スキーマを設計するときは、アプリケーションが関連データをクエリして返す必要があることを考慮してください。 データエンティティ間の関係をどのようにマッピングするかは、アプリケーションのパフォーマンスとスケーラビリティに影響します。
関連データを処理する推奨方法は、サブドキュメントに埋め込むことです。 関連データを埋め込むと、アプリケーションは 1 回の読み取り操作で必要なデータをクエリでき、低速の $lookup操作を回避できます。
一部のユースケースでは、参照を使用して別のコレクション内の関連データを示すことができます。
このタスクについて
関連データを埋め込むか、参照を使用するかを判断するには、アプリケーションの次の目的の相対的な重要性を考慮してください。
- 関連データのクエリを改善する
- アプリケーションが 1 つのエンティティについてのデータを返すために、1 つのエンティティを頻繁にクエリする場合は、頻繁に
$lookup操作を必要としないようにデータを埋め込みます。 - さまざまなエンティティから返されるデータを改善する
- アプリケーションが関連エンティティのデータをまとめて返す場合は、そのデータを単一のコレクションに埋め込みます。
- 更新パフォーマンスの向上
- アプリケーションが関連データを頻繁に更新する場合は、データを コレクションに保存し、 参照 を使用してそのコレクションにアクセスすることを検討してください。 参照を使用すると、データを 1 か所で更新するだけで、アプリケーションの書込みワークロードが軽減されます。
埋め込みデータと参照の利点について学ぶには、関連データのリンクを参照してください。
始める前に
関係のマッピングは、スキーマ設計プロセスの 2 番目のステップです。 関係をマッピングする前に、アプリケーションのワークロードを特定して、必要なデータを判断します。
手順
関連データのスキーマ マップを作成する
スキーマ マップには、関連するデータフィールドとそれらのフィールド間の関係のタイプ(1 対 1、1 対多、多対多)が表示されます。
スキーママップは エンティティ関係モデルに似ている場合があります。
関連データを埋め込むか参照を使用するかを選択する
データを埋め込むか参照を使用するかは、アプリケーションの一般的なクエリによって異なります。 「アプリケーション ワークロードの特定 」ステップで識別したクエリを確認し、このページの前半で説明したガイドラインを使用して、頻繁にクリティカルなクエリをサポートするようにスキーマを設計します。
選択したアプローチに一致するようにデータベース、コレクション、およびアプリケーション ロジックを構成します。
例
ブログ アプリケーションの次のスキーマ マップを考えてみましょう。

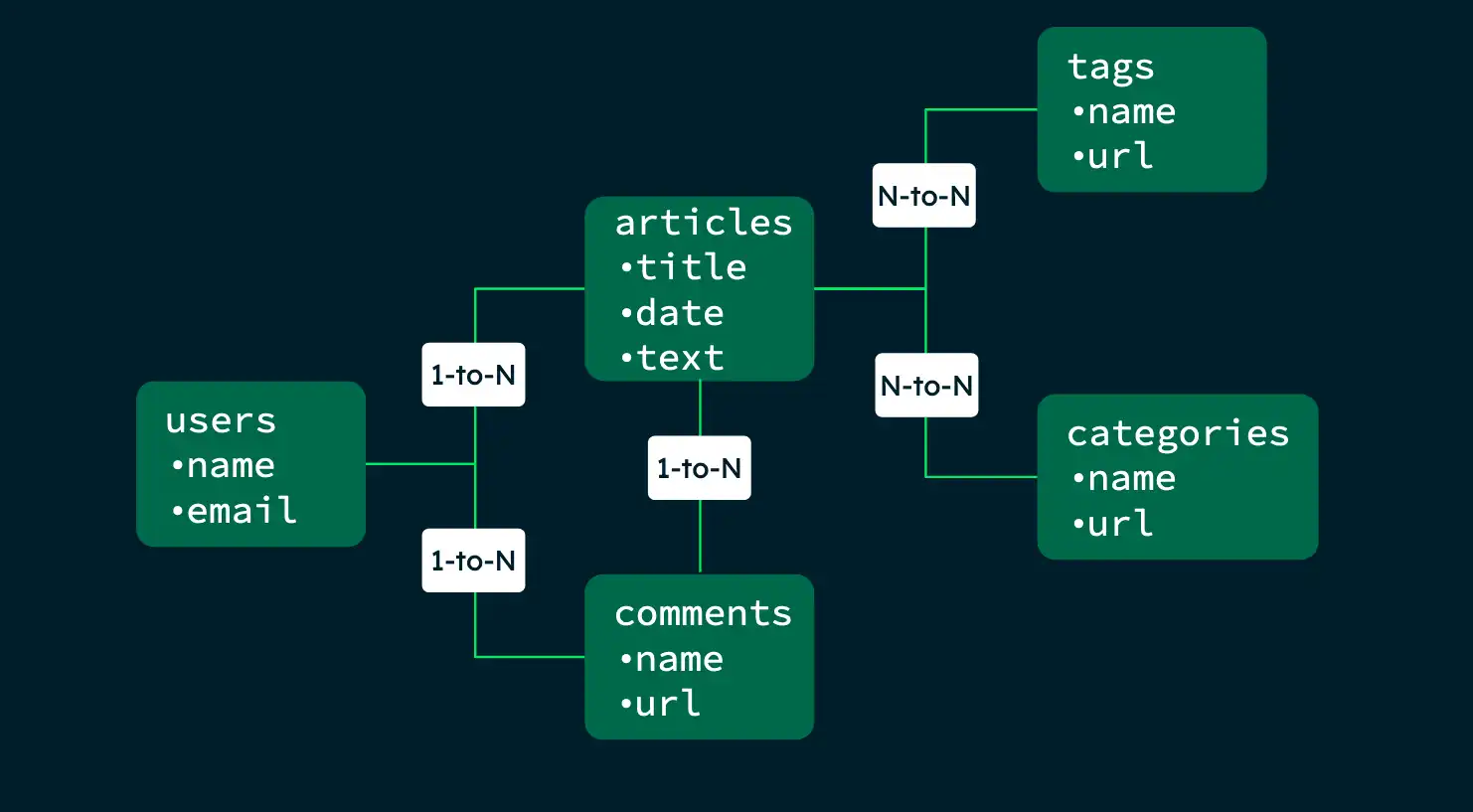
次の例は、アプリケーションのニーズに応じて、さまざまなクエリに対してスキーマを最適化する方法を示しています。
記事のクエリの最適化
アプリケーションが主にタイトルなどの情報を検索する記事をクエリする場合は、アプリケーションに必要なすべてのデータを 1 回の操作で返されるように関連情報をarticlesコレクションに埋め込みます。
次のドキュメントは、記事に対するクエリ用に最適化されています。
db.articles.insertOne( { title: "My Favorite Vacation", date: ISODate("2023-06-02"), text: "We spent seven days in Italy...", tags: [ { name: "travel", url: "<blog-site>/tags/travel" }, { name: "adventure", url: "<blog-site>/tags/adventure" } ], comments: [ { name: "pedro123", text: "Great article!" } ], author: { name: "alice123", email: "alice@mycompany.com", avatar: "photo1.jpg" } } )
記事と著者のクエリの最適化
アプリケーションが記事情報と著者情報を個別に返す場合は、記事と著者を別々のコレクションに保存することを検討してください。 このスキーマ設計により、著者情報を返すために必要な作業が軽減され、不要なフィールドを含めずに著者情報のみを返すことができます。
次のスキーマでは、 articlesコレクションにはauthorsコレクションへの参照であるauthorIdフィールドが含まれています。
記事コレクション
db.articles.insertOne( { title: "My Favorite Vacation", date: ISODate("2023-06-02"), text: "We spent seven days in Italy...", authorId: 987, tags: [ { name: "travel", url: "<blog-site>/tags/travel" }, { name: "adventure", url: "<blog-site>/tags/adventure" } ], comments: [ { name: "pedro345", text: "Great article!" } ] } )
Authors コレクション
db.authors.insertOne( { _id: 987, name: "alice123", email: "alice@mycompany.com", avatar: "photo1.jpg" } )
次のステップ
アプリケーションのデータの関係をマッピングしたら、スキーマ設計プロセスの次のステップは、設計パターンを適用してスキーマを最適化します。 「設計パターンの適用 」を参照してください。