次のスコア変更オプションはすべての演算子で使用できます。 詳細と例については、次のいずれかのオプションをクリックしてください。
boost
boostオプションは、結果の基本スコアに特定の数値またはドキュメント内の数値フィールドの値を乗算します。 たとえば、 boostを使用すると、結果内の一致する特定のドキュメントの重要性を高めることができます。
フィールド
boostオプションは次のフィールドを取ります。
フィールド | タイプ | 必要性 | 説明 |
|---|---|---|---|
| float | 条件付き | デフォルトの基本スコアに乗じる数値。 値は正の数である必要があります。 |
| string | 条件付き | デフォルトの基本スコアに乗じる値を持つ数値フィールドの名前。 |
| float | 任意 |
|
例
次の例では、 sample_mflixデータベース内の moviesコレクションを使用します。クラスターに サンプルデータセットがある場合は、 MongoDB Search defaultインデックスを作成し、クラスターで例クエリを実行できます。
サンプル複合クエリは、ある検索条件の重要性を別の検索条件よりも高める方法を示しています。 クエリには、 titleとscoreを除くすべてのフィールドを除外する$projectステージが含まれています。
次の例では、 複合 演算子は テキスト 演算子を使用して、 フィールドとHelsinki フィールドで用語plot titleを検索しています。titleフィールドのクエリでは、 scoreとboostオプションを併用して、 valueフィールドに指定されているようにスコア結果に 3 を掛けます。
1 db.movies.aggregate([ 2 { 3 "$search": { 4 "compound": { 5 "should": [{ 6 "text": { 7 "query": "Helsinki", 8 "path": "plot" 9 } 10 }, 11 { 12 "text": { 13 "query": "Helsinki", 14 "path": "title", 15 "score": { "boost": { "value": 3 } } 16 } 17 }] 18 } 19 } 20 }, 21 { 22 "$limit": 5 23 }, 24 { 25 "$project": { 26 "_id": 0, 27 "title": 1, 28 "plot": 1, 29 "score": { "$meta": "searchScore" } 30 } 31 } 32 ])
このクエリは次の結果を返します。ここでは、 titleがクエリタームに一致するドキュメントのスコアが、その基本値から3を掛けて計算されます。
[ { plot: 'Epic tale about two generations of men in a wealthy Finnish family, spanning from the 1960s all the way through the early 1990s. The father has achieved his position as director of the ...', title: 'Kites Over Helsinki', score: 12.2470121383667 }, { plot: 'Alex is Finlander married to an Italian who works as a taxi driver in Berlin. One night in his taxi come two men with a briefcase full of money. Unluckily for Alex, they are being chased by...', title: 'Helsinki-Naples All Night Long', score: 9.56808090209961 }, { plot: 'The recession hits a couple in Helsinki.', title: 'Drifting Clouds', score: 4.5660295486450195 }, { plot: 'Two teenagers from Helsinki are sent on a mission by their drug dealer.', title: 'Sairaan kaunis maailma', score: 4.041563034057617 }, { plot: 'A murderer tries to leave his criminal past in East Helsinki and make a new life for his family', title: 'Bad Luck Love', score: 3.6251673698425293 } ]
次の例では、 複合 演算子は テキスト 演算子を使用して、 フィールドとHelsinki フィールドで用語plot titleを検索しています。titleフィールドに対するクエリでは、 scoreとboostオプションを使用して、スコア結果にpathの数値フィールドimdb.ratingを乗じます。 数値フィールドが指定されたpathに見つからない場合、 演算子はドキュメントのスコアに3を乗算します。
1 db.movies.aggregate([ 2 { 3 "$search": { 4 "compound": { 5 "should": [{ 6 "text": { 7 "query": "Helsinki", 8 "path": "plot" 9 } 10 }, 11 { 12 "text": { 13 "query": "Helsinki", 14 "path": "title", 15 "score": { 16 "boost": { 17 "path": "imdb.rating", 18 "undefined": 3 19 } 20 } 21 } 22 }] 23 } 24 } 25 }, 26 { 27 "$limit": 5 28 }, 29 { 30 "$project": { 31 "_id": 0, 32 "title": 1, 33 "plot": 1, 34 "score": { "$meta": "searchScore" } 35 } 36 } 37 ])
このクエリは次の結果を返します。ここでは、 titleフィールドがクエリタームと一致するドキュメントのスコアが、その基本値から数値フィールドimdb.ratingまたは3 (フィールドが でない場合)の値を掛けて計算されます。次のドキュメントに見つかりました。
[ { plot: 'Epic tale about two generations of men in a wealthy Finnish family, spanning from the 1960s all the way through the early 1990s. The father has achieved his position as director of the ...', title: 'Kites Over Helsinki', score: 24.902257919311523 }, { plot: 'Alex is Finlander married to an Italian who works as a taxi driver in Berlin. One night in his taxi come two men with a briefcase full of money. Unluckily for Alex, they are being chased by...', title: 'Helsinki-Naples All Night Long', score: 20.411907196044922 }, { plot: 'The recession hits a couple in Helsinki.', title: 'Drifting Clouds', score: 4.5660295486450195 }, { plot: 'Two teenagers from Helsinki are sent on a mission by their drug dealer.', title: 'Sairaan kaunis maailma', score: 4.041563034057617 }, { plot: 'A murderer tries to leave his criminal past in East Helsinki and make a new life for his family', title: 'Bad Luck Love', score: 3.6251673698425293 } ]
constant
constantオプションは、基本スコアを指定された数値に置き換えます。
注意
constantとboostオプションは併用しないでください。
例
次の例では、sample_mflix.movies コレクションのデフォルト インデックスを使用して、plot title複合 演算子を使用して フィールドと フィールドをクエリします。クエリでは、テキスト演算子はscoreをconstantオプションと併用して、クエリがtitleフィールドのみに一致する結果のすべてのスコア結果を5に置き換えます。
1 db.movies.aggregate([ 2 { 3 "$search": { 4 "compound": { 5 "should": [{ 6 "text": { 7 "query": "tower", 8 "path": "plot" 9 } 10 }, 11 { 12 "text": { 13 "query": "tower", 14 "path": "title", 15 "score": { "constant": { "value": 5 } } 16 } 17 }] 18 } 19 } 20 }, 21 { 22 "$limit": 5 23 }, 24 { 25 "$project": { 26 "_id": 0, 27 "title": 1, 28 "plot": 1, 29 "score": { "$meta": "searchScore" } 30 } 31 } 32 ])
上記のクエリは次の結果を返します。ここでは、 titleフィールドに対してクエリに一致するドキュメントのスコアは、指定されたconstant値のみに置き換えられます。
1 [ 2 { 3 plot: 'Several months after witnessing a murder, residents of Tower Block 31 find themselves being picked off by a sniper, pitting those lucky enough to be alive into a battle for survival.', 4 title: 'Tower Block', 5 score: 8.15460205078125 6 }, 7 { 8 plot: "When a group of hard-working guys find out they've fallen victim to their wealthy employer's Ponzi scheme, they conspire to rob his high-rise residence.", 9 title: 'Tower Heist', 10 score: 5 11 }, 12 { 13 plot: 'Toru Kojima and his friend Koji are young student boys with one thing in common - they both love to date older women. Koji is a playboy with several women, young and older, whereas Toru is a romantic with his heart set on on certain lady.', 14 title: 'Tokyo Tower', 15 score: 5 16 }, 17 { 18 plot: 'A middle-aged mental patient suffering from a split personality travels to Italy where his two personalities set off all kinds of confusing developments.', 19 title: 'The Leaning Tower', 20 score: 5 21 }, 22 { 23 plot: 'A documentary that questions the cost -- and value -- of higher education in the United States.', 24 title: 'Ivory Tower', 25 score: 5 26 } 27 ]
embedded
注意
このオプションはembeddedDocument演算子でのみ使用できます。
embeddedオプションを使用すると、次の方法を構成できます。
一致する複数の埋め込みドキュメントのスコアを集計します。
一致する埋め込みドキュメントのスコアを集計した後、 embeddedDocument演算子のスコアを変更します。
注意
MongoDB Search embeddedDocuments 型、 embeddedDocument 演算子、および embedded スコアリング オプションはプレビュー段階です。
フィールド
embeddedオプションは次のフィールドを取ります。
フィールド | タイプ | 必要性 | 説明 |
|---|---|---|---|
| string | 任意 | 一致する埋め込みドキュメントのスコアを組み合わせる方法を設定します。 値は、次の集計戦略のいずれかである必要があります。
省略した場合、このフィールドのデフォルトは |
| 任意 | 集計戦略を適用した後に適用するスコアの変更を指定します。 |
例
次のサンプル クエリでは、 sample_analytics.transactionsコレクションでdefaultという名前のインデックスを使用します。 このインデックスは、embeddedDocuments transactions配列内のドキュメントに タイプを構成し、 フィールドとstring フィールドにはtransactions.symbol transactions.transaction_codeタイプを構成します。
例
{ "mappings": { "dynamic": true, "fields": { "transactions": { "dynamic": true, "fields": { "symbol": { "type": "string" }, "transaction_code": { "type": "string" } }, "type": "embeddedDocuments" } } } }
ドキュメントの配列を含むtransactionsフィールドのサンプル クエリには、出力を10の結果に制限する$limitステージと、次の操作を行う$projectステージが含まれています。
account_idとtransaction_countを除くすべてのフィールドを除外します。集計戦略とさらにスコアの変更を適用する
scoreという名前のフィールドを追加します。注意
functionは、embeddedDocument 演算子のoperatorのscoreオプション内で使用できます。ただし、式がpathオプションを必要とする場合、式のpathとして指定する数値フィールドはembeddedDocument演算子のpath内になければなりません。たとえば、次の例クエリでは、transactions.amountscore複合演算子 のオプション内で指定されたフィールド24 が、embeddedDocument行の演算子のパスtransactions4内にあります。
クエリは、 AMDを購入したアカウントを検索し、最大のAMD回の購入(共有数)に、アカウントがこの期間に行ったトランザクションの数のlog1pの値を掛けます。 以下に基づいてアカウントをランク付けします。
1 回のトランザクションで購入された
AMDの数過去の期間のトランザクションの数
1 db.transactions.aggregate({ 2 "$search": { 3 "embeddedDocument": { 4 "path": "transactions", 5 "operator": { 6 "compound": { 7 "must": [ 8 { 9 "text": { 10 "path": "transactions.symbol", 11 "query": "amd" 12 } 13 }, 14 { 15 "text": { 16 "path": "transactions.transaction_code", 17 "query": "buy" 18 } 19 } 20 ], 21 "score": { 22 "function": { 23 "path": { 24 "value": "transactions.amount", 25 "undefined": 1.0 26 } 27 } 28 } 29 } 30 }, 31 "score": { 32 "embedded": { 33 "aggregate": "maximum", 34 "outerScore": { 35 "function": { 36 "multiply": [ 37 { 38 "log1p": { 39 "path": { 40 "value": "transaction_count" 41 } 42 } 43 }, 44 { 45 "score": "relevance" 46 } 47 ] 48 } 49 } 50 } 51 } 52 } 53 } 54 }, 55 { "$limit": 10 }, 56 { 57 "$project": { 58 "_id": 0, 59 "account_id": 1, 60 "transaction_count": 1, 61 "score": { $meta: "searchScore" } 62 } 63 })
MongoDB Search では、過去の期間に多くのトランザクションを実行し、1 回のトランザクションで多くの AMD を購入したアカウントを上位にランク付けします。
1 [ 2 { account_id: 467651, transaction_count: 99, score: 19982 }, 3 { account_id: 271554, transaction_count: 96, score: 19851.822265625 }, 4 { account_id: 71148, transaction_count: 99, score: 19840 }, 5 { account_id: 408143, transaction_count: 100, score: 19836.76953125 }, 6 { account_id: 977774, transaction_count: 98, score: 19822.64453125 }, 7 { account_id: 187107, transaction_count: 96, score: 19754.470703125 }, 8 { account_id: 492843, transaction_count: 97, score: 19744.998046875 }, 9 { account_id: 373169, transaction_count: 93, score: 19553.697265625 }, 10 { account_id: 249078, transaction_count: 89, score: 19436.896484375 }, 11 { account_id: 77690, transaction_count: 90, score: 19418.017578125 } 12 ]
function
function オプションを使用すると、数値フィールドを使用してドキュメントの最終スコアを変更できます。式を通じて最終スコアを計算するための数値フィールドを指定できます。関数スコアの最終結果が 0 未満の場合、 MongoDB Search はスコアを 0 に置き換えます。
注意
embeddedDocument演算子のoperatorのscoreオプション内でfunctionを使用できます。 ただし、 pathオプションを必要とする関数スコア式の場合、式のpathとして指定する数値フィールドは、 embeddedDocument演算子のpath内になければなりません。
式
ドキュメントの最終スコアを変更するには、 functionオプションとともに次の式を使用します。
一連の数値を加算または乗算する算術式。
関数スコアで定数を許可する定数式 。
指定されたレートで乗算してスコアを減少または減少させます。
インデックス付き数値フィールド値を関数スコアに組み込む パス式 。
スコア式 。MongoDB Search によって割り当てられた関連性スコアを返します。
単位 式: 1 つの引数を取る式です。MongoDB Search では、指定された数値のログ10(x) またはログ10(x+1) を計算できます。
注意
MongoDB Search 関数のスコアは常に float 値であり、数値が非常に大きい場合や小さい場合は精度が失われる可能性があります。
算術式は、一連の数値を加算または乗算します。 たとえば、算術式を使用して、データエンタープライズパイプラインの数値フィールドを介して関連性ランキングを変更できます。 次のいずれかのオプションを含める必要があります。
注意
undefinedと評価される算術式は定数値に置き換えることはできません。
定数式を使用すると、関数スコアで定数が許容されます。 たとえば、 constantを使用して、データエンタープライズパイプラインの数値を介して関連性ランキングを変更できます。 次のオプションを含める必要があります。
オプション | タイプ | 説明 |
|---|---|---|
| float | 固定値を示す数値。MongoDB Search は負の値をサポートしています。 |
例
{ "function": { "constant": -23.78 } }
因果関係式を使用すると、指定された基点からの数値フィールド値の距離に基づいて、ドキュメントの最終スコアを減少させたり、乗算して削減したりできます。 decayは次のように計算されます。

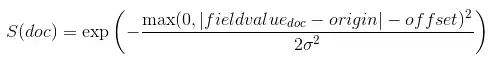
ここで、スコアはorigin±offsetからの距離scaleにある値decayになるように計算されます。

たとえば、 gaussを使用すると、ドキュメントの最新性に基づいてドキュメントの関連スコアを調整したり、上位のランキングに影響を与える日付に基づいてドキュメントの関連スコアを調整できます。 gaussは次のオプションを取ります。
フィールド | タイプ | 必要性 | 説明 |
|---|---|---|---|
| double | 任意 | スコアを乗算するレート。 値は、 数値フィールド値( |
| double | 任意 | 基準からの距離を決定するために使用する数値。 減少操作は、距離が |
| double | 必須 | 距離を計算する基準点。 |
| 必須 | 基本スコアを乗算するために使用する値を持つ数値フィールドの名前。 | |
| double | 必須 |
|
例
{ "function": { "gauss": { "path": { "value": "rating", "undefined": 50 }, "origin": 95, "scale": 5, "offset": 5, "decay": 0.5 } } }
最大評価は 100 であるとします。MongoDB Search では、ドキュメント内の ratingフィールドを使用してスコアを減少させます。
90から100の間の評価を持つドキュメントの現在のスコアを保持します。評価が
90未満のドキュメントに対して、現在のスコアに0.5を乗算します。評価が
85未満のドキュメントに対して、現在のスコアに0.25を乗じます。
パス式は、インデックス付き数値フィールド値を関数スコアに組み込みます。 これはstringまたはobjectのいずれかです。
stringの場合、値はパス式を検索する数値フィールドの名前です。
例
{ "function": { "path": "rating" } }
MongoDB Search は、ドキュメントの最終スコアに ratingフィールドの数値を組み込んでいます。
objectの場合、パス式は次のオプションを取ります。
オプション | タイプ | 必要性 | 説明 |
|---|---|---|---|
| string | 必須 | 数値フィールドの名前。 フィールドには負の数値を含めることができます。 |
| float | 任意 |
|
例
{ "function": { "path": {"value": "quantity", "undefined": 2} } }
MongoDB Search は、ドキュメントの最終スコアに、quantityフィールドまたは 2 (ドキュメントに quantityフィールドが存在しない場合)の数値を組み込みます。
スコア式は、クエリの関連性スコア( MongoDB Search が関連性に基づいてドキュメントを割り当てるスコア)を表します。これは、ドキュメントの現在のスコアと同じです。次のオプションを含める必要があります。
オプション | タイプ | 説明 |
|---|---|---|
| string | クエリの関連性スコアの値。 値は |
例
{ "function": { "score": "relevance" } }
非単一式は、単一の引数を取る式です。MongoDB Search では、単調式を使用して、指定された数値のログ10(x) またはログ10(x+1) を計算できます。例、log1p を使用して、ドキュメント一般度スコアによって関連性スコアを制御することができます。次のいずれかのオプションを含める必要があります。
オプション | タイプ | 説明 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 数値の対数10を計算します。 例: 単位式の構文 前の例では、 MongoDB Search は、
単位式の構文 前の例では、 MongoDB Search は定数式 | |||||||||||||||||||
| 数値に 単位式の構文 前の例では、 MongoDB Search は |
例
次の例では、 sample_mflix.moviesコレクションのデフォルト インデックスを使用してtitleフィールドをクエリします。 サンプル クエリには、出力を5の結果に制限する$limitステージと、 titleとscoreを除くすべてのフィールドを除外する$projectステージが含まれています。
例
この例では、テキスト演算子はscoreとfunctionオプションを使用して次の値を乗算します。
パス式の数値。ドキュメント内の
imdb.ratingフィールドまたは2フィールド(ドキュメントにimdb.ratingフィールドがない場合)の値関連性スコア、またはドキュメントの現在のスコア
db.movies.aggregate([{ "$search": { "text": { "path": "title", "query": "men", "score": { "function":{ "multiply":[ { "path": { "value": "imdb.rating", "undefined": 2 } }, { "score": "relevance" } ] } } } } }, { $limit: 5 }, { $project: { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } }])
このクエリは、スコアが指定されたfunction値に置き換えられた次の結果を返します。
{ "title" : "Men...", "score" : 23.431293487548828 } { "title" : "12 Angry Men", "score" : 22.080968856811523 } { "title" : "X-Men", "score" : 21.34803581237793 } { "title" : "X-Men", "score" : 21.34803581237793 } { "title" : "Matchstick Men", "score" : 21.05954933166504 }
例
次の例では、テキスト演算子はscoreとfunctionオプションを使用して、ドキュメントの現在のスコアを3の定数数値に置き換えます。
db.movies.aggregate([ { "$search": { "text": { "path": "title", "query": "men", "score": { "function":{ "constant": 3 } } } } }, { $limit: 5 }, { $project: { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } } ])
このクエリは、スコアが指定されたfunction値に置き換えられた次の結果を返します。
{ "title" : "Men Without Women", "score" : 3 } { "title" : "One Hundred Men and a Girl", "score" : 3 } { "title" : "Of Mice and Men", "score" : 3 } { "title" : "All the King's Men", "score" : 3 } { "title" : "The Men", "score" : 3 }
例
次の例では、テキスト演算子は、結果内のドキュメントの関連性スコアを減少させるために、 scoreとfunctionオプションを併用します。
クエリでは、 imdb.ratingフィールド値または4.6 imdb.ratingを持つドキュメント(ドキュメントにscale フィールドが存在しない場合)、 からの距離は5 originであり、 にプラスまたはマイナス9.5 offsetであるため、つまり0 である場合、 MongoDB Search は から始まるdecay0.5 を使用してスコアを乗算する必要があります。このクエリには、出力を最大 10 の結果に制限する $limit ステージと、結果に imdb.ratingフィールドを追加する $project ステージが含まれています。
db.movies.aggregate([ { "$search": { "text": { "path": "title", "query": "shop", "score": { "function":{ "gauss": { "path": { "value": "imdb.rating", "undefined": 4.6 }, "origin": 9.5, "scale": 5, "offset": 0, "decay": 0.5 } } } } } }, { "$limit": 10 }, { "$project": { "_id": 0, "title": 1, "imdb.rating": 1, "score": { "$meta": "searchScore" } } } ])
このクエリは次の結果を返します。
[ { title: 'The Shop Around the Corner', imdb: { rating: 8.1 }, score: 0.9471074342727661 }, { title: 'Exit Through the Gift Shop', imdb: { rating: 8.1 }, score: 0.9471074342727661 }, { title: 'The Shop on Main Street', imdb: { rating: 8 }, score: 0.9395227432250977 }, { imdb: { rating: 7.4 }, title: 'Chop Shop', score: 0.8849083781242371 }, { title: 'Little Shop of Horrors', imdb: { rating: 6.9 }, score: 0.8290896415710449 }, { title: 'The Suicide Shop', imdb: { rating: 6.1 }, score: 0.7257778644561768 }, { imdb: { rating: 5.6 }, title: 'A Woman, a Gun and a Noodle Shop', score: 0.6559237241744995 }, { title: 'Beauty Shop', imdb: { rating: 5.4 }, score: 0.6274620294570923 } ]
前のクエリで使用されたガus式の結果と、 MongoDB Search によって結果で返された関連性スコアを比較するには、次のクエリを実行します。
db.movies.aggregate([ { "$search": { "text": { "path": "title", "query": "shop" } } }, { "$limit": 10 }, { "$project": { "_id": 0, "title": 1, "imdb.rating": 1, "score": { "$meta": "searchScore" } } } ])
このクエリは次の結果を返します。
[ { title: 'Beauty Shop', imdb: { rating: 5.4 }, score: 4.111973762512207 }, { imdb: { rating: 7.4 }, title: 'Chop Shop', score: 4.111973762512207 }, { title: 'The Suicide Shop', imdb: { rating: 6.1 }, score: 3.5363259315490723 }, { title: 'Little Shop of Horrors', imdb: { rating: 6.9 }, score: 3.1020588874816895 }, { title: 'The Shop Around the Corner', imdb: { rating: 8.1 }, score: 2.762784481048584 }, { title: 'The Shop on Main Street', imdb: { rating: 8 }, score: 2.762784481048584 }, { title: 'Exit Through the Gift Shop', imdb: { rating: 8.1 }, score: 2.762784481048584 }, { imdb: { rating: 5.6 }, title: 'A Woman, a Gun and a Noodle Shop', score: 2.0802340507507324 } ]
例
次の例では、テキスト演算子はscoreとfunctionオプションを使用して、クエリの関連性スコアを数値フィールドimdb.ratingまたは4.6の値に置き換えますimdb.ratingフィールドがドキュメントに存在する。
db.movies.aggregate([{ "$search": { "text": { "path": "title", "query": "men", "score": { "function":{ "path": { "value": "imdb.rating", "undefined": 4.6 } } } } } }, { $limit: 5 }, { $project: { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } }])
このクエリは、スコアが指定されたfunction値に置き換えられた次の結果を返します。
{ "title" : "12 Angry Men", "score" : 8.899999618530273 } { "title" : "The Men Who Built America", "score" : 8.600000381469727 } { "title" : "No Country for Old Men", "score" : 8.100000381469727 } { "title" : "X-Men: Days of Future Past", "score" : 8.100000381469727 } { "title" : "The Best of Men", "score" : 8.100000381469727 }
例
次の例では、テキスト演算子はscoreをfunctionオプションとともに使用して、ドキュメントの現在のスコアと同じ関連性スコアを返します。
db.movies.aggregate([{ "$search": { "text": { "path": "title", "query": "men", "score": { "function":{ "score": "relevance" } } } } }, { "$limit": 5 }, { "$project": { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } }])
このクエリは、スコアが指定されたfunction値に置き換えられた次の結果を返します。
{ "title" : "Men...", "score" : 3.4457783699035645 } { "title" : "The Men", "score" : 2.8848698139190674 } { "title" : "Simple Men", "score" : 2.8848698139190674 } { "title" : "X-Men", "score" : 2.8848698139190674 } { "title" : "Mystery Men", "score" : 2.8848698139190674 }
例
次の例では、テキスト演算子はscoreをfunctionオプションとともに使用して、 imdb.ratingフィールドまたは10のログ10 (ドキュメントにimdb.ratingフィールドが存在しない場合)を計算します。
db.movies.aggregate([{ "$search": { "text": { "path": "title", "query": "men", "score": { "function": { "log": { "path": { "value": "imdb.rating", "undefined": 10 } } } } } } }, { "$limit": 5 }, { "$project": { "_id": 0, "title": 1, "score": { "$meta": "searchScore" } } }])
このクエリは、スコアが指定されたfunction値に置き換えられた次の結果を返します。
{ "title" : "12 Angry Men", "score" : 0.9493899941444397 } { "title" : "The Men Who Built America", "score" : 0.9344984292984009 } { "title" : "No Country for Old Men", "score" : 0.9084849953651428 } { "title" : "X-Men: Days of Future Past", "score" : 0.9084849953651428 } { "title" : "The Best of Men", "score" : 0.9084849953651428 }