GridFS
項目一覧
Overview
このガイドでは、 GridFS仕様を使用して MongoDB に大容量ファイルを保存、検索する方法を学びます。 GridFS は大きなファイルをチャンクに分割し、各チャンクを別々のドキュメントとして保存します。 GridFS でファイルをクエリすると、ドライバーは必要に応じてチャンクを再アセンブルします。 GridFS のドライバー実装は、ファイル ストレージの操作と組織を管理する抽象化です。
ファイルのサイズがBSONドキュメントサイズ制限の16 MB を超える場合は、 GridFSを使用します。 GridFSは、ファイル全体をメモリにロードせずにファイルにアクセスする目的でも役立ちます。 GridFSがユースケースに適しているかどうかの詳細については、 GridFSサーバーのマニュアル ページ を参照してください。
GridFS の仕組み
GridFS により、ファイルはバケット(ファイルのチャンクとそれを説明する情報を含む MongoDB コレクションのグループ)に整理されます。 バケットには以下のコレクションが含まれています。
バイナリ ファイルのチャンクを保存する
chunksコレクション。ファイルのメタデータを保存する
filesコレクション。
新しい GridFS バケットを作成すると、ドライバーによって前述のコレクションが作成されます。 別のバケット名を指定しない限り、コレクション名の前にデフォルトのバケット名fsがコレクション名の前に付きます。 ドライバーは最初の書込み (write) 操作中に新しい GridFS バケットを作成します。
また、ファイルや関連メタデータを効率的に取得できるように、各コレクションにインデックスも作成します。 ドライバーは、インデックスがまだ存在しない場合、およびバケットが空の場合にインデックスを作成します。 GridFS インデックスの詳細については、サーバーのマニュアル ページ「 GridFS インデックス 」を参照してください。
GridFS を使用してファイルを保存する場合、ドライバーはファイルを小さなチャンクに分割し、各ファイルはchunksコレクションに個別のドキュメントとして表されます。 また、ファイル ID、ファイル名、およびその他のファイル メタデータを含むドキュメントをfilesコレクションに作成します。 次の図は、GridFS がアップロードされたファイルを分割する方法を示しています。
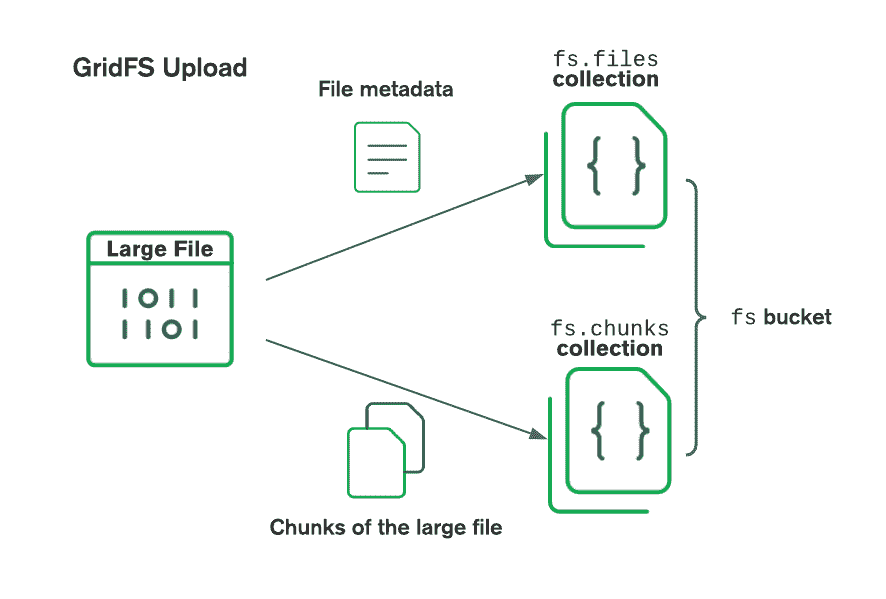
ファイルを検索する際、GridFS は指定されたバケット内のfilesコレクションからメタデータを取得し、その情報を使用してchunksコレクション内のドキュメントからファイルを再構築します。 ファイルをメモリに読み込んだり、ストリームに出力したりすることもできます。
GridFS の使用
GridFS 操作とその実行方法については、次のセクションを参照してください。
GridFS バケットの作成
GridFS からファイルを保存または検索するには、バケットを作成するか、MongoDB database 上の既存のバケットへの参照を取得します。 GridFSBucketインスタンスを作成するには、データベース パラメータを指定してNewBucket()メソッドを呼び出します。
db := client.Database("myDB") bucket, err := gridfs.NewBucket(db) if err != nil { panic(err) }
注意
GridFS バケットがすでに存在する場合、 NewBucket()メソッドは新しいバケットをインスタンス化するのではなく、バケットへの参照を返します。
デフォルトでは、新しいバケットの名前はfsです。 カスタム名でバケットをインスタンス化するには、次のように、 BucketOptionsインスタンスでSetName()メソッドを呼び出します。
db := client.Database("myDB") opts := options.GridFSBucket().SetName("custom name") bucket, err := gridfs.NewBucket(db, opts) if err != nil { panic(err) }
ファイルのアップロード
次のいずれかの方法で、ファイルを GridFS バケットにアップロードできます。
入力ストリームから読み取る
UploadFromStream()メソッドを使用します。出力ストリームに書き込む
OpenUploadStream()メソッドを使用します。
どちらのアップロード プロセスでも、 UploadOptionsのインスタンスに関する構成情報を指定できます。 UploadOptionsフィールドの完全なリストについては、 API ドキュメントを参照してください。
入力ストリームによるアップロード
入力ストリームを含むファイルをアップロードするには、次のパラメータを指定したUploadFromStream()メソッドを使用します。
ファイル名
開いたファイルをパラメータとして持つ
io.ReaderUploadFromStream()の動作を変更するための任意のoptsパラメーター
次のコード例では、 file.txtというファイルから読み取り、その内容を GridFS バケットにアップロードします。 ファイルのメタデータを設定するには、 optsパラメータを使用します。
file, err := os.Open("path/to/file.txt") uploadOpts := options.GridFSUpload().SetMetadata(bson.D{{"metadata tag", "first"}}) objectID, err := bucket.UploadFromStream("file.txt", io.Reader(file), uploadOpts) if err != nil { panic(err) } fmt.Printf("New file uploaded with ID %s", objectID)
注意
ドライバーは各オブジェクト ID 番号を一意に生成します。 出力される ID 番号はサンプル出力に似ていますが、ファイルやユーザーによって異なります。
出力ストリームによるアップロード
出力ストリームを使用してファイルをアップロードするには、次のパラメータを指定したOpenUploadStream()メソッドを使用します。
ファイル名
OpenUploadStream()の動作を変更するための任意のoptsパラメーター
次のコード例では、GridFS バケットでアップロードストリームを開き、 optsパラメーターを使用して各チャンクのバイト数を設定します。 次に、 file.txtのコンテンツに対してWrite()メソッドを呼び出して、そのコンテンツをストリームに書込みます。
file, err := os.Open("path/to/file.txt") if err != nil { panic(err) } uploadOpts := options.GridFSUpload().SetChunkSizeBytes(200000) uploadStream, err := bucket.OpenUploadStream("file.txt", uploadOpts) if err != nil { panic(err) } fileContent, err := io.ReadAll(file) if err != nil { panic(err) } var bytes int if bytes, err = uploadStream.Write(fileContent); err != nil { panic(err) } fmt.Printf("New file uploaded with %d bytes written", bytes)
ファイル情報の検索
GridFS バケットのfilesコレクションに保存されているファイル メタデータを検索できます。 filesコレクション内の各ドキュメントには、次の情報が含まれています。
ファイル ID
ファイルの長さ
最大チャンク サイズ
アップロード日時
ファイル名
その他の情報をストアできる
metadataドキュメント
ファイルデータを検索するには、 GridFSBucketインスタンスでFind()メソッドを呼び出します。 特定のファイル ドキュメントのみを一致させるには、クエリフィルターを引数としてFind()に渡すことができます。
注意
Find()メソッドには、パラメータとしてクエリフィルターが必要です。 filesコレクション内のすべてのドキュメントを一致させるには、空のクエリフィルターをFind()に渡します。
次の例では、 filesコレクション内のlengthの値が1500より大きいドキュメントのファイル名と長さを検索します。
filter := bson.D{{"length", bson.D{{"$gt", 1500}}}} cursor, err := bucket.Find(filter) if err != nil { panic(err) } type gridfsFile struct { Name string `bson:"filename"` Length int64 `bson:"length"` } var foundFiles []gridfsFile if err = cursor.All(context.TODO(), &foundFiles); err != nil { panic(err) } for _, file := range foundFiles { fmt.Printf("filename: %s, length: %d\n", file.Name, file.Length) }
ファイルのダウンロード
GridFS ファイルは、次のいずれかの方法でダウンロードできます。
ファイルを出力ストリームにダウンロードするには、
DowloadToStream()メソッドを使用します。入力ストリームを開くには、
OpenDownloadStream()メソッドを使用します。
出力ストリームへのファイルのダウンロード
DownloadToStream()メソッドを使用して、GridFS バケット内のファイルを出力ストリームに直接ダウンロードできます。 DownloadToStream()は、ファイル ID とio.Writerをパラメータとして受け取ります。 このメソッドは、指定されたファイル ID を持つファイルをダウンロードし、 io.Writerに書込みます。
次の例では、 ファイルをダウンロードし、ファイル バッファに書込みます。
id, err := primitive.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") fileBuffer := bytes.NewBuffer(nil) if _, err := bucket.DownloadToStream(id, fileBuffer); err != nil { panic(err) }
入力ストリームへのファイルのダウンロード
OpenDownloadStream()メソッドを使用して、入力ストリームを持つ GridFS バケット内のファイルをメモリにダウンロードできます。 OpenDownloadStream()は、ファイル ID をパラメータとして受け取り、ファイルを読み取ることができる入力ストリームを返します。
次の例では、ファイルをメモリにダウンロードし、その内容を読み取ります。
id, err := primitive.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") downloadStream, err := bucket.OpenDownloadStream(id) if err != nil { panic(err) } fileBytes := make([]byte, 1024) if _, err := downloadStream.Read(fileBytes); err != nil { panic(err) }
ファイル名の変更
バケット内の GridFS ファイルの名前を更新するには、 Rename()メソッドを使用します。 ファイル ID 値と新しいfilename値を引数としてRename()に渡します。
次の例では、ファイルの名前を "mongodbTutorial.zip":
id, err := primitive.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") if err := bucket.Rename(id, "mongodbTutorial.zip"); err != nil { panic(err) }
ファイルの削除
GridFS バケットからファイルを削除するには、 Delete()メソッドを使用します。 ファイル ID の値を引数としてDelete()に渡します。
次の例では、 ファイルを削除しています。
id, err := primitive.ObjectIDFromHex("62f7bd54a6e4452da13b3e88") if err := bucket.Delete(id); err != nil { panic(err) }
GridFS バケットの削除
GridFS バケットは、 Drop()メソッドを使用して削除できます。
次のコード例では、GridFS バケットを削除します。
if err := bucket.Drop(); err != nil { panic(err) }
追加リソース
GridFS とその操作の詳細については、 GridFS のマニュアル ページ をご覧ください。
API ドキュメント
このガイドで説明したメソッドやタイプの詳細については、次の API ドキュメントを参照してください。