定義
$densifyバージョン 5.1 で追加。
フィールド内の特定の値が欠落しているドキュメントのシーケンス内に新しいドキュメントを作成します。
$densifyは以下の目的で使用できます。時系列データのギャップを埋めます。
データのグループ間に欠落値を追加します。
指定した範囲の値をデータに入力します。
構文
$densifyステージの構文は次のとおりです。
{ $densify: { field: <fieldName>, partitionByFields: [ <field 1>, <field 2> ... <field n> ], range: { step: <number>, unit: <time unit>, bounds: < "full" || "partition" > || [ < lower bound >, < upper bound > ] } } }
$densifyステージは次のフィールドを持つドキュメントを取得します。
フィールド | 必要性 | 説明 |
|---|---|---|
必須 | 高密度化するフィールド。 指定された 指定された
制限については、「 | |
任意 | ドキュメントをグループ化するための複合キーとして機能するフィールドのセット。 このフィールドを省略すると、 はコレクション全体に対して 1 例については、パーティションによる圧縮を参照してください。 制限については、「 | |
必須 | データの圧縮方法を指定するオブジェクト。 | |
必須 |
| |
必須 | 各ドキュメントのフィールド値の増加量。 range.unit が指定されている場合、 | |
フィールドの日付値を増加させるときにステップフィールドに適用する単位。
の例については、「 時系列データの圧縮 」を参照してください。 |
行動と限界
field 制限事項
指定されたフィールドを含むドキュメントで、次の場合、 $densifyはエラーを返します。
コレクション内のどのドキュメントにも、
fieldの値は date 型で、単位フィールドは指定されていません。コレクション内のすべてのドキュメントには、数値型の
field値と単位フィールドが指定されています。fieldの名前は$で始まります。 フィールドを高密度にする場合は、フィールドの名前を変更する必要があります。 フィールド名を変更するには、$projectを使用します。
partitionByFields 制限事項
$densifypartitionByFields 配列内のいずれかのフィールド名がある場合は、 エラーが発生します。
非 string 値として評価されます。
$から始まります。
range.bounds 動作
range.Boundsが配列の場合:
出力の順序
$densify は、出力するドキュメントのソート順序を保証しません。
並べ替え順序を保証するには、並べ替えるフィールドで$sortを使用します。
例
時系列データの圧縮
4 時間以上の温度の読み取りを含むweatherコレクションを作成します。
db.weather.insertMany( [ { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T00:00:00.000Z"), "temp": 12 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T04:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T08:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T12:00:00.000Z"), "temp": 12 } ] )
この例では、 $densifyステージを使用して 4 時間間隔のギャップを埋め、データ ポイントの 1 時間ごとの粒度を実現します。
db.weather.aggregate( [ { $densify: { field: "timestamp", range: { step: 1, unit: "hour", bounds:[ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ] } } } ] )
この例では、次のことが行われます。
$densifyステージは、記録された温度間の時間差を埋めます。field: "timestamp"はtimestampフィールドを生成します。
range:step: 1は、timestampフィールドを 1 単位増加させます。unit: hourは、timestampフィールドを時間単位で生成します。bounds: [ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ]は、圧縮される時間の範囲を設定します。
次の出力では、 $densifyステージは00:00:00と08:00:00の時間の間の時間差を埋めます。
[ { _id: ObjectId("618c207c63056cfad0ca4309"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T00:00:00.000Z"), temp: 12 }, { timestamp: ISODate("2021-05-18T01:00:00.000Z") }, { timestamp: ISODate("2021-05-18T02:00:00.000Z") }, { timestamp: ISODate("2021-05-18T03:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430a"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T04:00:00.000Z"), temp: 11 }, { timestamp: ISODate("2021-05-18T05:00:00.000Z") }, { timestamp: ISODate("2021-05-18T06:00:00.000Z") }, { timestamp: ISODate("2021-05-18T07:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430b"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T08:00:00.000Z"), temp: 11 } { _id: ObjectId("618c207c63056cfad0ca430c"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T12:00:00.000Z"), temp: 12 } ]
パーティションによる圧縮
2 種類のコードのデータを含むcoffeeコレクションを作成します。
db.coffee.insertMany( [ { "altitude": 600, "variety": "Arabica Typica", "score": 68.3 }, { "altitude": 750, "variety": "Arabica Typica", "score": 69.5 }, { "altitude": 950, "variety": "Arabica Typica", "score": 70.5 }, { "altitude": 1250, "variety": "Gesha", "score": 88.15 }, { "altitude": 1700, "variety": "Gesha", "score": 95.5, "price": 1029 } ] )
値の全範囲を圧縮
この例では、 $densifyを使用して、各クッキーvarietyのaltitudeフィールドを高密度化します。
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "full", step: 200 } } } ] )
集計の例:
ドキュメントを
varietyで分割して、Arabica Typica用の 1 つのグループとGeshaフィルター用の 1 つのグループを作成します。full範囲を指定します。つまり、各 パーティションの既存のドキュメントの全範囲にわたってデータが圧縮されます。200のstepを指定します。つまり、新しいドキュメントは200のaltitude間隔で作成されます。
この集計は、次のドキュメントを出力します。
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { variety: 'Gesha', altitude: 600 }, { variety: 'Gesha', altitude: 800 }, { variety: 'Gesha', altitude: 1000 }, { variety: 'Gesha', altitude: 1200 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1400 }, { variety: 'Gesha', altitude: 1600 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 }, { variety: 'Arabica Typica', altitude: 1000 }, { variety: 'Arabica Typica', altitude: 1200 }, { variety: 'Arabica Typica', altitude: 1400 }, { variety: 'Arabica Typica', altitude: 1600 } ]
この画像には、 $densifyで作成されたドキュメントが可視化されています。

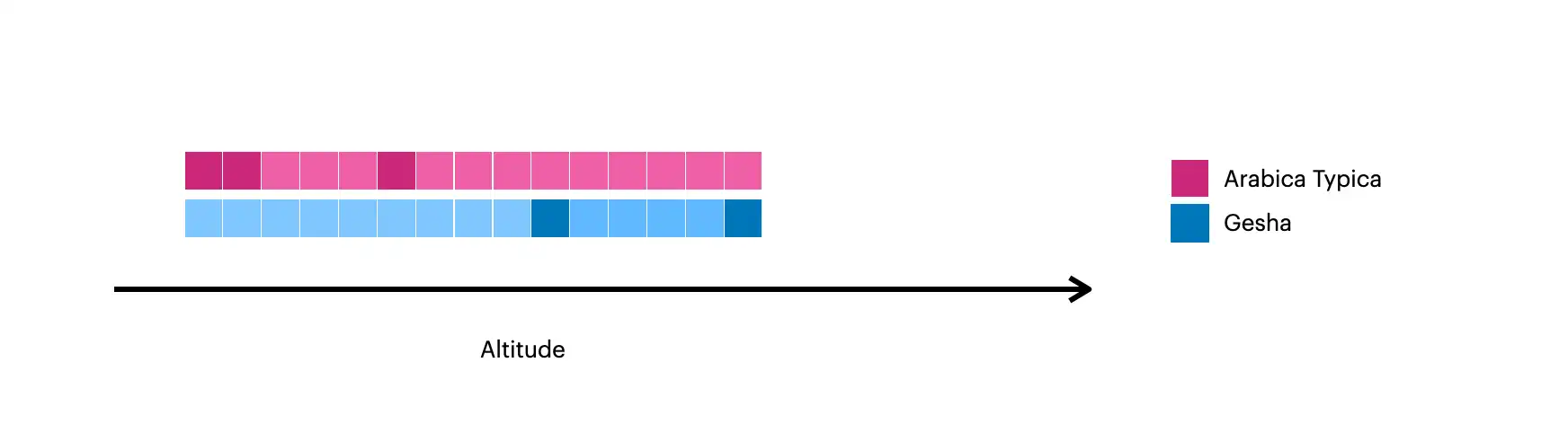
暗黙の正方形は、コレクション内の元のドキュメントを表します。
明るめの正方形は、
$densifyを使用して作成されたドキュメントを表します。
各パーティション内の値を高密度
この例では、 $densifyを使用して、各variety内のaltitudeフィールドのギャップのみを強調表示します。
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "partition", step: 200 } } } ] )
集計の例:
ドキュメントを
varietyで分割して、Arabica Typica用の 1 つのグループとGeshaフィルター用の 1 つのグループを作成します。partition範囲を指定します。つまり、各パーティション内でデータが圧縮されます。Arabica Typicaパーティションの場合、範囲は600-950です。Geshaパーティションの場合、範囲は1250-1700です。
200のstepを指定します。つまり、新しいドキュメントは200のaltitude間隔で作成されます。
この集計は、次のドキュメントを出力します。
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1450 }, { variety: 'Gesha', altitude: 1650 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 } ]
この画像には、 $densifyで作成されたドキュメントが可視化されています。

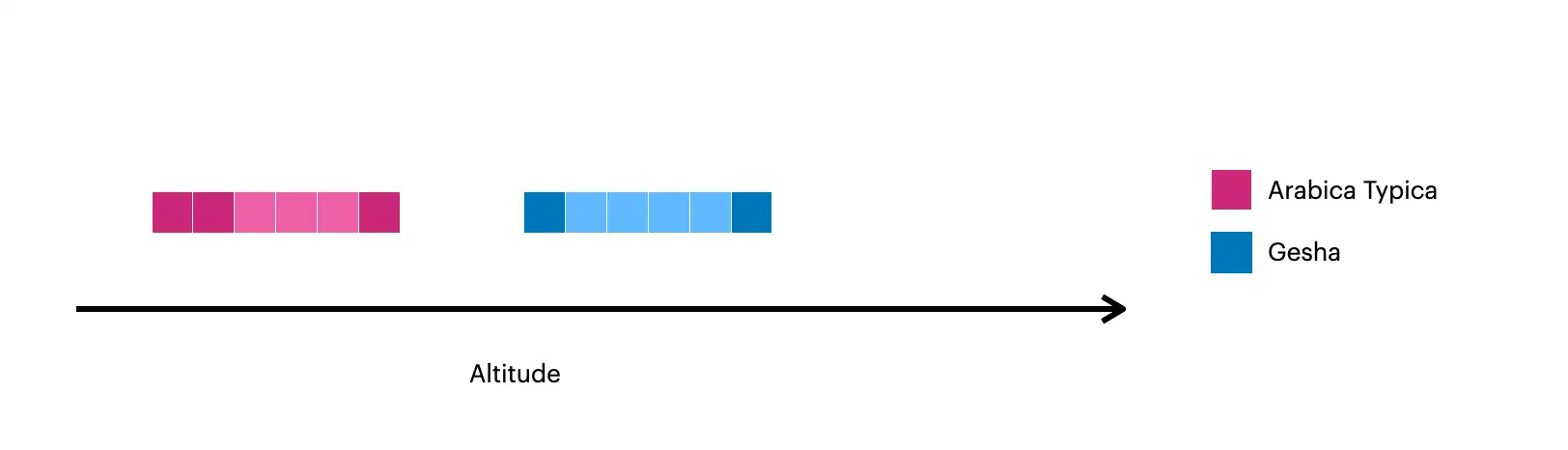
暗黙の正方形は、コレクション内の元のドキュメントを表します。
明るめの正方形は、
$densifyを使用して作成されたドキュメントを表します。
このページのC#の例では、Atlasサンプルデータセット の sample_weatherdata.dataコレクションを使用します。MongoDB Atlasクラスターを無料で作成して、サンプルデータセットをロードする方法については、 MongoDB .NET/ C#ドライバーのドキュメントの「 開始 」を参照してください。
次の Weather クラスと Point クラスは、sample_weatherdata.dataコレクション内のドキュメントをモデル化します。
public class Weather { public Guid Id { get; set; } public Point Position { get; set; } [] public DateTime Timestamp { get; set; } } public class Point { public float[] Coordinates { get; set; } }
sample_weatherdata.dataコレクションには、1 時間ごとの同じ positionフィールドの測定値を含む次のドキュメントが含まれています。
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
MongoDB .NET/ C#ドライバーを使用して$densify ステージを集計パイプラインに追加するには、 オブジェクトでdensify() PipelineDefinitionメソッドを呼び出します。
次の例では、前の 2 つのドキュメント間にドキュメントを追加するパイプラインステージを15分間隔で作成しています。次に、コードはこれらのドキュメントを Position.Coordinatesフィールドの値でグループ化します。
var densifyTimeRange = new DensifyDateTimeRange( new DensifyLowerUpperDateTimeBounds( lowerBound: new DateTime(1984, 3, 5, 8, 0, 0), upperBound: new DateTime(1984, 3, 5, 9, 0, 0) ), step: 15, unit: DensifyDateTimeUnit.Minutes ); var pipeline = new EmptyPipelineDefinition<Weather>() .Densify( field: w => w.Timestamp, range: densifyTimeRange, partitionByFields: [w => w.Position.Coordinates]);
前の集計ステージでは、コレクション内の次の強調表示されたドキュメントが生成されます。
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:15:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:30:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:45:00 EST 1984 }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
このページの Node.js の例では、Atlas サンプルデータセットの sample_weatherdata.data コレクションを使用します。無料の MongoDB Atlas クラスターを作成し、サンプルデータセットをロードする方法を学ぶには、MongoDB Node.js ドライバーのドキュメント「使用開始」をご覧ください。
sample_weatherdata.dataコレクションには、1 時間ごとの同じ positionフィールドの測定値を含む次のドキュメントが含まれています。
{_id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, {_id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }
MongoDB Node.jsドライバーを使用して $densify ステージを集計パイプラインに追加するには、パイプラインオブジェクトで $densify 演算子を使用します。
次の例では、前の 2 つのドキュメント間にドキュメントを追加するパイプラインステージを15分間隔で作成しています。次に、コードはこれらのドキュメントを position.coordinatesフィールドの値でグループ化します。次に、この例では集計パイプラインを実行します。
const pipeline = [ { $densify: { field: "ts", partitionByFields: ["position.coordinates"], range: { step: 15, unit: "minute", bounds: [new Date(1984, 3, 5, 8, 0, 0), new Date(1984, 3, 5, 9, 0, 0)] } } } ]; const cursor = collection.aggregate(pipeline); return cursor;
前の集計ステージでは、コレクション内の次の強調表示されたドキュメントが生成されます。
{ _id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:15:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:30:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:45:00.000Z }, { _id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }