는 Data Explorer 데이터를 프로세스 위한 집계 파이프라인 빌더를 제공합니다. 집계 파이프라인은 선택한 파이프라인 단계를 기반으로 문서를 집계된 결과로 변환합니다.
MongoDB Atlas 집계 파이프라인 빌더는 파이프라인을 실행하는 것이 아니라 파이프라인을 빌드하도록 설계되었습니다. 파이프라인 빌더는 드라이버 에서실행할 파이프라인을 쉽게 내보낼 수 있는 방법을 제공합니다.
데이터 액세스
Cloud Manager UI 에서 데이터와 상호 작용 하려면 다음을 수행합니다.
MongoDB Cloud ManagerGo MongoDB Cloud Manager 에서 프로젝트 의 Processes 페이지로 고 (Go) 합니다.
아직 표시되지 않은 경우 탐색 표시줄의 Organizations 메뉴에서 원하는 프로젝트가 포함된 조직을 선택합니다.
아직 표시되지 않은 경우 탐색 표시줄의 Projects 메뉴에서 원하는 프로젝트를 선택합니다.
사이드바에서 Database 제목 아래의 Processes를 클릭합니다.
프로세스 페이지가 표시됩니다.
필수 역할
Data Explorer 에서 집계 파이프라인을 생성하고 실행하려면 최소한 Project Data Access Read Only 역할 부여받아야 합니다.
파이프라인에서 $out 단계를 활용하려면 최소한 Project Data Access Read/Write 역할을 부여받아야 합니다.
집계 파이프라인 빌더에 액세스하기

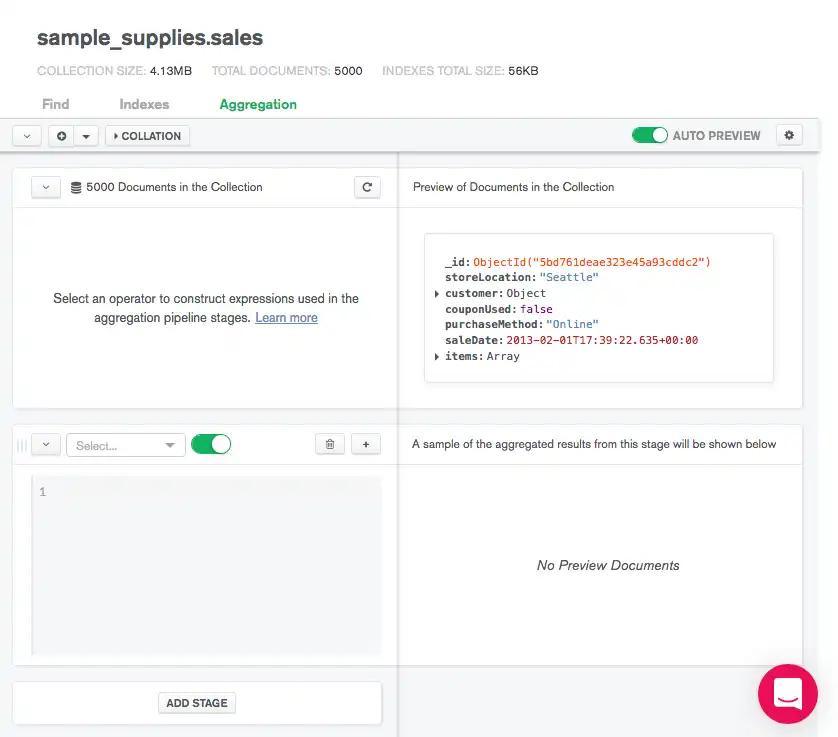
집계 파이프라인 만들기

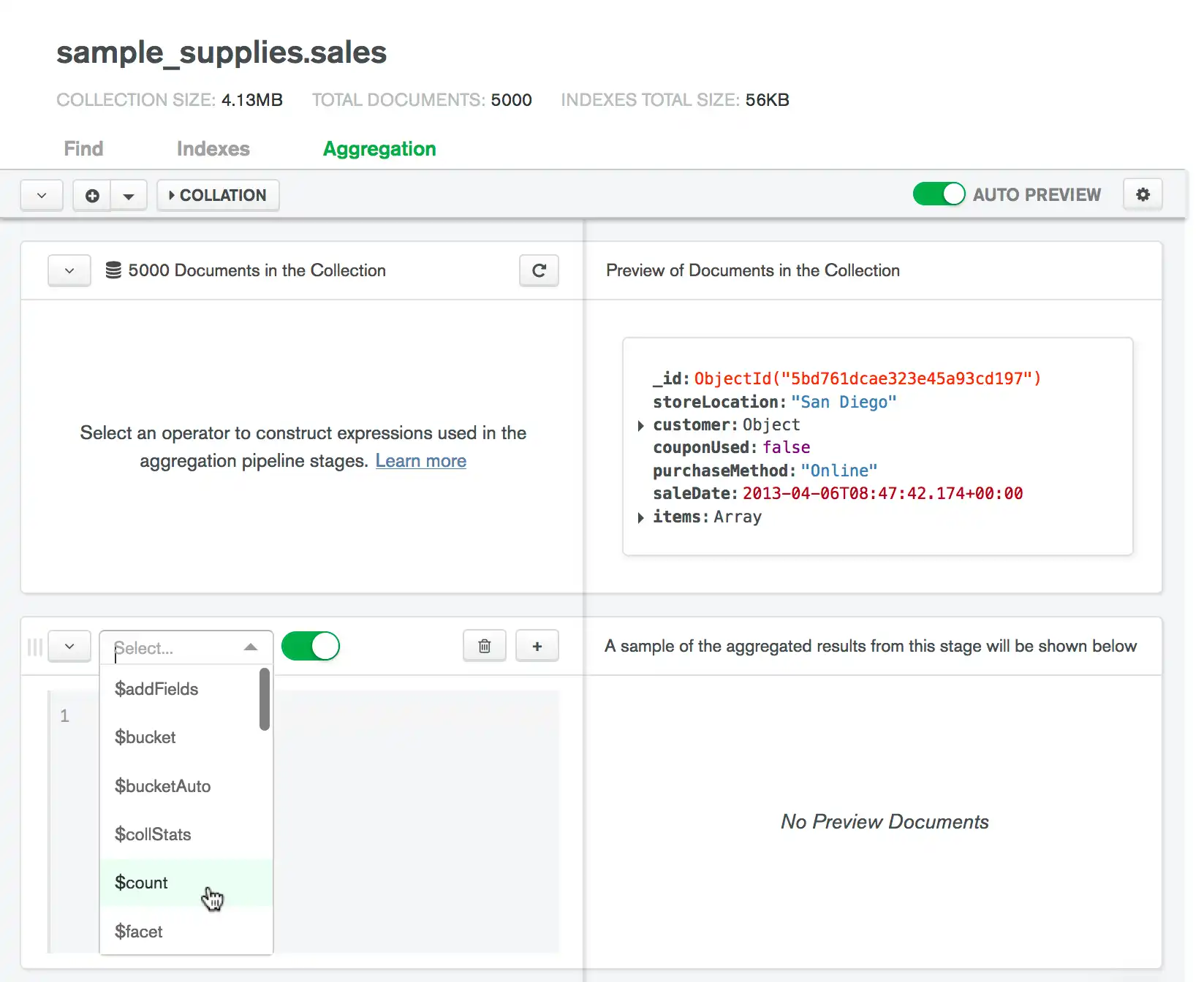
집계 단계를 입력합니다.
적절한 값으로 단계를 채웁니다. 댓글 모드가 활성화된 경우 파이프라인 빌더는 선택한 단계에 대한 구문 지침을 제공합니다.
단계를 수정하면 Data Explorer 가 현재 단계의 결과를 기반으로 오른쪽에 있는 미리보기 문서를 업데이트합니다.

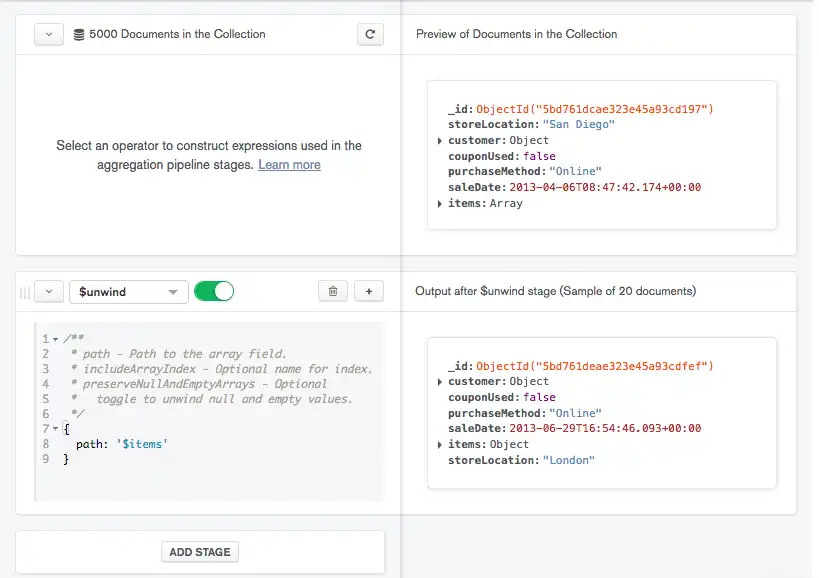

데이터 정렬
데이터 정렬을 이용하여 문자열 비교를 위한 언어별 규칙(예: 대소문자 및 악센트 표기 규칙)을 지정할 수 있습니다.
데이터 정렬 문서를 지정하려면 파이프라인 빌더 상단에서 Collation 을 클릭합니다.
데이터 정렬 문서에는 다음과 같은 필드가 있습니다.
{ locale: <string>, caseLevel: <boolean>, caseFirst: <string>, strength: <int>, numericOrdering: <boolean>, alternate: <string>, maxVariable: <string>, backwards: <boolean> }
locale 필드는 필수이며 다른 모든 데이터 정렬 필드는 선택 사항입니다. 필드에 대한 설명은 데이터 정렬 문서를 참조하세요.
텍스트에서 집계 파이프라인 가져오기
집계 파이프라인을 일반 텍스트에서 파이프라인 빌더를 사용하여 파이프라인을 쉽게 수정하고 확인할 수 있습니다.
일반 텍스트에서 파이프라인을 가져오기 위해선 다음을 수행해야 합니다:

대화 상자에 파이프라인을 입력하거나 붙여넣습니다.
파이프라인이 db.collection.aggregate() 메서드의 pipeline 매개변수 구문과 일치해야 합니다.
파이프라인 초기화
파이프라인을 초기의 빈 상태로 되돌리려면 파이프라인 빌더 맨 위에 있는 더하기 아이콘을 클릭합니다.
집계 파이프라인을 드라이버 언어로 내보내기
집계 파이프라인 빌더를 사용하여 완성된 파이프라인을 지원되는 드라이버 언어 중 하나인 Java, Node, C# 및 Python 3 중 하나로 내보낼 수 있습니다. 이 기능을 사용하여 애플리케이션에서 사용할 파이프라인을 포맷하고 내보낼 수 있습니다.
집계 파이프라인을 내보내려면 다음 단계를 따르세요.
집계 파이프라인을 구축합니다.
집계 파이프라인 생성에 대한 지침은 집계 파이프라인 생성을 참조하세요.
원하는 내보내기 언어를 선택합니다.
Export Pipeline To 드롭다운에서 원하는 언어를 선택합니다.
왼쪽의 My Pipeline 창에는 파이프라인이 mongosh 구문으로 표시됩니다.
파이프라인이 오른쪽 창에 선택된 언어로 표시됩니다.
집계 파이프라인 설정
집계 파이프라인 빌더 설정을 수정하려면 다음을 수행해야 합니다.

