Atlas에서 동기화 스토리지 최적화
이 페이지의 내용
Atlas Device Sync 는 동기화된 앱의 Atlas cluster 공간을 사용하여 동기화 를 위한 메타데이터 를 저장 합니다. 여기에는 동기화된 각 데이터베이스 의 변경 기록이 포함됩니다. Atlas App Services 는 Atlas cluster 에서 이 공간 사용량을 최소화합니다. 동기화 에 필요한 시간과 데이터를 줄이려면 메타데이터 를 최소화해야 합니다.
기록
App Services 백엔드 는 MongoDB oplog 영역 유사하게 각 Realm에 대한 기본 데이터의 변경 기록을 유지합니다. App Services 는 이 기록을 사용하여 백엔드 와 클라이언트 간의 데이터를 동기화합니다. App Services 는 동기화된 Atlas cluster 에 기록을 저장합니다.
트리밍
앱에서 클라이언트 최대 오프라인 시간을 설정하다 하면 트리밍 하면 클라이언트 최대 오프라인 시간보다 오래된 변경 사항이 삭제됩니다.
클라이언트 최대 오프라인 시간
트리밍에 사용되는 클라이언트 최대 오프라인 시간 은 기록의 보존 기간을 제어합니다. 이는 백엔드와의 동기화 세션 간에 클라이언트가 오프라인 상태를 유지할 수 있는 기간을 간접적으로 변경합니다. 지정된 일수 이상 동기화하지 않는 클라이언트는 다음에 백엔드에 연결할 때 클라이언트 재설정 될 수 있습니다.
클라이언트 최대 오프라인 시간을 더 낮은 값으로 설정하면 동기화에 필요한 기록 양이 줄어듭니다. 결과 최적화는 동기화된 Atlas cluster의 스토리지 사용량을 낮춥니다.
새 앱은 클라이언트 최대 오프라인 시간을 기본값인 30일로 자동으로 활성화합니다.
경고
클라이언트 최대 오프라인 시간으로 인해 기록에 영구적인 변경 사항 발생
클라이언트 최대 오프라인 시간을 통해 이전 기록을 트리밍할 수 있습니다. 이렇게 하면 영향을 받은 기록이 영구적으로 변경되어 나중에 클라이언트 가 재설정될 수 있습니다.
주요 개념
동기화는 모든 클라이언트에서 항상 동일한 종료 상태로 수렴되어야 합니다. 동기화 중에 수렴하려면 클라이언트에 마지막 동기화 직후 시작되는 전체 변경 기록이 필요합니다. 클라이언트가 장기간 동기화되지 않는 경우 트리밍으로 인해 클라이언트가 수렴되지 않는 방식으로 기록이 변경될 수 있습니다. 동기화는 모든 클라이언트가 공통 결과에 수렴하는 것에 의존하기 때문에 이러한 클라이언트는 동기화할 수 없습니다.
따라서 클라이언트는 동기화를 재개하기 전에 클라이언트 재설정을 완료해야 합니다. 클라이언트 재설정 시나리오에서 클라이언트는 영역의 클라이언트 로컬 복사본을 삭제하고 백엔드에서 해당 영역의 현재 상태를 다운로드합니다. 그런 다음 영역의 새 복사본을 사용하여 동기화가 다시 시작됩니다.
클라이언트 최대 오프라인 시간은 트리밍을 적용하기 전에 백엔드가 대기하는 시간을 제어합니다. 동기화되지 않은 지정된 일수가 지나면 클라이언트가 다음에 백엔드에 연결할 때 클라이언트 재설정을 경험할 수 있습니다.
클라이언트 최대 오프라인 시간을 지정하지 않는 애플리케이션은 트리밍을 적용하지 않습니다. 이는 클라이언트가 몇 주, 몇 달, 심지어 몇 년 동안 오프라인에서 연결한 후 변경 사항을 동기화할 수 있음을 의미합니다. 시간이 지남에 따라 자주 편집되는 Realm에는 많은 변경 사항이 누적됩니다. 변경 집합이 크면 동기화에 더 많은 시간과 데이터 사용량이 필요합니다.
클라이언트 최대 오프라인 시간이 클라이언트 재설정에 즉시 영향을 주지 않음
트리밍은 기록에 영구적이고 되돌릴 수 없는 변경을 일으킵니다. 따라서 클라이언트 최대 오프라인 시간을 늘려도 클라이언트가 클라이언트 재설정을 경험하기까지의 시간은 즉시 변경되지 않습니다. 기존 기록이 트리밍으로 인해 이미 변경되었으므로 클라이언트 재설정이 필요합니다. 새 기록은 새 클라이언트 최대 오프라인 시간까지 누적하는 데 시간이 필요합니다.
클라이언트 최대 오프라인 시간을 줄이면 클라이언트가 클라이언트 재설정 을 경험하기까지의 시간이 즉시 변경되지는 않습니다. 정기적으로 예약된 트리밍 작업 이 새로 적합한 기록에 트리밍을 적용하면 클라이언트 재설정이 더 일찍 수행되기 시작합니다.
클라이언트 최대 오프라인 시간 설정
App Services UI 의 사이드바에서 Device Sync 메뉴를 클릭합니다. Dashboard 탭 이 기본값 표시됩니다.
Configuration 탭을 클릭합니다.
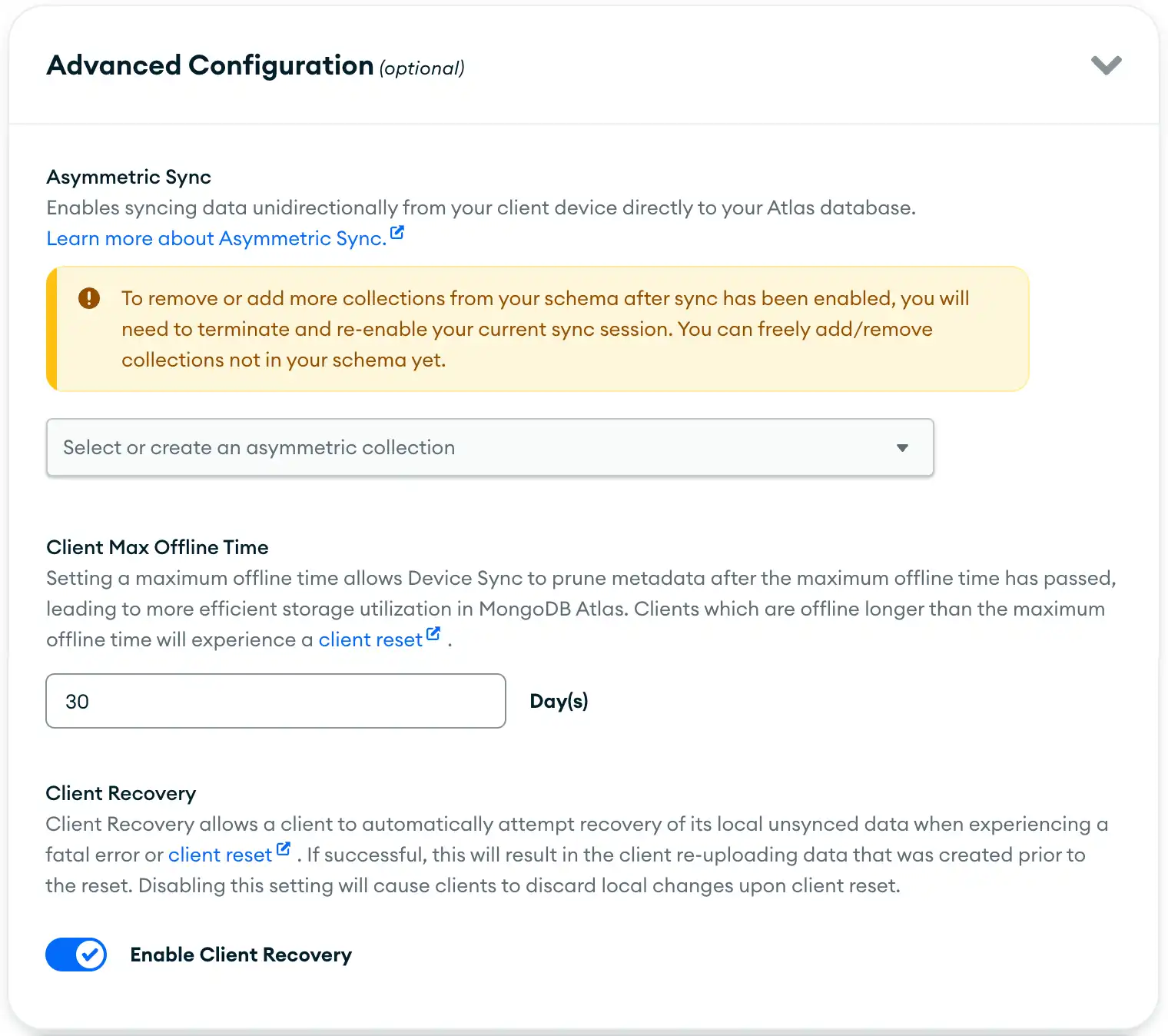
Advanced Configuration (optional) 섹션까지 아래로 스크롤하고 드롭다운을 클릭하여 섹션을 확장합니다.
![App Services UI 의 고급 구성 섹션]()
Client Max Offline Time 섹션에서 애플리케이션의 클라이언트 최대 오프라인 시간(일)을 지정합니다. 기본값 은 30 일입니다. 최소값은 1 입니다.
저장할 준비가 되면 화면 하단의 Save Changes 버튼을 클릭합니다.
확인 창에서 Save Changes 버튼을 다시 클릭하여 변경 사항을 확인합니다.

다음 pull 명령을 사용하여 앱 의 최신 버전의 로컬 사본을 가져옵니다.
당기기appservices pull --remote="<Your App ID>" 앱의
sync/config.json파일 에 있는client_max_offline_days속성 을 사용하여 애플리케이션의 클라이언트 최대 오프라인 시간 일수를 구성할 수 있습니다.``sync/config.json``{ "client_max_offline_days": 42, } 다음 푸시 명령을 사용하여 업데이트된 앱 구성을 배포합니다.
푸시appservices push --remote="<Your App ID>"
Flexible Sync 사용 시 성능 및 스토리지 최적화
Flexible Sync 구성의 경우, 사용되는 Atlas 저장 공간의 양은 설정한 쿼리 가능 필드 수에 직접 비례합니다. 쿼리 가능 필드는 지원 Atlas cluster의 스토리지를 사용합니다. 더 많은 쿼리 가능한 필드를 구성할수록 지원 cluster에서 더 많은 스토리지를 사용합니다.
앱에 많은 수의 collection이 있는 경우 여러 collection에서 동일한 쿼리 가능 필드 이름을 사용해야 할 수 있습니다. 이를 권한 과 결합하여 누가 어떤 컬렉션에 액세스할 수 있는지 보다 세부적으로 제어할 수 있습니다.
예시
앱에 20 또는 30개의 collection이 포함될 수 있지만 쿼리 가능한 필드 수를 최소화하려고 합니다. 모든 collection의 객체를 동기화하기 위해 collection 간에 전역 쿼리 가능 필드 를 재사용할 수 있습니다. 예를 들어, owner_id 는 여러 collection에서 쿼리하려는 필드일 수 있습니다.
또는 여러 collection에 owner_id 가 있을 수 있지만 하나의 collection에서만 쿼리하면 됩니다. 이 경우 owner_id collection을 쿼리 가능 필드 로 만들 수 있습니다. 즉, 동기화는 이 필드를 쿼리하지 않는 모든 collection에 대한 메타데이터를 저장하는 대신 하나의 collection에 대해 이 필드에 대한 메타데이터만 유지하면 됩니다.
마지막으로 owner_id == user.id 와 같이 기기에서 데이터의 특정 패싯을 쿼리하려는 앱의 경우 인덱싱된 쿼리 가능 필드 필드를 지정할 수 있습니다. 인덱싱된 쿼리 가능 필드는 클라이언트가 스토어 그룹 또는 단일 사용자와 같은 데이터의 작은 하위 집합만 동기화하면 되는 앱에 더욱 효율적인 성능을 제공합니다.
앱당 하나의 인덱싱된 쿼리 가능 필드를 가질 수 있습니다. 인덱싱된 쿼리 가능 필드는 동기화하는 각 collection에 동일한 적격 데이터 유형이 존재하고 사용해야 하는 글로벌 쿼리 가능 필드 입니다.
자세한 내용은 쿼리 가능 필드 범위 및 인덱싱된 쿼리 가능 필드를 참조하세요.
최상의 성능을 위해 광범위한 쿼리로 동기화된 영역을 엽니다. 그런 다음 좀 더 세분화된 쿼리를 추가하여 클라이언트 애플리케이션에 대상 데이터 세트를 노출합니다. 광범위한 쿼리에서 작업 세트를 분리하면 더 세분화된 쿼리를 사용하여 동기화된 영역을 여러 개 여는 것보다 더 나은 성능을 제공합니다.
쿼리 가능 필드를 구성할 때는 동기화에 사용하는 광범위한 쿼리를 고려하고 이러한 광범위한 쿼리를 지원하는 필드를 더 적게 선택합니다.
예시
할 일 목록 앱에서 동기화 쿼리로는 assignee == currentUser 또는 projectName == selectedProject 와 같은 광범위한 쿼리를 선호합니다. 이렇게 하면 문서를 동기화할 수 있는 몇 가지 광범위한 필드가 제공됩니다. 클라이언트에서는 특정 우선순위나 완료 상태의 작업에 대한 쿼리를 더욱 세분화하여 작업 세트를 분할할 수 있습니다.
요약
Realm Mobile Sync는 동기화된 Atlas cluster의 공간을 사용하여 변경 내역을 저장합니다.
트리밍을 사용하면 Flexible Sync 앱의 공간 사용량이 줄어들지만 클라이언트 최대 오프라인 시간(일)을 초과하여 백엔드에 연결하지 않은 클라이언트에 대해 클라이언트 재설정이 발생할 수 있습니다.
Flexible Sync 구성에 쿼리 가능 필드를 추가하면 Atlas Cluster에서 사용되는 스토리지가 증가합니다. 광범위한 쿼리를 사용하고 광범위한 쿼리를 지원하는 필드를 더 적게 선택하면 스토리지 소비가 줄어듭니다.