集計パイプラインビルダー
Data Explorerは、データを処理するための集計パイプラインビルダを提供します。 集計パイプラインは、選択されたパイプライン ステージ に基づいて、ドキュメントを集計された結果に変換します。
MongoDB Atlas 集計パイプライン ビルダーは、パイプラインを実行するためではなく、主にパイプラインをビルドするために設計されています。 パイプライン ビルダーを使用すると、 パイプラインをエクスポートして、ドライバー で実行する簡単な方法が提供されます。
Data Explorerにアクセスするには、以下の手順を行います。
左側のナビゲーションで [ Deployment ] をクリックします。
必要な MongoDB 配置を選択します。
Data Explorer タブを選択します。
必須のロール
Data Explorerで集計パイプラインを作成して実行するには、少なくともProject Data Access Read Onlyロールが付与されている必要があります。
パイプラインで$outステージを利用するには、少なくともProject Data Access Read/Writeロールが付与されている必要があります。
集計パイプライン ビルダーへのアクセス



集計パイプラインを作成する


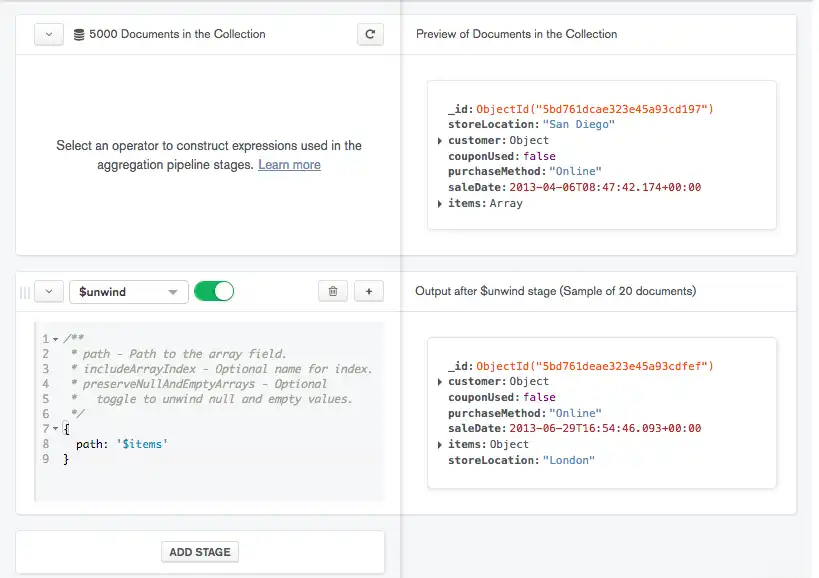
集計ステージを入力してください。
ステージに適切な値を入力します。 コメントモードが有効になっている場合、パイプラインビルダは選択したステージの構文ガイドラインを提供します。
ステージを変更すると、 Data Explorerは現在のステージの結果に基づいて右側のプレビュー ドキュメントが更新されます。



照合
collation を使用して、大文字と小文字やアクセント記号のルールなど、文字列比較の言語固有のルールを指定します。
照合ドキュメントを指定するには、パイプライン ビルダーの上部にある Collation をクリックします。
照合ドキュメントには、次のフィールドがあります。
{ locale: <string>, caseLevel: <boolean>, caseFirst: <string>, strength: <int>, numericOrdering: <boolean>, alternate: <string>, maxVariable: <string>, backwards: <boolean> }
locale フィールドは必須です。その他の照合フィールドはすべてオプションです。フィールドの説明については、「照合ドキュメント」を参照してください。
テキストからの集計パイプラインをインポートする
集計パイプラインをプレーンテキストからパイプライン ビルダーにインポートして、パイプラインを簡単に変更および検証できます。
プレーンテキストからパイプラインをインポートするには、次の手順に従います。


ダイアログにパイプラインを入力または貼り付けます。
パイプラインは、db.collection.aggregate() メソッドの pipeline パラメーターの構文と一致する必要があります。
パイプラインをリセットする
パイプラインを初期の空白の状態に戻すには、パイプライン ビルダーの上部にあるプラス アイコンをクリックします。
集計パイプラインをドライバー言語でエクスポートする
集約パイプライン ビルダーを使用すると、完成したパイプラインを、サポートされている ドライバー言語(Java、Node、C#、Python 3)のいずれかにエクスポートできます。この機能を使用して、アプリケーションで使用できるようにパイプラインをフォーマットおよびエクスポートします。
集計パイプラインをエクスポートするには、次の手順に従います。
集計パイプラインを構築します。
集計パイプラインの作成手順については、「 集計パイプラインの作成 」を参照してください。
希望のエクスポート言語を選択します。
Export Pipeline To ドロップダウンで、希望の言語を選択します。
左側の My Pipeline ペインには、パイプラインが mongosh 構文で表示されます。
右側のペインには、選択した言語でパイプラインが表示されます。
集計パイプライン設定
集計パイプラインビルダーの設定を変更するには、次の手順に従います。

