GridFS.
이 페이지의 내용
개요
이 가이드에서는 GridFS를 사용하여 MongoDB에서 대용량 파일을 저장하고 조회하는 방법에 대해 설명합니다. GridFS는 파일을 저장할 때 청크로 분할하고 검색할 때 다시 조립하는 방법을 설명하는 드라이버에 의해 구현된 사양입니다. GridFS의 드라이버 구현은 파일 스토리지의 운영과 구성을 관리하는 추상화입니다.
파일 크기가 BSON 문서 크기 제한인 16MB를 초과하는 경우 GridFS 를 사용해야 합니다. GridFS 가 사용 사례 에 적합한지 여부에 대한 자세한 내용은 GridFS 서버 매뉴얼 페이지를 참조하세요.
GridFS 작업과 이를 수행하는 방법을 설명하는 다음 섹션을 참조하세요.
GridFS 작동 방식
GridFS는 파일 청크와 파일을 설명하는 정보가 들어 있는 MongoDB 컬렉션 그룹인 버킷에 파일을 구성합니다. 버킷에는 GridFS 사양에 정의된 규칙을 사용하여 명명된 다음 컬렉션이 포함되어 있습니다.
chunks컬렉션은 바이너리 파일 청크를 저장합니다.files0} 컬렉션에 파일 메타데이터가 저장됩니다.
새 GridFS 버킷을 생성하면 운전자 는 다른 이름을 지정하지 않는 한 기본값 버킷 이름 fs 접두사 앞에 앞의 컬렉션을 생성합니다. 또한 운전자 는 파일 및 관련 메타데이터 를 효율적으로 검색할 수 있도록 각 컬렉션 에 인덱스 를 생성합니다. 운전자 는 GridFS 버킷이 아직 존재하지 않는 경우 첫 번째 쓰기 (write) 작업 시에만 GridFS 버킷을 생성합니다. 운전자 는 인덱스가 존재하지 않거나 버킷이 비어 있는 경우에만 인덱스를 생성합니다. GridFS 인덱스에 대한 자세한 내용은 GridFS 인덱스에 대한 서버 매뉴얼 페이지를 참조 GridFS .
GridFS로 파일을 저장할 때 드라이버는 파일을 작은 청크로 분할하며, 각각의 청크는 chunks 컬렉션에서 별도의 문서로 표시됩니다. 또한 files 컬렉션에 파일 ID, 파일 이름 및 기타 파일 메타데이터가 포함된 문서를 만듭니다. 메모리 또는 스트림에서 파일을 업로드할 수 있습니다. 버킷에 업로드할 때 GridFS가 파일을 분할하는 방법을 보려면 다음 다이어그램을 참조하세요.

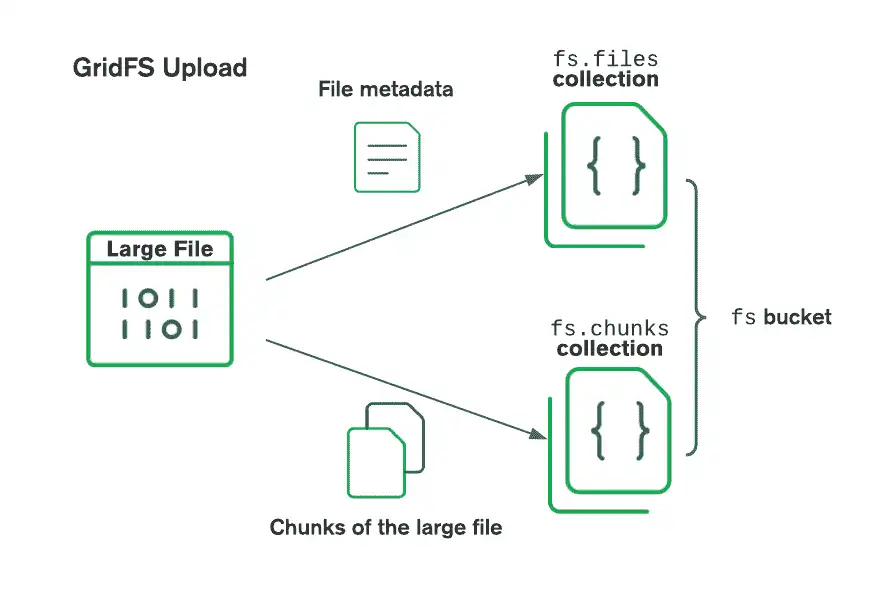
파일을 검색할 때 GridFS는 지정된 버킷의 files 컬렉션에서 메타데이터를 가져와서 이 정보를 사용하여 chunks 컬렉션의 문서에서 파일을 재구성합니다. 파일을 메모리로 읽거나 스트림으로 출력할 수 있습니다.
GridFS 버킷 만들기
GridFS에서 파일을 조회하거나 저장하려면 버킷을 만들거나 MongoDB 데이터베이스에서 기존 버킷에 대한 참조를 가져오면 됩니다. MongoDatabase 인스턴스를 매개 변수로 사용하여 GridFSBuckets.create() 헬퍼 메서드를 호출하여 GridFSBucket을 인스턴스화합니다. GridFSBucket 인스턴스를 사용하여 버킷의 파일에서 읽기 및 쓰기 작업을 호출할 수 있습니다.
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database);
기본 이름인 fs 이외의 사용자 지정 이름으로 버킷을 만들거나 참조하려면 아래와 같이 버킷 이름을 두 번째 매개 변수로 create() 메서드에 전달합니다.
GridFSBucket gridFSBucket = GridFSBuckets.create(database, "myCustomBucket");
참고
create()를 호출할 때 버킷이 존재하지 않으면 MongoDB가 버킷을 만들지 않습니다. 대신, 첫 번째 파일을 업로드할 때와 같이 필요에 따라 버킷을 생성합니다.
이 섹션에 언급된 클래스 및 메서드에 대한 자세한 내용은 다음 API 설명서를 참조하세요.
파일 저장
GridFS 버킷에 파일을 저장하려면 InputStream 인스턴스에서 파일을 업로드하거나 해당 데이터를 GridFSUploadStream에 기록하면 됩니다.
둘 중 어떤 업로드 프로세스에서든, 메타데이터로 저장할 파일 청크 크기 및 기타 필드/값 쌍과 같은 구성 정보를 지정할 수 있습니다. 다음 코드 스니펫에 표시된 대로 GridFSUploadOptions 인스턴스에서 이 정보를 설정합니다.
GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) // 1MB chunk size .metadata(new Document("myField", "myValue"));
자세한 내용은 GridFSUploadOptions API 설명서를 참조하세요.
중요
MAJORITY 쓰기 고려 사용
GridFS 버킷에 파일을 저장할 때는 WriteConcern.MAJORITY 쓰기 고려를 사용해야 합니다. 다른 쓰기 고려를 지정하면 GridFS 파일 업로드 중에 발생하는 복제본 세트 투표로 인해 업로드 프로세스가 중단되어 일부 파일 청크가 손실될 수 있습니다.
쓰기 고려에 대한 자세한 내용은 MongoDB Server 매뉴얼의 쓰기 고려 페이지를 참조하세요.
입력 스트림을 사용하여 파일 업로드
이 섹션에서는 입력 스트림을 사용하여 GridFS 버킷에 파일을 업로드하는 방법을 보여줍니다. 다음 코드 예시에서는 FileInputStream을 사용하여 파일 시스템의 파일에서 데이터를 읽고 다음 작업을 수행하여 GridFS에 업로드하는 방법을 보여 줍니다.
FileInputStream을 사용하여 파일 시스템에서 읽기.GridFSUploadOptions를 사용하여 청크 크기 설정.type이라는 사용자 지정 메타데이터 필드를 'zip archive' 값으로 설정.GridFS 파일 이름을 'myProject.zip'으로 지정하여
project.zip이라는 파일 업로드.
String filePath = "/path/to/project.zip"; try (InputStream streamToUploadFrom = new FileInputStream(filePath) ) { // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); // Uploads a file from an input stream to the GridFS bucket ObjectId fileId = gridFSBucket.uploadFromStream("myProject.zip", streamToUploadFrom, options); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + fileId.toHexString()); }
이 코드 예시에서는 업로드된 파일이 GridFS에 성공적으로 저장되면 해당 파일의 파일 ID를 출력합니다.
출력 스트림을 사용하여 파일 업로드
이 섹션에서는 출력 스트림에 기록하여 GridFS 버킷에 파일을 업로드하는 방법을 보여줍니다. 다음 코드 예시에서는 아래 작업을 수행해서 GridFSUploadStream에 기록하여 GridFS에 데이터를 보내는 방법을 보여줍니다.
'project.zip'이라는 파일을 파일 시스템에서 바이트 배열로 읽습니다.
GridFSUploadOptions를 사용하여 청크 크기 설정.type이라는 사용자 지정 메타데이터 필드를 'zip archive' 값으로 설정.바이트를
GridFSUploadStream에 기록하고 파일 이름 'myProject.zip'으로 지정합니다. 스트림은chunkSize설정에 지정된 한도에 도달할 때까지 데이터를 버퍼에 입력하고chunks컬렉션에 새 청크로 삽입합니다.
Path filePath = Paths.get("/path/to/project.zip"); byte[] data = Files.readAllBytes(filePath); // Defines options that specify configuration information for files uploaded to the bucket GridFSUploadOptions options = new GridFSUploadOptions() .chunkSizeBytes(1048576) .metadata(new Document("type", "zip archive")); try (GridFSUploadStream uploadStream = gridFSBucket.openUploadStream("myProject.zip", options)) { // Writes file data to the GridFS upload stream uploadStream.write(data); uploadStream.flush(); // Prints the "_id" value of the uploaded file System.out.println("The file id of the uploaded file is: " + uploadStream.getObjectId().toHexString()); // Prints a message if any exceptions occur during the upload process } catch (Exception e) { System.err.println("The file upload failed: " + e); }
이 코드 예시에서는 업로드된 파일이 GridFS에 성공적으로 저장되면 해당 파일의 파일 ID를 출력합니다.
참고
파일 업로드에 성공하지 못하면 작업에서 예외가 발생하고 업로드된 청크는 분리된 청크가 됩니다. 분리된 청크는 GridFS chunks 컬렉션에 있는 문서 중 GridFS files 컬렉션의 파일 ID를 참조하지 않는 문서입니다. 업로드 또는 삭제 작업이 중단되면 파일 청크가 분리된 청크가 될 수 있습니다. 분리된 청크를 제거하려면 읽기 작업을 사용하여 분리된 청크를 식별하고 쓰기 작업을 사용하여 제거해야 합니다.
파일 정보 검색
이 섹션에서는 GridFS 버킷의 files 컬렉션에 저장된 파일 메타데이터를 검색하는 방법을 알아볼 수 있습니다. 메타데이터에는 다음을 포함하여 참조하는 파일에 대한 정보가 포함됩니다.
파일의 ID
파일 이름
파일의 길이/크기
업로드 날짜 및 시간
다른 정보를 저장할 수 있는
metadata문서입니다.
GridFS 버킷에서 파일을 조회하려면 GridFSBucket 인스턴스에서 find() 메서드를 호출합니다. 이 메서드는 GridFSFindIterable을 반환하며, 이를 통해 결과에 액세스할 수 있습니다.
다음 코드 예시는 GridFS 버킷의 모든 파일에서 파일 메타데이터를 조회하고 출력하는 방법을 보여줍니다. 이 예에서는 GridFSFindIterable에서 조회된 결과를 순회할 수 있는 여러 가지 방법 중 Consumer 함수형 인터페이스를 사용하여 다음 결과를 출력합니다.
gridFSBucket.find().forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
다음 코드 예시에서는 쿼리 필터에 지정된 필드와 일치하는 모든 파일의 파일 이름을 조회하고 출력하는 방법을 보여줍니다. 또한 반환된 GridFSFindIterable에서 sort() 및 limit()를 호출하여 결과의 순서와 최대 개수를 지정합니다.
Bson query = Filters.eq("metadata.type", "zip archive"); Bson sort = Sorts.ascending("filename"); // Retrieves 5 documents in the bucket that match the filter and prints metadata gridFSBucket.find(query) .sort(sort) .limit(5) .forEach(new Consumer<GridFSFile>() { public void accept(final GridFSFile gridFSFile) { System.out.println(gridFSFile); } });
metadata 은 내장된 문서 이므로 쿼리 필터하다 는 점 표기법 을 사용하여 문서 내에서 type 필드 를 지정합니다. 자세한 내용은 임베디드/중첩 문서 쿼리 방법에 대한 서버 매뉴얼 가이드 를 참조하세요.
이 섹션에 언급된 클래스 및 메서드에 대한 자세한 내용은 다음 리소스를 참조하세요.
GridFSFindIterable API 설명서
GridFSBucket.find() API 설명서
파일 다운로드
파일을 GridFS에서 스트림으로 직접 다운로드하거나 스트림에서 메모리에 저장할 수 있습니다. 파일 ID 또는 파일 이름을 사용하여 조회할 파일을 지정할 수 있습니다.
파일 수정본
버킷에 동일한 파일 이름을 공유하는 파일이 여러 개 있는 경우, GridFS는 기본적으로 가장 최근에 업로드된 파일 수정본을 선택합니다. 같은 이름을 공유하는 각 파일을 구분하기 위해 GridFS는 동일한 이름의 파일에 업로드 시간 순으로 수정본 번호를 할당합니다.
원래의 파일 수정본 번호는 '0'이고 그 다음으로 가장 최근의 파일 수정본 번호는 '1'입니다. 수정본의 최신성에 해당하는 음수 값을 지정할 수도 있습니다. 수정본 값이 '-1'이면 가장 최근의 수정본이고 '-2'는 그 다음의 최근 수정본을 의미합니다.
다음 코드 스니펫은 GridFSDownloadOptions 인스턴스에서 파일의 두 번째 수정본을 지정하는 방법을 보여줍니다.
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(1);
수정본 열거에 대한 자세한 내용은 GridFSDownloadOptions 에 대한 API 설명서를 참조하세요.
출력 스트림에 파일 다운로드
GridFS 버킷에 있는 파일을 출력 스트림에 다운로드할 수 있습니다. 다음 코드 예시에서는 downloadToStream() 메서드를 호출하여 'myProject.zip' 파일의 첫 번째 수정본을 OutputStream에 다운로드하는 방법을 보여줍니다.
GridFSDownloadOptions downloadOptions = new GridFSDownloadOptions().revision(0); // Downloads a file to an output stream try (FileOutputStream streamToDownloadTo = new FileOutputStream("/tmp/myProject.zip")) { gridFSBucket.downloadToStream("myProject.zip", streamToDownloadTo, downloadOptions); streamToDownloadTo.flush(); }
이 메서드에 대한 자세한 내용은 downloadToStream() API 문서.
입력 스트림에 파일 다운로드
입력 스트림을 사용하여 GridFS 버킷에 있는 파일을 메모리에 다운로드할 수 있습니다. GridFS 버킷에서 openDownloadStream() 메서드를 호출하여 파일을 읽을 수 있는 입력 스트림인 GridFSDownloadStream을 열 수 있습니다.
다음 코드 예시에서는 fileId 변수가 참조하는 파일을 메모리에 다운로드하고 해당 콘텐츠를 문자열로 출력하는 방법을 보여줍니다.
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Opens an input stream to read a file containing a specified "_id" value and downloads the file try (GridFSDownloadStream downloadStream = gridFSBucket.openDownloadStream(fileId)) { int fileLength = (int) downloadStream.getGridFSFile().getLength(); byte[] bytesToWriteTo = new byte[fileLength]; downloadStream.read(bytesToWriteTo); // Prints the downloaded file's contents as a string System.out.println(new String(bytesToWriteTo, StandardCharsets.UTF_8)); }
이 메서드에 대한 자세한 내용은 openDownloadStream(). API 문서.
파일 이름 바꾸기
rename() 메서드를 호출하여 버킷에 있는 GridFS 파일의 이름을 업데이트할 수 있습니다. 파일 이름이 아닌 파일 ID로 이름을 바꾸도록 파일을 지정해야 합니다.
참고
rename() 메서드는 한 번에 하나의 파일 이름 업데이트만 지원합니다. 여러 파일의 이름을 바꾸려면 버킷에서 파일 이름과 일치하는 파일 목록을 조회하고, 이름을 바꾸려는 파일에서 파일 ID 값을 추출한 다음, rename() 메서드에 각각의 파일 ID를 개별적으로 호출하여 전달합니다.
다음 코드 예에서는 fileId 변수가 참조하는 파일 이름을 'mongodbTutorial.zip'으로 업데이트하는 방법을 보여 줍니다.
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Renames the file that has a specified "_id" value to "mongodbTutorial.zip" gridFSBucket.rename(fileId, "mongodbTutorial.zip");
이 메서드에 대한 자세한 내용은 rename() API 문서.
파일 삭제
delete() 메서드를 호출하여 GridFS 버킷에서 파일을 제거할 수 있습니다. 파일 이름이 아닌 파일 ID로 파일을 지정해야 합니다.
참고
delete() 메서드는 한 번에 하나의 파일 삭제만 지원합니다. 여러 파일을 삭제하려면 버킷에서 파일을 조회하고 삭제하려는 파일에서 파일 ID를 추출한 다음 delete() 메서드에 각각의 파일 ID를 개별적으로 호출하여 전달합니다.
다음 코드 예시에서는 fileId 변수가 참조하는 파일을 삭제하는 방법을 보여줍니다.
ObjectId fileId = new ObjectId("60345d38ebfcf47030e81cc9"); // Deletes the file that has a specified "_id" value from the GridFS bucket gridFSBucket.delete(fileId);
이 메서드에 대한 자세한 내용은 delete() API 문서.
GridFS 버킷 삭제
다음 코드 예시 는 'mydb'라는 데이터베이스 에서 기본값 GridFS 버킷을 삭제 하는 방법을 보여줍니다. 사용자 지정 이름이 지정된 버킷을 참조하려면 이 가이드 의 사용자 지정 버킷을 만드는 방법 섹션을 참조하세요.
MongoDatabase database = mongoClient.getDatabase("mydb"); GridFSBucket gridFSBucket = GridFSBuckets.create(database); gridFSBucket.drop();
이 메서드에 대한 자세한 내용은 drop() API 문서.
추가 리소스
MongoDB Java 드라이버 리포지토리에서 실행 가능한 GridFSTour.java의 예시.