La génération augmentée par récupération (RAG) est un framework d’IA générative populaire qui améliore les capacités des Large Language Models (LLM) en incorporant des informations pertinentes et à jour au cours du processus de génération. Cette approche permet aux LLM de compléter leurs connaissances pré-entraînées avec des données actuelles spécifiques au domaine. La RAG est une solution économique pour adapter un LLM à des cas d’utilisation spécifiques sans le processus coûteux et chronophage du réglage fin ou du réentraînement de l’ensemble du modèle.
Génération augmentée par récupération pour une IA plus intelligente
La génération augmentée par récupération permet aux organisations de tirer parti des LLM à usage général pour des applications spécialisées sans avoir besoin de modèles coûteux et personnalisés. La RAG répond directement aux limitations fondamentales de ces modèles en enrichissant les requêtes avec des informations actuelles et spécifiques au domaine pour améliorer les capacités de génération. Cela permet aux organisations d’intégrer des informations en temps réel, des ensembles de données propriétaires et une documentation spécialisée qui ne font pas partie de l’entraînement du modèle original. En joignant des preuves aux réponses de manière transparente, la RAG améliore la confiance et réduit le risque d’hallucinations.
Que sont les grand modèles de langage ?
Les LLM sont une forme d’intelligence artificielle conçue pour comprendre et produire des textes semblables à ceux des humains. En tant qu’application avancée du traitement du langage naturel (NLP), les LLM peuvent apprendre des schémas, des structures et de la grammaire à partir de quantités massives de données d’entraînement, ce qui leur permet de générer des réponses cohérentes aux prompts des utilisateurs. La force des grands modèles de langage réside dans leur capacité à effectuer un large éventail de tâches de génération de langage sans nécessiter d’entraînement spécifique à une tâche. Ce sont donc des outils polyvalents pour des applications telles que les chatbots, la traduction, la création de contenu et le résumé.
Les limites des grands modèles de langage
Un grand modèle de langage est un réseau neuronal complexe qui apprend en analysant des ensembles de données d’entraînement massifs. Ces modèles nécessitent des ressources informatiques substantielles, ce qui rend leur développement extrêmement coûteux et chronophage. De plus, l’infrastructure spécialisée requise pour l’hébergement et la maintenance des LLM représente un obstacle financier important, limitant leur accessibilité aux seules organisations bien dotées en ressources et ayant réalisé des investissements technologiques considérables.
Les LLM sont excellents pour répondre aux questions sur du contenu historique, mais leurs connaissances sont limitées par les contraintes de leurs données d’entraînement. Ils sont ainsi moins efficaces pour les requêtes nécessitant des connaissances à jour, car ils ne peuvent pas répondre à propos d’événements récents sans réentraînement du modèle.
De même, les LLM ne peuvent pas répondre de manière native aux questions concernant la documentation interne de l’entreprise ou d’autres ensembles de données spécifiques à un domaine et propres à une organisation donnée. Cette limitation pose des défis considérables aux entreprises cherchant à tirer parti des technologies d’IA qui nécessitent des connaissances approfondies et spécialisées adaptées à leurs besoins.
Ces limitations soulignent un autre défi des LLM : les hallucinations. Sans informations vérifiables, les modèles de langage peuvent produire des réponses qui paraissent fiables et plausibles, mais qui sont entièrement fabriquées. Cette tendance à produire des informations convaincantes mais fausses entraîne des risques importants pour les applications exigeant de la précision et de la fiabilité.

Avantages de la génération augmentée par récupération
La RAG est devenue populaire grâce à son architecture relativement simple et aux améliorations notables qu’elle apporte aux performances.
Rentable
La RAG permet aux organisations d’utiliser des modèles pré-entraînés à usage général pour des applications spécialisées, sans les frais liés au développement de modèles personnalisés. Une récupération efficace réduit les coûts d’API en garantissant que seules sont incluses les informations nécessaires à l’optimisation des LLM qui sont facturés au jeton.
Personnalisation du domaine
La RAG permet aux organisations d’adapter les modèles pré-entraînés à des domaines spécifiques en intégrant des bibliothèques de connaissances spécialisées. Les modèles peuvent ainsi produire des réponses concernant la documentation propriétaire et spécifique au secteur, sans nécessiter d’entraînement personnalisé. Le réglage fin peut offrir des avantages similaires, mais il prend beaucoup plus de temps, coûte plus cher et demande davantage de maintenance.
