Overview
本番前または本番環境のニーズに合わせて、さまざまな配置タイプ、クラウドプロバイダー、およびクラスター階層を使用してクラスターを構造化できます。これらの推奨事項を使用して、配置タイプ、クラウドプロバイダーとリージョン、およびベクトル検索を実行するためのクラスターと検索階層を選択します。
environment | 配置タイプ | クラスター階層 | クラウドプロバイダーのリージョン | ノード アーキテクチャ |
|---|---|---|---|---|
クエリのテスト | Flex or dedicated cluster Local deployment | M0, Flex, or higher tierN/A | All N/A | MongoDB プロセスと Search プロセスは同じノードで実行 |
アプリケーションのプロトタイプ作成 | シャーディングまたはシャーディングされていない専用クラスター |
| すべて | MongoDB プロセスと Search プロセスは同じノードで実行 |
本番環境 | シャーディングまたはシャーディングされていない個別の検索ノードを持つ専用クラスター |
| MongoDB プロセスと Search プロセスは異なるノードで実行 |
次のセクションでは、各環境について説明します。
環境のテストとプロトタイプ作成
検索クエリをテストし、アプリケーションをプロトタイプするには、以下のセクションで説明されているデプロイメント タイプとノード アーキテクチャをお勧めいたします。
この構成は、次のユースケースに最適です。
インデックスするドキュメントの合計が 2M 未満
10GB 未満のインデックス データ
7 日間で 10,000 件未満のクエリ
使用量が記載された値を超える場合は、専用の検索ノードに移行します。
以下のセクションでは、このノード アーキテクチャについて詳しく説明します。
- 配置タイプ
クラウドのクラスターでMongoDB Search クエリをテストするには、 Flex または専有クラスターを配置できます。
MongoDB Search クエリをローカルでテストするには、Atlas CLI を使用してローカル Atlas 配置を作成します。これは、ローカル コンピューターでホストされている単一ノードのレプリカセットなどです。ローカル配置は、ローカル マシンの CPU、メモリ、およびストレージリソースによって制限されます。アプリケーションを本番環境で使用する準備ができたら、Atlas のローカル配置を本番環境に移行します。
- Cluster Tiers
MongoDB Search クエリをテストするには、無料クラスター(
M0)と Flex クラスターを使用します。アプリケーションのプロトタイプ作成には、専用の
M10、M20以上の階層のクラスターを使用するか、ワークロード分離用に専用の検索ノードを配置します。アプリケーションが本番環境の準備ができたら、大規模なデータセットを処理する準備ができたら、上位階層にアップグレードします。- クラウドプロバイダーとリージョン
サポートされている任意のクラウドプロバイダーリージョンを使用してください。
選択したクラウドプロバイダーとリージョンは、クラスター階層で使用可能な構成オプションとクラスターの実行中コストに影響します。
ノード アーキテクチャ
テストおよびプロトタイプ作成環境には、 MongoDBプロセスとMongoDB Search プロセスが 同じノードで実行されるノードアーキテクチャを推奨します。この配置モデルの次の図では、 MongoDB Search mongot プロセスが Atlas クラスター内の各ノードで mongod と並行して実行され、これらは同じリソースを共有しています。

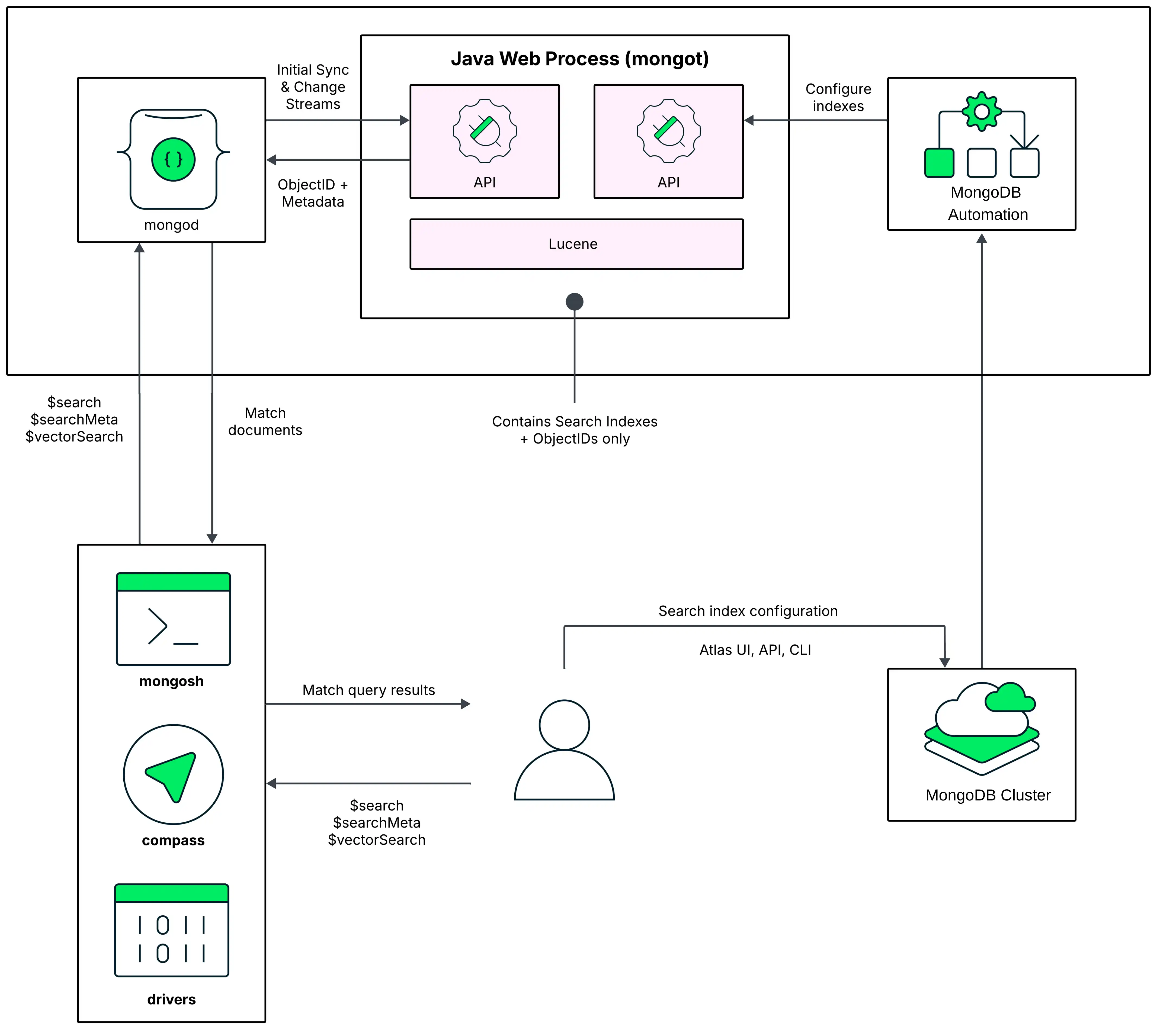
デフォルトでは 、Atlas は 最初のMongoDB Searchインデックスを作成するときに、mongod プロセスを実行するのと同じノードでMongoDB Search mongot プロセスを有効にします。
クエリを実行する際、 MongoDB Search は 構成済みの読み込み設定 (read preference)を使用して、クエリを実行するノードを識別します。クエリはまずMongoDBプロセスに送られます。このプロセスは、レプリカセットクラスターの場合は mongod、シャーディングされたクラスターの場合は mongos です。
レプリカセットクラスターの場合、mongod プロセスは同じノード上の mongot にクエリをルーティングします。シャーディングされたクラスターの場合、クラスター データは mongod インスタンス(シャード)全体で分割されます。各 mongot プロセスは、同じノード上にある mongodインスタンスのデータにのみアクセスできます。特定のシャードを対象とするMongoDB Search クエリは実行できません。mongos はクエリをすべてのシャードにルーティングするため、これらは scatter-gather パターンのクエリになります。If you use ゾーン を使用してシャーディングされたコレクションをクラスター内のシャードのサブセットにわたって分散する場合、 MongoDB Search はクエリしているコレクションのシャードを含むゾーンにクエリをルーティングして、次のシャードのみで $search クエリを実行します。コレクションが配置されている。
クエリがMongoDB Search mongot プロセスにルーティングされた後、mongot プロセスは検索とスコアリングを実行し、一致する結果のドキュメントID とその他の検索メタデータを対応する mongod プロセスに返します。次に、mongod プロセスは一致する結果のクエリをドキュメント全体で暗黙的に実行し、その結果をクライアントに返します。クエリで $search 同時実行 オプションを使用すると、 MongoDB Search はクエリ内並列処理を有効にします。詳細については、セグメント間でのクエリ実行の並列化 を参照してください。
mongot プロセスの詳細については、「クエリ処理」を参照してください。
MongoDB Searchインデックスで 保存済みソース フィールド を定義すると、mongot プロセスは mongot の指定フィールドを保存できます。次に、 MongoDB Search クエリで returnStoredSource オプション を使用すると、データベースでドキュメント全体を検索する代わりに、mongot から一致するドキュメントの保存済みフィールドを直接検索できます。
メリット
MongoDB Search を有効にすると、データベースに自動的に同期する統合されたフルマネージド検索エンジンを使用して、データ上に検索を簡単に構築できます。MongoDB Search は、全文検索用の $search や $searchMeta などのMongoDB Search集計パイプラインステージ、セマンティック検索用の $vectorSearch などの MongoDB Search 集計パイプライン ステージを、他のMongoDB集計パイプラインステージやスコアベースの結果ランキングと組み合わせて使用する豊富な問い合わせ言語を提供します。
クラスターにプロビジョニングされるリソースによっては、同じノードに両方の プロセスを配置した方が、別個の 専用ノードで検索プロセスを実行中よりもコスト効率が高くなる場合があります。
制限
データベース mongod と検索プロセス mongot の間でリソース競合が発生する可能性があります。これは、インデックスのパフォーマンスとクエリのレイテンシに悪影響を与える可能性があります。本番環境に対応したアプリケーションとその検索ワークロードをサポートするために、専用の検索ノードに移行します。
コスト
クラスターでMongoDB Search を有効にしても、追加料金や料金は発生しません。ただし、大規模なインデックス付きコレクションまたはインデックス定義では、クラスターのリソース使用率が増加する可能性があります。
Considerations
mongod プロセスと mongot プロセスの両方が 同じノードで実行されるため、特定の状況下で mongot が使用できなくなる可能性があります。 次の表では、潜在的な原因について説明しています。
原因 | 説明 |
|---|---|
クラスター階層のスケーリング - ネットワーク ストレージ | クラスターを増やすアップまたはスケールダウンすると、Atlas は新しいインスタンスをプロビジョニングします。 インスタンスの準備ができると、Atlas はネットワークストレージを接続し、新しいノードで
|
クラスター階層のスケーリング - ローカルSSD | |
Lucene のダウングレード | Lucene のダウングレードが必要になる稀なケースでは、新しい Luceneインデックス形式を読み取れない可能性があります。 |
ストレージの調整 | Atlas クラスター ノードに接続されたネットワークストレージを保持できます。 これにより、 ただし、クラスターがローカル NVMe ディスクを使用している場合、またはその他のまれな状況では、特定のリージョンではネットワークストレージを保持できない場合があります。このような場合、Atlas は最初の同期を実行し、最初の同期が完了するまで検索クエリは失敗します。 |
|
|
新しい | クラスターに新しいノードを追加すると、Atlas は最初の同期を実行して検索インデックスを作成します。 新しい |
インスタンスの再起動または置換 |
|
|
|
本番環境
本番環境に対応したアプリケーションには、次のセクションで説明する配置タイプとノード アーキテクチャを使用することをお勧めします。
この構成は、次のユースケースに最適です。
既存のテスト環境を本番環境に移行する場合は、専用の検索ノードをクラスターに追加します。詳しくは、「 専用検索ノードへの移行 」を参照してください。
新しい本番環境の配置を最初から作成する場合は、 MongoDB Search が利用できるリージョンとゾーンでMongoDB Search をサポートする
M10以上の階層のクラスターを使用し、専用の検索ノードを環境に追加します。詳しくは、専用検索ノードの追加 を参照してください。
- 配置タイプ
本番環境向けのアプリケーションには、
M10、M20、およびそれ以上の専有クラスター階層を使用してください。これらの上位階層のクラスターは、大規模なデータセットや本番環境のワークロードを処理できます。専用の検索ノードも配置することをお勧めします。検索要件が増加する場合は、 MongoDBノードをスケールアップするのと別個に検索配置を増やすアップすることができます。
- クラウドプロバイダーとリージョン
すべての Google Cloud リージョンと、AWS および Azure リージョンのサブセットで検索ノードを使用します。配置には、検索ノードが利用可能なクラウド プロバイダーとリージョンを必ず選択する必要があります。
すべてのクラスター階層は、サポートされているクラウドプロバイダー リージョンで利用できます。選択したクラウド プロバイダーとリージョンは、クラスターで使用できる構成オプションと検索層、およびクラスターの実行コストに影響します。
ノード アーキテクチャ
本番環境では、 MongoDBプロセスとMongoDB Search プロセスが別々のノードで実行されるノードアーキテクチャを推奨します。個別の検索ノードを配置するには、専用検索ノードへの移行を参照してください。
この配置モデルの次の図では、 MongoDB Search mongot プロセスは専用の検索ノードで実行されます。このノードは、mongod プロセスが実行されるクラスター ノードとは別です。

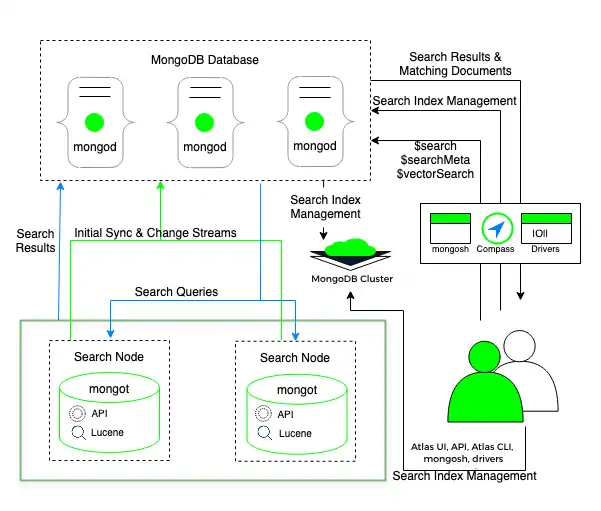
Atlas は、各クラスターまたはクラスター上の各シャードに検索ノードを配置します。たとえば、3 つのシャードを持つクラスターに 2 つの検索ノードを配置すると、Atlas は 6 つの検索ノード(シャードあたり 2 つ)を配置します。また、検索ノードの数と、各検索ノードにプロビジョニングされるリソースの量を構成することもできます。
別個の検索ノードを配置すると、Atlas はインデックス作成用に各 mongot に mongod を自動的に割り当てます。mongot は mongod と通信して、保存しているインデックスの変更をリッスンし、同期します。MongoDB Search は、mongod プロセスと mongot プロセスの両方が 同じノードで実行される配置と同様に、クエリのインデックスを作成して処理します。詳細については、 サポートされているクライアント と クエリとインデックス を参照してください。検索ノードを個別に配置する方法の詳細については、ワークロード分離用の検索ノード を参照してください。
検索ノードに移行すると、Atlas は検索ノードを配置しますが、検索ノード上のクラスター上のすべてのインデックスが正常に構築されるまで、ノードに対するクエリを処理しません。 Atlas が新しいノードにインデックスをビルドする間も、クラスター ノードのインデックスを使用してクエリを処理し続けます。 Atlas は、検索ノードにインデックスを正常にビルドし、クラスター ノード上のインデックスを削除した後にのみ、検索ノードからクエリの処理を開始します。
注意
検索ノードを追加したり、検索階層を変更したりしてクラスターを拡大すると、完全な MongoDB Search インデックスの再構築がトリガーされます。しかし、AWS 上のクラスターに専用の検索ノードがあり、カスタマー キー管理を使用した保管時の暗号化を有効にしていない場合、Atlas は以下の最適化を提供します。
検索ノードを増やすと、Atlas は新しいノードで MongoDB Search インデックス全体を再構築するのではなく、S3 のインデックスの最新コピーを使用します。
既存のノードの場合、Atlas はインデックスファイルの新しい増分リストを定期的に取得してアップロードします。Atlas はインデックスファイルを最大14日間保存します。
これは、Google Cloud または Azure 上の専用検索ノードを持つクラスターではまだ使用できません。
クエリを実行すると、そのクエリは構成済みの読み込み設定に基づいて mongod にルーティングされます。mongod プロセスは、同一ノード上のロード バランサーを通じて検索クエリを転送します。その結果、mongot プロセス全体にリクエストが分散されます。
MongoDB Search mongot プロセスは検索とスコアリングを実行し、一致する結果のドキュメントID とメタデータを mongod に返します。次に、mongod はドキュメント全体で一致する結果の検索を実行し、その結果をクライアントに返します。クエリで $search 同時実行 オプションを使用すると、 MongoDB Search はクエリ内並列処理を有効にします。詳細については、セグメント間でのクエリ実行の並列化 を参照してください。
クラスター上のすべての検索ノードを削除すると、検索クエリー結果の処理が中断されます。詳細については、「 クラスターの変更 」を参照してください。Atlas クラスターを削除すると、Atlas は一時停止し、関連付けられているすべてのMongoDB Search 配置(mongot プロセス)を削除します。
MongoDB Searchインデックスで 保存済みソース フィールド を定義すると、mongot プロセスは mongot の指定フィールドを保存できます。次に、 MongoDB Search クエリで returnStoredSource オプション を使用すると、データベースでドキュメント全体を検索する代わりに、mongot から一致するドキュメントの保存済みフィールドを直接検索できます。
メリット
別個の検索ノードを配置すると次のメリットが得られます。
- 高可用性
- 別個の検索ノードを配置すると、Atlas は少なくとも 2 つの検索ノードを強制して、障害や中断が発生した場合にワークロードが最小限のダウンタイムで機能し続けるようにします。
- スケーラビリティ
検索ノードを個別に配置すると、MongoDB クラスターから独立してストレージと計算能力をスケールできます。これにより、MongoDB とは独立してクエリ負荷をスケールすることも可能です。
検索ノードを水平方向に増やすするには、検索ノードの数を増減します。最小 2 から最大 32 の検索ノードまでプロビジョニングできます。クエリの負荷を分散するために、 MongoDB Search は検索クエリを利用可能なすべての検索ノードに分散します。
検索ノードを垂直方向にスケールするには、フルテキストワークロードをサポートするさまざまな検索階層、CPU、RAM、およびストレージ構成を選択します。
- パフォーマンス
専用の検索ノードを導入することで、
mongodおよびmongotプロセスのパフォーマンスとリソース利用率が向上し、これらのプロセス間のリソース競合が解消されます。専用検索ノードは同時セグメント検索をサポートしているため、 MongoDB Search は複数のインデックスセグメントを同時に検索できます。同時セグメント検索を使用すると、クエリの応答時間が改善される場合があります。
検索ノードのサイズ設定とスケーリングに関するヒント
検索ノードのメモリ要件を決定するには、次の Atlas メトリクスを使用します。
検索インデックスのサイズ
検索ノード上の RAM の合計
検索インデックスが 10 GB で、検索ノードの合計 RAM が 4 GB のアプリケーションを考えてみましょう。この場合、1GBのRAMが他のプロセスで使用され、インデックスデータ用に3GBのみが使用可能な場合、残りの7GBのインデックスデータ(10GB - 3GB = 7GB)は、必要に応じてディスクからページインされます。ディスクからの頻繁なページングは、ページフォールト、ディスク I/O、CPU IOWait の増加を引き起こし、パフォーマンスの低下を招きます。
8GB 以上の RAM を持つ上位のクラスター階層を使用すると、Atlas は検索インデックスの大部分のデータをメモリから提供でき、ディスクの読み取りとページ フォールトを最小化され、パフォーマンスが向上します。
注意
検索ノードに使用されるローカル SSD では、インデックス操作をサポートするために 20% のストレージ オーバーヘッドが必要です。
検索ノードのコスト
MongoDB は(M10 以上)の専有クラスターで個別の検索ノードをサポートします。検索ノードは、コンピュート集約型 NVMe インスタンスに配置されます。少なくとも 2 つのノードを配置する必要があります。ノードごとのリソース使用量が時間単位で毎日請求されます。詳細については、「検索ノードのコスト」を参照してください。
保存時の暗号化の有効化
デフォルトでは、MongoDBプロセスと検索プロセスは同じノードで実行されます。このアーキテクチャでは、カスタマー マネージドの暗号化はデータベースデータに適用されますが、検索インデックスには適用されません。
専用の検索ノードを有効にすると、検索プロセスは別々のノードで実行されます。これにより、検索ノード データの暗号化が有効になり、データベースデータと検索インデックスの両方を同じカスタマー マネージド キーで暗号化して、包括的な暗号化をカバーすることができます。
詳細については、「検索ノードでカスタマーキー管理を有効にする」を参照してください。
注意
この機能は KMS プロバイダー全体で利用できますが、検索ノードは AWS 上にある必要があります。
専用検索ノードの追加
新しいクラスターに専用の検索ノードを追加すると、次のことが可能になります。
クラスターから独立して、検索デプロイメントのサイズとスケールを変更します。
MongoDBデータベースと検索プロセスを同じノードで実行するクラスターで発生する可能性のあるリソース競合を解消します。
専用の検索ノードを追加するには以下の手順に従います。
ノード分離をサポートするクラウドプロバイダーとリージョンで、
M10以上の階層としてクラスターを作成します。詳細については、「クラスターの作成」を参照してください。専用検索ノードは、
M10以上のクラスター階層と、ノード分離 をサポートするクラウドプロバイダーリージョンでのみサポートされます。Search Nodes for workload isolationを有効にし、検索ノードを構成します。
専用検索ノードへの移行
ステージングから本番環境に移行し、専用の検索ノードを追加するには、既存のステージングとプロトタイプ作成の配置に次の変更を加えます。
導入環境でフレックス クラスターを使用している場合は、クラスター階層を上位の階層に変更します。専用検索ノードは
M10以上のクラスター階層でのみサポートされます。検索ノードが利用可能なリージョンにクラスターを配置します。専用の検索ノードは AWS および Azure の一部のリージョン、ならびにサポートされているすべての Google Cloud リージョンで利用可能です。既存のクラスターが検索ノードを利用できないリージョンでホストされている場合、検索ノードを利用できるリージョンにクラスターを移行してください。詳細については「ノード分離をサポートするクラウドプロバイダーのリージョン」をご覧ください。
Search Nodes for workload isolationを有効にして、検索ノードを構成します。 詳しくは、「検索ノードを追加する 」を参照してください。
専用の検索ノードを配置すると、次の一連のアクションが実行されます。
Atlas は検索ノードに検索インデックスを構築し、クラスター ノードからインデックスを削除します。
Atlas は検索クエリを検索ノードにルーティングします。
MongoDB Search は、検索インデックスを使用してクラスターにクエリを処理します。
配置のトラブルシューティング
Failed to Execute search Command エラー
mongod と並行して mongot を実行し、検索ノードを構成しない場合、mongot は次のいずれかのイベント中に終了し、Failed to Execute search Command エラーを返す可能性があります。
クラスターのスケールアップ
ノード フェイルオーバー
アップグレード
mongot
mongot を専用の検索ノードにデプロイすると、mongod は検索クエリをmongot プロセスがアクティブな正常なノードのみにルーティングするプロキシを使用します。