridFS bucket:
let bucket = my_db.gridfs_bucket(None); bucket.drop().await?;
Additional Information
API Documentation
To learn more about any of the methods or types mentioned in this guide, see the following API documentation: