Atlas Data Federation の概要
Atlas Data Federation について
Atlas Data Federation は、MongoDB Atlas 内および外のさまざまなソース全体でデータをネイティブにクエリ、変換、移動できる分散クエリ エンジンです。
重要な概念
Federated Database Instanceフェデレーティッドデータベースインスタンスは、Atlas Data Federation の配置です。各フェデレーティッドデータベースインスタンスには、データ ストア内のデータにマップされる仮想データベースとコレクションが含まれています。
Data Storeデータストアとは、データのロケーションを指します。 Atlas Data Federation は次のデータ ストアをサポートしています。
Atlas cluster
Atlas オンライン アーカイブ
Amazon Web Services S3バケット
Azure BLOB ストレージ
Google Cloud PlatformGoogle Cloud Platformストレージ
HTTPおよびHTTPSエンドポイント
Atlas Data Federation のアーキテクチャ

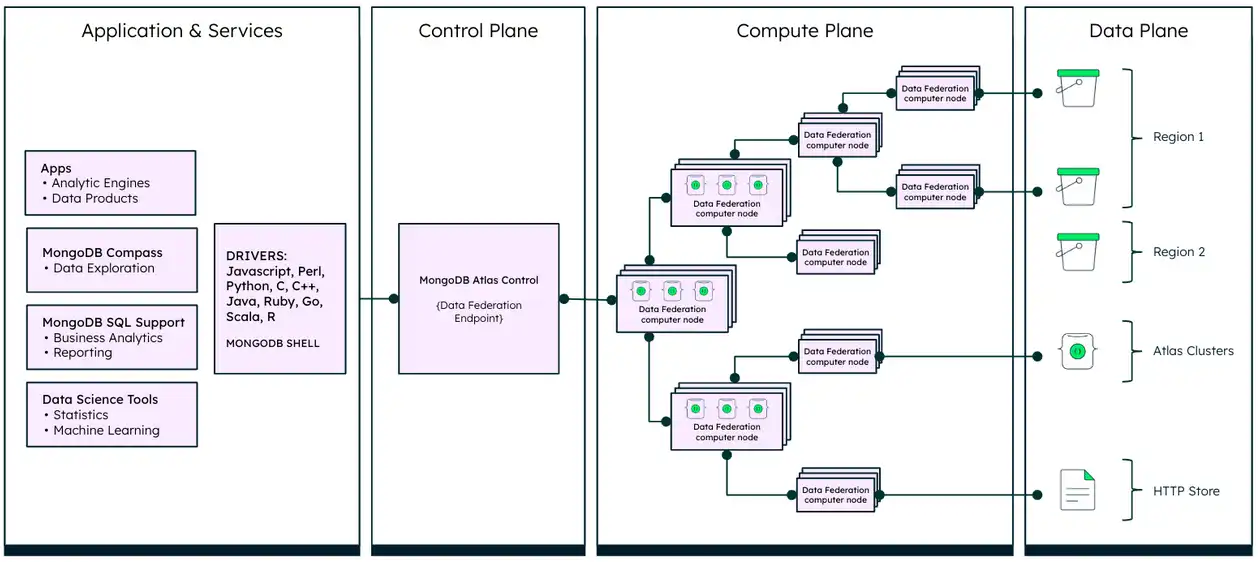
前の図の Data Plane は、データが存在する場所です。Atlas Data Federation を構成して、さまざまなストレージサービスのデータにアクセスできます。 具体的には、Atlas Data Federation を構成して、 Amazon Web Servicesリージョン、 Azure Blob Storage コンテナ、 GCPストレージ バケット、Atlas クラスター、 HTTPおよび HTTPS URL 、Atlas Online Archive からAmazon Web Services S バケットのデータにアクセスできます。3データストアにアクセスするための Atlas Data Federation の構成の詳細については、「 フェデレーティッドデータベースインスタンスのデータ ストアの定義 」を参照してください。
次に、フェデレーティッドデータベースインスタンスのロールベースのアクセス制御を設定できます。 クライアントがフェデレーティッドデータベースインスタンスに接続する方法は、グローバル接続オプションを使用するか、特定のリージョンに固定することで制御できます。 詳しくは、「フェデレーティッドデータベースインスタンスへの接続の構成 」を参照してください。
Atlas Data Federation は、データローカリティを維持し、可能な場合はローカル計算を最大化して、データ転送を最小限に抑え、パフォーマンスを最適化します。 前の図のコンピュート プランは、Atlas Data Federation がすべてのリクエストを処理する場所を示しています。 Atlas Data Federation は、Atlas Data Federation がクエリのデータを処理できるデータに最も近いリージョンにエージェントの従量制プールを提供します。 サポートされているリージョンの詳細については、「 Atlas Data Federation のリージョン 」を参照してください。
Atlas Data Federation はシステム内にデータを保持せず、クエリが処理されると、フェデレーティッドデータベースインスタンスにのみメタデータを保存します。 これにより、データ所有権規則に準拠し、法定要件に従ってデータを保存および処理することが保証されます。
Atlas Control Plane と同じである前図の Control Plane は、Atlas Data Federation がユーザーのリクエストをバランス化し、最終結果を集計します。
Atlas Data Federation は、処理のためにすべてのデータをコンピューティング ノードに転送するのではなく、基礎となるストレージ サービス上でクエリの一部を直接実行します。 さらに、クエリを実行すると、それは最初に Data Federation のフロントエンド コンポーネントによって処理されます。クエリはクエリを計画し、その後、バックエンドのノードに配布します。 その後、バックエンド ノードはデータ ストアに直接アクセスしてクエリ ロジックを実行し、結果をフロントエンドに返します。 このプロセスにより、移動されるデータ量が減るため、プロセス全体が高速化、低コストになります。 詳細については、「フェデレーティッドデータベースインスタンスのクエリ 」を参照してください。
クエリのパフォーマンスを最適化するために、Atlas Data Federation は次の処理を実行します。
Cloud Object Storage では、データのパーティション分割を使用して、クエリ パラメータに基づいて処理が必要なファイルを選択します。 詳細については、「 S3 データのパスの定義 」および「 パーティション属性タイプの使用」を参照してください。 さらに、Parquet メタデータを使用して、行グループ選択または列プロジェクションを使用して Parquet ファイルからスキャンされるデータ量を削減します。 詳細については、「 Perquet データ形式 」を参照してください。
Atlas クラスターの場合、クラスターへのクエリの可能な限り「プッシュダウン」が試行されます。 たとえば、集計パイプラインに
$matchステージがあり、ローカルで処理できる場合、Atlas Data Federation は Atlas クラスターでそのステージの処理を試み、結果のドキュメントのみを後続のステージの処理のためにフェデレーティッドレイヤーに返します。 詳しくは、 「 Atlas クラスターでのデータのクエリ 」を参照してください。
詳しくは、「クエリ パフォーマンスの最適化 」を参照してください。
MongoDB 言語固有のドライバー、 mongosh 、およびAtlas SQLを使用して Atlas Data Federation に接続できます。 詳しくは、「フェデレーティッドデータベースインスタンスへの接続 」を参照してください。
使用例
Atlas Data Federation を使用すると、次のことが可能になります。
AtlasAtlas クラスター データを、CSV AmazonAmazon Web Services 3AzureWeb Services S バケットまたはAzure Blob ストレージに書き込まれた Perquet または CSV ファイルにコピーします。
複数の Atlas クラスターとオンライン アーカイブにわたってクエリを実行し、Atlas データの全体的なビューを取得します。
AtlasAtlas クラスター、 AmazonAmazon Web Services Web Services S3 バケット、Azure Azure Blob ストレージ全体の集計からデータを具体化します。
Amazon WebAmazon Web Services 3AzureServices S バケットまたはAzure Blob ストレージから AtlasAtlas クラスターにデータを読み取り、インポートします。
Atlas Data Federation のリージョン
注意
請求額の超過請求を防ぐには、Atlas Data Federation Amazon Web ServicesAzureS3 またはAzure Blob Storage データソースと同じ または リージョンに作成します。Amazon Web ServicesS3 はAmazon Web Services で作成されたフェデレーティッドデータベースインスタンスのみをクエリでき、 で作成されたフェデレーティッドデータベースインスタンスのみを使用してAzure BlobAzure ストレージをクエリできます。
Atlas Data Federation は、次のいずれかのリージョンを通じてフェデレーティッドデータベースリクエストをルーティングします。
Atlas Data Federation のリージョン | AWS リージョン |
|---|---|
Virginia, USA | us-east-1 |
米国ワシントン州 | us-west-2 |
サンパウロ(ブラジル) | sa-east-1 |
アイルランド | eu-west-1 |
英国(ソウル) | eu-west-2 |
フランクフルト(ドイツ) | eu-central-1 |
Tokyo, Japan | ap-northeast-1 |
ムバイ(インド) | ap-outth-1 |
香港 | ap-sautheast-1 |
オーストラリア、シドニー | ap-sautheast-2 |
モントリオール(カナダ) | ca-central-1 |
Atlas Data Federation のリージョン | Azureリージョン |
|---|---|
Virginia, USA |
|
オランダ語 |
|
Atlas Data Federation のリージョン | Google Cloud Platformリージョン |
|---|---|
ベルギー |
|
Iowa, USA |
|
注意
フェデレーティッドクエリを実行すると料金が発生します。 詳細については、「 Data Federation のコスト 」を参照してください。