Informations en temps réel
La RAG permet aux grands modèles de langage d’accéder à des informations actuelles et de générer des réponses en récupérant dynamiquement des données à jour à partir de sources externes. La limitation des connaissances liée à des ensembles de données d’entraînement statiques est ainsi contournée, permettant aux modèles de fournir des informations sur les événements récents et les tendances émergentes.
Transparence
La RAG améliore la fiabilité des réponses de l’IA en fournissant des citations de sources et des preuves associées au contenu généré. En reliant chaque réponse à des sources spécifiques dans la Base de connaissances, la RAG permet aux utilisateurs de vérifier l’origine et l’exactitude des informations, réduisant ainsi le risque d’hallucinations et renforçant la confiance dans les résultats générés par l’IA.
Adaptabilité
L’un des principaux avantages de la RAG est sa capacité à s’adapter facilement aux nouveaux modèles de pointe. À mesure que des avancées apparaissent dans les modèles linguistiques ou les techniques de récupération, les organisations peuvent intégrer de nouveaux modèles ou ajuster les stratégies de récupération sans remanier l’ensemble du système. Cette flexibilité garantit le maintien à jour des systèmes RAG avec la technologie la plus avancée.
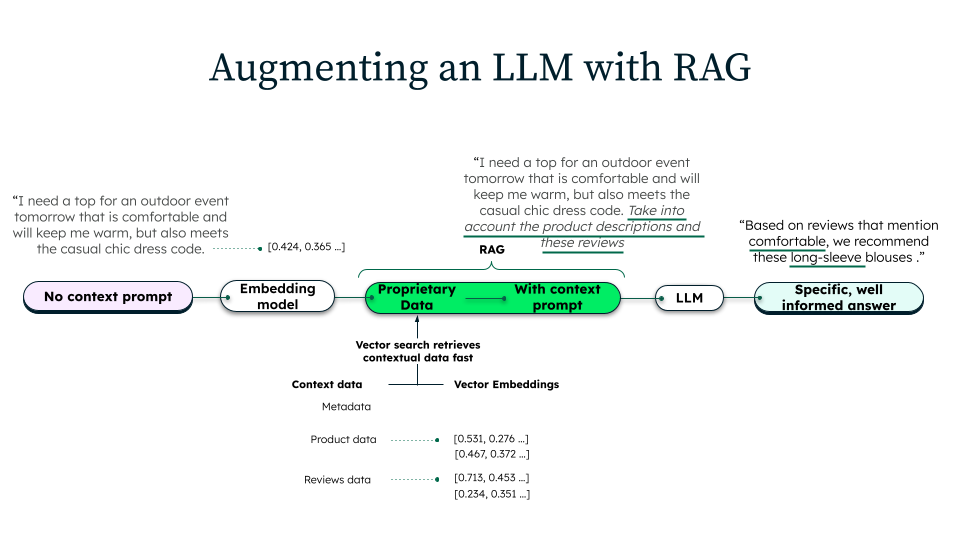
Comment fonctionne la génération augmentée par récupération ?
Le RAG se compose de trois phases distinctes : ingestion, récupération et génération.
Ingestion de données
Lors de l’ingestion, les organisations préparent leur base de connaissances pour la récupération des données. Les données sources sont collectées à partir de divers dépôts tels que la documentation interne, les bases de données ou les ressources externes. Ces documents sont ensuite nettoyés, mis en forme et découpés en segments plus petits et plus faciles à gérer. Chaque segment est converti en représentation vectorielle à l’aide d’un modèle d’embedding qui capture le sens sémantique du texte. Ces vecteurs sont stockés dans des bases de données vectorielles qui assurent une recherche sémantique efficace et un accès rapide.
Récupération d’informations
Lorsqu’un utilisateur soumet une requête, le système récupère le contexte pertinent avant la génération. La requête est transformée en représentation vectorielle à l’aide du même modèle d’embedding utilisé lors de l’ingestion. La recherche vectorielle va rechercher dans la base de données les segments de documents les plus similaires à la requête du point de vue sémantique. Des techniques supplémentaires de filtrage, de classement ou de réévaluation des poids peuvent être appliquées pour garantir que seules les informations les plus pertinentes sont récupérées, améliorant ainsi la précision de la réponse finale.
Génération
Une fois le contexte pertinent récupéré, un prompt augmenté est construit à partir du prompt initial, des mêmes passages récupérés et d’instructions spécifiques. Le LLM traite ce prompt pour générer une réponse qui synthétise ses connaissances pré-entraînées avec le contenu récupéré. Cette approche garantit que la réponse est documentée par des sources de données externes et alignée sur l’intention de l’utilisateur, ce qui améliore la précision de la réponse.
Cas d’utilisation sectoriels pour la génération augmentée par récupération
La RAG est déjà utilisée dans tous les secteurs pour exploiter le potentiel transformateur des grands modèles de langage et de l’IA.
- Fabrication : augmentation des LLM à partir des manuels techniques et des journaux de maintenance pour fournir des conseils opérationnels en temps réel. La RAG permet aux techniciens d’accéder rapidement à des informations précises sur les machines, réduisant ainsi les temps d’arrêt et améliorant les performances des équipements.
- Service client : utilisation de la documentation interne, des guides de produits et de l’historique d’assistance pour diagnostiquer les problèmes. La RAG aide les équipes support à récupérer instantanément du contenu pertinent, réduisant ainsi les temps de réponse et améliorant les taux de résolution au premier contact pour répondre efficacement aux requêtes des clients.
- Santé : synthèse des recherches médicales, des directives cliniques et des dossiers des patients pour appuyer les décisions diagnostiques et les recommandations de traitement. La RAG permet aux professionnels de santé d’accéder aux connaissances médicales actuelles tout en fournissant des informations transparentes et fondées sur des preuves.
- Services financiers : intégration des documents réglementaires, des études de marché et des directives de conformité pour soutenir la recherche d’investissements, l’évaluation des risques et la conformité réglementaire. La RAG permet aux analystes financiers de récupérer et d’analyser rapidement des informations financières complexes et actualisées.
- Ingénierie logicielle : examen de la documentation et des extraits de code pour assister les ingénieurs pendant l’écriture de code. La RAG peut également aider au débogage en suggérant des correctifs potentiels basés sur des problèmes passés similaires, ce qui améliore la productivité et la qualité.
Concepts clés de la génération augmentée par récupération
Chunking
Le chunking, ou découpage séquentiel, est un élément du processus d’ingestion de données qui améliore la précision du système tout en réduisant les coûts. Les grandes sections de contenu sont découpées en segments plus petits (les chunks) et plus faciles à gérer pour les préparer à la récupération. L’objectif est de créer des segments significatifs et entièrement contextualisés, en veillant à ce qu’ils conservent suffisamment d’informations pour être utiles tout en minimisant la redondance.
Un découpage efficace équilibre la précision et l’exhaustivité, ce qui permet au système de récupérer des informations pertinentes sans submerger les LLM de détails inutiles. Des segments bien structurés améliorent la précision de la récupération, réduisent l’utilisation des jetons et conduisent à des réponses plus précises et plus rentables.
Modèles d’embedding
Les modèles d’intégration convertissent les données en représentations numériques appelées vecteurs qui saisissent la signification sémantique. Cela permet au système de comprendre les relations entre les mots, les phrases et les documents, améliorant ainsi la précision de la récupération d’informations pertinentes.
Lors de l’ingestion, le modèle d’embedding traite chaque chunk de données, le transformant en vecteur avant de le stocker dans une base de données relationnelle. Lorsqu’un utilisateur soumet une requête, elle est convertie en un vecteur à l’aide du même modèle d’embedding.
Différents types de modèles d’intégration prennent en charge divers cas d’utilisation. Les modèles à usage général fonctionnent bien pour les applications grand public, tandis que les modèles spécifiques à un domaine sont conçus pour des secteurs comme le droit, la médecine ou la finance, améliorant ainsi la précision de la récupération dans les domaines spécialisés. Les modèles multimodaux vont au-delà du traitement de texte en traitant les images, l’audio et d’autres types de données, offrant ainsi des capacités de récupération plus avancées. Certains modèles peuvent créer une représentation numérique du texte pouvant être comparée directement à une image ou à une vidéo pour une récupération multimodale véritablement avancée.
Recherche sémantique
La recherche sémantique améliore la récupération d’informations en se concentrant sur le sens de la requête d’un utilisateur, ce qui améliore considérablement la recherche par mots-clés. En utilisant des embeddings, les requêtes et les documents sont convertis en vecteurs qui capturent la signification sémantique. Lorsqu’un utilisateur soumet une requête, la base de données vectorielle recherche les documents les plus pertinents, même si les termes exacts de la requête ne sont pas directement présents dans le contenu.
Cette approche permet une meilleure compréhension contextuelle, garantissant des résultats plus précis et pertinents. En reconnaissant les synonymes, les concepts apparentés et les variantes de mots, la recherche sémantique améliore l’expérience de l’utilisateur et réduit l’ambiguïté, en fournissant des résultats qui correspondent mieux à l’intention de l’utilisateur.
Reclassement
Le reclassement est une technique utilisée pour améliorer la pertinence des résultats de recherche après une phase initiale de récupération. Une fois qu’un ensemble de documents est récupéré, un modèle de reclassement les réorganise en fonction de leur pertinence par rapport à la requête de l’utilisateur. Ce modèle peut exploiter des fonctionnalités supplémentaires telles que la qualité du document, la pertinence contextuelle ou le score basé sur le machine learning pour affiner les résultats.
Le reclassement aide à prioriser les informations les plus utiles et contextuellement appropriées, améliorant ainsi la précision et la satisfaction des utilisateurs. Il est particulièrement utile lorsque la phase de récupération initiale renvoie un large éventail de résultats, permettant ainsi au système d’affiner la sélection et de présenter les réponses les plus pertinentes.
Prompt engineering
Le prompt engineering consiste à concevoir méticuleusement l’entrée fournie à un LLM pour orienter sa sortie dans la direction souhaitée. En structurant efficacement les prompts, vous vous assurez que le modèle génère des réponses plus précises, pertinentes et appropriées. Ce processus implique d’inclure des instructions claires, un contexte pertinent et parfois des exemples pour aider le modèle à comprendre la tâche.
Dans la génération augmentée par récupération, le prompt engineering joue un rôle clé en combinant les documents récupérés avec la requête originale de l’utilisateur pour produire des réponses cohérentes et précises. Des prompts bien conçus réduisent l’ambiguïté, minimisent les informations non pertinentes et garantissent l’alignement du modèle sur l’intention de l’utilisateur de façon à obtenir des résultats de meilleure qualité.
Optimiser votre application de génération augmentée par récupération
Les solutions RAG peuvent être optimisées pour offrir une plus grande précision et une expérience globale améliorée pour les utilisateurs finaux.
Optimiser la récupération d’informations
Plusieurs stratégies permettent d’améliorer la recherche d’informations pour la RAG. Tout d’abord, examinez les techniques de chunking pour vous assurer que les documents sont découpés en segments significatifs et contextuellement pertinents. Ensuite, choisissez le modèle d’intégration approprié pour saisir la signification sémantique de votre contenu. Les modèles spécifiques à un domaine peuvent offrir de meilleurs résultats pour certains cas d’utilisation. Bien que la recherche sémantique soit la plus couramment utilisée, demandez-vous si la recherche par mot-clé ou une approche hybride peut améliorer la récupération des données.
De plus, appliquez des méthodes de reclassement après la récupération initiale pour affiner la précision des résultats. Il est également essentiel d’ajuster le nombre de documents récupérés : trop nombreux, ils peuvent introduire du bruit, tandis qu’un nombre insuffisant peut vous faire passer à côté d’un contexte important. En trouvant le bon équilibre, vous améliorerez les performances et la pertinence de la récupération.
Optimisation de la génération de réponses
L’amélioration de la génération de langage dans la RAG peut être réalisée grâce à plusieurs approches clés. Tout d’abord, concentrez-vous sur le prompt engineering pour structurer les requêtes et le contexte de manière à guider le modèle linguistique pour générer des réponses plus précises et pertinentes. Des instructions claires, un contexte et des exemples contribuent à réduire l’ambiguïté et à améliorer la qualité des résultats. Ensuite, évaluez différents modèles ou LLM spécifiques au domaine pour vous assurer que les réponses générées correspondent aux nuances de votre cas d’utilisation particulier, améliorant ainsi la pertinence et la précision. En outre, les paramètres ajustables du modèle, tels que la température, doivent être pris en compte pour réguler la créativité des réponses du modèle.
Optimisation pour l’échelle de production
Assurez-vous que votre système RAG est prêt pour la production en choisissant les meilleurs fournisseurs pour les composants essentiels de votre application.
Quant à votre base de données vectorielle, optez pour une plateforme offrant des capacités de recherche et d’indexation très efficaces, notamment une prise en charge rapide et évolutive de la recherche approximative du plus proche voisin (ANN). Les bases de données vectorielles avancées peuvent également prendre en charge le filtrage des métadonnées, ce qui améliore la précision et la rapidité en réduisant les résultats de recherche à partir d’informations contextuelles supplémentaires. Votre système sera ainsi en mesure de récupérer rapidement les documents pertinents, y compris lorsque l’ensemble de données prend de l’ampleur.
Lors du choix d’un modèle d’embedding, il est essentiel de trouver un équilibre entre la forte dimensionnalité des vecteurs et l’efficacité du stockage et de la récupération. Bien que les embeddings de dimensions supérieures capturent des relations sémantiques plus riches, ils entraînent des coûts de calcul accrus, des exigences de stockage plus importantes et des temps de récupération plus lents.
De plus, lors de la sélection d’un LLM pour le composant de génération, assurez-vous qu’il correspond aux besoins spécifiques de votre cas d’utilisation. Les LLM doivent être capables d’interpréter avec précision les informations récupérées et de générer des réponses contextuellement cohérentes et pertinentes. Le choix des LLM a également un impact sur le coût et les performances globales du système : les modèles plus grands peuvent offrir une meilleure précision, mais au prix d’une latence et d’exigences de calcul plus élevées. Il est crucial d’évaluer votre temps de réponse, la qualité de votre sortie et vos exigences en termes d’infrastructure pour sélectionner un LLM qui fournit le juste équilibre entre performances et efficacité.
Défis de la génération augmentée par récupération
L’un des principaux défis de la RAG est la difficulté à centraliser et organiser le contenu pour une récupération efficace. Les systèmes RAG nécessitent l’accès à de vastes quantités de données dans divers domaines. Cependant, l’organisation de ce contenu de manière à permettre au modèle de récupérer efficacement les informations les plus pertinentes et à jour est une tâche complexe. Les données peuvent être réparties entre différentes plateformes, formats et bases de données, ce qui rend difficile de garantir une couverture et une précision complètes. De plus, il est essentiel d’assurer la cohérence entre plusieurs sources. Les informations récupérées peuvent être contradictoires, obsolètes ou incomplètes, ce qui peut brouiller la base de connaissances et nuire à la qualité et à la fiabilité des réponses générées. Ces défis soulignent la nécessité de systèmes d’indexation et de récupération plus sophistiqués pour permettre aux modèles RAG de récupérer le meilleur contenu possible et de produire des résultats pertinents et précis.
Un autre défi important est la capacité actuelle de la RAG qui se limite à répondre à des questions plutôt qu’à effectuer des tâches plus complexes. Si les systèmes RAG excellent dans la génération de réponses à partir des informations récupérées, ils ont du mal à exécuter des actions au-delà de la réponse aux requêtes ou de la création de contenu. Cette contrainte est due à la nature même de la RAG, conçue principalement pour extraire des données pertinentes de sources externes et fournir des résultats fondés sur ces données, plutôt que d’interagir avec des environnements réels ou de les manipuler. Par conséquent, bien que les modèles RAG puissent aider à la recherche d’informations et à la génération de contenu, leur capacité à exécuter des tâches telles que la résolution de problèmes ou la prise de décision reste sous-développée, limitant ainsi leur potentiel pour des applications plus dynamiques.
Créer un système de génération augmentée par récupération interactif et amélioré par la mémoire
L’amélioration de la RAG par l’ajout d’une mémoire accroît sa capacité à créer une expérience plus interactive en se souvenant des détails clés et du contexte des interactions passées. Les systèmes RAG traditionnels répondent généralement aux requêtes sans conserver d’informations sur plusieurs échanges, ce qui conduit à une expérience décousue. En intégrant des mécanismes de mémoire, les systèmes RAG peuvent stocker des faits pertinents, des préférences ou des idées issues des conversations actuelles et antérieures, leur permettant ainsi de s’y reporter au besoin. Le système peut ainsi générer des réponses plus personnalisées et mieux alignées sur le contexte, et créer une expérience plus fluide. Au fil du temps, le système développe une compréhension plus approfondie des besoins de l’utilisateur et adapte ses réponses pour les rendre plus pertinentes et plaisantes, donnant l’impression d’une conversation continue plutôt qu’une succession de requêtes isolées.
L’avenir de la génération augmentée par récupération et de l’IA générative
De nouvelles techniques de RAG continueront d’émerger, améliorant sa capacité à récupérer et à générer des informations de manière plus efficace, plus adaptative et plus intelligente. L’un des domaines de croissance prometteurs est le développement de mécanismes de récupération avancés, qui permettent aux systèmes RAG d’accéder dynamiquement à un éventail plus large de sources, y compris des bases de données spécialisées, du contenu non structuré et des informations en temps réel. Ces améliorations rendront les systèmes RAG plus sensibles au contexte, de manière à produire des résultats extrêmement pertinents et précis dans divers domaines.
Dans le même temps, l’intégration de nouvelles capacités agentiques de l’IA générative permettra aux systèmes d’IA de résoudre des problèmes, d’analyser des données et de prendre des décisions. Ces systèmes agentiques ne se contenteront pas d’extraire et de générer des réponses, mais prendront également des mesures basées sur les informations qu’ils auront recueillies, les rendant ainsi plus interactifs, autonomes et intelligents. En conséquence, la RAG occupera une place centrale dans des applications telles que la recherche automatisée, les recommandations personnalisées et les assistants virtuels interactifs, inaugurant une nouvelle ère d’IA réactive et proactive.
Réglage fin et génération augmentée par récupération
Le réglage fin est un processus par lequel un modèle linguistique est modifié à l’aide d’un entraînement supplémentaire sur de nouveaux contenus, enseignant essentiellement au modèle de nouvelles connaissances ou de nouveaux comportements qui sont définitivement intégrés dans sa mémoire paramétrique. Cette approche nécessite des ressources informatiques et une expertise considérables, et sa capacité à intégrer de nouvelles informations est limitée en raison des contraintes de taille du modèle. De plus, les modifications apportées sont permanentes et il est difficile de les mettre à jour. Un modèle affiné peut fournir des résultats spécifiques à un domaine, mais le temps d’entraînement qu’il exige et ses incidences financières le rendent difficile à maintenir à jour.
La génération augmentée par récupération (RAG) récupère dynamiquement le contenu qui ne fait pas partie des données d’entraînement avant que la génération linguistique n’interviennent. Cela permet aux modèles RAG d’intégrer de nouvelles données sans modifier les paramètres sous-jacents du modèle, ce qui les rend plus flexibles et évolutifs pour les tâches qui exigent de grandes quantités de connaissances comme le réglage fin.
Créez des applications de RAG avec MongoDB Atlas et Voyage AI
MongoDB Atlas est une base de données polyvalente robuste qui prend en charge les vecteurs et la recherche vectorielle. C’est la solution idéale pour créer des applications de RAG de niveau production.
Voyage AI fournit de puissants modèles d’intégration et de reclassement pour créer une récupération d’informations très précise.
Donnez un nouvel élan à vos projets : simplifiez votre processus de développement et libérez de la valeur tout en bénéficiant d’une intégration transparente aux principaux partenaires d’IA et fournisseurs de cloud, aux fournisseurs de LLM et aux intégrateurs de systèmes.
Ressources
Découvrez MongoDB Atlas, la base de données vectorielle avec recherche intégrée, capacités vectorielles et plus encore. Inscrivez-vous gratuitement maintenant.
Pour en savoir plus sur Voyage AI, consultez ce blog.
Pour obtenir des conseils stratégiques et une assistance à la mise en œuvre de la recherche ou d’autres éléments de la pile d’IA, consultez notre Programme d’applications MongoDB AI.