大きなファイルの保存
項目一覧
Overview
このガイドでは、 GridFSを使用してMongoDBに大容量ファイルを保存、検索する方法を学びます。GridFSはC++ドライバーによって実装された仕様で、ファイルを保存するときにチャンクに分裂し、検索時にそれらのファイルを再アセンブルする方法を記述します。 ドライバーのGridFSの実装は、ファイルストレージの操作と組織を管理する抽象化です。
ファイルのサイズがBSONドキュメントサイズ制限の 16 MB を超える場合は、 GridFSを使用します。GridFSがユースケースに適しているかどうかの詳細については、 MongoDB Serverマニュアルの GridFSを参照してください。
GridFS の仕組み
GridFS により、ファイルはバケット(ファイルのチャンクとそれを説明する情報を含む MongoDB コレクションのグループ)に整理されます。 バケットには、GridFS の仕様に定義されている規則を使用して名前付けされた、以下のコレクションが含まれています。
chunksコレクションは、バイナリファイルのチャンクを保存します。filesコレクションは、ファイルのメタデータを保存します
ドライバーは、最初にデータを書き込むと、 GridFSバケットが存在しない場合はそれを作成します。 バケットには、別の名前を指定しない限り、デフォルトのバケット名 fs がプレフィックスが付いた前述のコレクションが含まれます。ファイルと関連メタデータを効率的に取得するために、ドライバーは各コレクションにインデックスを作成します。 ドライバーは、 GridFSバケットで読み取りおよび書込み操作を実行する前に、これらのインデックスが存在することを確認します。
GridFSインデックスの詳細については、 MongoDB Serverマニュアルの「 GridFSインデックス 」を参照してください。
GridFSを使用してファイルを保存する場合、ドライバーはファイルを小さなチャンクに分割し、各ファイルは chunksコレクションに個別のドキュメントとして表されます。また、ファイルID、ファイル名、およびその他のファイルメタデータを含むドキュメントを filesコレクションに作成します。C++ドライバーにストリームを渡して消費するか、新しいストリームを作成してそのストリームに直接書き込むことで、ファイルをアップロードできます。
次の図は、 GridFSがバケットにアップロードされるときにファイルを分割する方法を示しています。

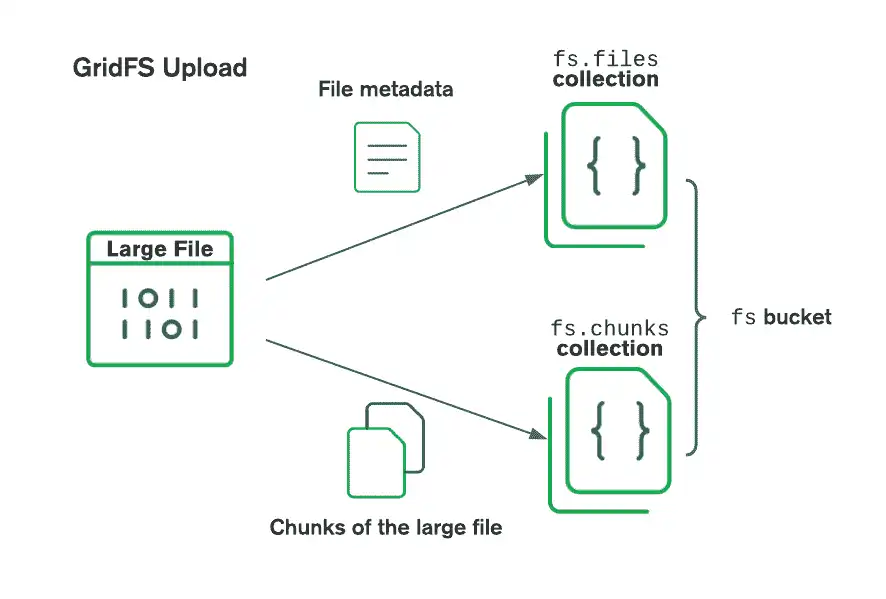
ファイルを検索する際、 GridFSは指定されたバケット内の filesコレクションからメタデータを取得し、その情報を使用して chunksコレクション内のドキュメントからファイルを再構築します。ファイルの内容を既存のストリームに書込むか、ファイルをポイントする新しいストリームを作成することで、ファイルを読み取ることができます。
GridFS バケットの作成
GridFSからのファイルの保存または検索を開始するには、データベースで gridfs_bucket() メソッドを呼び出します。このメソッドは、既存のバケットにアクセスし、バケットが存在しない場合は新しいバケットを作成します。
次の例では、 dbデータベースでgridfs_bucket()メソッドを呼び出します。
auto bucket = db.gridfs_bucket();
バケットをカスタマイズする
GridFSバケット構成をカスタマイズするには、mongocxx::options::gridfs::bucketクラスのインスタンスを gridfs_bucket() メソッドの任意の引数として渡します。次の表では、mongocxx::options::gridfs::bucketインスタンスで設定できるフィールドを説明しています。
フィールド | 説明 |
|---|---|
| Specifies the bucket name to use as a prefix for the files and chunks collections.
The default value is "fs".Type: std::string |
| Specifies the chunk size that GridFS splits files into. The default value is 261120.Type: std::int32_t |
| Specifies the read concern to use for bucket operations. The default value is the
database's read concern. Type: mongocxx::read_concern |
| Specifies the read preference to use for bucket operations. The default value is the
database's read preference. Type: mongocxx::read_preference |
| Specifies the write concern to use for bucket operations. The default value is the
database's write concern. Type: mongocxx::write_concern |
次の例では、mongocxx::options::gridfs::bucketインスタンスの bucket_nameフィールドを設定して、"myCustomBucket" という名前のバケットを作成します。
mongocxx::options::gridfs::bucket opts; opts.bucket_name("myCustomBucket"); auto bucket = db.gridfs_bucket(opts);
ファイルのアップロード
次の方法を使用して、 GridFSバケットにファイルをアップロードできます。
open_upload_stream() :ファイルの内容を書き込むことができる新しいアップロードストリームを開きます
アップロード_from_stream() : 既存のストリームの内容をGridFSファイルにアップロードします
アップロード ストリームへの書き込み
特定のファイル名のアップロードストリームを作成するには、open_upload_stream() メソッドを使用します。open_upload_stream() メソッドを使用すると、 options::gridfs::uploadインスタンスの構成情報を指定できます。これはパラメータとして渡すことができます。
この例では、アップロードストリームを使用して次のアクションを実行しています。
オプションインスタンスの
chunk_size_bytesフィールドを設定します"my_file"という名前の新しいGridFSファイルの書き込み可能なストリームを開き、chunk_size_bytesオプションを適用しますwrite()メソッドを呼び出してmy_fileにデータを書込み (write) ます。ここではストリームは を指しますmy_fileを指しているストリームを閉じるには、close()メソッドを呼び出します
mongocxx::options::gridfs::upload opts; opts.chunk_size_bytes(1048576); auto uploader = bucket.open_upload_stream("my_file", opts); // ASCII for "HelloWorld" std::uint8_t bytes[10] = {72, 101, 108, 108, 111, 87, 111, 114, 108, 100}; for (auto i = 0; i < 5; ++i) { uploader.write(bytes, 10); } uploader.close();
既存のストリームをアップロードする
ストリームの内容を新しいGridFSファイルにアップロードするには、upload_from_stream() メソッドを使用します。upload_from_stream() メソッドを使用すると、 options::gridfs::uploadインスタンスの構成情報を指定できます。これはパラメータとして渡すことができます。
この例では、次のアクションを実行します。
/path/to/input_fileにあるファイルをバイナリ読み取りモードのストリームとして開きますupload_from_stream()メソッドを呼び出して、ストリームの内容を"new_file"という名前のGridFSファイルにアップロードします
std::ifstream file("/path/to/input_file", std::ios::binary); bucket.upload_from_stream("new_file", &file);
ファイル情報の検索
このセクションでは、GridFS バケットの files コレクションにストアされているファイル メタデータを検索する方法を学びます。メタデータには、参照先のファイルに関する次のような情報が含まれます。
ファイルの
_idファイルの名前
ファイルの長さ/サイズ
アップロード日時
その他の情報を保存できる
metadataドキュメント
GridFSバケットからファイルを検索するには、バケットで mongocxx::gridfs::bucket::find() メソッドを呼び出します。このメソッドは、結果にアクセスできる mongocxx::cursorインスタンスを返します。カーソルの詳細については、「 カーソルからデータにアクセスする ガイド」を参照してください。
例
次のコード例は、 GridFSバケット内のファイルからファイルメタデータを検索して印刷する方法を示しています。 forループを使用して返されたカーソルを反復処理し、 ファイルのアップロード例 にアップロードされたファイルの内容を表示します。
auto cursor = bucket.find({}); for (auto&& doc : cursor) { std::cout << bsoncxx::to_json(doc) << std::endl; }
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
find() メソッドはさまざまなクエリ仕様を受け入れます。その mongocxx::options::find パラメーターを使用して、並べ替え順序、返されるドキュメントの最大数、返される前にスキップするドキュメント数を指定できます。利用可能なオプションのリストを表示するには、 APIドキュメント を参照してください。
ファイルのダウンロード
次の方法を使用して、 GridFSバケットからファイルをダウンロードできます。
open_Download_stream() : 新しいダウンロード ストリームを開き、ファイルの内容を読み取ることができる
ダウンロード_to_stream() :ファイル全体を既存のダウンロード ストリームに書込みます
ダウンロード ストリームからの読み取り
MongoDBデータベースからファイルをダウンロードするには、 open_download_stream()メソッドを使用してダウンロード ストリームを作成します。
この例では、ダウンロード ストリームを使用して次のアクションを実行しています。
"new_file"という名前のGridFSファイルの_id値を取得します。_id値をopen_download_stream()メソッドに渡して、ファイルを読み取り可能なストリームとして開きますファイルの内容を保存するために
bufferベクトルを作成しますread()メソッドを呼び出して、downloaderストリームからベクトルにファイルの内容を読み取ります
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); auto downloader = bucket.open_download_stream(id); std::vector<uint8_t> buffer(downloader.file_length()); downloader.read(buffer.data(), buffer.size());
既存のストリームへのダウンロード
バケットでdownload_to_stream()メソッドを呼び出すと、 GridFSファイルの内容を既存のストリームにダウンロードできます。
この例では、次のアクションを実行します。
/path/to/output_fileにあるファイルをバイナリ書込みモードのストリームとして開きます"new_file"という名前のGridFSファイルの_id値を取得します。ファイルをストリームにダウンロードするには、
_id値をdownload_to_stream()に渡します
std::ofstream output_file("/path/to/output_file", std::ios::binary); auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); bucket.download_to_stream(id, &output_file);
ファイルの削除
バケットからファイルのコレクション ドキュメントと関連するチャンクを削除するには、 delete_file()メソッドを使用します。 これにより、ファイルが実質的に削除されます。 削除するファイルは、ファイル名ではなく、 _idフィールドで指定する必要があります。
次の例では、_id 値を delete_file() に渡して "my_file" という名前のファイルを削除する方法を示しています。
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "my_file"))); auto id = doc->view()["_id"].get_value(); bucket.delete_file(id);
注意
ファイルの変更
delete_file() メソッドでサポートされているファイルの削除は、一度に 1 件のみです。各ファイルのリビジョニング、または同じファイル名を共有するアップロード時間が異なるファイルを削除する場合は、各リビジョニングの _id 値を収集します。次に、delete_file() メソッドを個別に呼び出して、各 _id 値を渡します。
API ドキュメント
C++ドライバーを使用して大容量のファイルを保存および検索する方法の詳細については、次のAPIドキュメントを参照してください。