GridFS
項目一覧
Overview
このガイドでは、 GridFSを使用して MongoDB に大容量ファイルを保存、検索する方法を学びます。 GridFS とは、ファイルを保存するときにチャンクに分割し、検索時にファイルを再アセンブルする方法を記述するドライバーによって実装された仕様です。 GridFS のドライバー実装は、ファイル ストレージの操作と組織を管理する抽象化です。
ファイルのサイズが BSON ドキュメント サイズ制限の16 MB を超える場合は、GridFS を使用する必要があります。 GridFS がユースケースに適しているかどうかの詳細については、 GridFS サーバーのマニュアル ページ を参照してください。
GridFS 操作とその実行方法については、次のセクションを参照してください。
GridFS の仕組み
GridFS により、ファイルはバケット(ファイルのチャンクとそれを説明する情報を含む MongoDB コレクションのグループ)に整理されます。 バケットには、GridFS の仕様に定義されている規則を使用して名前付けされた、以下のコレクションが含まれています。
chunksコレクションには、バイナリ ファイルのチャンクがストアされます。filesコレクションには、ファイルのメタデータがストアされます。
新しい GridFS バケットを作成すると、別の名前を指定しない限り、ドライバーによって前述のコレクションが作成され、デフォルトのバケット名fsがプレフィックスとして表示されます。 また、ファイルや関連メタデータを効率的に取得できるように、各コレクションにインデックスも作成します。 ドライバーは、GridFS バケットがまだ存在しない場合、最初の書込み操作でのみ GridFS バケットを作成します。 ドライバーは、インデックスが存在しない場合と、バケットが空の場合にのみインデックスを作成します。 GridFS インデックスの詳細については、サーバーのマニュアル ページ「 GridFS インデックス 」を参照してください。
GridFS を使用してファイルを保存する場合、ドライバーはファイルを小さなチャンクに分割し、各ファイルはchunksコレクションに個別のドキュメントとして表されます。 また、ファイル ID、ファイル名、およびその他のファイル メタデータを含むドキュメントをfilesコレクションに作成します。 ファイルをメモリからアップロードすることも、ストリームからアップロードすることもできます。 バケットにアップロードされるときに GridFS がファイルを分割する方法を確認するには、次の図を参照してください。

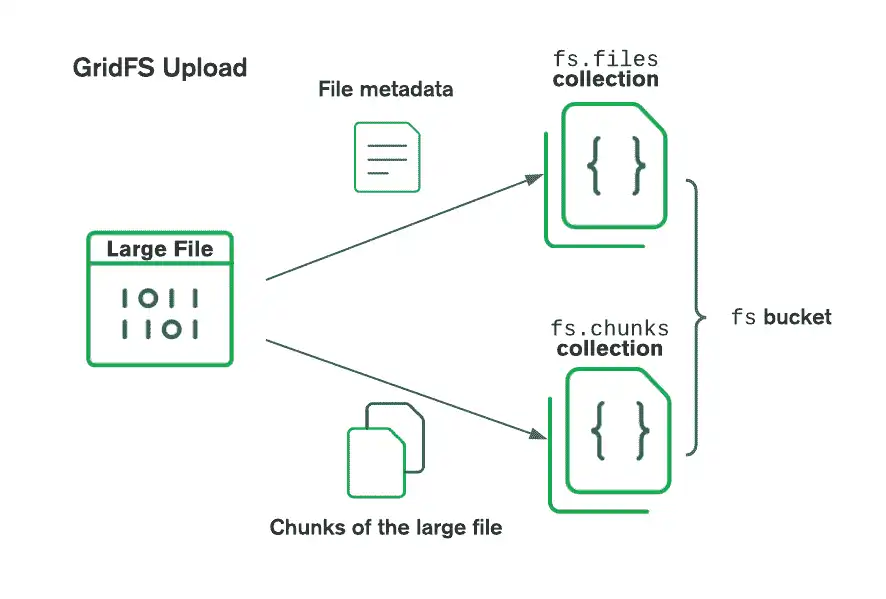
ファイルを検索する際、GridFS は指定されたバケット内の files コレクションからメタデータを取得し、その情報を使用して chunks コレクション内のドキュメントからファイルを再構築します。ファイルをメモリに読み込んだり、ストリームに出力したりすることもできます。
GridFS バケットの作成
GridFS からファイルを保存または検索するには、バケットを作成するか、MongoDB database に既存のバケットへの参照を取得します。 MongoDatabaseインスタンスをパラメータとして指定してGridFSBuckets.create()ヘルパー メソッドを呼び出し、 GridFSBucketをインスタンス化します。 GridFSBucketインスタンスを使用して、バケット内のファイルの読み取り操作および書込み操作を呼び出すことができます。
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database);
デフォルト名fs以外のカスタム名のバケットを作成または参照するには、次のようにバケット名を 2 番目のパラメータとしてcreate()メソッドに渡します。
GridFSBucket gridFSBucket = GridFSBuckets.create(database, "myCustomBucket");
注意
create()を呼び出すと、バケットが存在しない場合は MongoDB はバケットを作成しません。 代わりに、MongoDB は最初のファイルをアップロードするときなど、必要に応じてバケットを作成します。
このセクションで説明されるクラスとメソッドの詳細については、次の API ドキュメントを参照してください。
ファイルの保存
GridFS バケットにファイルを保存するには、 InputStreamのインスタンスからファイルをアップロードするか、そのデータをGridFSUploadStreamに書込みます。
どちらのアップロード プロセスでも、ファイル チャンク サイズやその他のフィールドと値のペアなどの構成情報を指定して、メタデータとして保存できます。 次のコード スニペットに示すように、 GridFSUploadOptionsのインスタンスにこの情報を設定します。
GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) // 1MB chunk size .metadata(new Document("myField", "myValue"));
GridFSUploadOptions を参照 詳しくは、 API ドキュメント を参照してください。
重要
マジョリティ書込み保証 (write concern) の使用
GridFS バケットにファイルを保存するときは、必ずWriteConcern.MAJORITY書込み保証を使用してください。 別の書込み保証を指定すると、GridFS ファイルのアップロード中に発生するレプリカセットの選挙によってアップロード プロセスが中断され、一部のファイル チャンクが失われる可能性があります。
書込み保証 (write concern) の詳細については、サーバー マニュアルの「書込み保証(write concern) 」のページを参照してください。
入力ストリームを使用してファイルをアップロードする
このセクションでは、入力ストリームを使用して GridFS バケットにファイルをアップロードする方法を説明します。 次のコード例は、 FileInputStreamを使用してファイルシステム内のファイルからデータを読み取り、GridFS にアップロードする方法を示しており、次の操作を実行します。
FileInputStreamを使用してファイルシステムから読み取ります。GridFSUploadOptionsを使用してチャンク サイズを設定します。typeというカスタム メタデータ フィールドに「zip Archive」という値を設定します。GridFS ファイル名を「myProject.zip」として指定して、
project.zipというファイルをアップロードします。
String filePath = "/path/to/project.zip"; try (InputStream streamToUploadFrom = new FileInputStream(filePath) ) { // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); // Uploads a file from an input stream to the GridFS bucket ObjectId fileId = gridFSBucket.uploadFromStream("myProject.zip", streamToUploadFrom, options); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + fileId.toHexString()); }
このコード例では、アップロードされたファイルが GridFS に正常に保存された後に、そのファイルのファイル ID を出力します。
詳しくは、 updateFromStream() の API ドキュメント を参照してください。
出力ストリームを使用したファイルのアップロード
このセクションでは、出力ストリームに書き込んでファイルを GridFS バケットにアップロードする方法を説明します。 次のコード例は、 GridFSUploadStreamに書き込みを行い、次の操作を実行して GridFS にデータを送信する方法を示しています。
「project.zip」という名前のファイルを読み込む ファイルシステムからバイト配列に変換する。
GridFSUploadOptionsを使用してチャンク サイズを設定します。typeというカスタム メタデータ フィールドに「zip Archive」という値を設定します。バイトを
GridFSUploadStreamに書き込み、ファイル名「myProject.zip」を割り当てます。 ストリームは、chunkSize設定で指定された制限に達するまでデータをバッファに読み取り、新しいチャンクとしてchunksコレクションに挿入します。
Path filePath = Paths.get("/path/to/project.zip"); byte[] data = Files.readAllBytes(filePath); // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); try (GridFSUploadStream uploadStream = gridFSBucket.openUploadStream("myProject.zip", options)) { // Writes file data to the GridFS upload stream uploadStream.write(data); uploadStream.flush(); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + uploadStream.getObjectId().toHexString()); // Prints a message if any exceptions occur during the upload process } catch (Exception e) { System.err.println("The file upload failed: " + e); }
このコード例では、アップロードされたファイルが GridFS に正常に保存された後に、そのファイルのファイル ID を出力します。
注意
ファイルのアップロードが成功しない場合、操作は例外をスローし、アップロードされたチャンクは 孤立したチャンク になります。 孤立したチャンクとは、GridFS filesコレクション内のファイル ID を参照していない GridFS chunksコレクション内のドキュメントです。 アップロードまたは削除操作が中断された場合、ファイル チャンクは 孤立したチャンク になる可能性があります。 孤立したチャンクを削除するには、読み取り操作を使用してチャンクを識別し、書込み操作を使用して削除する必要があります。
ファイル情報の検索
このセクションでは、GridFS バケットの files コレクションにストアされているファイル メタデータを検索する方法を学びます。メタデータには、参照先のファイルに関する次のような情報が含まれます。
ファイルの ID
ファイルの名前
ファイルの長さ/サイズ
アップロード日時
その他の情報をストアできる
metadataドキュメント
GridFS バケットからファイルを検索するには、 GridFSBucketインスタンスでfind()メソッドを呼び出します。 このメソッドは結果にアクセスできるGridFSFindIterableを返します。
次のコード例は、GridFS バケット内のすべてのファイルからファイル メタデータを検索して印刷する方法を示しています。 GridFSFindIterableから検索した結果をトラバースする方法はさまざまありますが、この例ではConsumer関数インターフェースを使用して次の結果を出力します。
gridFSBucket.find().forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
次のコード例は、クエリフィルターで指定されたフィールドと一致するすべてのファイルのファイル名を検索して出力する方法を示しています。 この例では、返されたGridFSFindIterableに対してsort()とlimit()を呼び出して、結果の順序と最大数を指定します。
Bson query = Filters.eq("metadata.type", "zip archive"); Bson sort = Sorts.ascending("filename"); // Retrieves 5 documents in the bucket that match the filter and prints metadata gridFSBucket.find(query) .sort(sort) .limit(5) .forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
metadataは埋め込みドキュメントであるため、クエリフィルターはドット表記を使用してドキュメント内のtypeフィールドを指定します。 詳細については、埋め込み/ネストされたドキュメントをクエリする方法に関するサーバーのマニュアル ガイドを参照してください。
このセクションで述べられたクラスとメソッドについて詳しくは、次のリソースを参照してください。
GridFSFindIterable API ドキュメント
GridFSbucket.find()API ドキュメント
ファイルのダウンロード
GridFS からファイルをストリームに直接ダウンロードすることも、ストリームからメモリに保存することもできます。 ファイル ID またはファイル名を使用して、取得するファイルを指定できます。
ファイルの変更
バケットに同じファイル名を共有する複数のファイルが含まれている場合、GridFS はデフォルトでファイルの最新アップロード バージョンを選択します。 同じ名前を共有する各ファイルを区別するために、GridFS は同じファイル名を共有するファイルにアップロード時間順のリダイレクト番号を割り当てます。
元のファイルの変更番号は「0」で、次の最新のファイルの変更番号は「1」です。 コレクションの変更点に対応する負の値を指定することもできます。 変更値の「-1」は最新のリビルドを参照し、「-2」は次の最新のリビジョニングを参照します。
次のコード スニペットは、 GridFSDownloadOptionsのインスタンス内のファイルの 2 番目のバージョンを指定する方法を示しています。
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(1);
変更の列挙の詳細については、 GridFSDownloadOptions の API ドキュメントを参照してください。
出力ストリームへのファイルのダウンロード
GridFS バケット内のファイルを出力ストリームにダウンロードできます。 次のコード例は、 downloadToStream()メソッドを呼び出して「myProject.zip」という名前のファイルの最初の改訂版をダウンロードする方法を示しています。 OutputStreamに渡す追加オプション。
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(0); // Downloads a file to an output stream try (FileOutputStream streamToDownloadTo = new FileOutputStream("/tmp/myProject.zip")) { gridFSBucket.downloadToStream("myProject.zip", streamToDownloadTo, downloadOptions); streamToDownloadTo.flush(); }
このメソッドの詳細については、 ダウンロードToStream() API ドキュメント。
入力ストリームへのファイルのダウンロード
入力ストリームを使用して、GridFS バケット内のファイルをメモリにダウンロードできます。 GridFS バケットでopenDownloadStream()メソッドを呼び出して、ファイルを読み取れる入力ストリームであるGridFSDownloadStreamを開くことができます。
次のコード例は、 fileId変数が参照するファイルをメモリにダウンロードし、その内容を string として出力する方法を示しています。
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Opens an input stream to read a file containing a specified "_id" value and downloads the file try (GridFSDownloadStream downloadStream = gridFSBucket.openDownloadStream(fileId)) { int fileLength = (int) downloadStream.getGridFSFile().getLength(); byte[] bytesToWriteTo = new byte[fileLength]; downloadStream.read(bytesToWriteTo); // Prints the downloaded file's contents as a string System.out.println(new String(bytesToWriteTo, StandardCharsets.UTF_8)); }
このメソッドの詳細については、 OpenDownloadStream() 。 API ドキュメント。
ファイル名の変更
バケット内の GridFS ファイルの名前を更新するには、 rename()メソッドを呼び出します。 名前を変更するファイルは、ファイル名ではなく、ファイル ID で指定する必要があります。
注意
rename()メソッドでサポートされているファイル名の更新は、一度に 1 件のみです。 複数のファイルの名前を変更するには、バケットからファイル名と一致するファイルのリストを検索し、名前を変更するファイルからファイル ID 値を抽出し、各ファイル ID をrename()メソッドに個別に呼び出して渡します。
次のコード例は、 fileId変数が参照するファイルの名前を「mongodbチュートリアル.zip」に更新する方法を示しています。
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Renames the file that has a specified "_id" value to "mongodbTutorial.zip" gridFSBucket.rename(fileId, "mongodbTutorial.zip");
このメソッドの詳細については、「 rename() 」 API ドキュメント。
ファイルの削除
GridFS バケットからファイルを削除するには、 delete()メソッドを呼び出します。 削除するファイルは、ファイル名ではなく、ファイル ID で指定する必要があります。
注意
delete()メソッドでサポートされているファイルの削除は、一度に 1 件のみです。 複数のファイルを削除するには、バケットからファイルを検索し、削除するファイルからファイル ID 値を抽出し、 delete()メソッドを個別に呼び出して各ファイル ID を渡します。
次のコード例は、 fileId変数が参照するファイルを削除する方法を示しています。
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Deletes the file that has a specified "_id" value from the GridFS bucket gridFSBucket.delete(fileId);
このメソッドの詳細については、「 delete() API ドキュメント。
GridFS バケットの削除
次のコード例は、「mydb」という名前のデータベース上のデフォルトの GridFS バケットを削除する方法を示しています。 カスタム名前のバケットを参照するには、このガイドの「 カスタム バケットの作成方法 」のセクションを参照してください。
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database); gridFSBucket.drop();
このメソッドの詳細については、 drop() API ドキュメント。
追加リソース
実行可能な例 GridFSTour.java MongoDB Java ドライバー リポジトリからの。