Overview
このガイドでは、 GridFSを使用して MongoDB に大容量ファイルを保存、検索する方法を学びます。 GridFS とは、ストレージ時にファイルをチャンクに分割し、検索時にファイルを再アセンブルする方法を記述した仕様です。 GridFS の Rust ドライバーの実装は、ファイル ストレージの操作と組織を管理します。
ファイルのサイズが BSON ドキュメント サイズ制限の16 MB を超える場合は、GridFS を使用します。 GridFS は、ファイル全体をメモリにロードせずにファイルにアクセスするのにも役立ちます。 GridFS がユースケースに適しているかどうかの詳細については、サーバー マニュアルの GridFSページを参照してください。
GridFS の詳細については、このガイドの次のセクションに移動してください。
GridFS の仕組み
GridFS により、ファイルはバケット(ファイル チャンクと記述情報を含む MongoDB コレクションのグループ)に整理されます。 バケットには、GridFS の仕様に定義されている規則に従って名前付けされた、以下のコレクションが含まれています。
chunksは、バイナリ ファイルのチャンクを保存します。filesは、ファイルのメタデータを保存します
新しい GridFS バケットを作成すると、Rust ドライバーは次のアクションを実行します。
別の名前を指定しない限り、デフォルトのバケット名
fsをプレフィックスとして、chunksとfilesコレクションを作成します各コレクションにインデックスを作成し、ファイルと関連メタデータを効率的に取得します
このページの「 GridFS バケットの参照 」セクションの手順に従って、GridFS バケットへの参照を作成できます。 ただし、ドライバーは最初の書込み操作まで新しい GridFS バケットとそのインデックスを作成しません。 GridFS インデックスの詳細については、サーバー マニュアルの「 GridFS インデックス」のページを参照してください。
GridFS バケットにファイルを保存する場合、Rust ドライバーは次のドキュメントを作成します。
一意のファイル ID、ファイル名、およびその他のファイル メタデータを保存する
filesコレクション内の 1 つのドキュメントドライバーによって小さな部分に分割されるファイルの内容を保存する
chunksコレクション内の 1 つ以上のドキュメント
次の図は、GridFS がファイルをバケットにアップロードするときにファイルを分割する方法を示しています。

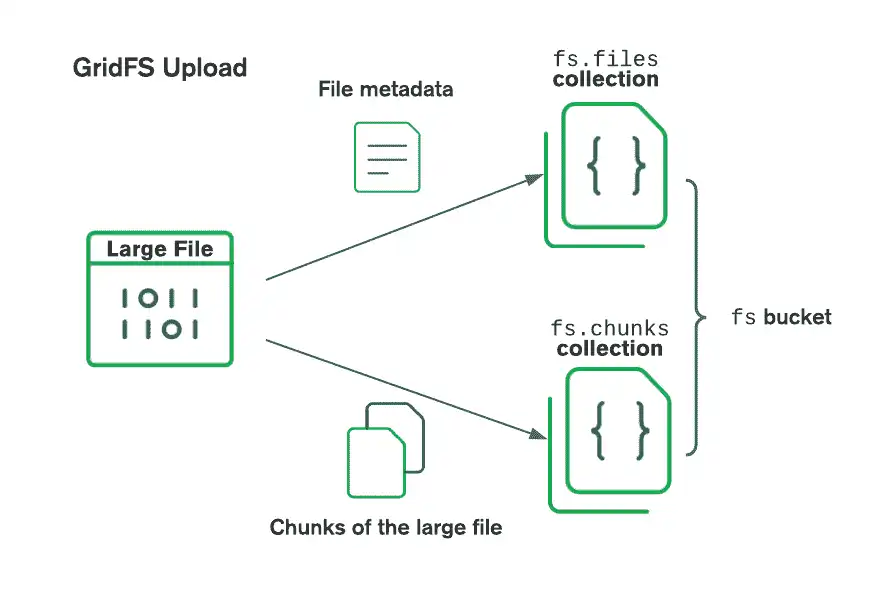
ファイルを検索する際、GridFS は指定されたバケット内の files コレクションからメタデータを取得し、その情報を使用して chunks コレクション内のドキュメントからファイルを再構築します。ファイルをメモリに読み込んだり、ストリームに出力したりすることもできます。
GridFS バケットの参照
GridFS バケットにファイルを保存する前に、バケット参照を作成するか、既存のバケットへの参照を取得します。
次の例では、データベース インスタンスでgridfs_bucket()メソッドを呼び出します。これにより、新規または既存の GridFS バケットへの参照が作成されます。
let bucket = my_db.gridfs_bucket(None);
カスタム バケット名を指定するには、 GridFsBucketOptions構造体のbucket_nameフィールドを設定します。
注意
構造体をインスタンス化する
Rust ドライバーは、 GridFsBucketOptionsを含む一部の構造体型を作成するためのビルダ設計パターンを実装します。 builder()メソッドを使用して、オプション ビルダー メソッドを連鎖させることで、各タイプのインスタンスを構築できます。
次の表では、 GridFsBucketOptionsフィールドを設定するために使用できる方法について説明しています。
方式 | Possible Values | 説明 |
|---|---|---|
bucket_name() | Any String value | Specifies a bucket name, which is set to fs by default |
| 任意の | ファイルをチャンクに分割するために使用するチャンク サイズを指定します。デフォルトでは 255 KB |
write_concern() | WriteConcern::w(),WriteConcern::w_timeout(),WriteConcern::journal(),WriteConcern::majority() | Specifies the bucket's write concern, which is set to the database's write concern by default |
|
| バケットの読み取り保証 (read concern) を指定します。デフォルトではデータベースの読み取り保証 (read concern) に設定されています。 |
selection_criteria() | SelectionCriteria::ReadPreference,SelectionCriteria::Predicate | Specifies which servers are suitable for a bucket operation, which is set to the database's selection criteria by default |
次の例では、 GridFsBucketOptionsインスタンスでオプションを指定して、書込み操作のカスタム バケット名と 5 秒の時間制限を構成します。
let wc = WriteConcern::builder().w_timeout(Duration::new(5, 0)).build(); let opts = GridFsBucketOptions::builder() .bucket_name("my_bucket".to_string()) .write_concern(wc) .build(); let bucket_with_opts = my_db.gridfs_bucket(opts);
ファイルのアップロード
アップロード ストリームを開き、ファイルをストリームに書き込むことで、GridFS バケットにファイルをアップロードできます。 ストリームを開くには、バケット インスタンスでopen_upload_stream()メソッドを呼び出します。 このメソッドは、ファイルの内容を書き込むことができるGridFsUploadStreamのインスタンスを返します。 ファイルの内容をGridFsUploadStreamにアップロードするには、 write_all()メソッドを呼び出し、ファイル バイトをパラメーターとして渡します。
Tip
必要なモジュールをインポートする
GridFsUploadStream構造体はfutures_io::AsyncWrite属性を実装します。 write_all()などのAsyncWrite書込みメソッドを使用するには、次の使用宣言を使用してAsyncWriteExtモジュールをアプリケーション ファイルにインポートします。
use futures_util::io::AsyncWriteExt;
次の例では、アップロードストリームを使用して、 "example.txt"というファイルを GridFS バケットにアップロードします。
let bucket = my_db.gridfs_bucket(None); let file_bytes = fs::read("example.txt").await?; let mut upload_stream = bucket.open_upload_stream("example").await?; upload_stream.write_all(&file_bytes[..]).await?; println!("Document uploaded with ID: {}", upload_stream.id()); upload_stream.close().await?;
ファイルのダウンロード
ダウンロード ストリームを開いてストリームから読み取ることで、GridFS バケットからファイルをダウンロードできます。 バケット インスタンスでopen_download_stream()メソッドを呼び出して、目的のファイルの_id値をパラメータとして指定します。 このメソッドは、ファイルにアクセスできるインスタンスGridFsDownloadStreamを返します。 GridFsDownloadStreamからファイルを読み取るには、 read_to_end()メソッドを呼び出し、ベクトルをパラメーターとして渡します。
Tip
必要なモジュールをインポートする
GridFsDownloadStream構造体はfutures_io::AsyncRead属性を実装します。 read_to_end()などのAsyncRead読み取りメソッドを使用するには、次の使用宣言を使用してAsyncReadExtモジュールをアプリケーション ファイルにインポートします。
use futures_util::io::AsyncReadExt;
次の例では、ダウンロード ストリームを使用して、GridFS バケットから3289の_id値を持つファイルをダウンロードします。
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let mut buf = Vec::new(); let mut download_stream = bucket.open_download_stream(Bson::ObjectId(id)).await?; let result = download_stream.read_to_end(&mut buf).await?; println!("{:?}", result);
注意
GridFS ストリーミング API は部分的なチャンクを読み込むことはできません。 ダウンロード ストリームが MongoDB からチャンクをプルする必要がある場合、チャンク全体をメモリにプルします。 通常、255 KB のデフォルトのチャンク サイズで十分ですが、チャンク サイズを小さくしてメモリのオーバーヘッドを減らすことができます。
ファイル情報の検索
GridFS バケットのfilesコレクションに保存されているファイルに関する情報を取得できます。 各ファイルは、ファイル情報を表す次のフィールドを含むFilesCollectionDocument型のインスタンスとして保存されます。
_id: ファイル IDlength: ファイルサイズchunk_size_bytes: ファイルのチャンクのサイズupload_date: ファイルのアップロード日時filename: ファイルの名前metadata: ユーザー指定のメタデータを保存するドキュメント
バケットからファイルを検索するには、GridFS バケット インスタンスでfind()メソッドを呼び出します。 このメソッドは、結果にアクセスできるカーソル インスタンスを返します。
次の例では、GridFS バケット内の各ファイルの長さを検索して出力します。
let bucket = my_db.gridfs_bucket(None); let filter = doc! {}; let mut cursor = bucket.find(filter).await?; while let Some(result) = cursor.try_next().await? { println!("File length: {}\n", result.length); };
Tip
find()メソッドの詳細については、 データの取得ガイドを参照してください。 カーソルからデータを検索する方法の詳細については、「 カーソルを使用したデータへのアクセス」ガイドを参照してください。
ファイル名の変更
バケット内の GridFS ファイルの名前を更新するには、バケット インスタンスでrename()メソッドを呼び出します。 ターゲット ファイルの_id値と新しいファイル名をパラメーターとしてrename()メソッドに渡します。
注意
rename() メソッドでサポートできるファイル名の更新は、一度に 1 件のみです。複数のファイルの名前を変更するには、バケットからファイル名と一致するファイルのリストを検索し、名前を変更するファイルから _id フィールドを抽出し、rename() メソッドを個別に呼び出して各値を渡します。
次の例では、 3289の_id値を含む ファイルのfilenameフィールドを"new_file_name"にアップデートします。
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let new_name = "new_file_name"; bucket.rename(Bson::ObjectId(id), new_name).await?;
ファイルの削除
バケットからファイルを削除するには、 delete()メソッドを使用します。 ファイルを削除するには、バケット インスタンスでdelete()を呼び出し、ファイルの_id値をパラメータとして渡します。
注意
delete()メソッドでサポートされているファイルの削除は、一度に 1 件のみです。 複数のファイルを削除するには、バケットからファイルを検索し、削除するファイルから_idフィールドを抽出し、 delete()メソッドを個別に呼び出して各_id値を渡します。
次の例では、 _idフィールドの値が3289である ファイルを削除しています。
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); bucket.delete(Bson::ObjectId(id)).await?;
GridFS バケットの削除
drop()バケットを削除するには、files chunksメソッドを使用します。これにより、バケットの コレクションと コレクションが削除されます。バケットを削除するには、バケット インスタンスでdrop()を呼び出します。
次の例では、GridFS バケットを削除します。
let bucket = my_db.gridfs_bucket(None); bucket.drop().await?;
詳細情報
API ドキュメント
このガイドで言及されているメソッドや型の詳細については、以下のAPIドキュメントを参照してください。