Machine learning (ML) has been the buzzword for some time now, and from CEOs, business analysts, and data scientists to administrators and developers, everyone is eager to delve into the world of machine learning. Before getting into what machine learning is, let's quickly understand the fundamental differences between ML, deep learning (DL), and artificial intelligence (AI).
Table of contents
- ML vs AI vs DL
- Machine learning explained
- Why should one learn machine learning technology?
- History of machine learning (timeline)
- Types of machine learning models
- Supervised machine learning
- Unsupervised machine learning
- Reinforcement learning
- Machine learning process
- Machine learning use-cases
- Future trends in machine learning
- Summary
- FAQs
ML vs AI vs DL
Artificial intelligence is a branch of computer science that utilizes a computer to mimic or copy the decision-making and problem-solving abilities of a human brain. Some popular examples of AI are robots and autonomous vehicles. Machine learning is a branch or subset of AI that focuses on self-learning algorithms and uses volumes of data to gain knowledge and predict results — for example, recommendation systems and chatbots. DL comes under the machine learning umbrella and focuses on using artificial neural networks to simulate the human brain — for example, facial recognition and virtual assistants.

Difference between AI, ML and DL
Machine learning explained
Machine learning is the capability of machines to attain human intelligence by performing complex tasks that could previously only be done by humans. Machine learning focuses on self-learning algorithms to train itself and perform a set of actions, without being explicitly programmed. So, a “machine” can “learn” on its own by applying a set of algorithms (or rules) on the input data provided to it through several data sources and uncovering patterns.
The input data could be, for example:
- Historical data collected from various sources.
- Real-time data from transactions, streaming data from IoT devices, etc.
- Web crawling.
A simple example is your email inbox, where, based on your daily usage patterns and preferences, the messages can be put into different categories like spam, important, shopping, and so on. Other common examples are face recognition in Google photos, and personal assistants like Alexa and Siri.
Machine learning systems can also improvise based on the results and readjust algorithms to produce better results in each iteration. For example, let’s say you receive an email from an unfamiliar sender. Your email algorithm might classify it as spam at first — but later, as you label it as not spam or move it to the inbox, the algorithm learns to correctly categorize the emails from that sender or similar senders in the future.
Machine learning applications encompass a wide range of techniques, including computer vision, natural language processing, pattern identification, and predictive maintenance. Uses of these applications can be employed both with and without human intervention.
Why should one learn machine learning technology?
Machine learning systems are capable of solving complex problems with speed and accuracy that humans cannot match. With volumes of data generated, it is possible to create the right algorithms for prediction, decision making, and automating mundane processes. For example, if you are a developer, machine learning can help you with automated code generation and code analysis. If you are a tester, ML algorithms can help you with bug detection, edge test cases, and analyzing bug statistics. Similarly, if you are a writer, ChatGPT can help you with content recommendations, research assistance, and translations.
Businesses use machine learning algorithms for descriptive (use data to tell what happened), predictive (use data to tell what will happen), or prescriptive (use data to make important decisions) modeling. For instance, large retailer chains like Walmart and fast food companies like Burger King use descriptive analysis to form association rules and understand the common products that customers generally purchase together — like bread-eggs, burger-coke, and so on. Companies like Facebook and Netflix use predictive modeling to deliver personalized content to customers based on their past preferences. Airline companies use prescriptive modeling to determine market conditions and dynamically change pricing for flights and accommodation.
Success in machine learning algorithms is leading toward the development of advanced AI systems, like self-driving cars, ChatGPT, and speech assistants. Knowing these systems will help you be up to date with the relevant technologies, understand their limitations, and use them to bring in more innovation and productivity. For example, ChatGPT is a great tool and can help you with a lot of tasks, but you need to be able to ask the right questions.
History of machine learning (timeline)
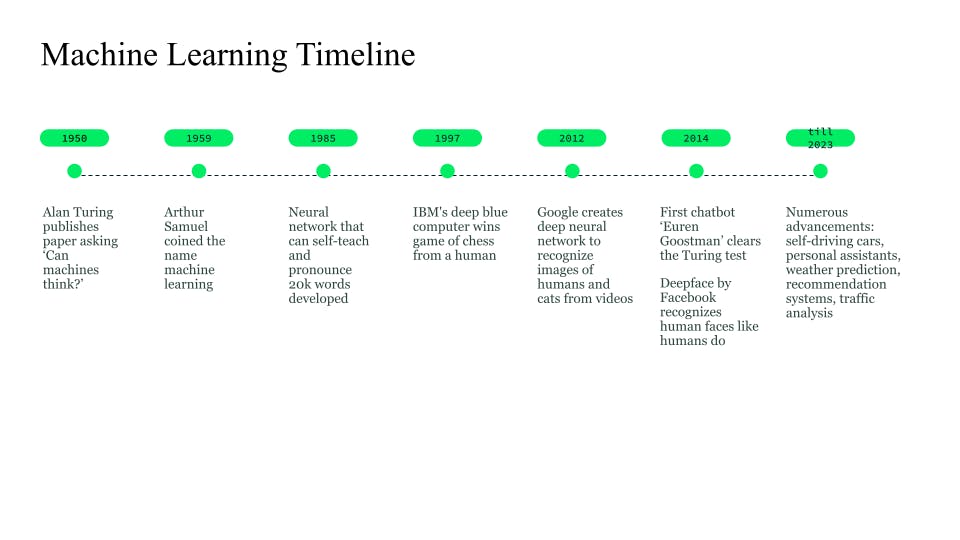
Although the exact inception of AI is debatable, a significant milestone occurred in 1950 when Alan Turing published a paper, "Computer machinery and intelligence." Later, in 1952, Arthur Samuel created a checkers game for computers to play and learn as they played. This was yet another notable achievement, akin to the learning process of the human brain, which derives knowledge from experience. Arthur coined the term "machine learning" in 1959.
Breakthrough in AI and ML came in 1985, when the first neural network NETtalk was invented. It was able to learn and pronounce 20,000 words in a week. In 1997, IBM's chess game, Deep Blue, won the game against a human chess expert for the first time. This marked a great accomplishment, as a machine was able to “think,” understand a human’s chess moves, play the next move based on the opponent’s move, and defeat a human in the game.
Further works continued in the 21st century, with the development of Google's deep neural network for image recognition in 2012, chatbots in 2014, self-driving cars, personal assistants, and the recommendation systems of today!
 How AI and machine learning have evolved over the years
How AI and machine learning have evolved over the years
Types of machine learning models
As the nature of data is different, the solutions applied to process and analyze the data also vary.
Some of the incoming data might have labels for identification, i.e., the features or characteristics that can be used to classify the data. For example, the color of a fruit, texture of a cloth, age of a person, eyes of a cat, and price of a product are features that help us identify the respective object. Such data is called labeled data.
However, most of the data is in the form of images, videos, PDF or text files, audios, CCTV footage, sensor data, tweets, and streaming data, all of which do not have unique characteristics that can classify or label them. Such data is called the raw data and is unlabeled. Raw data can be labeled by humans or scripts for machine learning algorithms to learn. Once a machine is able to label the data, human intervention becomes unnecessary, allowing machine learning models to process the data autonomously.
Based on the incoming data and the type of business problem we are trying to solve, we can apply the right type of machine learning model. Often, we may have to apply more than one model to achieve the desired results.
We explain the main types of machine learning models below:
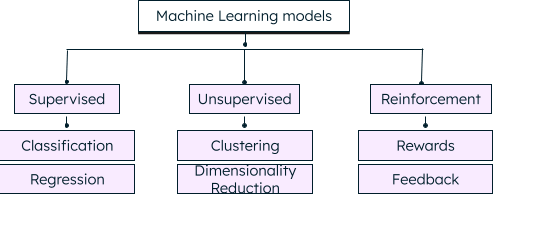
- Supervised machine learning: The machines are trained on labeled datasets, where labels help in grouping the data. The training dataset comes with a known input and output, and the machine needs to derive the exact function to get the output. Once the machine acquires this knowledge, it can process new datasets to verify its learning capabilities.
- Unsupervised machine learning: In this type, the datasets are not labeled. The machine does not know the correct output with certainty and derives it based on grouping, patterns, differences and trends in the input data.
- Reinforcement learning: Here, the machine trains by trial and error and establishes a reward system for taking the best decisions, and decides the next action based on the current actions and state.
Three major types of machine learning models
Another type of machine learning is the semi supervised learning model, which combines supervised and unsupervised learning algorithms — i.e., it has both labeled and unlabeled data and consists of both classification and clustering problems. Semi supervised learning is suitable for tasks where we have large amounts of unlabeled data and a small amount of labeled data. Semi supervised learning is also known as weak supervision.
Supervised machine learning
As the name says, in a supervised learning algorithm, the machine is fed with the input training data and the expected output. The machine acquires knowledge from the training data and comes up with the right function that determines the relationship between the input and the output. The function is then applied to a new set of data, and testing is done to see if the desired output is achieved.
A similar analogy is a child's brain, which is initially a clean slate. We show him/her people of different age groups and by visualizing the features, they are able to distinguish between girl, boy, young, old, and so on. Now, when the child sees a new person, with the information already known, he/she is able to relate and identify the person to be one of the known categories (old, young, girl, boy).
Supervised machine learning algorithms
Supervised learning algorithms require a huge amount of high-quality labeled data for producing accurate results. They are divided into two main categories:
Classification
In a classification mode, the ML algorithm puts the data into one of the categories. For example, if you have a dataset of shapes with characteristics like 2D, triangle, no sides, all sides equal, four sides, and so on, your model can categorize the data based on these characteristics as triangle, square, circle, and so on.
Regression
Regression uses statistical methods to predict an outcome or a continuous value, based on independent input variables. For example, by analyzing historical data that includes key features (input variables) such as mileage, age, model, after-sales service, value-adds, and durability of cars, a regression model can be developed to accurately predict the price of a particular second-hand car.
Some popular supervised learning algorithms are:
Naive Bayes: Naive Bayes is based on the Bayes theorem and is very effective for classification problems, mainly text classification. It is based on the probability of occurrence of a feature independent of the other features. Some popular applications of Naive Bayes include spam filtering, sentiment analysis, and credit scoring.
Decision Tree: Decision trees can be used for classification and regression. Decision trees follow a hierarchical structure, with the root node being the first node that represents the main problem/decision. From there, based on a series of questions, the tree is split into various paths depending on the answer (mostly yes/no). Here’s how a decision tree makes decisions.
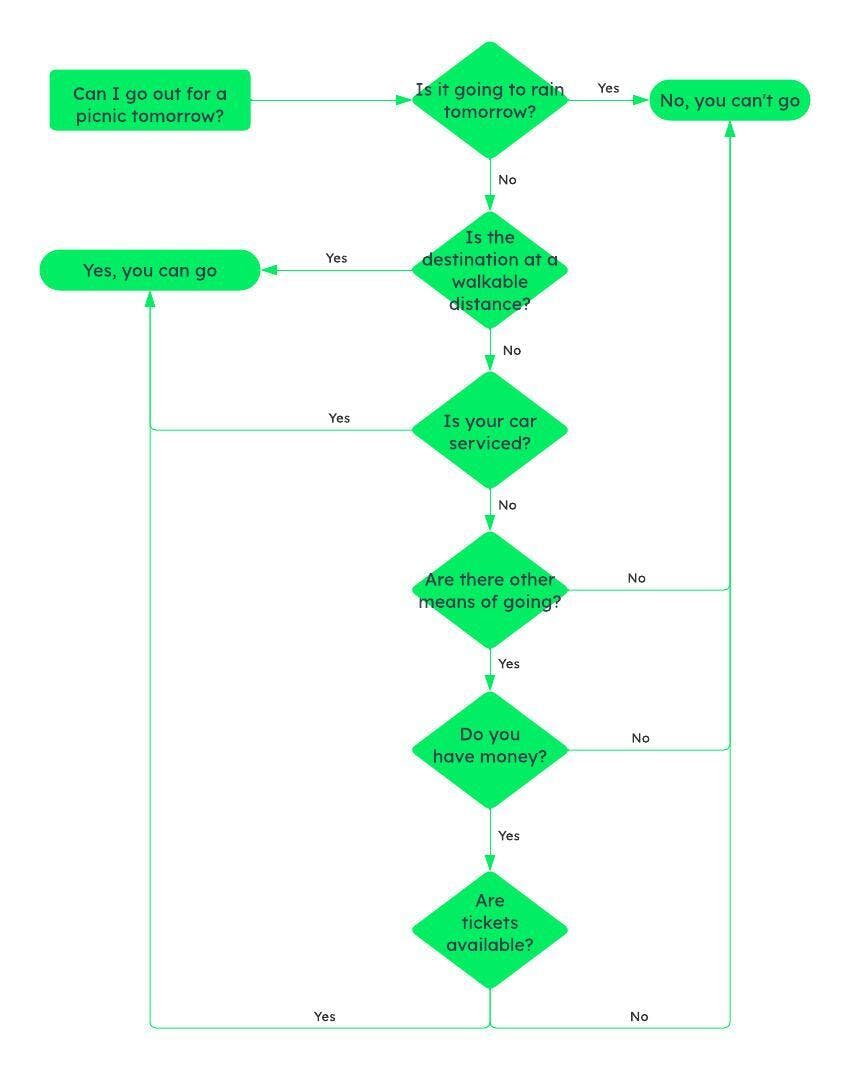
How decision tree splits to solve yes/no problems
Random forest: Random Forest is an ensemble supervised learning algorithm that combines multiple decision trees to predict the output. It can be used for both classification and regression tasks and can handle large amounts of data with multiple variables (features).
Support Vector machines (SVM): SVM is a powerful algorithm, more prominently used for classification, although it is also suitable for regression problems. SVM is used for text classification, anomaly detection, image classification, handwriting recognition, spam detection, and face detection. Support vectors are nothing but the data points, and the algorithm tries to find the optimum boundary or plane that separates the support vectors of each class (type).
Linear regression: Linear regression is used to find the continuous value of a dependent variable based on independent data points. Based on the scatter plot of variables, the algorithm finds the best fitting line and the corresponding linear equation (i.e., slope and the y-intercept) that gives the relationship between the independent and dependent variables. Using the equation, we can find the value we need. For example, if we have the median income of IT employees from the year 2005-2022, we can plot the income (dependent) against the time (independent) and find the linear equation. By putting a new time value in the equation, the algorithm can predict the median income for the required time (like 2025).
Logistic regression: Logistic regression is also called the generalized linear model. The difference between logistic regression and linear regression is that logistic regression predicts the probability of an outcome using a logistic function equation. The probability helps us categorize the data point into either of the categories: 0 or 1. For example, a student with 82% marks will get admission to a certain college, but a student with 34% or 49% will not. To determine the category which a data point falls into, a threshold is set. In our case, the threshold is 50%, so anything less than 50 will be one category and above 50 will be another.
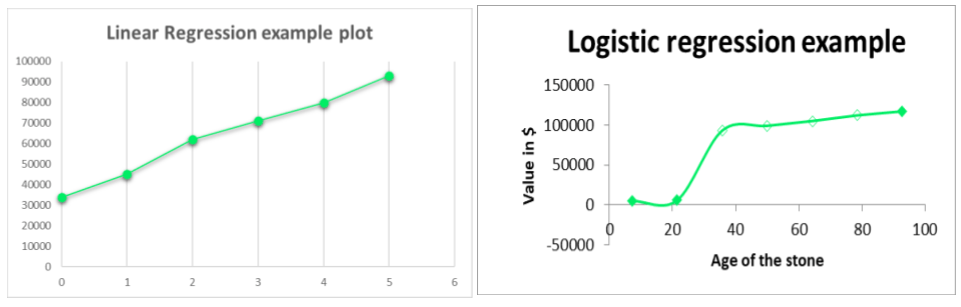 Linear and logistic regression example plots
Linear and logistic regression example plots
Unsupervised machine learning
Unlike supervised learning algorithms, in this type, there are no labeled datasets. The machine finds patterns, trends, and groups from the input data to derive inferences and make predictions. Unsupervised machine learning models are useful in finding those hidden patterns in data that are not explicitly programmed for or anticipated, like data mining, genetic clustering, medical imaging, and object recognition. Unsupervised learning algorithms are divided into clustering, association, and dimensionality reduction.
Unsupervised machine learning algorithms
Most of the data collected from various sources — like web crawling, emails, multimedia, and documents — is unstructured and doesn't come with labeled outputs. To make sense of such data, we need to apply unsupervised machine learning algorithms such as:
K-means clustering: As the name suggests, k-means is a clustering algorithm which works on the principle that similar data points should exist in the same vicinity and can be grouped into one cluster. “K” defines the number of clusters to be created. Once K is decided, each data point is assigned to a particular cluster. The process is iterative and repeats until all the data points are assigned to a cluster that have similar features.
Isolated forest: Isolated forest is an anomaly detection unsupervised machine learning algorithm that uses decision trees to find anomalies in the data. Anomalies are the deviations from the normal behavior, like unusual data points, outliers in a trend, or drifts in the dataset. Anomaly detection helps in identifying fraudulent transactions, signature identification, and malfunctioning equipment. Isolated forest splits the outlier data points such that they are isolated from the other data points.
Principal component analysis (PCA): PCA is a dimensionality reduction algorithm used for exploratory data analysis and predictive modeling. Using mathematical methods, like orthogonal transformation to find the variance of each feature, PCA extracts the most important features (features having high variance) of a dataset and discards the features that have low variance (least important), thus reducing the dimensions of data. PCA is widely used for image and video compression, customer profiling, and data classification.
Apriori: Apriori algorithm applies breadth-first search to identify items that are frequently used together and create association rules. It applies the principle of market-basket analysis for data mining — for example, food items that go together in the cart, like bread-eggs, milk-biscuits, and so on. It is widely used by recommendation engines that suggest movies, songs, or items that a user can choose, based on their past preferences.
Reinforcement learning
In reinforcement learning, an agent (machine) trains to take the best action in a certain environment, using trial and error methods. A cumulative reward system (positive feedback) is established for each correct action and a penalty (negative feedback) is added for incorrect action. The agent makes decisions based on its current state and a set of rules known as policy. It transitions to a new state based on the feedback. The feedback reinforces the learning in the machine.
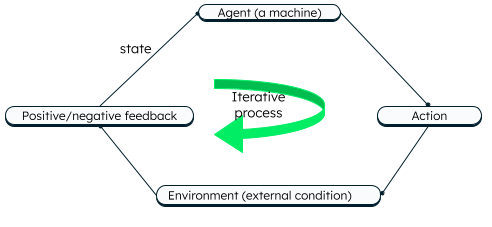
Main actors of the reinforcement learning process
Consider the classic game of Pong, where you (human) are playing against the machine (agent). As the game goes, the agent learns to hit the ball and controls the paddle accordingly so that it doesn't miss the ball. For each correct action (hitting the ball), the agent gets a point (reward) and for each wrong action (missing the ball), the agent receives a penalty (point for opponent).
The method where the agent receives a reward — like points, a spot on the leaderboard, or badges — for good results is called positive reinforcement learning. Due to the incentivization, the algorithm tries to get good results each time. The method where the agent gets negative points, a penalty, or loses a life for each mistake is known as negative reinforcement learning. This discourages the agent from making the same decision again.
Reinforcement learning is widely used in recommendation engines, gaming systems, robotics, autonomous or self-driving cars, formulating sales and marketing strategies, and deep learning models.
Reinforcement learning methods
Reinforcement machine learning algorithms deploy various methods to learn the most optimal policy:
Value-based methods: In this approach, the agent tries to find the best value function. For this, the agent estimates the value of each state-action pair based on the cumulative reward each state-action pair gives. Consider the game of Pacman, where Pacman moves in a maze-like environment to consume all the dots, while evading the monsters. At each step, he collects the data of his state-action pairs, like being eaten by a monster by taking a right, or escaping the monster by taking left. The cumulative value of each such pair helps Pacman decide the optimal next action to receive the maximum value, like consuming the dot and taking a left. Value-based approach works well for video games, autonomous agents, and board games.
Policy-based methods: In this method, the agent follows a set of rules (policies) to decide the best action in a given state. It refines the policies based on cumulative rewards and experience by adjusting the parameters of a policy function and obtaining the most optimal policy. Policy-based reinforcement learning is suitable for robotics, natural language processing, and autonomous navigation.
Actor-critic methods: This approach combines both policy-based and value-based reinforcement learning approaches. Here, the actor learns and improves the policy, and the critic predicts the quality (or value) or the different state-action pairs. The learning between the actor and critic is iterative and very efficient. It is suitable for robotics, gaming, and continuous control tasks.
Reinforcement learning algorithms
Reinforcement learning algorithms aim to solve decision-making problems by utilizing a combination of neural networks, iterative algorithms, and policy optimization techniques. Through iterative trial and error, the agent (machine) learns to make optimal decisions and determine the best course of action within a given environment. These algorithms excel in scenarios where limited or no training data is available, as they facilitate direct interaction between the machine and the environment for training and continuous improvement.
There are many reinforcement learning algorithms, the most common and simplest being the Q-learning algorithm.
Q-learning: “Q” stands for quality and measures how valuable a particular action is, for the rewards to maximize. The Q-learning algorithm uses a table called the Q-table and updates it with state-action values in each iteration. It takes the best action (the action with the maximum value) for the next state depending on the existing/previous values in the Q-table. In other words, it exploits the current knowledge to make optimal decisions. Q-learning is popularly used in humanoid robots and drones.
Deep Q-networks (DQN): As the number of features increases, storing and updating a separate Q-value for every state-action pair becomes computationally expensive. To solve this, Q-learning can be combined with deep neural networks that can handle high dimensional state space (i.e., datasets with multiple features). DQN is the foundation for autonomous vehicles.
State-Action-Reward-State-Action (SARSA): SARSA is similar to Q-learning. However, the difference is that during training, the agent learns from the current set of actions in the current state. The previous set of actions and rewards are not considered for new states, so the algorithm does not depend on previous states and actions. This means SARSA explores more, takes a longer time to choose an optimal path, and understands risks better. SARSA is very useful in environments where exploration of the environment is crucial. Some areas where SARSA is used are robot control, game playing, and recommendation systems.
Machine learning process
Machine learning mainly involves three steps: training, validation, and testing.
For training, the machine needs huge volumes of current and historic data. Data is collected from multiple sources and can be in structured, unstructured, or semi-structured formats. Such data cannot be used as it is because it may have many irrelevant columns, null values, and so on. Thus, data is cleaned and transformed into the required format. There are many tools to clean and transform the data — for example, R, Python, and Excel. You can view our tutorial on how to clean and analyze data using MongoDB with R and Python. Once data is ready to use, it is fed to the machine learning algorithm.
The algorithm is selected depending on the business problem. For example, if your problem is to determine whether it will rain tomorrow, or whether an email is spam or not, you can use decision trees or naive bayes. Similarly, if you want to understand the shopping trend of a certain age group of customers, you can use clustering. You may require more than one algorithm in some cases.
Once you decide the algorithm and the machine learns from the dataset, it needs to be validated using new datasets, called the testing datasets. There are four possible results:
- True Positive: When a condition exists and the machine learning model predicts it correctly (for example, the machine identifies a dog as a dog in an image)
- True Negative: When the condition does not exist and the model believes it does not exist (for example, there is no dog in the image and the machine also says the same)
- False Positive: When the condition does not exist but the model believes it does (for example, the model identifies a cat in the image as a dog)
- False Negative: When the condition exists but the model cannot identify it (for example, the machine is unable to identify the dog in the image)
These four results determine the accuracy of the model and form the basis of determining the model’s suitability for a given problem. The model and parameters are re-evaluated iteratively, until we get the desired accuracy.
Other than validating and fine-tuning the algorithms, testing datasets is essential for assessing the performance of machine learning models. It improves reliability and generalizability of the models and steers decision-making in practical applications.
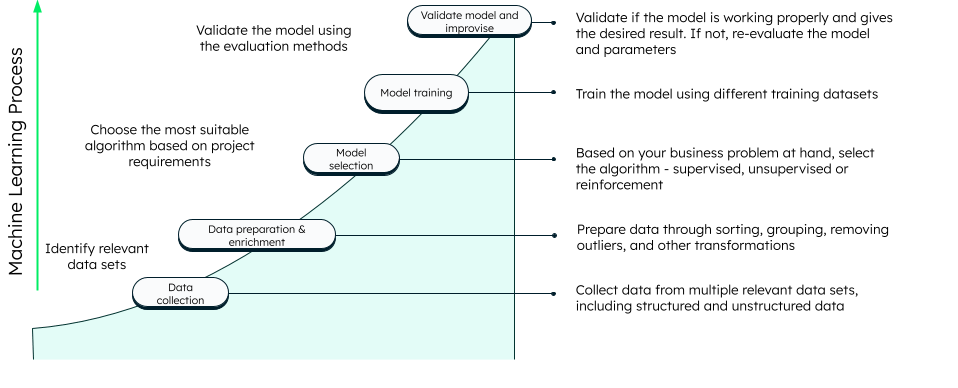 Various steps involved in machine learning
Various steps involved in machine learning
Machine learning use-cases
Machine learning finds applications in various fields, from banking, logistics, and the food sector to healthcare, education, and research. Below, we list a few of the most prominent machine learning use cases:
Image and face recognition
The most common use case of ML is for image and handwriting recognition. A common example is Google photos, which sorts photos of you and your friends and family using face recognition. Image recognition can go a long way in detecting crimes, aiding forensic investigations, diagnosing diseases, and much more.
Recommendation engine
If you shop often with Amazon or watch Netflix, you must have noticed the way the system recommends you products/movies based on your genre and previous watch preferences. All this is done through machine learning algorithms that collect user data and make predictions.
Healthcare
Using machine learning algorithms, many ailments can be detected at early stages, which would otherwise go unnoticed. Also, when fed with patient history and their lifestyles, ML algorithms can perform predictive analytics and suggest preventive measures and personalized treatment plans for any potential ailments. Researchers can also use machine learning models for drug discovery and development.
Fraud detection
Machine learning algorithms can be trained to detect unusual transaction activities, suspicious links, fake accounts, and fake signatures using pattern and handwriting recognition.
Natural language processing
Machine learning algorithms have come quite far in comprehending and responding to human language, the most popular tools being Alexa, Siri, and chatbots.
Autonomous cars
By using advanced machine learning algorithms, cameras, radar, GPS, and sensors, autonomous vehicles can be helpful in optimizing traffic congestion, fuel efficiency, improved mobility, and many other benefits.
Robotics
Machine learning algorithms are used to process sensor data obtained from various sources, like cameras and radars. Using computer vision, motion planning and control, object recognition, and autonomous navigation, ML helps a robot to manage obstacles, perceive information, and perform tasks. Further, using natural language processing, robots are able to interact with humans.
Future trends in machine learning
AI and machine learning are continuously evolving, and the future looks quite bright, with focus on:
Deep reinforcement learning systems to learn complex situations and make the right decisions in dynamic environments.
Consistent insights in the fields of healthcare, education, finance, manufacturing, and many other domains.
Federated learning — i.e., keeping the user data private while training the models across decentralized devices and collaborative learning.
IoT integration. As the number of IoT devices are increasing, it is important for machine learning models to process real-time data.
Reducing human bias, to make the models more trustworthy and ethical.
Summary
Machine learning has proven to be very useful in various domains, like education, healthcare, manufacturing, marketing, and many more. However, it needs a lot of data to produce actual results. It is very important to follow proper ethics and governance rules while collecting user data, considering their privacy.
The type of algorithm(s) used depends largely on your business problem, and it takes experience to understand and arrive at the right algorithm(s). At times, human biases can lead to bias in the training data, as well.
That said, when put to the right use, machine learning can prove to be more accurate, avoid errors that humans make while doing the same task, and arrive at decisions much faster than humans can. It can reduce the load on humans to perform mundane tasks and help them improve productivity.
FAQs
What is machine learning (ML)?
Machine learning is a branch of computer science that involves training computers to perform tasks akin to human learning. The machine learning process uses various algorithms that apply transformed data collected from diverse sources, for learning. The output is iteratively evaluated until the most accurate results are achieved.
How does machine learning work?
Machine learning works on a set of processes. First, raw data is collected from different sources. From that, the relevant data is sorted, grouped, processed, and transformed to make it ready for analysis. The data is then fed to the chosen machine learning algorithms, which train and produce the output. The output is evaluated and improvised until the desired results are achieved.
Is machine learning AI?
Machine learning is a branch of AI, where machines learn how to perform certain tasks that could previously be done only by humans. Machines do this by collecting volumes of data, processing the data, and applying the relevant algorithms, until the desired result is achieved.