What is a Graph Database?
A graph database stores data in nodes and edges—nodes for information about an entity and edges for information about the relationship or actions between nodes. This data model allows graph databases to create relationships between the interconnected data, which makes searching for connections and patterns in the data easier than it is with traditional databases.
Graph databases use the following key terms:
Nodes (or vertices) You can think of nodes as the nouns in your databases; they store information about people, places, and things. For example, Airport could be a node with properties airport_code and country. In MongoDB, those would be the documents in a collection.
Edges (or relationships between data) You can think of edges as the verbs in your databases; they store information about the actions that are taken between the nodes. For example, “is,” “has,” “likes,” “follows,” as in user_1 follows user_2, or airport_1 has restaurant_2. In MongoDB, those would be defined through the $graphLookup operator.
Properties A property is a key-value pair that stores information about a particular node or edge. For example, airport_code. These are the same as the properties in a MongoDB document.
Labels A label can optionally be used to tag a group of related nodes. For example, all nodes that have airport details can be labelled as Airport.
Table of contents
How data is stored in a graph database
Let's walk through how data is stored in a graph database. Let's say you want to store air travel information.
Each airport would be represented by a node, and information about the airports would be stored in the nodes' properties. For example, you could create a node for Auckland Airport in New Zealand with properties such as airport_code: AKL and country: New-Zealand.
A flight between two airports—that is, the relationship between two nodes—is represented by an edge. The edge's properties contain information about the flight. In this example, you could create an edge between the nodes for Auckland Airport and Brisbane Airport. The edge could have properties like airplane: 73H 388 and airline: Qantas.

A node represents Auckland Airport, with its properties listed. An edge represents a flight from Auckland Airport to Brisbane Airport, with properties for airplane and airline.
In addition to the nodes for airports, you might create nodes for other related entities such as airport restaurants. You might choose to apply a label like Airport to the airport nodes and Restaurant to the restaurant nodes. The graph visualization diagram below shows a graph with several nodes, edges, properties, and labels.
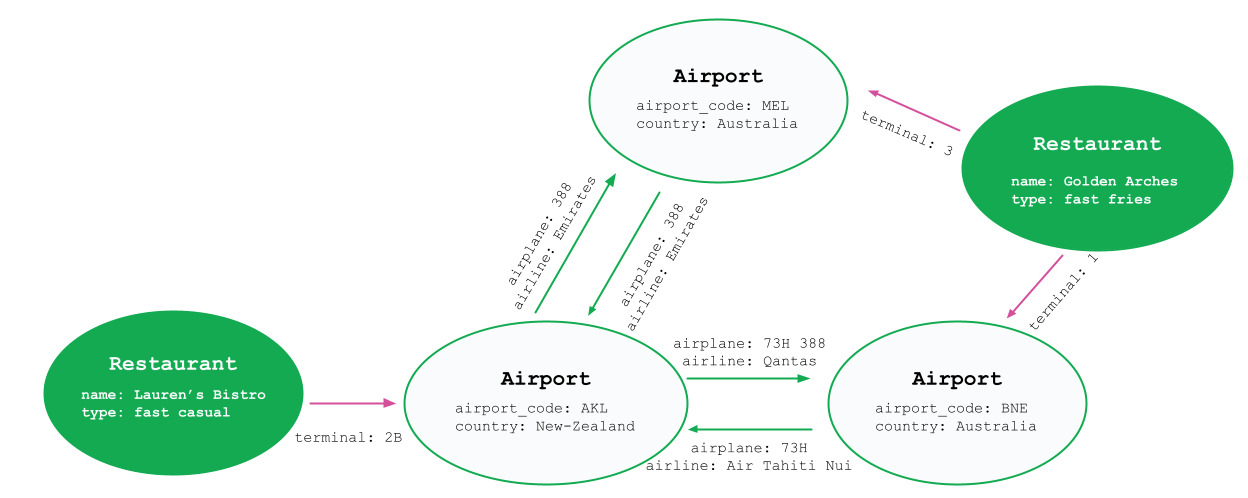
A graph that represents airports, airport restaurants, and flights.
Core functions of graph databases?
Graph databases started gaining popularity with the rise of big data to manage complex data relationships. They are now a significant part of applications like social networks, recommendation engines, and fraud detection. Below are some reasons why organizations choose a graph database over other options.
Relationship management
Because graph databases prioritize relationships and can directly navigate even complex ones, they excel in queries that require multiple levels or traversals. They allow you to query relationships between nodes to look for patterns and make predictions. In a world where making intelligent decisions and recommendations is becoming increasingly important, graph databases shine where traditional relational databases struggle.
Graph analytics
Graph analytics is a technique of analyzing graph structure to provide data insights, patterns, and relationships between interconnected data elements. It involves using the connections between the nodes (entities) and their relationships (edges) to perform complex data analysis. Although some databases support graph-like queries, most traditional databases are not optimized for large-scale graph analytics.
Flexible schema
Most graph databases provide a flexible schema. This allows developers to easily make changes to their database as requirements inevitably change and evolve. Flexible schemas are hugely valuable for agile teams building modern applications.
Performance with interconnected data
Traditional databases usually struggle querying multiple levels of connected data due to the complex nature of joins, which results in deteriorating performance. A graph database is optimized to traverse and query relationships directly even for multiple levels of interconnected data.
How MongoDB integrates with graph data
MongoDB is a general-purpose document database. Since MongoDB stores data in documents, you can easily store and query in a graph structure. As shown in the diagram below, the document model is a superset of other data models including key-value, relational, objects, graph, and geospatial.
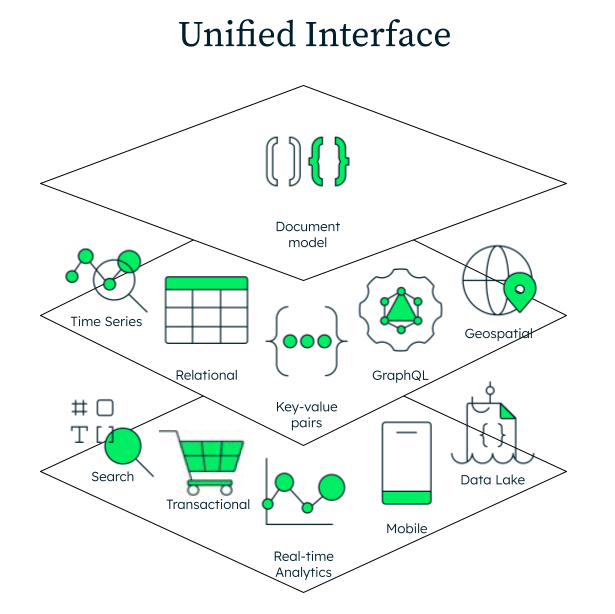
Documents are a superset of all other data models.
MongoDB has a $graphLookup aggregation pipeline stage for querying graphs. $graphLookup is ideal for traversing graphs, trees, and hierarchical data. Keep in mind that $graphLookup may not be as performant or provide the full graphing algorithm capabilities that a standalone graph database does.
If your application will be frequently running graphing queries, consider coupling your MongoDB database with a graph database. Note that coupling databases introduces significant complexity into your architecture, requiring you to keep data in sync between two distinct systems as well as use different languages to query them. Therefore, if your requirement for graph queries can be served by the capabilities that are built into MongoDB, you may be better off keeping everything together in one place and using a single API to interact with your data.
For more information on the graph capabilities in MongoDB, check out this webinar on working with graph data in MongoDB.
Getting started with MongoDB as a graph database
MongoDB has a $graphLookup aggregation pipeline stage that performs a recursive search. $graphLookup can be used to traverse connections between documents.
Let's take a look at an example from the routes collection, which is included in the MongoDB Atlas sample dataset. The routes collection contains information about airline routes between airports. Below is a sample document from the routes collection.
{
_id:"56e9b39c732b6122f878b0cc",
airline: {
id: 4089,
name: 'Qantas',
alias: 'QF',
iata: 'QFA'
},
src_airport: 'AKL',
dst_airport: 'BNE',
airplane: '73H 388'
}The document above stores information about a route from Auckland Airport (AKL) to Brisbane Airport (BNE). The document indicates that the airplanes assigned to this route are the Boeing 737-800 (73H) and the Airbus 380-800 (388). The document also indicates that the airline operating this route is Qantas.
Let's query for all possible destinations that can be reached from Auckland Airport either directly or through connecting flights. We can use MongoDB's aggregation pipeline to craft our query. We can begin our aggregation pipeline with the $match stage to match documents where the src_airport is AKL. Then we can use the $graphLookup stage to recursively search for documents where the src_airport matches the current document's dst_airport. Below is the full aggregate command to be run in the MongoDB shell. Note that this query will likely take a few minutes to run as it searches for all possible routes.
db.routes.aggregate(
[
{
$match: {
src_airport: 'AKL'
}
},
{
$graphLookup: {
from: 'routes',
startWith: '$dst_airport',
connectFromField: 'dst_airport',
connectToField: 'src_airport',
as: 'routesThatCanBeReached',
depthField: 'numberOfAdditionalStops'
}
}
])The result is a set of documents. Each document in the result is a route that originates from AKL. Each document also contains an array named routesThatCanBeReached, which lists all of the routes that can be reached either directly or indirectly from the route listed in the document. The numberOfAdditionalStops field indicates how many additional stops a passenger would have after their first flight in order to complete this route. Below is part of the output from running the aggregate command above.
[
{
_id: "56e9b39c732b6122f878b0cc",
airline: { id: 4089, name: "Qantas", alias: "QF", iata: "QFA" },
src_airport: "AKL",
dst_airport: "BNE",
airplane: "73H 388",
routesThatCanBeReached: [
{
_id: "56e9b39c732b6122f8787a6d",
airline: { id: 2822, name: "Iberia Airlines", alias: "IB", iata: "IBE" },
src_airport: "ORY",
dst_airport: "IBZ",
airplane: "320",
numberOfAdditionalStops: 3
},
{
_id: "56e9b39c732b6122f87882a1",
airline: { id: 3052, name: "Jetstar Airways", alias: "JQ", iata: "JST" },
src_airport: "BNE",
dst_airport: "LST",
airplane: "320",
numberOfAdditionalStops: 0
}
...
]
},
{
_id: "56e9b39c732b6122f878b0cd",
airline: { id: 4089, name: "Qantas", alias: "QF", iata: "QFA" },
src_airport: "AKL",
dst_airport: "MEL",
airplane: "73H",
routesThatCanBeReached: [
...
]
},
...
]Let's say we want to further refine this query. We want to limit our results to trips with, at most, one stop. To do this, we can set maxDepth to 0 to indicate the query should use a maximum recursion depth of 0. We can also choose to only search for flights on a particular airline by using the restrictSearchWithMatch property. Below is the full aggregate command to be run in the MongoDB shell:
db.routes.aggregate([
{
'$match': {
'src_airport': 'AKL',
'airline.name': 'Qantas'
}
}, {
'$graphLookup': {
'from': 'routes',
'startWith': '$dst_airport',
'connectFromField': 'dst_airport',
'connectToField': 'src_airport',
'as': 'airportsThatCanBeReachedWithOnlyOneStop',
'maxDepth': 0,
'restrictSearchWithMatch': {
'airline.name': 'Qantas'
}
}
}
]
)Just like the previous command that we ran, the result is a set of documents. Each document contains an array named airportsThatCanBeReachedWithOnlyOneStop, which contains information about routes that begin at the connection and are operated by Qantas. Below is part of the output from running the aggregate command above.
[
{
_id: ObjectId("56e9b39c732b6122f878b0cc"),
airline: { id: 4089, name: 'Qantas', alias: 'QF', iata: 'QFA' },
src_airport: 'AKL',
dst_airport: 'BNE',
airplane: '73H 388',
airportsThatCanBeReachedWithOnlyOneStop: [
{
_id: ObjectId("56e9b39c732b6122f878b104"),
airline: { id: 4089, name: 'Qantas', alias: 'QF', iata: 'QFA' },
src_airport: 'BNE',
dst_airport: 'LDH',
airplane: 'DH8'
},
{
_id: ObjectId("56e9b39c732b6122f878b0f8"),
airline: { id: 4089, name: 'Qantas', alias: 'QF', iata: 'QFA' },
src_airport: 'BNE',
dst_airport: 'CBR',
airplane: '717 73H'
},
…
{
_id: ObjectId("56e9b39c732b6122f878b0cd"),
airline: { id: 4089, name: 'Qantas', alias: 'QF', iata: 'QFA' },
src_airport: 'AKL',
dst_airport: 'MEL',
airplane: '73H',
airportsThatCanBeReachedWithOnlyOneStop: [
{
_id: ObjectId("56e9b39c732b6122f878b1bd"),
airline: { id: 4089, name: 'Qantas', alias: 'QF', iata: 'QFA' },
src_airport: 'MEL',
dst_airport: 'HBA',
airplane: '73H'
},
…
]
}
…
]The examples above are just a taste of what you can do with $graphLookup. Check out the official MongoDB documentation on $graphLookup and the free MongoDB University Course on the Aggregation Framework.
Graph database vs. relational database
The main purpose of choosing a graph database over a traditional relational database is that a graph database can directly traverse through multiple relationships, which can only be accomplished in relational databases using complex joins.
Here are some other prominent differences between a graph database and relational database:
Graph database types
There are several types of graph databases, classified based on their query capabilities, underlying data model, and use cases they handle—with many of them having their own query language.
Property graph databases use the property graph model that stores properties for both edges and nodes. For example, Neo4j uses Cypher query language.
Resource Description Framework (RDF) graph databases use the RDF model, where data is represented as triples in subject-predicate-object manner. For example, Apache Jena uses SPAR query language.
Multi model databases support various models, including graph, document, and key-value for enhanced flexibility. For example, ArangoDB uses the ArangoDB query language.
Key considerations for graph databases?
A graph database is a great choice when you need to analyze relationships between entities to look for patterns, generate intelligent recommendations, model networks, or compute graph algorithms.
Native graph databases tend to be less performant for non-traversal queries. Most applications require such queries, so they require a general-purpose database. For applications that would benefit from both a graph database as well as a general purpose database, developers have two options:
- Couple a general-purpose database (like a document or relational database) with a graph database.
- Use a general-purpose database (like MongoDB) that has graphing capabilities.
Common use cases for graph data
Graph databases are suited for a variety of use cases that need to represent parent-child relationships. Some of the most common are detecting fraud, building recommendation engines, managing IT networks, and computing graph algorithms between data.
Detecting fraud
A graph database is commonly used for the detection of money laundering, credit card fraud, insurance fraud, tax fraud, and other criminal activity in financial transactions. In recent years, criminals have become increasingly sophisticated in their schemes. Rather than working from a single point or account, they create a fraud ring of smaller schemes that are much more likely to go undetected. Graph databases allow analysts to look at the connections between the data to find patterns of fraud.
Building recommendation engines
Modern businesses want to provide intelligent recommendations to their customers as a strategic way to increase revenue. Graph databases allow an application to analyze previous purchase data to determine what the customer may want to purchase next.
Managing IT networks
A graph database can help IT specialists model and manage networks, IT infrastructure, and IoT devices. Because these entities are physically connected in the real world, they map naturally to graphs. Graph databases can enable organizations to easily perform impact analysis and plan for outages.
Computing graph algorithms
When you need to efficiently perform calculations on the connections between data, graph databases are a great option. They are used extensively for computing graph algorithms such as shortest path and PageRank. These algorithms are used in everything from finding the cheapest flight between two locations to determining influence in social networks.
Knowledge graphs
Knowledge graphs use graph databases to provide semantic meaning and context, enabling richer and more insightful analytics. Knowledge graphs combine and represent data in a graph model by extracting data from multiple sources, determining the relationships between the nodes (entities) based on the context and constructing graphs.
FAQs
Is MongoDB a graph database?
When should you use a graph database vs. MongoDB?
Most applications will require a general-purpose database like MongoDB. Some applications will also require graph capabilities. In those cases, MongoDB's $graphLookup may provide sufficient graph capabilities, providing developers with the simplicity of using a single database. Other applications will require more advanced graph capabilities that are currently only available in a dedicated graph database. In those cases, a graph database can be coupled with a general-purpose database like MongoDB.
Can MongoDB be used as a graph database?
Getting Started with MongoDB as a Graph Database

