Overview
In this guide, you can learn how to store and retrieve large files in MongoDB by using GridFS. GridFS is a specification implemented by the C driver that describes how to split files into chunks when storing them and reassemble them when retrieving them. The driver's implementation of GridFS is an abstraction that manages the operations and organization of the file storage.
Use GridFS if the size of your files exceeds the BSON document size limit of 16MB. For more detailed information on whether GridFS is suitable for your use case, see GridFS in the MongoDB Server manual.
How GridFS Works
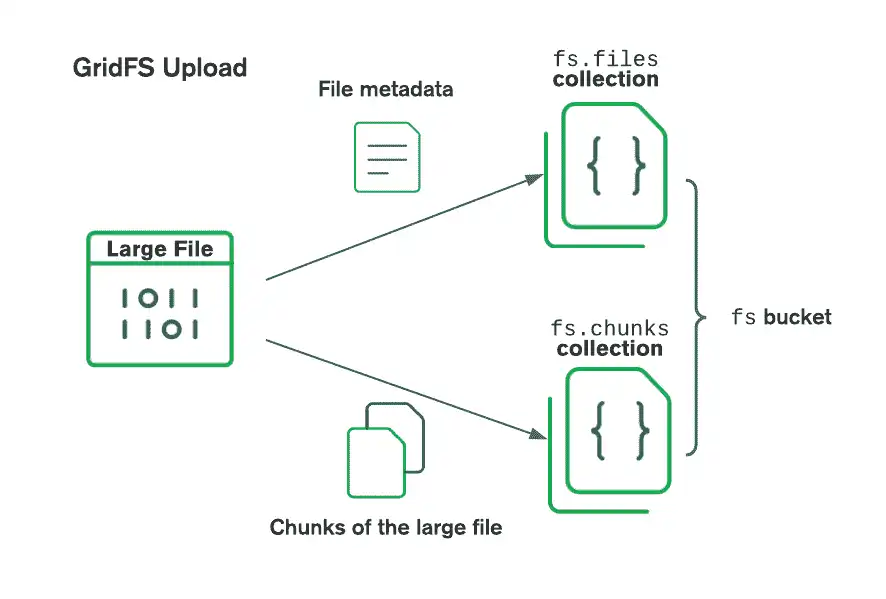
GridFS organizes files in a bucket, a group of MongoDB collections that contain the chunks of files and information describing them. The bucket contains the following collections, named using the convention defined in the GridFS specification:
The
chunkscollection stores the binary file chunks.The
filescollection stores the file metadata.
The driver creates the GridFS bucket, if it doesn't exist, when you perform
the first write operation. The bucket contains the preceding collections
prefixed with the default bucket name fs, unless you specify a different
name. To ensure efficient retrieval of the files and related metadata, the driver
also creates an index on each collection if they don't exist and when the
bucket is empty.
For more information about GridFS indexes, see GridFS Indexes in the MongoDB Server manual.
When using GridFS to store files, the driver splits the files into smaller
chunks, each represented by a separate document in the chunks collection.
It also creates a document in the files collection that contains
a file ID, file name, and other file metadata. You can upload the file by passing
a stream to the C driver to consume or creating a new stream and writing to it
directly.
The following diagram shows how GridFS splits files when they are uploaded to a bucket:

When you retrieve files from GridFS, it fetches the metadata from the files
collection in the specified bucket and uses the information to reconstruct
the file from documents in the chunks collection. You can read the file
by writing its contents to an existing stream or creating a new stream that points
to the file.
Create a GridFS Bucket
To use GridFS, first call the mongoc_gridfs_bucket_new() function.
This function creates a new mongoc_gridfs_bucket_t structure or accesses
an existing mongoc_gridfs_bucket_t and accepts the following parameters:
Database: Specifies the database in which to create the bucket
Options document: Specifies options to customize the bucket, or
NULLRead preference: Specifies the read preference to use for read operations, or
NULLto inherit the database's read preferenceError location: Specifies a location for an error value, or
NULL
The following example calls the mongoc_gridfs_bucket_new() function and passes
the db database as a parameter:
mongoc_database_t *db = mongoc_client_get_database(client, "db"); bson_error_t error; mongoc_gridfs_bucket_t *bucket = mongoc_gridfs_bucket_new(db, NULL, NULL, &error); if (!bucket) { fprintf(stderr, "Failed to create bucket: %s\n", error.message); }
Customize the Bucket
You can customize the GridFS bucket configuration by passing a BSON document that specifies
option values to the mongoc_gridfs_bucket_new() function. The following table describes
the options you can set in the document:
Option | Description |
|---|---|
| Specifies the bucket name to use as a prefix for the files and chunks collections.
The default value is "fs".Type: string |
| Specifies the chunk size that GridFS splits files into. The default value is 255 kB. Type: int32 |
| Specifies the read concern to use for bucket operations. The default value is the
database's read concern. Type: mongoc_read_concern_t |
| Specifies the write concern to use for bucket operations. The default value is the
database's write concern. Type: mongoc_write_concern_t |
The following example creates a bucket named "myCustomBucket" by passing an
options document to mongoc_gridfs_bucket_new() that sets the bucketName option:
mongoc_database_t *db = mongoc_client_get_database(client, "db"); bson_t opts = BSON_INITIALIZER; BSON_APPEND_UTF8(&opts, "bucketName", "myCustomBucket"); bson_error_t error; if (!mongoc_gridfs_bucket_new(db, &opts, NULL, &error)) { fprintf(stderr, "Failed to create bucket: %s\n", error.message); }
Upload Files
You can upload files to a GridFS bucket by using the following functions:
mongoc_gridfs_bucket_open_upload_stream(): Opens a new upload stream to which you can write file contentsmongoc_gridfs_bucket_upload_from_stream(): Uploads the contents of an existing stream to a GridFS file
Write to an Upload Stream
Use the mongoc_gridfs_bucket_open_upload_stream() function to create an
upload stream for a given file name. The mongoc_gridfs_bucket_open_upload_stream()
function allows you to specify configuration information in an options document,
which you can pass as a parameter.
This example uses an upload stream to perform the following actions:
Opens a writable stream for a new GridFS file named
"my_file"Calls the
mongoc_stream_write()function to write data to"my_file", which the stream points toCalls the
mongoc_stream_close()andmongoc_stream_destroy()functions to close and destroy the stream pointing to"my_file"
bson_error_t error; mongoc_stream_t *upload_stream = mongoc_gridfs_bucket_open_upload_stream(bucket, "my_file", NULL, NULL, &error); if (upload_stream == NULL) { fprintf(stderr, "Failed to create upload stream: %s\n", error.message); } else { const char *data = "Data to store"; mongoc_stream_write(upload_stream, data, strlen(data), -1); } mongoc_stream_close(upload_stream); mongoc_stream_destroy(upload_stream);
Upload an Existing Stream
Use the mongoc_gridfs_bucket_upload_from_stream() function to upload the contents
of a stream to a new GridFS file. The mongoc_gridfs_bucket_upload_from_stream()
function allows you to specify configuration information in an options document, which
you can pass as a parameter.
This example performs the following actions:
Calls the
mongoc_stream_file_new_for_path()function to open a file located at/path/to/input_fileas a stream in read only (O_RDONLY) modeCalls the
mongoc_gridfs_bucket_upload_from_stream()function to upload the contents of the stream to a GridFS file named"new_file"Calls the
mongoc_stream_close()andmongoc_stream_destroy()functions to close and destroy the stream
mongoc_stream_t *file_stream = mongoc_stream_file_new_for_path("/path/to/input_file", O_RDONLY, 0); bson_error_t error; if (!mongoc_gridfs_bucket_upload_from_stream(bucket, "new_file", file_stream, NULL, NULL, &error)) { fprintf(stderr, "Failed to upload file: %s\n", error.message); } mongoc_stream_close(file_stream); mongoc_stream_destroy(file_stream);
Retrieve File Information
In this section, you can learn how to retrieve file metadata stored in the
files collection of the GridFS bucket. A file's metadata contains information
about the file it refers to, including:
The
_idof the fileThe name of the file
The length/size of the file
The upload date and time
A
metadatadocument in which you can store any other information
To retrieve files from a GridFS bucket, call the mongoc_gridfs_bucket_find()
function and pass your bucket as a parameter. The function returns a cursor
from which you can access the results.
Tip
To learn more about cursors in the C driver, see the Access Data From a Cursor guide.
