- $cmd
- MongoDB のデータベースコマンド が公開される仮想 コレクション。データベースコマンドを使用するには、コマンドの発行 を参照してください。
- _id
- すべての MongoDB ドキュメントに必要なフィールド。_id フィールドにはユニークな値が必要です。
_idフィールドはドキュメントのプライマリキーと考えることができます。_idフィールドなしで新しいドキュメントを作成すると、MongoDB では自動的にこのフィールドが作成され、ユニークな BSON ObjectId が割り当てられます。 - 絶対システム CPU 使用率
CPU を共有するクラウドインスタンスが使用可能な CPU の全量に対するシステム CPU 使用率。
クラウドプロバイダーがクラウドインスタンスの CPU 使用率を調整する場合、インスタンスの絶対システム CPU 使用率は、このインスタンスに割り当てられたベースライン CPU 使用率と同じになります。
バースト メカニズムなど、クラウドプロバイダーがベースライン CPU より高い CPU を追加すると、インスタンス上の正規化されたカーネル CPU 使用率とユーザー CPU 使用率の合計が、インスタンスのベースライン CPU を超える可能性があります。 この場合、正規化されたカーネル CPU 使用率とユーザー CPU 使用率の合計は、クラウドインスタンスによって共有される CPU の完全な量よりも小さくなります。 「 相対的なシステム CPU 使用率 、 ベースライン CPU 使用率 、 バースト可能なインスタンス も参照してください。
- アキュムレータ
- 集計パイプライン 内のドキュメント間で状態を維持する 集計パイプライン 内 の 式 。アキュムレータ操作のリストについては、
$groupを参照してください。 - アクション
- ユーザーがリソースに対して実行できる操作。 アクションとリソースを組み合わせて特権を作成します。 「アクション 」を参照してください。
- 管理データベース
- 特権データベースです。特定の管理コマンドを実行するには、ユーザーは
adminデータベースへのアクセス権が必要です。管理コマンドのリストについては、「管理コマンド」を参照してください。 - 持続的標的型攻撃
- セキュリティにおいて、ネットワーク、ディスク、メモリへの長期的なアクセスを取得して維持し、長期間検出されないままになる攻撃者。
- 集計
- 大量のデータを削減して要約する操作。詳細については、「集計操作」を参照してください。
- 集計パイプライン
- ドキュメントを処理する 1 つ以上のステージで構成されます。集計パイプラインは、複雑なクエリをExpressための豊富な構文を提供します。 ステージのリストについては、集計ステージを参照してください。
- アラート
データベース操作またはサーバーの使用率がクラスターのパフォーマンスに影響を与えるしきい値に達したときに、Atlas によって送信される通知。アラートをトリガーするために設定できる条件については、アラート条件の確認を参照してください。
Tip
- 分析ノード
- 運用ワークロードに影響を与えたくないクエリを分離できる特殊な読み取り専用ノード。 分析ノードは、BI ツールによって実行されるクエリのレポートなどの分析データを処理するのに役立ちます。 読み取りパフォーマンスを最適化し、レイテンシを削減するために、専用の地理的リージョンで分析ノードをホストできます。
- API
クライアントと MongoDB Atlas 間の相互作用を容易にする通信プロトコル。 Atlas Administration API を使用して、Atlas UI で実行される多くのタスクを自動化できます。
- 近似近傍(ANN)検索
特定の クエリ点に近いポイントをデータセット内ですばやく見つけるために使用される計算手法です。ベクトル検索は、Ann 検索を使用して、すべてのベクトルをスキャンすることなく、クエリ内のベクトル埋め込みに最も近いデータ内のベクトル埋め込みを検索します。
- アービタ
- 選挙 で投票するためだけに存在する レプリカセット のノード 。アービタ はデータを複製しません。 アービタは プライマリの選挙 に参加しますが、プライマリになることはできません。 詳細については、「レプリカセット アービタ 」を参照してください。
- Atlas
- MongoDB Atlas はクラウドでホストされるサービスとしてのデータベースです。
- Atlas user
MongoDB Atlasアプリケーションにアクセスするために使用されるアカウント。MongoDB Atlasユーザーには、ユーザー ロールで定義された特定の権限を使用して、 MongoDB Atlas の組織、プロジェクト、またはその両方へのアクセス権を付与できます。MongoDB Atlasユーザーはデータベースユーザーとは異なります。MongoDB AtlasユーザーはMongoDBデータベースへのアクセスを提供していません。
- Atlas user role
Atlas userに付与される権限のセット。 権限は組織レベルまたはプロジェクトレベルで付与できます。
- アトミック操作
- アトミック操作とは、完全に完了するか、まったく完了しない書き込み操作です。複数のドキュメントへの書き込みを伴う分散トランザクションの場合、トランザクションを成功させるには、各ドキュメントへのすべての書き込みを成功させる必要があります。アトミック操作は部分的には完了できません。「原子性とトランザクション」を参照してください。
- 認証
- ユーザー ID の検証です。 「自己管理型配置での認証 」を参照してください。
- 承認
- データベースや操作へのアクセスをプロビジョニング。 「自己管理型配置の ロールベースのアクセス制御 」を参照してください。
- オートスケーリング
クラスターの使用状況に応じて、クラスター階層、ストレージ容量、またはその両方を自動的に増加または減少させるように構成可能なオプション。
- 自動暗号化
- 使用中の暗号化機能では、事前構成された暗号化スキーマに基づいた暗号化と複合化が自動的に実行されます。MongoDB のクエリ言語は、自動暗号化共有ライブラリによって適切な呼び出しに変換されるため、暗号化と復号化の呼び出し用にアプリケーションを書き直す必要はありません。
- B木
- データベース マネジメント システムでインデックスを保存するために一般的に使用されるデータ構造。MongoDBは B 木インデックスを使用します。
- バックアップ
特定の時点でのクラスターの状態をカプセル化するデータのコピー。 バックアップはデータ損失イベントが発生した場合の安全対策を提供します。
MongoDB Atlas は、フルマネージドのクラウドバックアップを提供します。
- バックアップカーソル
- バックアップ ファイルのリストをポイントする追尾可能 (tailable) カーソル。バックアップカーソルは内部専用です。
- バランサー
- シャーディングされたクラスターのコンテキストで実行され、チャンクの移行を管理する内部 MongoDB プロセス。 管理者は、シャーディングされたクラスターのすべてのメンテナンス操作でバランサーを無効にする必要があります。 「シャーディングされたクラスター バランサー 」を参照してください。
- ベースライン CPU 使用率
- CPU を共有するクラウドインスタンスが使用可能な CPU の全量に対する割合。 クラウドプロバイダーは、インスタンスのクラスター層に基づいて、各クラウドインスタンスに一定量のベースライン CPU を割り当てます。 通常、ベースライン CPU20 50使用率は絶対システム CPU 使用率の % と % の間で該当します。「相対的なシステム CPU 使用率とバースト可能なインスタンス」も参照してください。
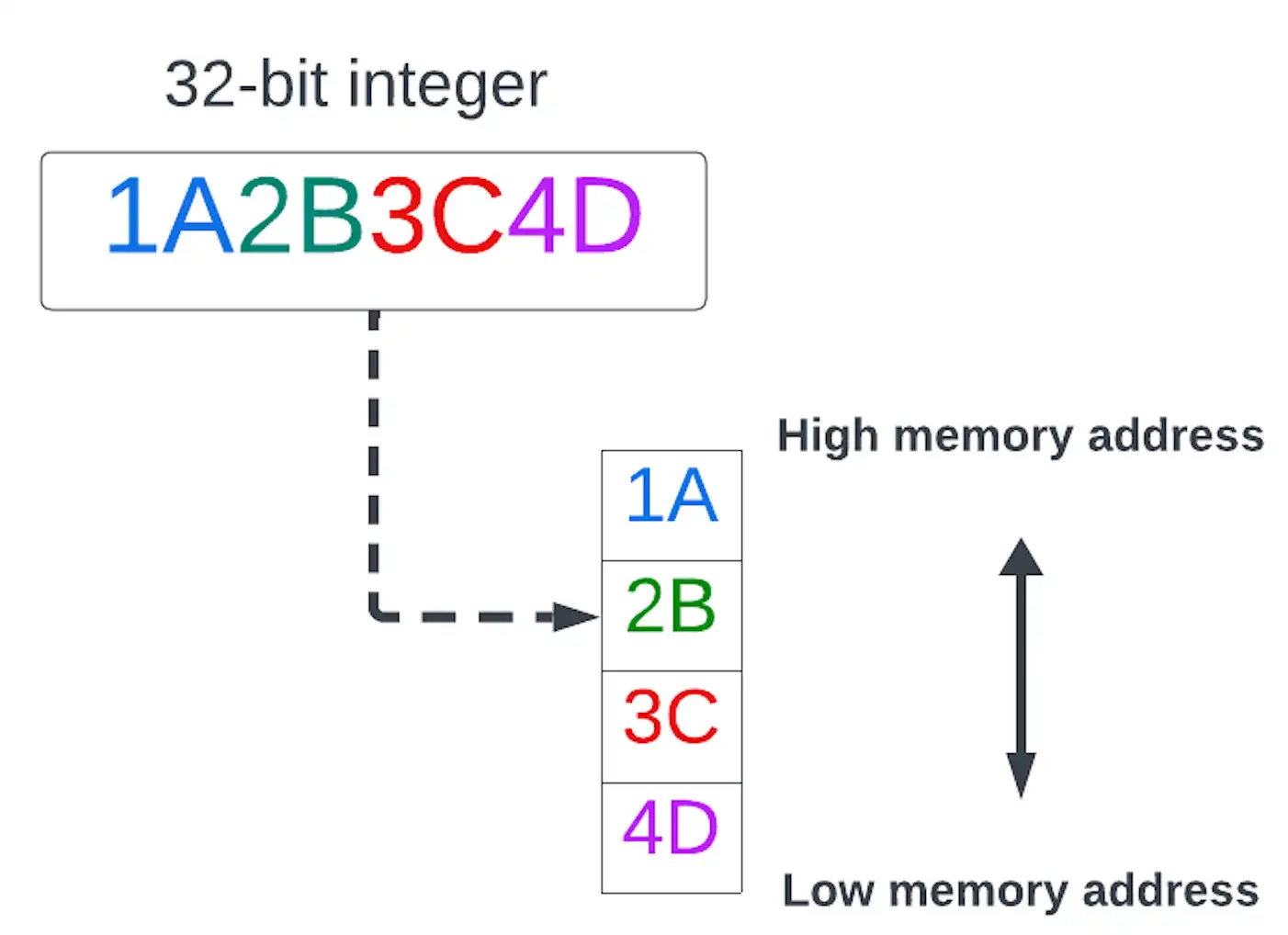
- ビッグエンディアン
マルチバイト データ値のうちバイト数が最大(ビッグエンド)のものが最下位のメモリ アドレスに格納されるバイト オーダー。
 クリックして拡大します
クリックして拡大します- ブロッキングソート
- 出力が返される前に、メモリ内での必ず実行されるソートです。メモリ内ソートは、大規模なデータセットのパフォーマンスに影響を与える可能性があります。インデックスのソートを使用して、メモリ内ソートを回避します。
- 有界コレクションスキャン
- クエリオプティマイザが使用するプランで、特定のフィールド値範囲のドキュメントを除外します。たとえば、日付フィールド値の範囲が指定された日付範囲外の場合、その範囲のドキュメントはクエリプランから除外されます。「コレクションスキャン」を参照してください。
- BSON
- MongoDB でドキュメントの保存とリモートプロシージャコールの実行に使用される直列化形式。「BSON」は「binary」と「JSON」という単語を組み合わせたものであり、JSON(JavaScript Object Notation)ドキュメントのバイナリ表現と考えることができます。BSON types と MongoDB 拡張 JSON(v2)を参照してください。
- BSON types
- BSON直列化形式でサポートされている型のセット。 BSON typesのリストについては、「 BSON types types 」を参照してください。
- バースト可能なインスタンス
- 一部のクラウドプロバイダーでは「CPUクレジット」モデルを使用する共通の物理 CPU を共有するクラウドインスタンスタイプ。バースト可能な インスタンスを使用すると、インスタンスリソースの異なる要求によって、共有 CPU の一部が各仮想インスタンスで使用可能になるか、使用できなくなる可能性があります。詳しくは、Amazon Web Services のバースト可能なインスタンス、Azureディスクのバースト、GCP CPU バーストを参照してください。「 ベースライン CPU 使用率 」、 「絶対システム CPU 使用率」 、「相対的システム CPU 使用率」も参照してください。
- CAP定理
- コンピューティング システムには、整合性、可用性、パーティション許容度という 3 つの特性があるため、分散コンピューティング システムではこれらの 3 つの機能のうち 2 つは提供できますが、3 つすべてを提供することはできません。
- 上限付きコレクション
- コレクションが最大サイズに達すると、最も古いエントリを自動的に上書きする固定サイズのコレクション。 レプリケーション で使用される MongoDB oplog は、Cappedコレクションです。「 Capped コレクション 」を参照してください。
- 濃度
- 値のセットにある要素数の尺度です。たとえば、
A = { 2, 4, 6 }のセットには 3 つの要素が含まれており、濃度は 3 です。「シャードキー濃度」を参照してください。 - 直積集合
- 2 つのデータセットを結合した結果では、結合されたセットに、可能なすべての値の組み合わせが含まれます。
- CFQ
- CFQ(Complete Fairness Queueing)は、受信リクエスト プロセスに帯域幅を割り当てる I/O 操作スケジューラです。
- チェックサム値
- データの整合性を確保するために使用される計算値。md5 アルゴリズムはチェックサム値として使用されることもあります。
- チャンク
- シャード内のシャードキー値の連続した範囲。チャンクの範囲は、下側の境界を含み、上側の境界を含みません。MongoDB は、クラスター内でデータのバランスを取る必要がある場合にチャンクを分裂します。デフォルトのチャンク サイズは 128 メガバイトですが、自動分裂をトリガーせずに、チャンクがデフォルトのサイズより大きくなる可能性があります。チャンクの分裂は、クラスター全体にデータを均等に分散するためのバランシング プロセスの一部として行われます。詳細については、チャンクを使用したデータのパーティショニング、クラスター バランサー、およびクラスター バランサーの管理を参照してください。
- クライアント
データの永続性とストレージにデータベースを使用するアプリケーション層。 ドライバーは、アプリケーション層とデータベース サーバー間のインターフェース レベルを提供します。
クライアントは 1 つのスレッドまたはプロセスである場合もあります。
- クライアントのアフィニティ
- 指定されたデータソースへのコンシステント クライアント接続です。
- クラウドバックアップ
クラスターのクラウド サービス プロバイダーのネイティブ スナップショット 機能を使用して、ローカライズされたクラスター バックアップ ストレージ。
MongoDB Atlas は、次の場所で提供されるクラスターのクラウドバックアップをサポートします。
Tip
- クラスター
MongoDBデプロイを構成するノードのセット。クラスターは、レプリカセット と シャーディングされた 配置にすることができます。
- クラスタークラス
Amazon Web Servicesでホストされている M40+ クラスター用に構成可能です。
クラスターのストレージ クラス。 選択したクラスは、クラスター ストレージのパフォーマンスとクラスターのコストに影響します。 次のいずれかのクラスを選択できます。
Low CPU
General
Local NVMe SSD
- クラスター層
クラスター内の各データを保持するサーバーのメモリ、ストレージ、vCPU、 IOPS仕様を決定します。 クラスター階層が増加すると、クラスター ストレージ サイズと全体的なパフォーマンスも増加します。
- クラスター間の同期
- シャードされたクラスター間でデータを同期します。C2C 同期とも呼ばれます。
- クラスター化されたコレクション
- クラスター化されたインデックス キー順のドキュメントを保存する コレクション 。「クラスター化されたコレクション 」を参照してください。
- CMK
- カスタマーマスターキーの略語。「カスタマーマスターキー」を参照してください。
- コレクション
- MongoDB ドキュメントをグループにしたもので、RDBMS テーブルと同じものです。単一データベース内にあり、スキーマを強制しません。コレクション内のドキュメントには異なるフィールドが含まれることがあります。通常は、類似または関連する目的があります。名前空間を参照してください。
- コレクションスキャン
- コレクションスキャンというクエリ実行戦略では、MongoDB はコレクション内のすべてのドキュメントを検査して、クエリ条件に一致するかどうかを確認する必要があります。このようなクエリは非常に効率が悪く、インデックスを使用しません。クエリ実行戦略の詳細については、「クエリの最適化」を参照してください。
- コミット
startSessionコマンドの開始後に行われたデータの変更を保存します。トランザクション内の操作は、commitTransactionコマンドでコミットされるまで永続的ではありません。- コミットクォーラム
- インデックス構築中、コミットクォーラムは、プライマリ ノードがコミットを実行する前に、ローカル インデックス構築をコミットする準備ができている必要のあるセカンダリの数を指定します。
- 複合インデックス
- 2 つ以上のキーで構成されるインデックス。 「複合インデックス 」を参照してください。
- 同時実行制御
- 同時実行性制御は、データベースの操作が正確性に妥協することなく同時に実行できるようにする仕組みです。悲観的な同時実行制御では、競合する可能性がない場合でも、競合の懸念があるすべての操作がブロックされます。ロックを備えたシステムで使用されるものはその代表例です。楽観的な同時実行制御は、WiredTiger で採用されている方式であり、競合が発生した可能性が生じるまでチェックを遅らせます。何らかの書込み競合(write conflict)が発生した場合は、いずれかの操作を終了して再試行します。
- config database
- シャードされたクラスターのメタデータを含む内部データベース。通常、ユーザーが
configデータベースを変更することはありません。configデータベースの詳細については、「コンフィギュレーションデータベース」を参照してください。 - config server
- シャーディングされた
mongodクラスター に関連付けられたすべてのメタデータを保存する インスタンス。「コンフィギュレーションサーバー 」を参照してください。 - コンフィギュレーションシャード
- シャーディングされたクラスターに関連付けられたすべてのメタデータを保存し、アプリケーションデータも保存できる
mongodインスタンス。「コンフィギュレーションシャード」を参照してください。 - 接続プール
- ドライバーによって保持されるデータベース接続のキャッシュです。キャッシュされた接続は、データベースへの接続が必要なときに、新しい接続を開始する代わりに再利用されます。
- 接続ストーム
- 配置が処理できる以上の接続をドライバーが作成しようとするシナリオ。ドライバーは、新しい接続のリクエストに失敗すると、配置の減速や新しい接続の作成失敗を受け、さらに多くの接続確立をリクエストします。これらの継続的なリクエストにより、配置に過剰な負荷がかかり、停止につながる恐れがあります。
- コンテナ
- コンピューティング環境間の移行を容易にするためにパッケージ化されたソフトウェアとそれに依存しているライブラリの集合です。コンテナはオペレーティング システム上で区分化されたプロセスとして実行され、独自のリソース制約を設定できます。一般的なコンテナ テクノロジーは Docker と Kubernetes です。
- 競合係数
- ドキュメント フィールドなどの同じリソースを変更しようとする複数の操作では、競合が発生し、操作が遅延します。 競合係数は、暗号化されたフィールドと値のペアを内部的に分割し、操作を最適化するために Queryable Encryption で使用される設定です。 「競合 」を参照してください。
- コサイン類似度
- 2 つのベクトル間の角度を使用して、それらのベクトル間の類似性を判断するメトリクス。コサイン類似度はベクトルの方向に影響されます。ベクトル検索のベクトル埋め込みをインデックス化するときに、コサイン類似度関数を使用できます。ベクトルが単位の長さで正規化されている場合は、代わりに dotProduct 類似度 関数を使用します。
- CPU スティール
- CPU 使用が保証されたベースライン CPU クレジット蓄積率を超過する割合。CPU スティールは、バースト戦略でクレジットモデルに依存するクラウドプロバイダーにとって重要です。CPU クレジットは、蓄積される CPU 使用率の単位です。クレジットは一定の割合で蓄積され、保証されたレベルのパフォーマンスを提供します。これらのクレジットを使用して、CPU パフォーマンスをさらに向上させることができます。クレジット残高がなくなると、MongoDB は保証された CPU パフォーマンスのベースラインのみを提供し、超過分をスティールパーセントとして表示します。相対的なシステム CPU 使用率、ベースライン CPU 使用率、バースト可能なインスタンスも参照してください。
- CRUD
- データベースの基本操作(Create、Read、Update、Delete)の頭字語です。MongoDB CRUD 操作を参照してください。
- CSV
- カンマ区切りの値を持つテキスト データ形式。CSV ファイルには表形式のデータがあるため、関係データベース間でのデータ交換に使用できます。
mongoimportを使用して CSV ファイルをインポート可能です。 - cursor
- クエリ の結果セットへのポインター。クライアントはカーソルを反復処理して結果を検索できます。デフォルトでは 、セッション内で開かれていないカーソルは、10 分間非アクティブになると自動的にタイムアウトになります。セッション内で開かれたカーソルは、セッションの終了またはタイムアウトとともに閉じられます。「カーソル」を参照してください。
- カスタムロール
保存して データベースユーザー に割り当てることができる、MongoDBの 特権アクション とMongoDBの ロール のカスタムセット。MongoDB Atlas の組み込みロールで必要な権限セットが記述されていない場合は、カスタムロールを作成します。
- CMK(カスタマー マスター キー)
- データ暗号化キー を暗号化するキー。 カスタマー マスター キーは、リモート キー プロバイダーでホストされている必要があります。
- daemon
- バックグラウンドの非インタラクティブ プロセス。
- データディレクトリ
mongodがデータファイルをストアするファイル システムのロケーションです。dbPathでデータディレクトリを指定します。- データ暗号化キー
- MongoDB ドキュメントのフィールドの暗号化に使用するキー。暗号化されたデータ暗号化キーは、キーヴォールトコレクションに保存されます。データ暗号化キーはCMKによって暗号化されます。
- Data Explorer
クラスター データを表示および操作するためのMongoDB Atlas内のツールです。また、 Data Explorerを使用してインデックスを管理し、集計パイプラインを実行してデータを処理することもできます。
Tip
- Data Federation
MongoDBクエリ言語 を使用して、低コストの S3 バケット、 MongoDB Atlasクラスター、 HTTPエンドポイントに保存されているデータをクエリするための MongoDB のソリューション。分析アプリケーションは、Atlas Data Federation を使用して、データ処理ニーズにアーカイブ データを使用できます。
- データファイル
- ドキュメント データとインデックスを保存します。
dbPathオプションは、データ ファイルのファイル システムの場所を指定します。 - データ取り込みパイプライン
- RG を使用し、 MongoDB Atlasなどのベクトルデータベースに保存することで、データを整理および変換するためのワークフローです。
- データパーティション
- データを範囲に分裂する分散システム アーキテクチャ。シャーディングではパーティショニングが使用されます。「チャンクを使用したデータのパーティショニング」を参照してください。
- データセンターの認識
- クライアントが場所に基づいてシステム内のメンバーにアドレス指定できるようにするプロパティ。 レプリカセットは、タグ付けを使用してデータセンターの認識を実装します。 「データセンターの認識 」を参照してください。
- database
- コレクションのコンテナ。 各データベースには、ファイル システム内のファイルのセットがあります。 通常、1 つの MongoDB サーバーには複数のデータベースがあります。
- データベースコマンド
- insert、update、remove、クエリ以外の MongoDB の操作です。データベースコマンドの一覧については、「データベースコマンド」を参照してください。データベースコマンドを使用するには、「コマンドの発行」を参照してください。
- データベースの持ち出し
- データベースの持ち出しとは、権限のある者が安全なシステムからデータを取得し、それを権限のない者と共有するか、安全でないシステムに保存することを指します。これは悪意がある場合もあれば、偶発的な場合もあります。
- database profiler
- 有効にすると、実行時間が長いすべての操作の記録をデータベースの
system.profileコレクションに保存するツールです。プロファイラーは、遅いクエリを診断するために最もよく利用されます。詳しくは、データベースプロファイラーを参照してください。 - データベースユーザー
MongoDBクラスターにアクセスするためのクライアントを認証するために使用される認証情報。データベースユーザーに権限を割り当てて、そのユーザーのクラスターへのアクセスレベルを決定できます。データベース ユーザーは Atlas ユーザーとは異なります。データベース ユーザーは、 MongoDB Atlasアプリケーションではなく、 MongoDB配置にアクセスできます。
- dbpath
- MongoDB のデータファイル ストレージのロケーションです。
dbPathを参照してください。 - DDL (データ定義言語)
- DDL には、コレクションとインデックスを作成および変更するコマンドが含まれています。
- デッドレターキュー (DLQ)
- デッドレターキュー (DLQ)は、取り込み中にエラーをスローしたドキュメントを保存するMongoDB Atlas データベース内のコレクションです。
- 専用クラスター
階層
M10以上のクラスターを含むクラスター カテゴリ。階層推奨環境M10およびM20開発
低トラフィック本番
M30以上本番環境
- 専用コンフィギュレーションサーバー
- シャーディングされたクラスター に関連するすべてのメタデータのみを保存する
mongodインスタンス。 - DEK
- データ暗号化キー。 詳細については、「データ暗号化キー 」を参照してください。
- 遅延ノード
- プライマリになることができず、指定された遅延で操作を適用するレプリカセットノード。 遅延は、人間によるエラー(意図せずに削除されたデータベース)や本番データベースに予期しない影響を与える更新からデータを保護するのに役立ちます。 「遅延レプリカセット ノード 」を参照してください。
- 密なベクトル
- ほとんどまたはすべての次元にゼロ以外の値が含まれているデータの数値表現。ベクトル検索は、より複雑な関係をキャプチャするために、より多くのデータを含む高密度のベクトルを使用します。
- 配置
- データを含むMongoDBサーバーのグループ。MongoDB Atlasが管理するクラスターはクラスター(レプリカセット または シャーディングされたクラスター)です。
- 次元
- 多次元空間内のデータの機能または属性を構成するコンポーネントまたは要素の数。ベクトル検索は、インデックス作成時とクエリ時に最大
4096次元をサポートします。 - ドキュメント
- MongoDBコレクション内のレコードと、MongoDB 内のデータの基本単位。 ドキュメントはJSONオブジェクトと似ていますが、 BSONと呼ばれるよりタイプが多い形式でデータベースに存在します。 「ドキュメント 」を参照してください。
- ドット表記
- MongoDB は、ドット表記を使用して配列の要素にアクセスし、埋め込みドキュメントのフィールドにアクセスします。「ドット表記」を参照してください。
- dotProduct の類似性
- 多次元空間内の 2 つのベクトル間の類似性を測定し、ベクトルがほぼ同じ方向を点場合は正、ベクトルが逆の方向を点場合は負、ベクトルに類似性がない場合は 0 のスカラー値を返します。ベクトル検索では、最近傍の検索時に
dotproduct類似度関数を使用することがサポートされています。ベクトルが単位の長さで正規化されている場合は、コサイン類似度の代わりにこの類似度関数を推奨します。 - ドレイン
- あるシャードから別のシャードへチャンクを排除または「排出」するプロセス。管理者は、シャードをクラスターから排除する前にシャードを draining する必要があります。「シャーディングされたクラスターからシャードを削除する」を参照してください。
- ドライバー
- 特定のコンピューター言語で MongoDB を操作するためのクライアント ライブラリ。 ドライバー を参照してください。
- 耐久性がある
- 1 つ以上のサーバー プロセスをシャットダウン(またはクラッシュ)して再起動した後に続く書込み操作は耐久性があります。 単一の
mongodサーバーの場合、書込み操作は、サーバーのジャーナルファイルに書込まれているときに永続的と見なされます。 レプリカセットの場合、書込み操作は、書込み操作が大多数の投票ノードで耐久性を確保し、大多数の投票ノードのジャーナルに書込まれた後に耐久性があると見なされます。 - 選挙可能な\nノード
- レプリカセット の プライマリ ノードになる資格のあるノード。MongoDB Atlas は、選挙中にプライマリ資格として最も優先順位が高いリージョンのノードを優先します。確実に選挙を行うには、リージョン全体の選択可能なノードの合計数が 3、5、または 7 である必要があります。
- 選挙
- レプリカセットのメンバーが起動時とエラー発生時にプライマリを選択するプロセス。「レプリカセットの選出」を参照してください。
- 埋め込み
- テキスト、画像、オーディオ、ビデオなどのデータを数値の配列として表現し、多次元空間内の座標として解釈できます。MongoDB Atlas はMongoDB Atlasクラスターへの埋め込みの保存をサポートしており、 ベクトル検索 は最大
4096次元のベクトル埋め込みのインデックス作成とクエリをサポートしています。 - 暗号化のキー
データの暗号化と復号化専用に生成されたビットのランダムなstring 。
MongoDB Atlas
Project Ownersは、 MongoDB Atlasが提供するデフォルトの保管時の暗号化に加えて、データの追加の暗号化レイヤーを構成できます。プロジェクト所有者は、 MongoDB Atlasと互換性のあるカスタマーキー管理プロバイダーをMongoDB暗号化ストレージエンジンとともに使用できます。MongoDB Atlas は、保存時の暗号化の構成で次のカスタマーキー管理プロバイダーをサポートします。
- 暗号化スキーマ
- Queryable Encryptionでは、どのフィールドがクエリ可能で、どのフィールドで許可されるクエリ タイプを定義する encryptedFieldsドキュメント。
- エンディアン性
- コンピューティング分野では、エンディアンとはバイトが配置される順序を指します。エンディアンは、通信媒体を介した送信を指す場合もありますが、バイトの重要性と位置に基づくコンピューター メモリ内でのバイトの順序付け方法を指す場合の方がより一般的です。詳細については、ビッグエンディアンとリトルエンディアンを参照してください。
- エンベロープ暗号化
- データ暗号化キーを使用してデータが暗号化され、データ暗号化キーがカスタマー マスターキー と呼ばれる別のキーで暗号化される暗号化手順。 暗号化されたキーは、KeyVault と呼ばれる MongoDB コレクションにBSONドキュメントとして保存されます。
- ユークリッド類似性
- 多次元空間内の 2 つのベクトル間の距離を使用して類似性を計算するための式。ユークリッド距離はベクトルの大きさに影響されます。ベクトル検索では、ベクトルのインデックス作成と、最近傍を検索するときに
euclidean類似度関数を使用することがサポートされています。 - 結果整合性
- システムへの変更が徐々に伝達されるようにする分散システムの特性です。データベース システムでは、読み取り可能なノードが最新の更新を保持する必要がないことを意味します。
- 明示的な暗号化
- 使用中の暗号化を使用する場合、暗号化データの操作時に、暗号化や復号化操作、keyID、クエリのタイプ(Queryable Encryption の場合)またはアルゴリズム(クライアント側フィールドレベル暗号化の場合)を明示的に指定します。自動暗号化と比較してください。
- 式
値に変換されるクエリのコンポーネント。 式はステートレスであるため、式の構築に使用される値をミューテーションせずに値が返されます。
MongoDB クエリ言語では、次のコンポーネントから式を構築できます。
コンポーネント例定数
3演算子
フィールドパス式
"$<path.to.field>"例、
{ $add: [ 3, "$inventory.total" ] }は、$add演算子と 2 つのオペランドで構成される式です。定数
3フィールドパス式
"$inventory.total"
式は、入力ドキュメントのパス
inventory.totalの値に3を追加した結果を返します。- フェイルオーバー
- 障害発生時に レプリカセット の セカンダリ メンバーが プライマリ になるようにするプロセス。「自動フェイルオーバー 」を参照してください。
- フィールド
- ドキュメント内の名前と値のペア。 ドキュメントには 0 個以上のフィールドがあります。 フィールドは、関係データベースの列に類似しています。 「ドキュメント構造 」を参照してください。
- フィールドパス
- ドキュメント内のフィールドへのパス。フィールドパスを指定するには、フィールド名の前にドル記号(
$)を付けた文字列を使用します。 - ファイアウォール
- IP アドレスやその他のパラメーターに基づいてアクセスを制限するシステム レベルのネットワーク フィルターです。ファイアウォールは、セキュリティで保護されたネットワークの一部です。「ファイアウォール」を参照してください。
- 無料クラスターとフレキシブルなクラスター
Free(無料階層)階層クラスターを含むクラスター カテゴリ。無料クラスターと Flex クラスターは通常、開発および小規模本番ワークロードに使用されます。- 無料階層
データをホストするための小規模な開発環境を提供する無料で使用できるクラスター層。無料のクラスターには有効期限がなく、Atlas の機能のサブセットにアクセスできます。無料クラスターは、インスタンスサイズ
M0によって呼ばれることもあります。- fsync
メモリ内のすべてのダーティ ページをストレージにフラッシュするシステム呼び出しです。アプリケーションがデータを書き込むと、MongoDB ではデータがストレージ層に記録されます。
永続的なデータを提供するために、 WiredTigerはチェックポイントを使用します。 詳細については、「ジャーナリングと WiredTiger ストレージ エンジン 」を参照してください。
- ジオハッシュ
- ジオハッシュ値は、座標グリッド上のロケーションのバイナリ表現です。「ジオハッシュ値」を参照してください。
- GeoJSON
- JavaScript Object Notation( JSON )に基づく地理空間データの交換形式。GeoJSON は 地理空間クエリ で使用されます。サポートされている GeoJSON オブジェクトについては、 「地理空間データ」 をご参照ください。GeoJSON形式の仕様については、 https://tools.ietf.org/html/rfc7946 #section-.3 1を参照してください。
- 地理空間
- 地理的な場所に関連します。「地理空間クエリ」を参照してください。
- グローバル クラスター
グローバルに分散されたアプリケーション インスタンスとクライアントに対してロケーション認識型の読み取りおよび書込み操作をサポートするための 地理的ゾーン が定義されたクラスター。 階層
M30以上のクラスターでグローバル シャーディングを有効にできます。- グローバル書き込みゾーン
グローバルクラスターのディストリビューションのサブセットを表す地理的ゾーン。各グローバルクラスターは最大 9 の個別のグローバル書き込みゾーンをサポートします。各ゾーンは、1 つの最優先リージョンと、1 つ以上の選択可能、読み取り専用、または分析リージョンで構成されます。
利用可能な地理的リージョンは、選択したクラウド サービス プロバイダーによって異なります。
- GridFS
- MongoDB データベースに大容量のファイルを保存するための規則。すべての公式 MongoDB ドライバーは、
mongofilesプログラムと同様に GridFS 規則をサポートしています。GridFS を参照してください。 - グループ
- プロジェクト を参照してください。
- グループ ID
- プロジェクトID を参照してください。
- ハッシュされたシャードキー
- シャードキー フィールドの値のハッシュを使用して シャードクラスタのノードにドキュメントを配布する シャードキー のタイプ。 「ハッシュされたインデックス 」を参照してください。
- ヘルスマネージャー
- ヘルスマネージャーは、指定された 強度レベル で ヘルスマネージャーファセット に対してヘルスチェックを実行します。ヘルスマネージャーのチェックは指定された時間間隔で実行されます。 ヘルスマネージャーは、障害のあるmongosをクラスターから自動的に移動するように構成できます。
- ヘルスマネージャーファセット
- ヘルスマネージャーがヘルスチェックを実行するように構成できる機能のセット。 たとえば、DNS または LDAP クラスターの健全性の問題を自動的に監視および管理するようにヘルスマネージャーを構成できます。 詳細については、「ヘルスマネージャーのファセット」を参照してください。
- 非表示ノード
- プライマリ になることができず、クライアントアプリケーションからは参照できない レプリカセット のノード。「非表示のレプリカセット ノード 」を参照してください。
- 階層的ナビゲーション可能なスモールワールドグラフ
- 多次元空間で効率的な最近傍検索を実行するためのアルゴリズム。ベクトル検索 はHierarchical Navigable Small Worlds を使用して ANN 検索を実行します。
- 高可用性
高可用性とは、耐久性、冗長性、自動フェイルオーバーを考慮して設計されたシステムを指します。そのようなシステムでサポートされているアプリケーションは、長期間にわたってダウンタイムなしで動作できます。MongoDB レプリカセットは、ベストプラクティスに従って配置すると、高可用性をサポートします。
レプリカセットの配置アーキテクチャに関するガイダンスは、「レプリカセットの配置アーキテクチャ」を参照してください。
- 最優先リージョン
- ハイブリッド検索
- 全文検索やセマンティック検索などの異なる検索メソッドを組み合わせて、それぞれの利点を活用する方法。 結果は、RRF(Reciリスト ランク統合)などの手法を使用して結合されます。
- idempotent
- 同じ入力で操作を複数回実行すると、同じ結果が生じます。
- 影響
Estimated Performance Advisor が提案するインデックスのパフォーマンス向上。
- メモリ内ソート
出力が返される前に、メモリ内での必ず実行されるソートです。メモリ内ソートは、大規模なデータセットのパフォーマンスに影響を与える可能性があります。インデックスのソートを使用して、メモリ内ソートを回避します。
インデックスのソート操作の詳細については、「ソートとインデックスの使用」を参照してください。
- 使用中の暗号化
- 送信、保存、処理時にデータを保護し、その暗号化されたデータに対してサポートされているクエリを有効にする暗号化。MongoDBは、使用中の暗号化に対して、Queryable Encryption とクライアント側フィールド レベルの暗号化という 2 つのアプローチを提供します。
- index
- クエリを最適化するデータ構造です。「インデックス」を参照してください。
- インデックスの限界
- MongoDB がインデックスを使用してクエリを実行するときに検索するインデックス値の範囲です。詳しくは、「マルチキー インデックスの限界」を参照してください。
- インデックス署名
- インデックス を一意に識別するパラメータの組み合わせ。
- インデックスのソート
- ソート結果がインデックスによって提供されるソート。インデックスを使用するソート操作は、多くの場合、メモリ内ソートよりもパフォーマンスが優れています。詳細については、「インデックスを使用してクエリ結果をソートする」を参照してください。
- init script
- Linux プラットフォームの初期化システムで使用される shell スクリプトで、デーモンプロセスを開始、再起動、または停止します。 パッケージ マネージャーを使用して MongoDB をインストールした場合、インストールの一部としてシステムの初期化スクリプトが提供されます。 詳しくは、ご利用中のオペレーティング システム用のインストール ガイドを参照してください。
- init システム
- init システムは、カーネルの起動後に Linux プラットフォーム上で最初に開始されるプロセスであり、システムにおける他のプロセスをすべて管理します。init システムは、init スクリプト を使用して、
mongodやmongosなどのデーモンプロセスを開始、再起動、または停止します。最近の Linux バージョンでは通常、systemd init システムとsystemctlコマンドが使用されます。古いバージョンの Linux では通常、System V init システムとserviceコマンドが使用されます。詳しくは、ご利用中のオペレーティング システム用のインストール ガイドを参照してください。 - 最初の同期
- 既存のレプリカセット ノードから新しいレプリカセット ノードにデータを複製するレプリカ セット操作。詳しくは、最初の同期を参照してください。
- 意向ロック
- リソースのロック 。これは、意向ロックを持つリソースよりも細かい粒度の同時実行制御を使用して、リソースを から読み取り(インテント共有)、またはリソースに書込む(意向排他)ことを示します。 インテント ロックにより、リソースの同時読み取りと書込みが可能になります。 詳しくは、 MongoDB ではどのようなタイプのロックを使用しますか。 を参照してください。
- インターフェイスエンドポイント
Amazon Web Services プライベートIPアドレスを持つVPCエンドポイントで、 Amazon Web Services PrivateLink 経由でMongoDB Atlasプライベートエンドポイント サービスにトラフィックを送信します。
- 割り込みポイント
- 操作を安全に終了できる点です。MongoDB では、指定された割り込みポイントによってのみ操作を終了します。「実行中の操作の終了」を参照してください。
- IP アクセス リスト
MongoDB Atlasプロジェクト内のクラスターへのアクセス権を持つIPアドレスと CIDR ブロックのリスト。パブリック インターネット経由のクライアント接続の場合、 MongoDB Atlas は対応するプロジェクトのIP アクセス リストのエントリからのみクラスターへの接続を許可します。アクセス リストには最大 200 エントリを含めることができます。
MongoDB Atlas、ネットワークピアリング接続やプライベートエンドポイントなど、非パブリック ネットワークを介したクライアント接続も許可されます。これらのタイプの接続は、 IP アクセス リストに関係なく機能します。詳しくは、「ネットワーク ピアリング接続の設定」および「Atlas のプライベート エンドポイントの詳細」を参照してください。
- IPv6
- インターネット ホストをサポートするための、大規模なアドレス空間を備えた IP(インターネット プロトコル)標準の改訂版です。
- ISODate
- 日付を表示するために
mongoshで使用される国際日付形式。 形式はYYYY-MM-DD HH:MM.SS.millisです。 - JavaScript
- スクリプト言語。mongosh、レガシー
mongoshell、および特定のサーバー関数は JavaScript インタープリターを使用します。詳細については、サーバーサイド JavaScript を参照してください。 - journal
- ハードシャットダウンのイベントでデータベースを有効な状態にするために使われる逐次的なバイナリ トランザクション ログ。ジャーナリングでは、最初にジャーナル、次にコア データファイルの順にデータが書き込まれます。ジャーナルファイルは事前に割り振られており、データディレクトリにファイルとして存在します。詳しくは、ジャーナリングを参照してください。
- JSON
- JavaScriptオブジェクト表記。多くのプログラミング言語でサポートされている構造化データを表現するためのプレーンテキスト形式。詳細については、http://www.json.org を参照してください。特定のMongoDB ツールは、 MongoDB BSONドキュメントの近似値をJSON形式でレンダリングします。MongoDB拡張JSON (v2) を参照してください。
- JSON document
- JSON ドキュメント は、 構造化形式のフィールドと値のコレクションです。JSONドキュメントのサンプルについては、http://json.org/example.html例を参照してください。
- JSONポインター
- JSONドキュメント内の特定のフィールド値を指定する 文字のプレフィックスが付いた string 。
/ - JSONP
- パディング付きのJSON 。 アプリケーションに JSON を挿入する方法を指します。 潜在的なセキュリティ上の懸念 を表示します。
- ジャンボチャンク
- 指定したチャンク サイズを超え、小さなチャンクに分割できないチャンク。詳細については、分割不可/ジャンボチャンク を参照してください。
- K 近傍検索
- 定義された類似性関数Sを持つポイントPのセットが指定されている場合、クエリ点qには、S*(*p, q)の最適な値を持つP内のkポイントのセットが検索されます。ベクトル検索ENN 検索では正確な上位 k ポイントが返され、ANN 検索では q に類似する k ポイントが返されますが、必ずしも q に最も近い k ポイントではありません。
- キーマテリアル
- 暗号化アルゴリズムがデータの暗号化と復号化に使用するランダムな文字列のビットです。
- キーヴォールトコレクション
- 暗号化されたデータ暗号化キーをBSONドキュメントとして保存する MongoDB コレクション。
- LDAP
- ユーザーを認証し、クラスター上のデータにアクセスする権限を付与するために使用されるクロスプラットフォームプロトコル。MongoDB Atlasを使用すると、TLS 経由で独自の LDAPサーバーを使用するすべてのMongoDBクライアントからのユーザー認証と認可を管理できます。単一の LDAPS 構成は、 MongoDB Atlasプロジェクト内のすべてのクラスターに適用されます。
- 最小権限
- ユーザーの作業に不可欠なアクセスのみをユーザーに許可する承認ポリシーです。
- legacy coordinate pairs
- MongoDB バージョン2.4より前の地理空間データに使用されている形式。 この形式では、地理空間データを平面座標系の点として保存します(たとえば、
[ x, y ])。 「地理空間クエリ 」を参照してください。 - LineString
- LineStringは、2 つ以上の位置の配列です。4 つ以上の位置を持つ閉じたLineString は、GeoJSON LineString仕様(https://tools.ietf.org/html/rfc7946#section-3.1.4)で説明されているように、LinearRing と呼ばれます。MongoDBでLineStringを使用するには、GeoJSON オブジェクトを参照してください。
- link-token
- Cloud ManagerまたはMongoDB Ops Manager の配置からMongoDB Atlasのクラスターへのライブ移行中に、 Cloud ManagerまたはMongoDB Ops ManagerからMongoDB Atlasに接続するために必要な情報を含む string 。
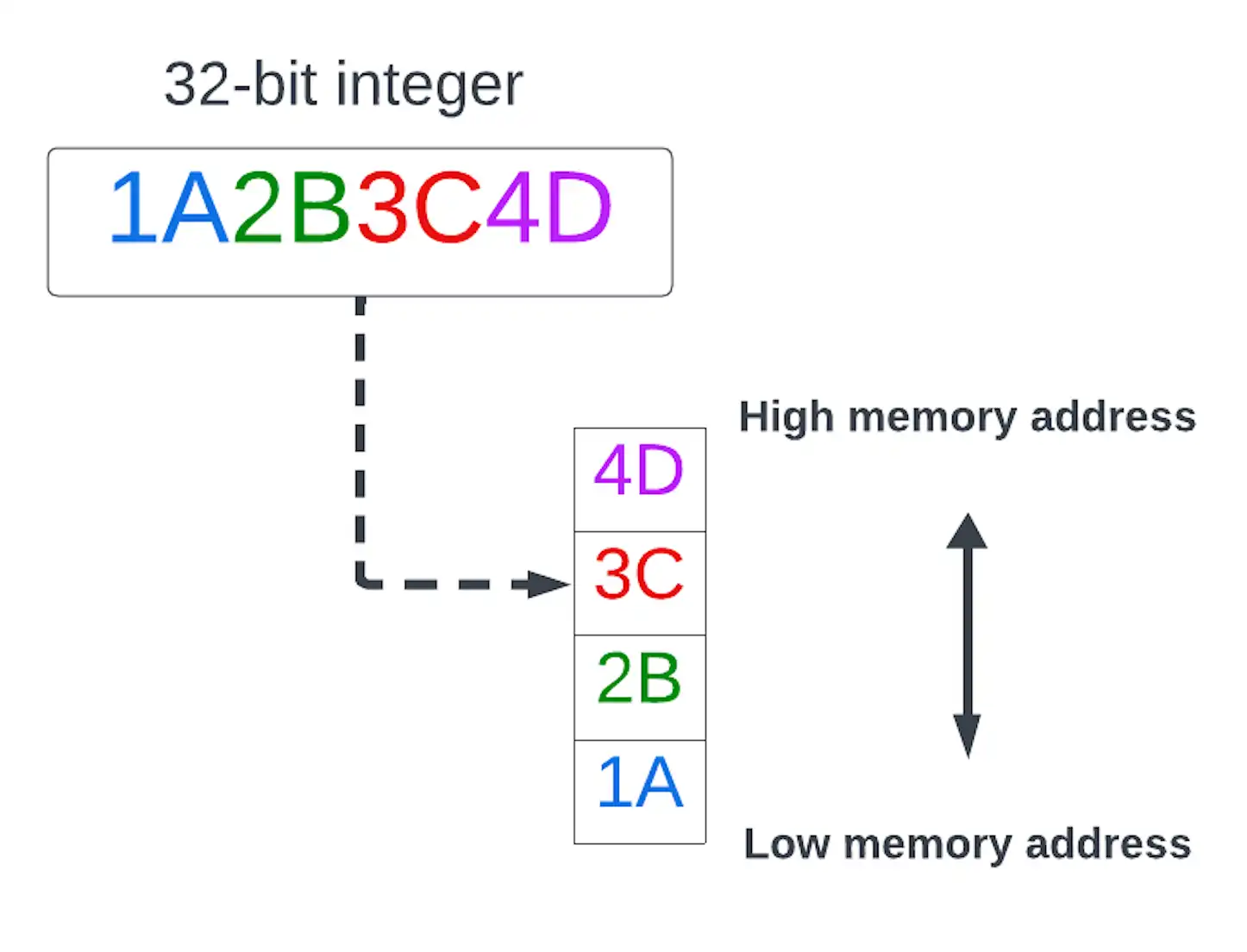
- リトルエンディアン
マルチバイト データ値のうちバイト数が最小(リトルエンド)のものが最下位のメモリ アドレスに格納されるバイト オーダー。
 クリックして拡大します
クリックして拡大します- ライブ移行
既存のソースレプリカセットまたはシャーディングされたクラスターをMongoDB Atlasにシームレスに移動するための プロセス。ライブ移行プロセス中、 MongoDB Atlas は、アプリケーションがMongoDB Atlasクラスターに切り替わるまで、ターゲットクラスターをリモートソースと同期した状態を維持します。
- ロック
- MongoDB は、同時実行性が正確性に影響を与えないようロックを使用します。 MongoDB は、 読み取りロック( read lock ) 、書込みロック(write lock) 、インテント ロックを使用します。 詳細については、「 MongoDB ではどのようなタイプのロックを使用しますか 」を参照してください。
- ログファイル
- 受信接続、コマンドの実行、発生した問題などのサーバー イベントが含まれます。詳細については、「ログ メッセージ」を参照してください。
- LVM
- 論理ボリューム マネージャー。LVM は、物理デバイスからディスク イメージを抽象化し、システム マネジメントに便利な raw ディスク操作やスナップショット機能を多数提供するプログラムです。LVM と MongoDB の詳細については、「Linux で LVM を使用したバックアップと復元」を参照してください。
- メンテナンスウィンドウ
MongoDB Atlas がクラスターの週次メンテナンスを開始する日時。プロジェクト設定でメンテナンスウィンドウを設定できます。
重要
メンテナンスウィンドウに関する考慮事項
緊急のメンテナンス アクティビティ セキュリティ パッチのような至急の整備アクティビティは、選択したウィンドウを待つことはできません。MongoDB Atlas は必要に応じてこれらのメンテナンス アクティビティを開始します。
進行中のメンテナンス操作 クラスターのメンテナンスがスケジュールされると、現在のメンテナンス作業が完了するまでメンテナンスウィンドウを変更できません。
メンテナンスにはレプリカ セットの選択が必要MongoDB Atlas は、MongoDBマニュアルに記載されているメンテナンス手順と同じ方法でメンテナンスを実行します。この手順では、レプリカセット選挙ごとに、メンテナンスウィンドウ中に少なくとも 1 回のレプリカセット選挙が必要です。
メンテナンスは可能な限り時刻に近い時間に開始 メンテナンスは常に可能な限り予定時刻に近い時間に開始されますが、進行中のクラスターアップデートや予期しないシステム問題により、開始時間が遅れる可能性があります。
- map-reduce
- データを選択する "map" フェーズと、データを変換する "reduce" フェーズで構成される集計プロセス。MongoDB では、map-reduce を使用してデータに対して任意の集計を実行できます。map-reduce の実装については、「Map-Reduce」を参照してください。集計へのすべてのアプローチについては、「集計操作」を参照してください。
- マッピング型
- プログラミング言語で、キーを値に関連付ける構造体です。キーには、キーと値のペアが埋め込まれている場合があります (辞書、ハッシュ、マップ、連想配列など)。これらの構造体のプロパティは、言語の仕様と実装によって異なります。通常、マッピング型内のキーの順序は任意であり、保証されません。
- md5
- 供給されたデータのチェックサム値を計算するハッシュアルゴリズム。アルゴリズムはデータを識別するためのユニークな値を返します。MongoDB は、GridFS のデータチャンクを識別するために md5 を使用します。filemd5(データベースコマンド)を参照してください。
- 平均
- 数値セットの平均。
- 中央値
- データセットでは、中央値とはデータの 50% がその値以下になるパーセンタイル値です。
- ノード
- 個々のmongodプロセス。 レプリカセットには複数のノードがあります。 ノードは、ノード とも呼ばれます。
- metadata collection
- Queryable Encryption で、暗号化されたフィールドに対するクエリを有効にするために MongoDB が使用する内部コレクションです。「メタデータコレクション」を参照してください。
- MIME
- 多目的インターネットメール拡張機能。複数のデータストレージ、転送、および電子メールのコンテキストでデータのエンコーディングとタイプを宣言するために使用される、タイプとエンコーディングの定義の標準セット。
mongofilesツールには、GridFS ストレージに挿入されたファイルを記述するための MIME タイプを指定するオプションが用意されています。 - モード
- 一連の番号の中で最も頻繁に発生する番号。
- mongo
レガシー MongoDB shell。
mongoプロセスは、レガシー shell をmongodまたは インスタンスのいずれかに接続されたmongosデーモン として起動します。shell には JavaScript インターフェイスがあります。MongoDB v5.0 以降は、
mongoは非推奨となり、クライアント shell としてmongoの代わりに mongosh が使用されます。詳しくは、mongosh を参照してください。- mongod
- MongoDB データベース サーバー。
mongodプロセスは MongoDB サーバーをデーモンとして起動します。 MongoDB サーバーはデータリクエストとバックグラウンド操作を管理します。 詳しくはmongodを参照してください。 - MongoDB Charts
MongoDB Atlasデータの可視化ツール。MongoDB AtlasクラスターからMongoDB Charts を起動し、Chartsアプリケーションでデータを表示して、データの可視化を開始できます。
- MongoDB Search
きめ細かなテキストインデックス作成により、追加の管理なしでデータに対する高度なテキスト検索が可能になります。MongoDB Search は、数種類のテキストアナライザ、スコアベースの結果ランキング、豊富なクエリ言語のオプションを提供します。
- mongos
- MongoDB のシャーディングされたクラスターにおけるクエリルーター。
mongosプロセスは、MongoDB ルーターを デーモン として起動します。MongoDB ルーターは、アプリケーションと MongoDB の シャーディングされたクラスター 間のインターフェースとして機能し、クラスター全体にわたるすべてのルーティングと負荷分散を処理します。mongosインスタンス をご覧ください。 - mongosh
MongoDB Shell。mongosh は、
mongodまたはmongosインスタンスへの shell インターフェイスを提供します。- マルチリージョンクラスター
複数の地理的リージョンにまたがるMongoDB Atlasクラスター。マルチリージョンクラスターは、アプリケーションのクエリを最も適切な地理的リージョンにルーティングすることで可用性を向上させ、パフォーマンスを向上させることができます。
マルチリージョンクラスターには選択可能なノードが含まれている必要があります。
マルチリージョンクラスターには、読み取り専用ノードと分析ノードを含めることができます。
- namespace
- 名前空間は、データベース名ならびにコレクションまたはインデックスの名前を組み合わせたもの(
<database-name>.<collection-or-index-name>)です。すべてのドキュメントは名前空間に属します。「名前空間」を参照してください。 - 名前空間のインサイト
コレクション レベルのクエリ レイテンシを監視する MongoDB Atlas ツール。 特定のホストおよび操作タイプに関するクエリ レイテンシのメトリクスと統計情報を表示できます。 ピン留めされた名前空間を管理し、対応するクエリ レイテンシ チャートに表示する名前空間を最大 5 つ選択できます。
- 自然な順序
順序
recordIdsは作成され、WiredTiger インデックスに保存されます。1 つのインスタンスで実行されるコレクションスキャンのデフォルト ソート順序は、自然な順序です。レプリカセットでは、自然な順序が一貫していることは保証されず、ノードによって異なる場合があります。
シャーディングされたコレクションでは、自然な順序は定義されていません。ただし、
$naturalを使用しても、各シャードにコレクションスキャンが強制的に実行されます。詳細については、ストレージ順序で返却 を参照してください。
- ネットワークパーティション
分散システムをパーティションに分割し、一方のパーティション内のノードが他方のパーティション内のノードと通信できなくなるネットワーク障害を指します。
場合によっては、パーティションが部分的または非対称になることがあります。部分パーティションの例としては、ネットワークのノードを 3 つのセットに分割したものがあり、最初のセットのノードは 2 番目のセットのノードと通信できず、その逆も同様ですが、すべてのノードが 3 番目のセットのノードと通信できます。
非対称パーティションでは、特定のノードから発信された場合にのみ通信が可能になる場合があります。たとえば、パーティションの片側にあるノードは、通信チャンネルを「発信」した場合にのみ、もう一方の側と通信できます。
- ネットワークピアリング接続
2 つのインターネット ネットワークが接続してトラフィックを交換するプロセス。MongoDBクラスター用に作成されたMongoDB Atlas VPCとVPC を直接ピアリングできます。ネットワーク ピアリングを使用すると、アプリケーションサーバーはパブリック ネットワークから分離されたままMongoDB Atlasに直接接続できます。
- node
- 個々のmongodプロセス。 レプリカセットには複数のノードがあります。 ノードは、ノードとも呼ばれます。
- noop
- No Operation(noop)は、先入れ先出しキューに基づいて着信プロセスの I/O 帯域幅を割り当てる I/O 操作スケジューラです。
- 正規化された string
- string の Unicode 正規化形式 は、Unicode コード ポイントを標準化された方法で適用します。2 つの文字列はユーザーには同一に見えますが、マークの結合順序などに違いがあります。string を正規化すると、バイナリ表現が同じになります。
- NVMe
- NVMe(Non- Volume Memory Express )は、高速ストレージ メディアにアクセスするためのプロトコルです。
- NVMeストレージ
Amazon Web Servicesでホストされている M40 以上のクラスターで利用可能
低レイテンシと高スループットの IO を必要とするAmazon Web Servicesでホストされるアプリケーションには、 NVMeクラスタークラスを使用できます。 NVMe クラスタークラスは、独自のデータプロトコルを活用して、データアクセス速度を大幅に向上させます。
NVMe クラスターは、バックアップを容易にするために、高スループットと IOPS を備えたプロビジョニングされたボリュームで構成される 非表示のセカンダリー ノード を使用します。
- ObjectId(オブジェクト識別子)
- ObjectId を参照してください。
- ObjectId
- コレクション 12内で一意である バイトの BSON 型。ObjectId は、タイムスタンプ、コンピューター ID、プロセス ID、ローカルプロセスの増分カウンターを使用して生成されます。 MongoDB は、 _idフィールドのデフォルト値として ObjectId 値を使用します。
- 操作ログ
- 詳しくは、 oplog を参照してください。
- 操作メタデータ
- 挿入、アップデート、削除操作の回数や時間など、プロセスの内容ではなくプロセスの実行に関する情報。
- 操作拒否フィルター
- 拒否されたクエリシェイプ。詳細については、「操作拒否フィルターでスロークエリをブロックする」を参照してください。
- optime
- 詳しくは、 optime を参照してください。
- 運用ノード
- MongoDB Atlasクラスター内の選挙可能な ノードまたは読み取り専用ノード。
- 演算子
$クエリ述語、式、集計ステージなどのMQLコンポーネントをExpressために使用される で始まるキーワードです。例、$gtはMQL "greater than(より大きい)" 演算子です。使用可能な演算子については、MongoDBクエリ言語リファレンスを参照してください。- oplog
- MongoDB database への論理書込みの順序付き履歴を保存するCapped コレクション。 oplog は、MongoDB のレプリケーションを有効にする基本的なメカニズムです。 レプリカセットoplogを参照してください。
- oplog バッファ コレクション
再シャーディング操作中に作成される一時的なコレクションで、ドナーシャードからの oplog エントリを保存します。
oplog バッファーコレクションは、ドナーシャードから削除された場合でも、受信者シャードが oplog エントリーにアクセスできるようにします。oplog バッファー コレクションは、再シャーディングが完了したときに削除されます。
- oplog hole
- oplog の書込み (write) が順序どおりでないため、oplog に生じた一時的なギャップです。レプリカセットのプライマリは、oplog エントリをバッチ操作として並行して適用します。その結果、バッチからまだ書込まれていないエントリによって、oplog に一時的なギャップが発生する可能性があります。
- oplog window
- oplog エントリにはタイムスタンプが付けられます。oplog window は、
oplog内の最新のタイムスタンプと最も古いタイムスタンプの間の時間差です。セカンダリ ノードとプライマリ ノードの接続が切れた場合、oplog window 内で接続が復元された場合のみ、レプリケーションを使用して再度同期できます。 - optime
レプリケーション oplog 内の位置への参照。optime 値は、次の内容を含むドキュメントです。
- 順序クエリプラン
sort()の順序と一致する順序で結果を返すクエリプランです。「クエリプラン」を参照してください。- 組織
MongoDB Atlasプロジェクトの論理的なグループ化。組織を活用して、その組織に含まれるプロジェクトの請求、ユーザー、セキュリティ設定を管理できます。
請求は組織レベルで行われますが、各プロジェクトの使用量は可視性が維持されます。
組織内のすべてのプロジェクトを表示できます。
チームを使用して、組織ユーザーを組織内のプロジェクトに一括に割り当てることができます。
Tip
- 組織ID
- MongoDB Atlas組織を識別するために使用される一意の 24 桁の16進数文字列。「すべての組織を返す」エンドポイントは、API呼び出しを実行する認証済みユーザーがアクセスできるすべての組織のIDを返します。
- 孤立したカーソル
- アプリケーション コード内で正しく閉じられていない、または反復処理されていないカーソルです。孤立したカーソルは、MongoDB 配置でパフォーマンスの問題を引き起こす可能性があります。
- 孤立したドキュメント
シャーディングされたクラスター内の孤立したドキュメントとは、シャード上のドキュメントの中でも他のシャードにもチャンク状に存在しているドキュメントを指します。これは、移行の失敗、または異常なシャットダウンが原因で移行のクリーンアップが不完全になったことが原因です。
チャンクの移行が完了すると、孤立したドキュメントは自動的にクリーンアップされます。孤立したドキュメントを削除するために
cleanupOrphanedを実行する必要はなくなりました。- パッシブノード
members[n].priorityが0であるため、プライマリになることができない レプリカセット のメンバー。「優先順位0レプリカセット ノード 」を参照してください。- per-CPU cache
- 特定の CPU コアのメモリをローカルに保存するキャッシュの一種。CPU ごとのキャッシュは、MongoDB 8.0 で導入された TCMalloc の新しいバージョンで使用されます。
- スレッドごとのキャッシュ
- アプリケーションのスレッドごとに、ローカルにメモリーを保存するキャッシュの一種。スレッドごとのキャッシュは、MongoDB 7.0 以前で使用されているレガシーバージョンの TCMalloc で使用されます。
- パーセンタイル
- データセットでは、パーセンタイルとは、データのパーセンテージが指定された値以下の値を指します。詳細については、「計算に関する考慮事項」を参照してください。
- Performance Advisor
MongoDB Atlas は、クラスターで実行される低速クエリを監視し、クエリのパフォーマンスを向上させるためのインデックスを提案するツールです。Performance Advisor が提案する各インデックスには、そのインデックスによって得られる潜在的なパフォーマンス向上を示す影響スコア が含まれます。
- PID
- プロセス識別子。UNIX のようなシステムでは、実行中の各プロセスにユニークな整数 PID が割り当てられます。PID を使用して実行中のプロセスを検査し、そのプロセスにシグナルを送信できます。「
/procファイル システム」を参照してください。 - パイプ
- UNIX のようなシステムにおける通信チャンネルです。独立したプロセスがデータを送受信できるようにします。UNIX shell では、パイプ操作によって、あるコマンドの出力を別のコマンドの入力に向けることができます。
- パイプライン
- 集計における一連の操作。詳しくは、集計パイプラインを参照してください。
- プランキャッシュクエリシェイプ
クエリ述語、ソート、プロジェクション、および照合の組み合わせ。プランキャッシュクエリシェイプにより、MongoDB は等価のクエリを識別し、そのパフォーマンスを分析できます。
クエリ述語については、述語構造とフィールド名のみが使用されます。クエリ述語の値は使用されません。例えば、クエリ述語
{ type: 'food' }は{ type: 'drink' }と等価です。プランキャッシュクエリシェイプが同じスロークエリを識別するために、各プランキャッシュクエリシェイプには16進数の
planCacheShapeHash値が付いています。詳細については、「planCacheShapeHash と planCacheKey」を参照してください。MongoDB 8.0 以降では、既存の
queryHashフィールドはplanCacheShapeHashという名前の新しいフィールドに重複します。 以前のバージョンのMongoDBを使用している場合は、queryHashフィールドのみが表示されます。 今後のMongoDBバージョンでは、非推奨のqueryHashフィールドが排除されます。代わりにplanCacheShapeHashフィールドを使用する必要があります。- 点
- GeoJSON ポイント仕様で説明されている単一の座標ペア: https://tools.ietf.org/html/rfc7946#section-3.1.2。MongoDBで点を使用するには、GeoJSON オブジェクトを参照してください。
- 多角形
LinearRing 座標配列の配列(https://tools.ietf.org/html/rfc7946#section-3.1.6)。複数の円がある多角形の場合、最初は外側の円で、他の円は内側の円または穴である必要があります。
MongoDB では、外側の円は自己交差することはできません。内側の円は外側のループの中に完全に収まっていなければならず、互いに交差したり重なったりすることはできません。「GeoJSON オブジェクト」を参照してください。
- イメージ後ドキュメント
- 挿入、置換、またはアップデートされた後のドキュメントを指します。「イメージ前ドキュメントとイメージ後ドキュメントによる変更ストリーム」を参照してください。
- powerOf2Sizes
- 各ドキュメントにスペースを割り当てて、ストレージの再利用を最大化し、断片化を減らすコレクションごとの設定。
powerOf2Sizesは TTL コレクションのデフォルトです。コレクション設定を変更するには、collModを参照してください。 - イメージ前ドキュメント
- 置換、アップデート、または削除される前のドキュメントを指します。「イメージ前ドキュメントとイメージ後ドキュメントによる変更ストリーム」を参照してください。
- 事前分割
- データを挿入する前に実行される操作で、シャードキー値の範囲をチャンクに分割して、簡単な挿入と高い書込みスループットを容易にします。 事前分割により、MongoDB バランサー が分割するのを待つのではなく、コレクションを手動で分割することで、シャーディングされた クラスター内 のドキュメントの初期分散が迅速化する場合があります。「シャーディングされたクラスターで範囲を作成する 」を参照してください。
- 接頭辞圧縮
- 同一のインデックス キー プレフィックスをメモリ 1 ページにつき 1 回だけストアすることで、メモリとディスクの消費量を削減します。WiredTiger の圧縮動作の詳細については、「圧縮」を参照してください。
- プライマリ
- レプリカセットでは、 プライマリ はすべての書込み (write) 操作を受け付けるメンバーです。 詳しくは、 プライマリ を参照してください。
- プライマリキー
- レコードの一意の不変識別子。 RDBMSソフトウェアでは、プライマリキーは通常、各行の
idフィールドに保存される整数です。 MongoDB では、 _idフィールドにはドキュメントのプライマリキー(通常は BSON ObjectId )が保存されます。 - プライマリシャード
- シャーディングされたクラスター内の各データベースにはプライマリシャードがあります。これは、データベース内のすべてのシャーディングされていないコレクションに対するデフォルトのシャードです。詳しくは、「プライマリシャード」を参照してください。
- 優先順位
- レプリカセット内のどのノードがプライマリになる可能性が最も高いかを判断するのに役立つ構成可能な値。 詳しくは
members[n].priorityを参照してください。 - 特権
- 指定されたリソースと、そのリソースに対して許可されるアクションの組み合わせ。 「特権」を参照してください。
- プロジェクト
クラスターの論理グループ 。 1 つのプロジェクト内に複数のクラスターと、1 つの組織内に複数のプロジェクトを設定できます。
注意
プロジェクトはグループと同義です。
- プロジェクトID
MongoDB Atlasプロジェクトを識別するために使用される一意の 24 桁の16進数文字列。「すべてのプロジェクトを取得」 APIエンドポイントは、 「 API呼び出しを実行する認証済みユーザーがアクセスできるすべてのプロジェクトのIDを返します。
注意
プロジェクト ID はグループ ID と同義です。
- プロジェクション
- MongoDB が結果セットで返すフィールドを指定するクエリに提供されるドキュメント。プロジェクションの詳細については、クエリから返されるプロジェクト フィールド を参照してください。
- 量子化
- ベクトル内の個々の次元の値をより小さな範囲に圧縮してリソース消費を減らし、速度を向上させる方法。ベクトル検索 は、量子化されたベクトルのインデックス作成とクエリをサポートします。
- クエリ
- 読み取りリクエスト 。 MongoDB は、名前が 文字で始まる クエリ演算子 を含む JSON
$形式のクエリ言語を使用します。mongoshでは、db.collection.find()} メソッドとdb.collection.findOne()メソッドを使用してクエリを実行できます。 「クエリ ドキュメント 」を参照してください。 - クエリフレームワーク
- 操作を処理するクエリオプティマイザと クエリ実行エンジン の組み合わせです。
- クエリ演算子
- クエリ内の
$で始まるキーワードです。たとえば、$gtは " "greater than(より大きい)" 演算子です。クエリ演算子のリストについては、クエリ演算子を参照してください。 - クエリオプティマイザ
- クエリプランを生成するプロセス。オプティマイザは、クエリごとに、結果をできるだけ効率的に返すインデックスとクエリを照合するプランを生成します。クエリを実行するたびにオプティマイザはクエリプランを再利用します。コレクションが大幅に変更された場合、オプティマイザは新しいクエリプランを作成します。「クエリプラン」を参照してください。
- クエリプラン
- クエリ プランナーによって選択された最も効率的な実行プランです。詳細については、「クエリプラン」を参照してください。
- クエリ述語
ドキュメントが指定されたクエリに一致するかどうかを示すブール値を返す式。 たとえば、
{ name: { $eq: "Alice" } }は、値が string"Alice"である フィールド"name"を持つドキュメントを返します。クエリ述語には、より複雑な一致のために子式と演算子を含めることができます。使用可能なクエリ演算子を確認するには、クエリ述語を参照してください。
- Query Profiler
- MongoDB Atlas クラスター内のパフォーマンスの問題を診断およびモニターするMongoDB Atlasツール。クエリプロファイラーは、実行時間が長いクエリとそのパフォーマンス統計を表示できます。 クエリプロファイラーによって返されたデータをフィルタリングして、特定の名前空間と操作タイプに絞り込むことができます。
- クエリシェイプ
- クエリシェイプは、類似したクエリをグループ化する一連の仕様です。詳細については、クエリシェイプを参照してください。
- 範囲
- チャンク内のシャードキー値の連続した範囲。 データ範囲には、下限が含まれ、上限が除外されます。 MongoDB では、シャードに含まれるコレクションのデータが他のシャードに比べて多すぎる場合にデータを移行します。 「チャンクとシャーディングされたクラスター バランサーを使用したデータのパーティショニング 」を参照してください。
- RDBMS
- リレーショナルデータベース管理システム。 リレーショナル モデルに基づくデータベース マネジメント システムで、クエリ言語としてSQLを通常使用します。
- 読み取り保証 (read concern)
- 読み取り操作の分離レベルを指定します。 たとえば、読み取り保証 を使用すると、レプリカセット内の大多数のノードに反映されたデータのみを読み取ることができます。 詳しくは、 読み取り保証(read concern) を参照してください。
- 読み取りロック(read lock)
- コレクションやデータベースなどのリソースに対する共有 ロックにおいて、保持されている間は同時読み取りが許可されますが、書込みは許可されません。詳しくは、MongoDB ではどのようなタイプのロックを使用しますか。を参照してください。
- 読み込み設定 (read preference)
- クライアントが読み取り操作を指示する方法を決定する設定。 読み込み設定(read preference)は、シャード レプリカセットを含むすべてのレプリカセットに影響します。 デフォルトでは、MongoDB はプライマリへの読み取りを指示します。 ただし、結果整合性のある読み取りのために、セカンダリに読み取りを指示することもできます。 読み込み設定(read preference) を参照してください。
- 読み取り専用ノード
- 選択可能なノードリージョンを補完する専用の地理的リージョン内のレプリカセット。 読み取り専用ノードを使用して、最も頻繁に読み取られるデータをローカル化してパフォーマンスを向上させることができます。
- リアルタイムのパフォーマンスパネル
MongoDB Atlas は、現在のネットワーク トラフィック、クラスター上のデータベース操作、およびホスト マシンに関するハードウェア統計を表示するモニタリング サービスです。リアルタイム パフォーマンス パネル を使用して、クエリの実行時間を視覚的に評価し、ネットワーク アクティビティを監視して、レプリカセットの セカンダリ ノードでの潜在的なレプリケーションラグを検出します。
- 呼び出す
- ANN 検索によって返された true の最近傍 の割合を測定します。この測定値は、アルゴリズムがENN 検索の結果にどの程度近似しているかを反映しています。Reball@k という表記は、ベクトル検索によって返された上位 k の結果に存在する最近傍の数を示す測定値を指します。
- リカバリ中
- レプリカセットノードのステータスは、ノードがセカンダリまたはプライマリのアクティビティを開始する準備ができていないことを示します。 リカバリ ノードは読み取りに使用できません。
- 相対的なシステム CPU 使用率
クラウドインスタンスに割り当てられたベースライン CPU の量に対する CPU 使用率。絶対的なシステム CPU 使用率をクラウドインスタンスに割り当てられたベースライン CPU の量で割ることで、相対的なシステム CPU 使用率を計算できます。
MongoDB は相対的なシステム CPU 使用率を 100% に制限します。クラウドプロバイダーがクラウドインスタンスの CPU 使用率を制限するか、そのインスタンスで使用可能な CPU のベースライン量を超えて CPU 使用率をバーストする場合、相対的なシステム CPU 値は100% となります。
- レプリカセット
- 同じデータセットを維持する MongoDB サーバーのグループ。 レプリカセットは冗長性、高可用性を提供し、すべての配置環境の基盤となります。
- レプリケーション
- 複数のデータベース サーバーが同じデータを共有できるようにする機能。レプリケーションにより、データの冗長性が確保され、負荷分散が可能になります。「レプリケーション」を参照してください。
- レプリケーションラグ
- プライマリ のoplog内の最後の操作と特定のセカンダリに適用された最後の操作までの時間間隔。 通常、レプリケーションラグはできるだけ短くする必要があります。 「レプリケーションラグ 」を参照してください。
- 常駐メモリ
- 現在物理 RAM に保存されているアプリケーションのメモリのサブセット。 常駐メモリは、物理 RAM とストレージにマップされたメモリを含む仮想メモリのサブセットです。
- resource
- データベース、コレクション、コレクションのセット、またはクラスター。 特権は、指定されたリソースに対する アクションを許可します。 リソース を参照してください。
- ロール
- 指定された リソース に対する アクション を許可する特権のセットです。ユーザーに割り当てられたロールによって、ユーザーのリソースと操作へのアクセス権が決まります。 「セキュリティ 」を参照してください。
- rollback
- すべてのレプリカセットの一貫性を確保するために書き込み操作を元に戻すプロセス。「レプリカセットフェイルオーバー中のロールバック」を参照してください。
- ローリング再起動
- クラスター内のすべてのノードを順番に再起動する プロセス。クラスターの可用性を維持するために、 MongoDB Atlas はセカンダリノードから始めて、一度に 1 つのノードを再起動します。MongoDB Atlas は、ローリング再起動が完了するまで、常に プライマリノードを維持します。
- スカラー量化
- スカラー量化では、各次元のセグメント内のすべてのインデックス付きベクトルから最小値と最大値を選択し、それらの間で等しいサイズのビン化を生成します。これらの各次元をビン化すると、新しい量子化された値が生じます。ベクトル検索 は、float32 ベクトルの自動スカラー量子化と、埋め込みプロバイダーからのスカラー量子化ベクトルの取り込みとインデックス作成をサポートしています。
- セカンダリ
- マスター データベースのコンテンツを複製するレプリカセット メンバー。セカンダリ メンバーは読み取りのリクエストを実行できます。しかし、書き込み操作を実行できるのはプライマリ メンバーのみです。詳しくは、セカンダリを参照してください。
- セカンダリインデックス
- クエリエンジン がクエリを実行するために実行する必要がある作業量を最小限に抑えることで、クエリのパフォーマンスを向上させるデータベースインデックス。 「インデックス 」を参照してください。
- セカンダリ ノード
- セカンダリを参照してください。 セカンダリ ノードとも呼ばれます。
- シードリスト
- シードリストは、レプリカセット構成の初期検出のためにドライバーとクライアント(
mongoshなど)によって使用されます。シードリストは、host:portペアのリストとして提供できます(標準接続文字列 形式または DNS エントリを参照)。詳細については、SRV 接続形式を参照してください。 - 自己管理型
- 外部マネジメントやサードパーティ サービス(MongoDB Atlas など)ではなく、個人または組織によって設定および維持される MongoDB インスタンス。
- セマンティック検索
- クエリと同様の意味を持つ値を検索します。セマンティック検索では、語彙の重複がない場合でも、単語やフレーズ間の自然な関係がキャプチャされます。セマンティック検索とベクトル検索は、多くの場合、どちらもどちらも使用されます。ベクトル検索は、 MongoDB Atlasクラスターに保存されているベクトルデータのセマンティック検索をサポートしています。
- セット名
- レプリカセットに付けられた任意の名前です。レプリカセットのすべてのノードは、
replSetName設定または--replSetオプションで指定された名前と同じ名前を持つ必要があります。 - シャード
- シャーディングされた クラスターの
mongod全データセットの一部を保存する単一の インスタンスまたは レプリカ セット。通常、本番環境の配置では、すべてのシャードがレプリカセットの一部であることを確認します。 「シャード 」を参照してください。 - シャードキー
- MongoDB が シャーディングされたクラスターのメンバー間でドキュメントを分散するために使用するフィールド。 詳細については、「シャードキー 」を参照してください。
- シャーディングされたクラスター
- シャーディングされた MongoDB 配置を構成するノードのセット。シャーディングされたクラスターは、コンフィギュレーションサーバー、シャード、および 1 つ以上の
mongosルーティング プロセスで構成されます。詳細については、シャーディングされたクラスター コンポーネントを参照してください。 - シャーディング
- キー範囲によってデータをパーティション化し、2 つ以上のデータベース インスタンスにデータを分散するデータベース アーキテクチャです。シャーディングにより水平方向のスケーリングが可能になります。「シャーディング」を参照してください。
- シェルヘルパー
- データベースコマンドの簡潔な構文を持つ
mongosh内のメソッドです。シェルヘルパーは、対話型エクスペリエンスを向上させます。「mongoshメソッド」を参照してください。 - 類似関数
- 2 つのベクトル間の類似性を測定します。ベクトル検索は、
euclidean、cosine、dotProduct類似度関数をサポートしています。 - 単マスターレプリケーション
- 1 つのデータベースインスタンスのみが書込み (write) を受け入れるレプリケーショントポロジー。 単一マスター レプリケーションは整合性を確保し、MongoDB で使用されるレプリケーション トポロジーです。 詳しくは、 レプリカセット プライマリ を参照してください。
- Snappy
- 効率的な計算要件と適切な圧縮率のバランスを取るための圧縮/解凍ライブラリ。Snappy は、MongoDB のWiredTiger使用用のデフォルトの圧縮ライブラリです。詳細については、「 Snappy とWiredTiger の圧縮ドキュメント 」を参照してください。
- スナップショット
- スナップショットは、その時点における
mongodインスタンスのデータのコピーです。クラスターまたはレプリカセット全体、またはクラスター内の単一のコンフィギュレーションサーバーのスナップショット メタデータを取得できます。 - ソフトIRQ
- クラウドインスタンスがソフトウェア割り込みリクエストを処理するために現在使用している CPU の一部を反映する CPU 使用率メトリクスです。一部のクラウドプロバイダーでは、このメトリクスはバースト可能なインスタンスの CPU 使用率を追跡するのに役立ちます。
- ソートキー
- フィールドをソートするときに比較される値。 MongoDB が数値以外のフィールドのソートキーを決定する方法については、「比較/ソート順序 」を参照してください。
- 分裂
- シャードされた クラスター 内 の チャンク の分割。「チャンクを使用したデータのパーティショニング 」を参照してください。
- SQL
- 構造化クエリ言語(SQL)は、関係データベースとのやりとりに使用されます。
- SSD
- Solid State Disk(ソリッド ステート ディスク)。機械式ハード ドライブで使用される回転プラッターと可動式の読み取り/書込みヘッドの代わりに、ソリッド ステート エレクトロニクスを使用して永続性を実現する高性能ストレージです。
- ステイル読込み
- ステイル読み取りとは、別のトランザクションによって変更されたがまだデータベースにコミットされていない古い(古い)データをトランザクションが読み取った場合を指します。
- スタンドアロン
レプリカセットの一部としてではなく、単一のサーバーとして実行する
mongodのインスタンスです。スタンドアロン インスタンスをレプリカセットに変換するには、「スタンドアロンの自己管理型mongodをレプリカセットに変換する」を参照してください。注意
スタンドアロンインスタンスは、ノードが1つのみのレプリカセットではありません。
- 溜め込みコレクション
再シャーディング操作中に、各ドナーシャードのために受信者シャードに作成される一時的なコレクションです。
操作の競合によりすぐに挿入できないドキュメントを一時的に保持する溜め込みコレクションです。たとえば、ドキュメントのシャードキーが更新されると、そのドキュメントは別のシャードに属することになり、そのドキュメントに適用される操作の順序が曖昧になる可能性があります。受信者は、正しい順序で操作を適用できるようになるまで、これらのドキュメントを溜め込みコレクションに保管します。
- 降格
レプリカセットの プライマリ ノードメンバーは、自身をプライマリ メンバーとして除去し、セカンダリ メンバーになります。
レプリカセットがプライマリとのコンタクトを失った場合、セカンダリは新しいプライマリを選出します。古いプライマリが選挙を知ると、そのプライマリは退いて、セカンダリとしてレプリカセットに再び参加します。
ユーザーが
replSetStepDownコマンドを実行すると、プライマリは降格し、レプリカセットに新しいプライマリが強制的に選択されます。
- storage engine
- メモリとディスクの両方で、データの保存方法とアクセス方法を管理するデータベースの部分です。 異なるストレージ エンジンは、特定のワークロードに対してより優れた性能を発揮します。 MongoDB に組み込まれているストレージ エンジンの詳細については、「自己管理型配置のストレージ エンジン」を参照してください。
- ストレージ順序
- 「自然な順序 」を参照してください。
- 厳密な一貫性
- すべてのノードがシステムの最新の変更で構成されていることを要求する分散システムのプロパティです。データベース システムでは、データを提供できるすべてのシステムが必ず最新の書込み (write) で構成されている必要があることを意味します。
- サブジェクト代替名
- サブジェクト代替名(SAN)は、X.509 証明書の拡張機能であり、IP アドレスやドメイン名など、1つのセキュリティ証明書が保護することのできるリソースを指定する値の配列を許可します。
- 同期
- ノードが プライマリからデータを複製するレプリカセット操作。MongoDB によるノードの作成時または復元時に初めて同期が行われます。これを最初の同期と呼びます。その後、レプリカセットのデータ変更が常にノードに反映されるよう、継続的に動機が行われます。詳しくは、レプリカセット データ同期を参照してください。
- syslog
- Unix 系のシステムで、サーバーとプロセスがロギング情報を送信するための統一された標準を提供するロギングプロセスです。MongoDB には、出力をホストの syslog システムに送信するオプションが用意されています。
syslogFacilityを参照してください。 - tag
レプリカセットに適用され、クライアントがデータセンター対応操作を実行するために使用するラベルです。レプリカセットでタグを使用する方法の詳細については、「読み込み設定 (read preference) タグセット」を参照してください。
- tag set
- 0 個以上のタグを含むドキュメント
- 追尾可能 (tailable) カーソル
- 上限付きコレクションの場合、追尾可能 (tailable) カーソルは、クライアントが初期カーソルの結果を使い果たした後も開いたままになるカーソルです。クライアントが上限付きコレクションに新しいドキュメントを挿入しても、追尾可能 (tailable) カーソルはドキュメントの検索を続行します。
- チーム
- 同じ組織内のAtlas ユーザーのグループ。 チームを使用して、複数のプロジェクトにわたって同じ Atlas ユーザーのグループにアクセス権を付与できます。 チーム内の全ユーザーが同じプロジェクトへのアクセスを共有します。
- ターム
- レプリカセットのノードの場合、選挙試行に対応する単調に増加する数を指します。
- 時系列コレクション
- 一定期間にわたる測定値のシーケンスを効率的に保存するコレクション。 「時系列 」を参照してください。
- トポロジー
MongoDB インスタンスの配置の状態を指します。次のことが含まれます。
配置のタイプ(スタンドアロン、レプリカセット、またはシャーディングされたクラスター)。
サーバーの可用性。
各サーバーの役割(プライマリ、セカンダリ、コンフィギュレーションサーバー、または
mongos)。
- トランザクション
- 読み取り操作または書込み (write) 操作のグループです。詳細については、「トランザクション」を参照してください。
- トランザクションの調整役
- レプリカセット または シャーディングされた クラスター で トランザクション を管理する MongoDB のコンポーネントです。ノード間のマルチドキュメントトランザクションの実行と完了を調整し、複雑な操作をアトミック操作として取り扱うことができます。
- TSV
- タブ区切りの値で構成されるテキストベースのデータ形式。一般的に、この形式は表形式のデータに適しているため、関係データベース間のデータ交換に使用されます。
mongoimportを使用して TSV ファイルをインポートできます。 - TTL
- Time-to-Live(TTL)とは、システムが情報を削除または期限切れにする前に、特定の情報がキャッシュまたはその他の一時ストレージに保持される有効期限または期間です。MongoDB には TTL コレクション機能があります。「TTL を設定してコレクションのデータを期限切れにする」を参照してください。
- 無制限配列
- 時間の経過と共に一貫して大きくなる配列。ドキュメント フィールド値が無制限配列の場合、その配列はパフォーマンスに悪影響を及ぼす可能性があります。一般に、無制限配列を使わずにスキーマを設計します。
- 一意なインデックス
- 単一のコレクション内の特定のフィールドの一意性を強制するインデックス。「一意なインデックス」を参照してください。
- unix epoch
- 1970 年 1 月 1 日 00:00:00 UTC を指します。一般的には時間を表すときに使用され、この時点からの秒数またはミリ秒数がカウントされます。
- 順序なしクエリプラン
sort()の順序と一致しない順序で結果を返すクエリプランです。「クエリプラン」を参照してください。- アップグレード
- MongoDBの1つのバージョンからそれ以降のバージョンにクラスターを変更するプロセス。
- upsert
更新操作のオプション。たとえば
db.collection.updateOne()、db.collection.findAndModify()が挙げられます。アップサートがtrueの場合、更新操作は次のいずれかになります。クエリに一致するドキュメントを更新します。
一致するドキュメントがない場合は、新しいドキュメントを挿入します。新しいドキュメントには、アップデート操作で指定されたフィールド値が含まれます。
アップサートの詳細については、「一致するものが存在しない場合は新しいドキュメントを挿入する(
Upsert)」を参照してください。- ベクトルデータベース
- ベクトル埋め込みと関連するメタデータを保存し、保存されたベクトル埋め込みに対して最近傍検索を有効にするシステムです。MongoDB Atlas をベクトルデータベースとして使用し、 ベクトル検索を使用して保存されたベクトル埋め込みでベクトル検索を実行できます。ベクトルデータベースを使用して RG を実装できます。
- ベクトル インデックス
- 最近傍検索クエリを効率的に処理するデータ構造。ベクトル検索 は、
$vectorSearchクエリを実行中のフィールドにインデックスための タイプvectorのインデックスの作成をサポートしています。 - ベクトル検索
- クエリ ベクトルとインデックス付きベクトルを比較し、最も近い一致を見つけることで、ベクトル埋め込みのセマンティック検索を実行できる機能。
- vectorSearch
- ベクトルインデックスに保存されているベクトルのセットに対して k 近傍検索を実行する方法。ベクトル検索は、 k 近傍の Ann および ENN 検索をサポートします。
- 仮想記憶
- アプリケーションの作業メモリを指し、通常はディスクと物理 RAM の両方に存在します。
- ウォール クロック タイム
- コンピューター プログラムまたは計算の開始から完了までの間に経過する時間です。
- WGS84
- MongoDB がGeoJSON オブジェクトに対する地理空間クエリ用に地球のような球体上のジオメトリを計算するために使用するデフォルトの参照システムと地理的データ。「EPSG:4326: WGS 84」仕様(http://spatialreference.org/ref/epsg/4326/)を参照してください。
- ウィンドウ演算子
- コレクションからドキュメントの範囲から値を返します。「ウィンドウ演算子」を参照してください。
- ワーキングセット
- MongoDB が最も頻繁に使用するデータです。
- 書込み保証 (write concern)
- 書き込み操作が成功したかどうかを指定します。書込み保証(write concern)により、アプリケーションは挿入エラーや使用できない
mongodインスタンスを検出できます。レプリカセットの場合、指定した数のノードへのレプリケーションを確認するように書込み保証(write concern)を構成できます。詳しくは、書込み保証(write concern)を参照してください。 - 書込み競合 (write conflict)
- 少なくとも 1 つが書込み(write)である 2 つの同時操作において、楽観的な同時実行制御を使用するストレージ エンジンの制約に違反するリソースを使用しようとする状況。MongoDB は競合する書込み操作の 1 つを自動的に終了し、再試行します。
- 書込みロック (write lock)
- コレクションやデータベースなどのリソースに対する排他ロック。 プロセスがリソースに書込むとき、他のプロセスがそのリソースに書込んだり、リソースを読み込んだりするのを防ぐために、排他的書込みロック (write lock) が必要です。 ロックの詳細については、「 FAQ: 同時実行性 」を参照してください。
- zlib
- MongoDB が snappy を使用するのと比較して、より多くの CPU をコストにして、より高い圧縮率を提供するデータ圧縮ライブラリ。WiredTiger を圧縮ライブラリとして zlib を使用するように構成できます。詳細については、 http://www.zlib.net およびWiredTiger圧縮ドキュメントを参照してください。
- ゾーン
- 特定のシャーディングされたコレクションのシャードキー値の範囲に基づいて、ドキュメントをグループ化します。 シャーディングされたクラスター内の各シャードは、1 つ以上のゾーンに含めることができます。 バランシングされたクラスターでは、MongoDB はゾーンの読み取りと書込みを、そのゾーン内のシャードにのみ指示します。 詳細については、ゾーンのマニュアル ページを参照してください。
- zstd
- zlib と比較して、より高い圧縮率とより低い CPU 使用率を提供するデータ圧縮ライブラリ。