Schema 탭은 컬렉션에 있는 필드의 데이터 유형과 형태에 대한 개요를 제공합니다. 데이터베이스와 컬렉션은 왼쪽 탐색에서 볼 수 있습니다.
개요는 컬렉션의 문서를 샘플링한 것을 기반으로 합니다. 스키마 개요에는 날짜 및 정수의 최소값과 최대값, 특정 값의 발생 빈도, 데이터의 카디널리티와 같은 필드 내용에 대한 추가 데이터가 포함될 수 있습니다.
MongoDB는 유연한 스키마 모델 을 사용하기 때문에 일부 필드에는 문서마다 다른 유형의 데이터가 포함될 수 있습니다. 예를 들어 address 필드의 경우 일부 문서에는 문자열과 정수가, 다른 문서에는 객체가 또는 이 세 가지 모두의 조합이 포함될 수 있습니다.
유형이 다른 필드의 경우 Schema 탭에는 필드에 포함된 다양한 데이터 유형의 분석과 각 데이터 유형의 백분율이 표시됩니다.
예시
Schema 탭에는 컬렉션에 포함된 총 문서 수, 평균 문서 크기 및 컬렉션이 차지하는 총 디스크 공간 등 test.restaurants 컬렉션에 대한 크기 정보를 맨 위에 표시합니다.
다음 필드에 세부 정보가 표시됩니다:
_id필드는 ObjectId입니다. 각 ObjectId에는 타임스탬프가 포함되어 있으므로 Compass는 샘플링된 문서의 생성 시간 범위를 표시합니다.address필드에는 4개의 중첩된 필드가 포함되어 있습니다. 필드 패널을 확장하여 각 중첩 필드에 대한 분석을 볼 수 있습니다.borough필드에는 식당이 위치한 자치구를 나타내는 문자열이 포함되어 있습니다. 카디널리티가 아주 낮으면 Compass에서 필드 콘텐츠의 등급별 막대를 제공할 수 있으며 가장 빈번하게 발생하는 문자열이 왼쪽에 표시됩니다.grades필드에 문자열 배열이 포함되어 있습니다. 이 분석에는 최소, 최대 및 평균 배열 길이가 표시됩니다.
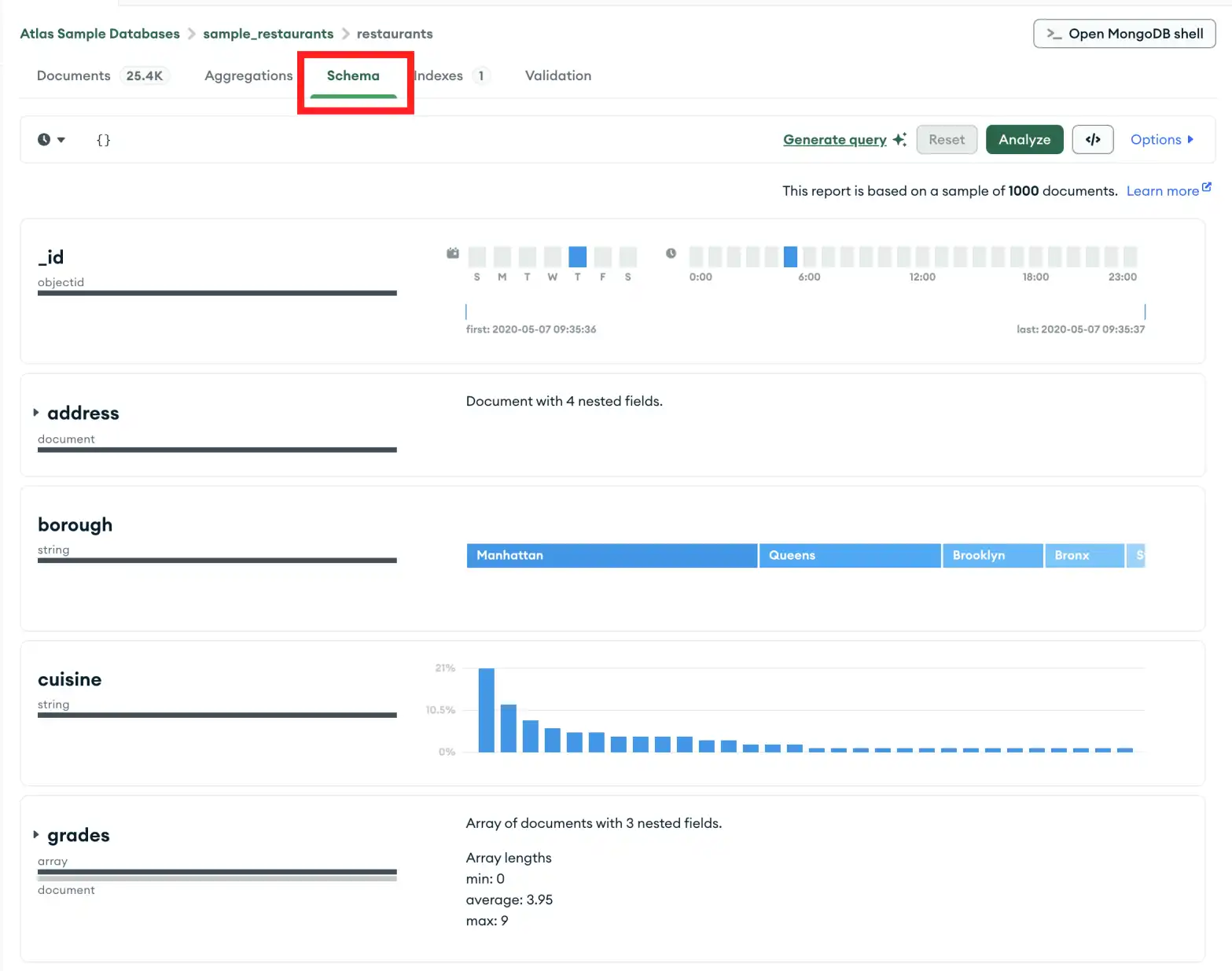
쿼리 표시줄
Schema 탭의 쿼리 표시줄을 사용하여 결과 집합을 제한하는 쿼리 필터를 만들 수 있습니다. 표시할 특정 필드 및 반환할 결과 수와 같은 쿼리 옵션을 지정하려면 Options 버튼을 클릭하세요.
참고
1,000개 이상의 문서로 구성된 쿼리 결과 집합의 경우 Compass는 결과의 하위 집합을 표시합니다. 그렇지 않으면 Compass는 전체 결과 세트를 표시합니다.
샘플링에 대한 자세한 내용은 샘플링을 참조하세요.

팁
Schema 탭에서 쿼리 작성기를 사용하여 쿼리 표시줄에 쿼리를 입력할 수도 있습니다.
필드 설명
Compass는 각 필드에 대해 필드에 포함된 데이터 유형 및 값의 범위에 대한 요약 정보를 표시합니다. Compass는 데이터 유형과 카디널리티 수준에 따라 히스토그램, 그레이드 막대, 지리 지도 및 샘플 데이터를 표시하여 각 필드에 포함된 데이터의 형태와 범위를 파악할 수 있습니다.
단일 데이터 유형이 있는 필드
다음은 date 유형의 데이터가 포함된 last_login 필드에 대한 데이터 유형 요약의 예입니다.


여러 데이터 유형이 있는 필드
여러 데이터 유형이 포함된 필드의 경우 Compass는 문서 전체의 다양한 데이터 유형에 대한 백분율 분석을 표시합니다. 아래 예시에서 차트는 phone_no 필드의 콘텐츠 분석을 보여줍니다. 문서의 20%가 int32 유형이고 나머지 80%가 string 유형임을 알 수 있습니다.


누락된 필드
컬렉션에 일부 필드의 값이 누락된 상태의 문서가 포함된 경우 누락된 값은 undefined로 표시됩니다. 아래 예에서 age 필드에는 샘플링된 문서의 40%에 기록된 값이 없습니다.

문자열
문자열은 세 가지 방식으로 표시될 수 있습니다. 필드에 완전히 고유한 문자열이 있는 경우 Compass는 지정된 필드에서 무작위로 선택한 문자열 값을 표시합니다. 필드에서 무작위로 선택된 새로운 세트를 보려면 동그란 새로 고침 아이콘을 클릭하세요.


서로 다른 문자열 값이 소수만 존재하는 경우, Compass는 문자열 값의 전체 집단 중 해당 값을 차지하는 비율을 보여주는 단일 등급 막대로 문자열을 표시합니다.


일부 중복되는 문자열 값이 여러 개 있는 경우 Compass는 필드 내에서 발견된 각 문자열의 빈도를 나타내는 히스토그램을 표시합니다.


참고
각 막대 위로 마우스를 올리면 해당 문자열 값이 표시되는 툴팁이 나타납니다.
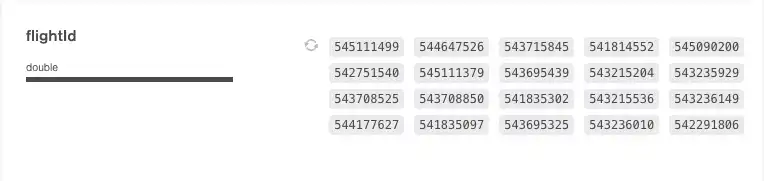
숫자
숫자는 문자열과 표현 방식이 비슷합니다. 고유 번호는 다음과 같은 방식으로 표시됩니다:

중복되는 번호는 해당 빈도를 나타내는 히스토그램으로 표시됩니다:


날짜 및 객체 ID
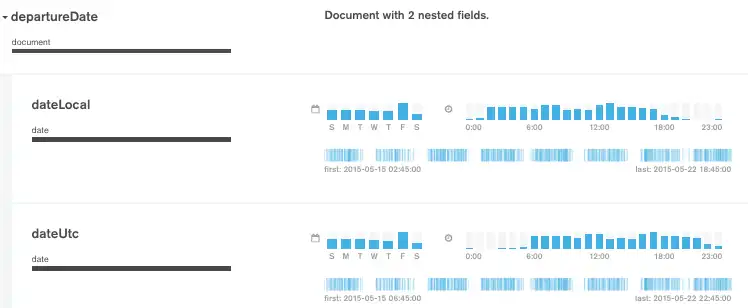
날짜를 나타내는 필드(및 타임스탬프를 포함하는 ObjectID 데이터 유형을 포함하는 필드)는 여러 막대형 차트에 표시됩니다. 맨 위 행의 두 차트는 타임스탬프 값의 요일과 시간을 나타냅니다.
하단의 단일 차트는 첫 번째 및 마지막 타임스탬프 값을 보여 주고, 수직선은 처음부터 마지막 타임스탬프 범위에 걸친 타임스탬프의 분포를 나타냅니다.


내장된 문서 및 배열
하위 문서나 배열이 포함된 필드는 필드 옆에 작은 삼각형이 표시되고 하위 문서나 배열에 포함된 데이터를 시각적으로 표현합니다.


삼각형을 클릭하여 필드를 확장하고 내장된 문서를 봅니다.

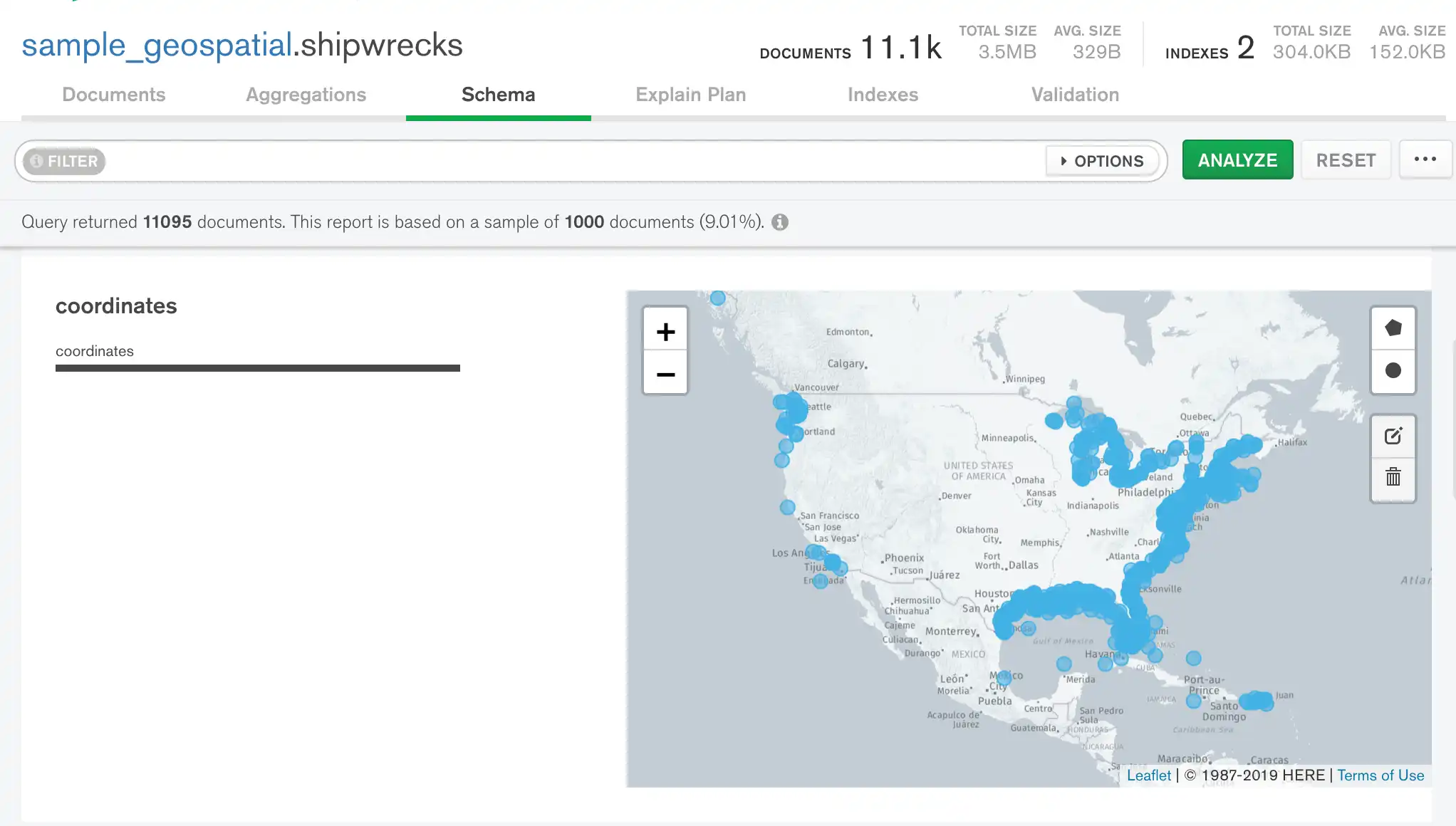
GeoJSON 및 [longitude,latitude] 배열
GeoJSON 데이터 또는 [longitude,latitude] 배열이 포함된 필드는 대화형 맵과 함께 표시됩니다. Compass에서 위치 데이터와 상호 작용하는 방법에 대한 자세한 내용은 위치 데이터 분석을 참조하세요.

참고
타사 매핑 서비스는 Compass Isolated Edition에서 사용할 수 없습니다.
혼합 유형 Charts 보기
필드에 혼합된 유형이 포함된 경우 type 필드를 클릭하면 각 유형의 다양한 차트를 볼 수 있습니다. 아래 예에서 age 필드에는 문자열인 값이 표시됩니다.


int32 유형을 클릭하면 차트에 해당 숫자 데이터가 표시됩니다:

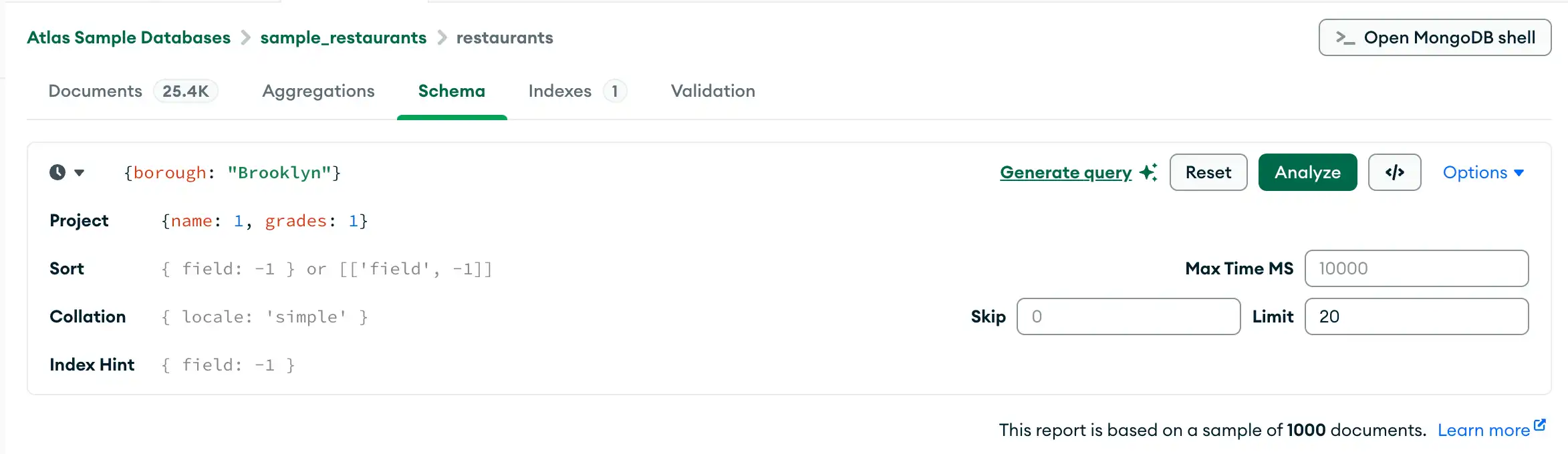
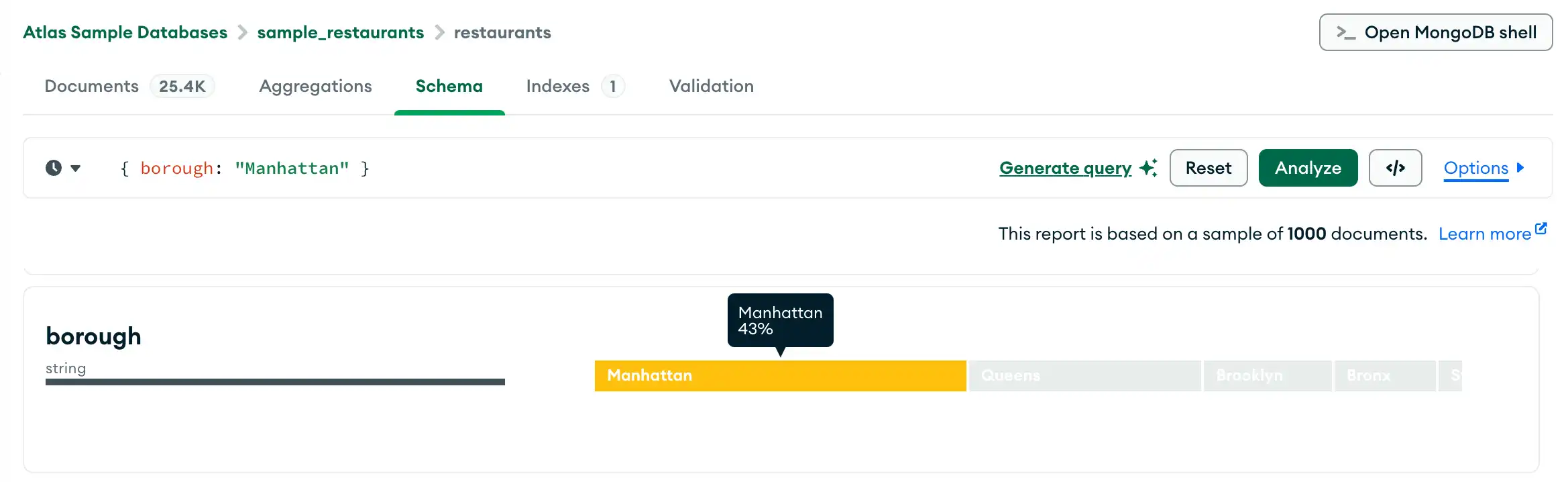
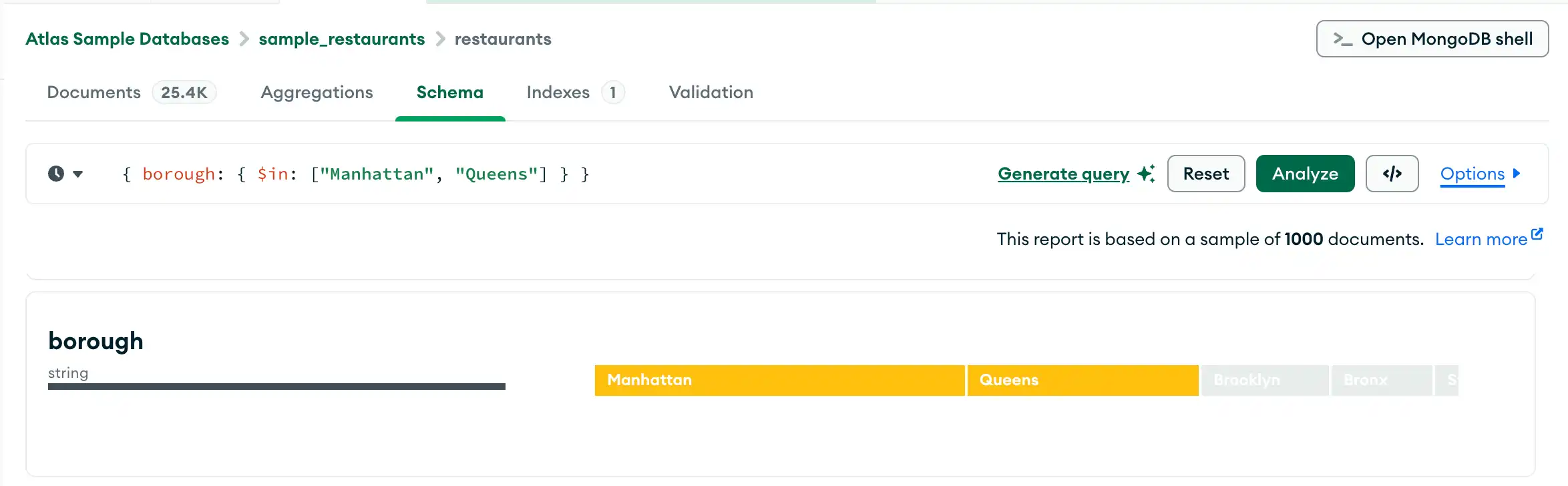
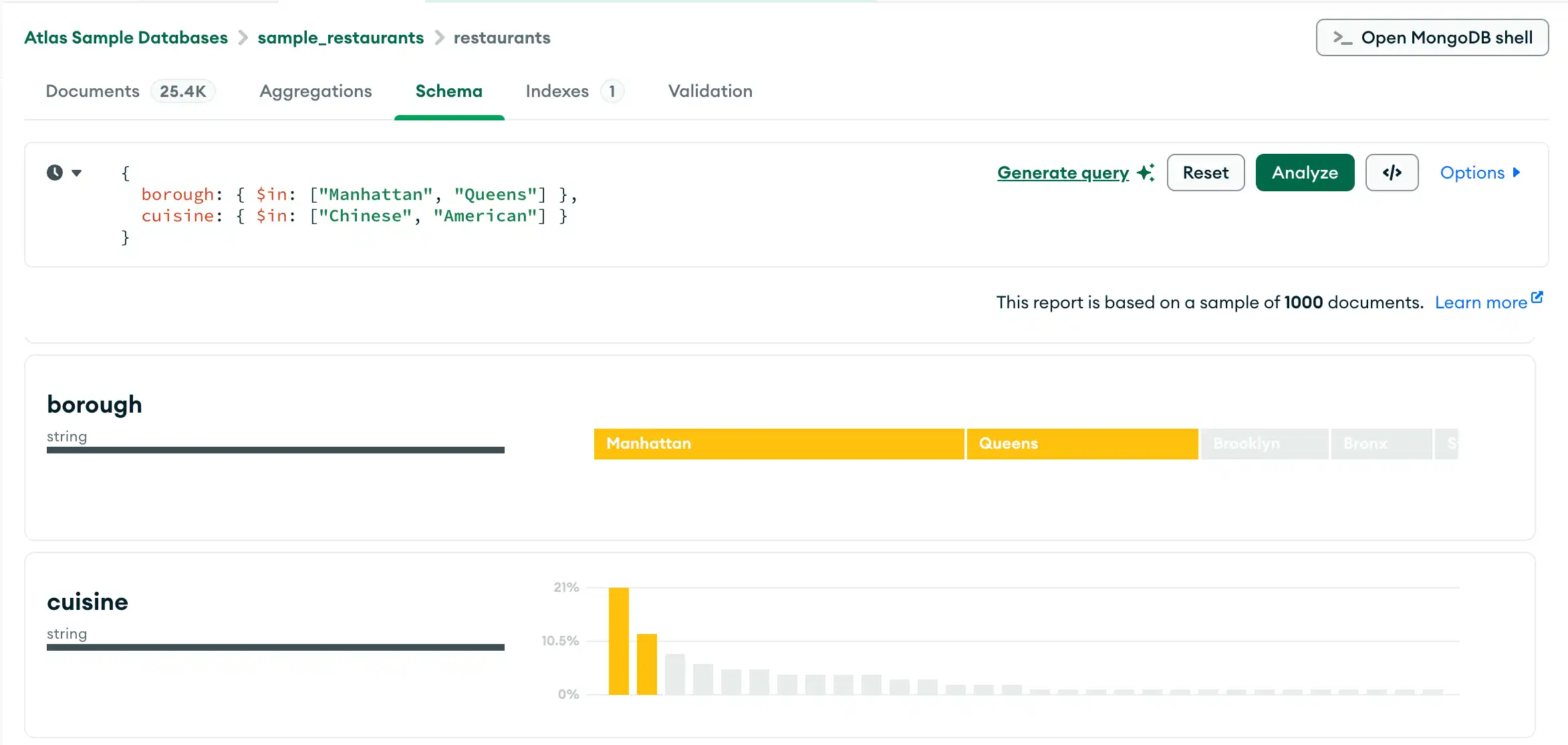
쿼리 빌더
Schema 탭에서는 쿼리 바에 필터를 직접 입력하거나 Compass 쿼리 빌더를 사용하여 필터를 생성할 수 있습니다. 쿼리 빌더를 사용하면 스키마의 하나 이상의 필드에서 데이터 요소를 선택하고 선택된 요소와 일치하는 쿼리를 구성할 수 있습니다.
팁
클릭 가능한 쿼리 빌더를 사용하여 초기 쿼리 필터를 작성한 다음, 생성된 필터를 정확한 요구 사항에 맞게 수동으로 편집할 수 있습니다.
다음 절차에서는 쿼리 표시줄을 사용하여 복잡한 쿼리를 작성하는 단계에 대해 설명합니다.




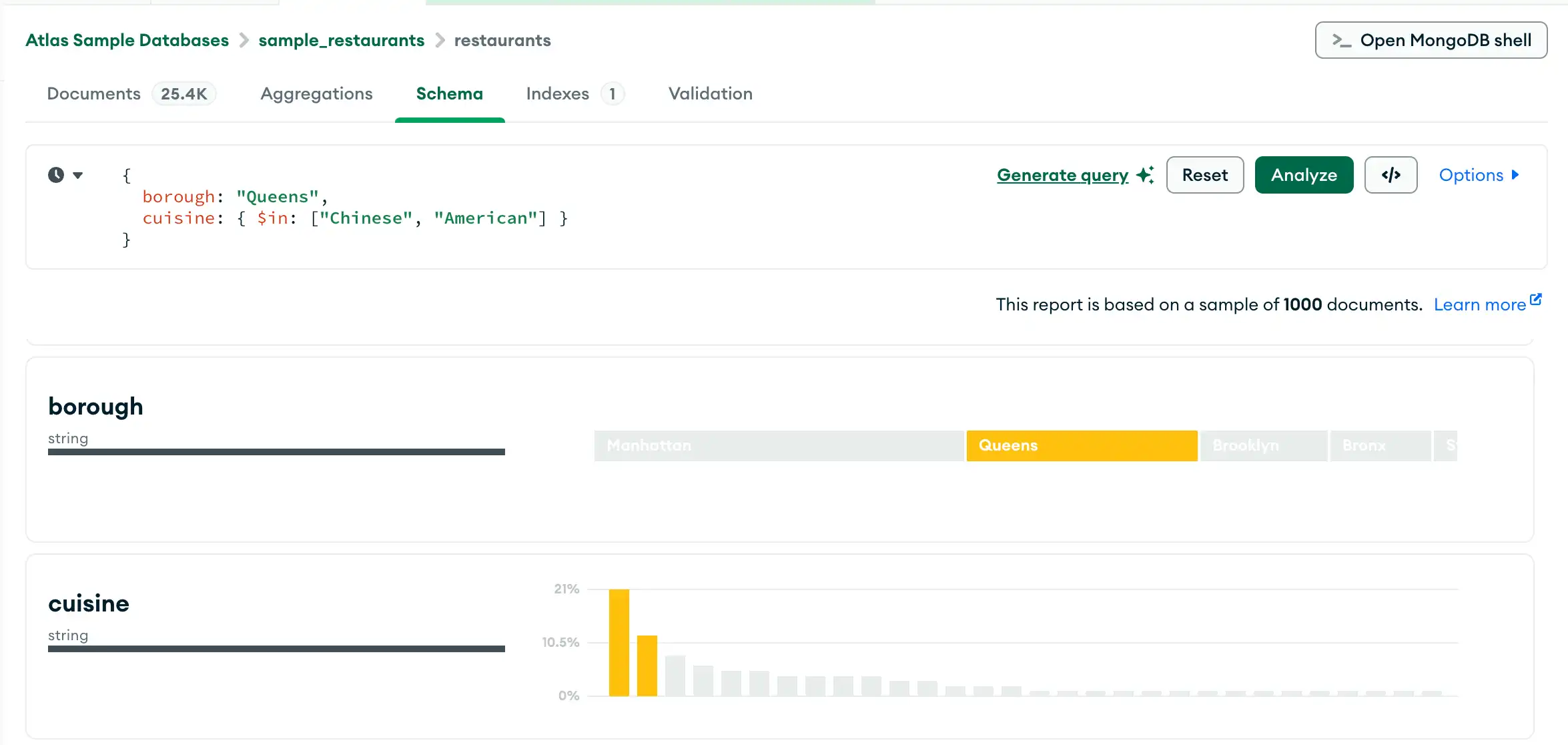
위치 데이터 분석
Schema 탭에서 대화형 맵을 사용하여 위치 데이터를 필터링하고 분석할 수 있습니다. 필드에 GeoJSON 데이터 또는 [longitude,latitude] 배열이 포함된 경우 Schema 탭에 필드의 점이 포함된 맵이 표시됩니다. 위치 필드의 데이터 유형은 coordinates입니다.

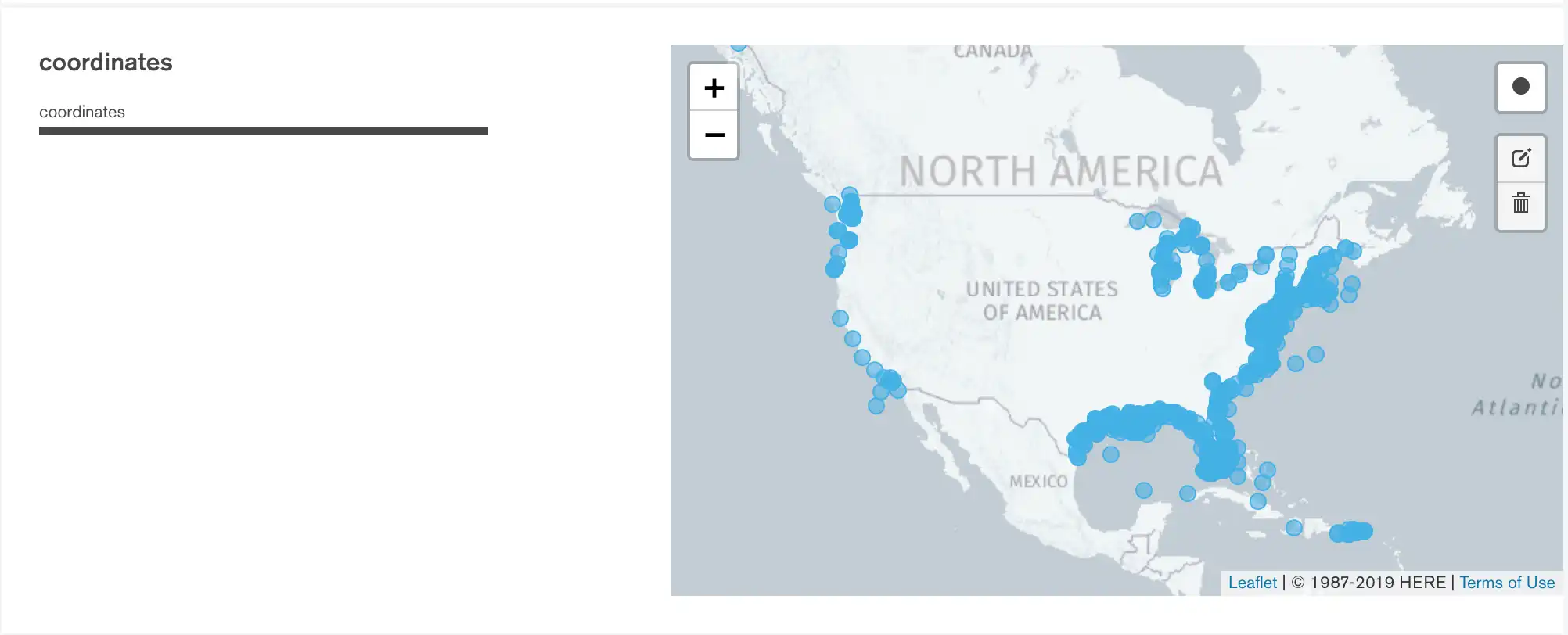
위치 필터 적용
맵에 필터를 적용하여 포인트의 특정 범위만 분석할 수 있습니다. 위치 필터를 정의하려면 다음을 따릅니다:
맵 오른쪽 상단의 Circle 버튼을 클릭합니다.
맵을 클릭하고 드래그하여 분석하려는 맵 영역을 포함하는 원을 그립니다.
스키마 분석에 맵의 추가 영역을 포함하려면 원하는 대로 이 프로세스를 반복합니다.

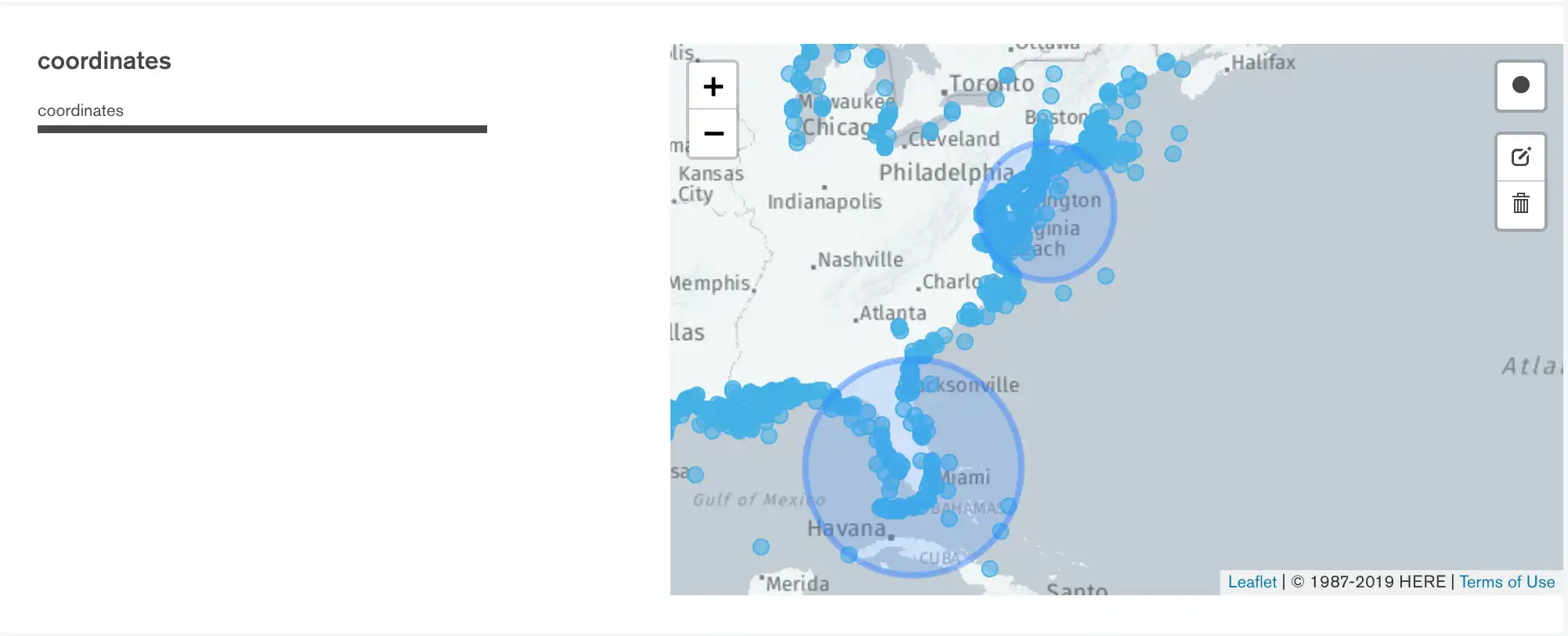
위치 필터를 그리면 쿼리 표시줄이 업데이트되어 스키마 분석에 적용된 $geoWithin 쿼리에 사용된 정확한 좌표가 표시됩니다.
여러 위치 필터를 지정하는 경우 쿼리는 여러 $geoWithin 연산자를 사용하는 $or 쿼리가 됩니다.
위치 필터 편집
위치 필터를 이동하거나 크기를 조정하려면 맵 오른쪽에 있는 을 클릭합니다. 다음과 같은 필터 편집 모드로 들어갑니다.

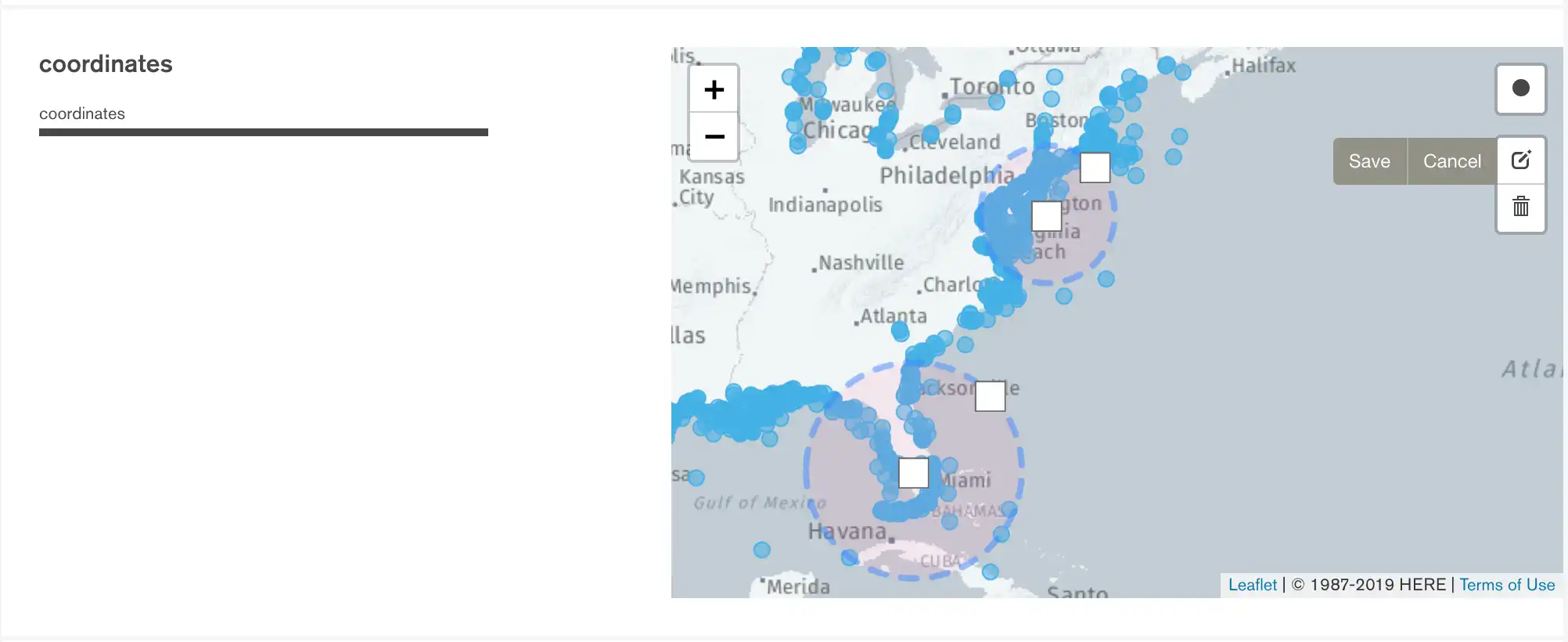
- 필터를 이동하려면 다음과 같이 하세요.
- 원 중앙에 있는 사각형을 클릭하고 드래그합니다.
- 필터 크기를 조정하려면 다음과 같이 하세요.
- 원 가장자리에 있는 사각형을 클릭하고 드래그합니다.
필터를 수정한 후 Save를 클릭합니다.
위치 필터 삭제
지도에서 위치 필터를 삭제하려면 다음과 같이 합니다:
지도의 오른쪽을 클릭합니다.
둘 하나를 클릭합니다:
해당 필터를 삭제할 위치 필터입니다.
Clear All 을(를) 클릭하여 모든 위치 필터를 삭제합니다.
Save를 클릭합니다.
문제 해결
스키마 분석 시간이 초과된 경우, 그 이유는 분석 중인 컬렉션이 너무 커서 분석이 완료되기 전에 MongoDB가 작업을 중지하기 때문일 수 있습니다. 작업 시간이 끝날 수 있도록 MAX TIME MS 값을 올리세요.
MAX TIME MS의 값을 늘리려면:
쿼리 표시줄에서 Options을(를) 확장합니다.
![옵션 단추는 쿼리 바의 오른쪽에서 분석 단추 옆에 있습니다.]()
컬렉션을 수용하기 위해 MAX TIME MS 의 값을 높입니다. MAX TIME MS 기본값은 60000밀리초 또는 60초이지만 대규모 컬렉션은 분석하는 데 수십 초가 걸릴 수 있습니다.

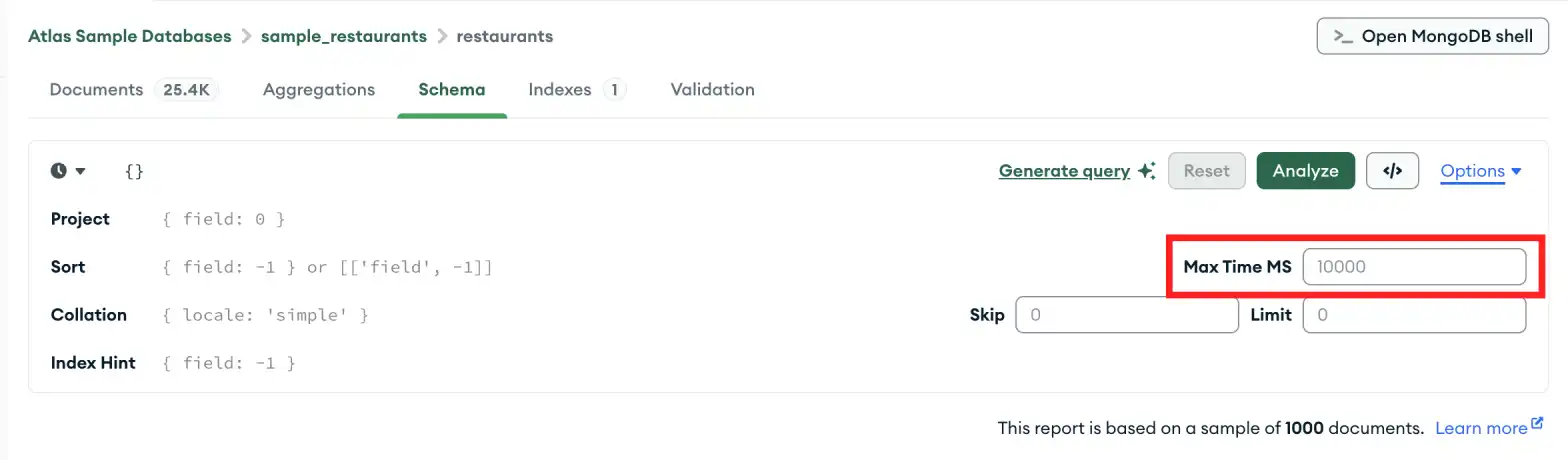
MAX TIME MS의 값을 늘린 후 Analyze를 클릭하여 스키마 분석을 다시 시도합니다.