Docs Home → アプリケーションの開発 → Python ドライバー → PyMongo
大きなファイルの保存
Overview
このガイドでは、 GridFSを使用して MongoDB に大容量ファイルを保存、検索する方法を学びます。 GridFS とは、ファイルを保存するときにチャンクに分割し、検索時にファイルを再アセンブルする方法を記述する PyMongo によって実装された仕様です。 ドライバーの GridFS の実装は、ファイル ストレージの操作と組織を管理する抽象化です。
ファイルのサイズが BSON ドキュメント サイズ制限の16 MB を超える場合は、GridFS を使用する必要があります。 GridFS がユースケースに適しているかどうかの詳細については、 マニュアルの GridFS MongoDB Serverを参照してください。
次のセクションでは、GridFS 操作とその実行方法について説明します。
GridFS の仕組み
GridFS により、ファイルはバケット(ファイルのチャンクとそれを説明する情報を含む MongoDB コレクションのグループ)に整理されます。 バケットには、GridFS の仕様に定義されている規則を使用して名前付けされた、以下のコレクションが含まれています。
chunksコレクションには、バイナリ ファイルのチャンクがストアされます。filesコレクションには、ファイルのメタデータがストアされます。
新しい GridFS バケットを作成すると、別の名前を指定しない限り、ドライバーによって前述のコレクションが作成され、デフォルトのバケット名fsがプレフィックスとして表示されます。 また、ファイルや関連メタデータを効率的に取得できるように、各コレクションにインデックスも作成します。 ドライバーは、GridFS バケットが存在しない場合、最初の書込み操作が実行されたときにのみ GridFS バケットを作成します。 ドライバーはインデックスが存在しない場合と、バケットが空の場合にのみインデックスを作成します。 GridFS インデックスの詳細については、 マニュアルの「 GridFS インデックス MongoDB Server」を参照してください。
GridFS を使用してファイルを保存する場合、ドライバーはファイルを小さなチャンクに分割し、各ファイルはchunksコレクションに個別のドキュメントとして表されます。 また、ファイル ID、ファイル名、およびその他のファイル メタデータを含むドキュメントをfilesコレクションに作成します。 ファイルをメモリからアップロードすることも、ストリームからアップロードすることもできます。 バケットにアップロードされるときに GridFS がファイルを分割する方法を確認するには、次の図を参照してください。

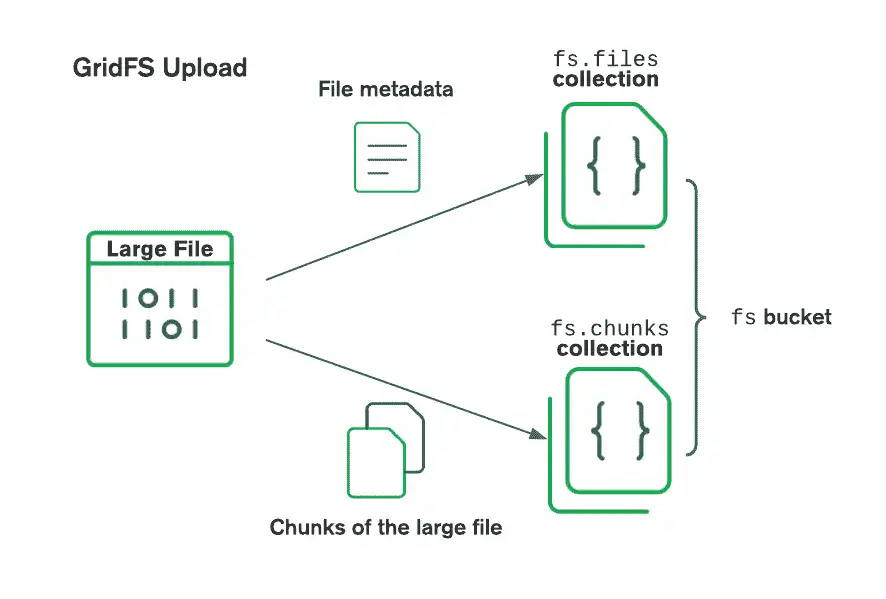
ファイルを検索する際、GridFS は指定されたバケット内の files コレクションからメタデータを取得し、その情報を使用して chunks コレクション内のドキュメントからファイルを再構築します。ファイルをメモリに読み込んだり、ストリームに出力したりすることもできます。
GridFS バケットの作成
GridFS からファイルを保存または検索するには、 GridFSBucket()コンストラクターを呼び出し、 Databaseインスタンスを渡して GridFS バケットを作成します。 GridFSBucketインスタンスを使用して、バケット内のファイルの読み取り操作および書込み操作を呼び出すことができます。
const db = client.db(dbName); const bucket = new mongodb.GridFSBucket(db);
デフォルト名fs以外のカスタム名のバケットを作成または参照するには、次のようにバケット名を 2 番目のパラメータとしてGridFSBucket()コンストラクターに渡します。
const bucket = new mongodb.GridFSBucket(db, { bucketName: 'myCustomBucket' });
ファイルのアップロード
指定されたファイル名のアップロードストリームを作成するには、 GridFSBucketクラスのopen_upload_stream()メソッドを使用します。 open_upload_stream()メソッドでは、ファイル チャンク サイズやその他のフィールドと値のペアなどの構成情報を指定し、メタデータとして保存できます。 次のコード例に示すように、これらのオプションをopen_upload_stream()のパラメーターとして設定します。
fs.createReadStream('./myFile'). pipe(bucket.openUploadStream('myFile', { chunkSizeBytes: 1048576, metadata: { field: 'myField', value: 'myValue' } }));
ファイル情報の検索
このセクションでは、GridFS バケットの files コレクションにストアされているファイル メタデータを検索する方法を学びます。メタデータには、参照先のファイルに関する次のような情報が含まれます。
ファイルの
_idファイルの名前
ファイルの長さ/サイズ
アップロード日時
その他の情報をストアできる
metadataドキュメント
GridFS バケットからファイルを検索するには、 GridFSBucketインスタンスでfind()メソッドを呼び出します。 このメソッドは、結果にアクセスできるCursorインスタンスを返します。 PyMongo のCursorオブジェクトの詳細については、「カーソルからのデータへのアクセス 」を参照してください。
次のコード例は、GridFS バケット内のすべてのファイルからファイル メタデータを検索して印刷する方法を示しています。 for...of構文を使用してCursorイテラブルをトラバースし、結果を表示します。
const cursor = bucket.find({}); for await (const doc of cursor) { console.log(doc); }
find()メソッドはさまざまなクエリ仕様を受け入れます。 そのパラメーターを使用して、ソート順序、返されるドキュメントの最大数、返される前にスキップするドキュメント数を指定できます。 MongoDB のクエリの詳細については、「データの取得 」を参照してください。
ファイルのダウンロード
MongoDB データベースからファイルをダウンロードするには、GridFSBucket の open_download_stream_by_name() メソッドを使用してダウンロード ストリームを作成します。
次の例は、filename フィールドにストアされているファイル名で参照されるファイルを作業ディレクトリにダウンロードする方法を示しています。
bucket.openDownloadStreamByName('myFile'). pipe(fs.createWriteStream('./outputFile'));
注意
同じ filename 値を持つドキュメントが複数ある場合、GridFS は指定された名前(uploadDate フィールドによって決定)を持つ最新のファイルをストリーミングします。
あるいは、ファイルの _id フィールドをパラメータとして受け取る open_download_stream() メソッドを使用することもできます。
bucket.openDownloadStream(ObjectId("60edece5e06275bf0463aaf3")). pipe(fs.createWriteStream('./outputFile'));
注意
GridFS ストリーミング API は部分的なチャンクを読み込むことはできません。 ダウンロード ストリームが MongoDB からチャンクをプルする必要がある場合、チャンク全体をメモリにプルします。 通常、 255キロバイトのデフォルトのチャンク サイズで十分ですが、チャンク サイズを小さくしてメモリのオーバーヘッドを減らすことができます。
ファイル名の変更
バケット内の GridFS ファイルの名前を更新するには、rename() メソッドを使用します。名前を変更するファイルは、ファイル名ではなく、ファイルの _id フィールドで指定する必要があります。
次の例では、ドキュメントの_idフィールドを参照してfilenameフィールドを"newFileName"に更新する方法を示しています。
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");
注意
rename()メソッドでサポートされているファイル名の更新は、一度に 1 件のみです。 複数のファイルの名前を変更するには、バケットからファイル名と一致するファイルのリストを検索し、名前を変更するファイルから_idフィールドを抽出し、各値をrename()メソッドに個別に呼び出して渡します。
ファイルの削除
バケットからファイルのコレクション ドキュメントと関連するチャンクを削除するには、 delete()メソッドを使用します。 これにより、ファイルが実質的に削除されます。 削除するファイルは、ファイル名ではなく、 _idフィールドで指定する必要があります。
次の例は、_id フィールドを参照してファイルを削除する方法を示しています。
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");
注意
delete()メソッドでサポートされているファイルの削除は、一度に 1 件のみです。 複数のファイルを削除するには、バケットからファイルを検索し、削除するファイルから_idフィールドを抽出し、 delete()メソッドを個別に呼び出して各値を渡します。
API ドキュメント
PyMongo を使用して大容量のファイルを保存および検索する方法の詳細については、次の API ドキュメントを参照してください。