Example
The following code example shows you how to retrieve and print file metadata
from files in a GridFS bucket. It uses a while loop to iterate through
the returned cursor and display the contents of the files uploaded in the
Upload Files examples:
mongoc_cursor_t *cursor = mongoc_gridfs_bucket_find(bucket, bson_new(), NULL); const bson_t *file_doc; while (mongoc_cursor_next(cursor, &file_doc)) { char *json = bson_as_relaxed_extended_json(file_doc, NULL); printf("%s\n", json); bson_free(json); } mongoc_cursor_destroy(cursor);
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "my_file", "metadata" : { } } { "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file", "metadata" : { } }
The mongoc_gridfs_bucket_find() function accepts various query specifications. You can use its
options parameter to specify the sort order, maximum number of documents to return,
and the number of documents to skip before returning. To view a list of available
options, see the mongoc_collection_find_with_opts()
API documentation.
Download Files
You can download files from a GridFS bucket by using the following functions:
mongoc_gridfs_bucket_open_download_stream(): Opens a new download stream from which you can read the file contentsmongoc_gridfs_bucket_download_to_stream(): Writes the entire file to an existing download stream
Read From a Download Stream
You can download files from your MongoDB database by using the
mongoc_gridfs_bucket_open_download_stream() function to
create a download stream.
This example uses a download stream to perform the following actions:
Calls the
mongoc_gridfs_bucket_open_download_stream()function to select a GridFS file with the specified_idvalue and opens it as a readable streamCalls the
mongoc_stream_read()function to read the contents of the fileCalls the
mongoc_stream_close()andmongoc_stream_destroy()functions to close and destroy the download stream pointing to the file
char buf[512]; bson_value_t file_id; file_id.value_type = BSON_TYPE_OID; bson_oid_init_from_string(&file_id.value.v_oid, "66fb1b8ea0f84a74ee099e71"); bson_error_t error; mongoc_stream_t *download_stream = mongoc_gridfs_bucket_open_download_stream(bucket, &file_id, &error); if (!download_stream) { fprintf(stderr, "Failed to create download stream: %s\n", error.message); } mongoc_stream_read(download_stream, buf, 1, 1, 0); mongoc_stream_close(download_stream); mongoc_stream_destroy(download_stream);
Note
If there are multiple documents with the same file name,
GridFS will stream the most recent file with the given name (as
determined by the uploadDate field).
Download to an Existing Stream
You can download the contents of a GridFS file to an existing stream
by calling the mongoc_gridfs_bucket_download_to_stream() function.
This example performs the following actions:
Calls the
mongoc_stream_file_new_for_path()function to open a file located at/path/to/output_fileas a stream in read and write (O_RDWR) modeDownloads a GridFS file that has the specified
_idvalue to the streamCalls the
mongoc_stream_close()andmongoc_stream_destroy()functions to close and destroy the file stream
mongoc_stream_t *file_stream = mongoc_stream_file_new_for_path("/path/to/output_file", O_RDWR, 0); bson_error_t error; if (!file_stream) { fprintf(stderr, "Error opening file stream: %s\n", error.message); } bson_value_t file_id; file_id.value_type = BSON_TYPE_OID; bson_oid_init_from_string(&file_id.value.v_oid, "66fb1b8ea0f84a74ee099e71"); if (!mongoc_gridfs_bucket_download_to_stream(bucket, &file_id, file_stream, &error)) { fprintf(stderr, "Failed to download file: %s\n", error.message); } mongoc_stream_close(file_stream); mongoc_stream_destroy(file_stream);
Delete Files
Use the mongoc_gridfs_bucket_delete_by_id() function to remove a file's collection
document and associated chunks from your bucket. This effectively deletes the file.
The following example shows you how to delete a file by referencing its _id field:
bson_error_t error; bson_oid_t oid; bson_oid_init_from_string(&oid, "66fb1b365fd1cc348b031b01"); if (!mongoc_gridfs_bucket_delete_by_id(bucket, &oid, &error)) { fprintf(stderr, "Failed to delete file: %s\n", error.message); }
Note
File Revisions
The mongoc_gridfs_bucket_delete_by_id() function supports deleting only one
file at a time. If you want to delete each file revision, or files with different upload
times that share the same file name, collect the _id values of each revision.
Then, pass each _id value in separate calls to the mongoc_gridfs_bucket_delete_by_id()
function.
API Documentation
To learn more about using the C driver to store and retrieve large files, see the following API documentation: