GridFS.
개요
이 가이드에서는 GridFS를 사용하여 MongoDB에 대용량 파일을 저장하고 검색하는 방법을 배울 수 있습니다. GridFS는 저장 중에 파일을 청크로 분할하고 검색 중에 다시 어셈블하는 방법을 설명합니다. GridFS의 드라이버 구현은 파일 스토리지의 운영 및 조직을 관리합니다.
파일 크기가 BSON 문서 크기 제한인 16 메가바이트를 초과하는 경우 GridFS를 사용해야 합니다. GridFS가 사용 사례에 적합한지 여부에 대한 자세한 내용은 GridFS 서버 매뉴얼 페이지를 참조하세요.
GridFS 작업 및 구현에 대해 자세히 알아보려면 다음 섹션을 탐색합니다.
GridFS 작동 방식
GridFS는 파일 청크 및 설명 정보가 포함된 MongoDB 컬렉션의 그룹인 버킷에 파일을 구성합니다. 버킷에는 GridFS 사양에 정의된 규칙을 사용하여 명명된 다음 컬렉션이 포함되어 있습니다.
chunks컬렉션은 바이너리 파일 청크를 저장합니다.files0} 컬렉션에 파일 메타데이터가 저장됩니다.
새 GridFS 버킷을 생성하면 드라이버는 다른 이름을 지정하지 않는 한 기본 버킷 이름 fs 접두사가 붙은 chunks 및 files 컬렉션을 생성합니다. 또한 드라이버는 파일 및 관련 메타데이터를 효율적으로 검색할 수 있도록 각 컬렉션에 인덱스를 생성합니다. 드라이버는 GridFS 버킷이 아직 존재하지 않는 경우 첫 번째 쓰기 작업 시에만 GridFS 버킷을 생성합니다. 드라이버는 인덱스가 존재하지 않거나 버킷이 비어 있는 경우에만 인덱스를 생성합니다. GridFS 인덱스에 대한 자세한 내용은 GridFS 인덱스에 대한 서버 매뉴얼 페이지를 참조 하세요.
GridFS로 파일을 저장할 때 드라이버는 파일을 작은 조각으로 분할하며, 각 조각은 chunks 컬렉션에서 별도의 문서로 표시됩니다. 또한 files 컬렉션에 고유한 파일 ID, 파일 이름 및 기타 파일 메타데이터가 포함된 문서를 만듭니다. 메모리 또는 스트림에서 파일을 업로드할 수 있습니다. 다음 다이어그램은 버킷에 업로드할 때 GridFS가 파일을 분할하는 방법을 설명합니다:

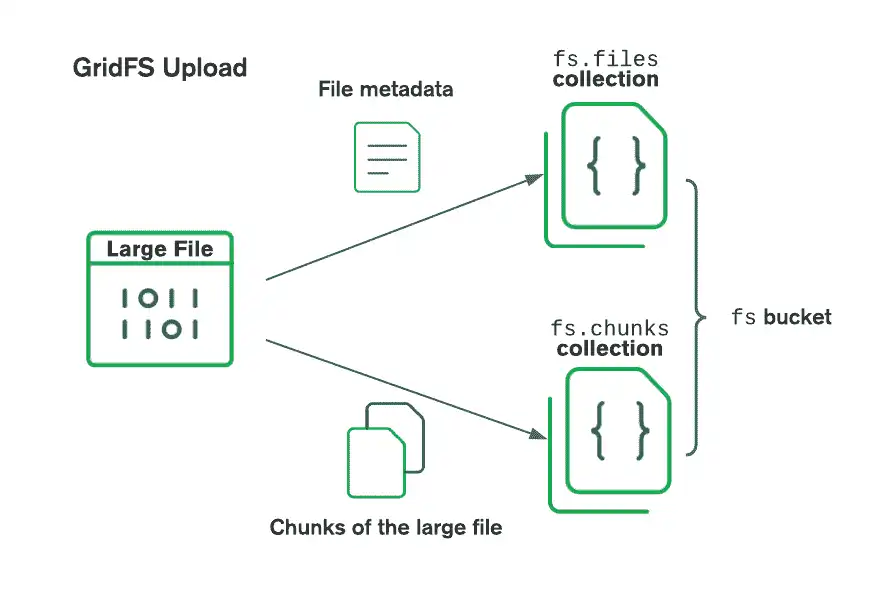
파일을 검색할 때 GridFS는 지정된 버킷의 files 컬렉션에서 메타데이터를 가져와서 이 정보를 사용하여 chunks 컬렉션의 문서에서 파일을 재구성합니다. 파일을 메모리로 읽거나 스트림으로 출력할 수 있습니다.
GridFS 버킷 만들기
버킷을 생성하거나 기존 버킷에 대한 레퍼런스를 가져와 GridFS에서 파일 저장 또는 검색을 시작하세요. 데이터베이스를 매개변수로 전달하여 GridFSBucket 인스턴스를 만듭니다. 그런 다음 GridFSBucket 인스턴스를 사용하여 버킷의 파일에 대한 읽기 및 쓰기 작업을 호출할 수 있습니다.
const db = client.db(dbName); const bucket = new mongodb.GridFSBucket(db);
다음 예와 같이 버킷 이름을 create() 메서드의 두 번째 매개변수로 전달하여 기본 이름 fs가 아닌 사용자 지정 이름으로 버킷을 생성하거나 레퍼런스로 활용합니다.
const bucket = new mongodb.GridFSBucket(db, { bucketName: 'myCustomBucket' });
자세한 내용은 GridFSBucket API 설명서를 참조하세요.
파일 업로드
GridFSBucket의 openUploadStream() 메서드를 사용하여 지정된 파일 이름에 대한 업로드 스트림을 만듭니다. pipe() 메서드를 사용하여 Node.js 읽기 스트림을 업로드 스트림에 연결할 수 있습니다. openUploadStream() 메서드를 사용하면 파일 청크 크기 및 메타데이터로 저장할 기타 필드/값 쌍과 같은 구성 정보를 지정할 수 있습니다.
다음 예시에서는 fs 변수로 표시되는 Node.js 읽기 스트림을 GridFSBucket 인스턴스의 openUploadStream() 메서드로 파이프하는 방법을 보여 줍니다.
fs.createReadStream('./myFile'). pipe(bucket.openUploadStream('myFile', { chunkSizeBytes: 1048576, metadata: { field: 'myField', value: 'myValue' } }));
자세한 내용은 openUploadStream() API 문서를 참조하세요.
파일 정보 검색
이 섹션에서는 GridFS 버킷의 files 컬렉션에 저장된 파일 메타데이터를 검색하는 방법을 알아볼 수 있습니다. 메타데이터에는 다음을 포함하여 참조하는 파일에 대한 정보가 포함됩니다.
파일의
_id입니다.파일 이름
파일의 길이/크기
업로드 날짜 및 시간
다른 정보를 저장할 수 있는
metadata문서입니다.
GridFSBucket 인스턴스에서 find() 메서드를 호출하여 GridFS 버킷에서 파일을 검색합니다. 해당 메서드는 결과에 액세스할 수 있는 FindCursor 인스턴스를 반환합니다.
다음 코드 예시는 GridFS 버킷의 모든 파일에서 파일 메타데이터를 검색하고 출력하는 방법을 보여줍니다. 다음 예시에서는 FindCursor 이터러블(iterable)에서 검색된 결과를 활용할 수 있는 여러 가지 방법 중 for await...of 구문을 사용하여 결과를 표시합니다:
const cursor = bucket.find({}); for await (const doc of cursor) { console.log(doc); }
find() 메서드는 다양한 쿼리 사양을 허용하며 sort(), limit(), project() 등의 다른 메서드와 결합할 수 있습니다.
이 섹션에 언급된 클래스 및 메서드에 대한 자세한 내용은 다음 리소스를 참조하세요.
파일 다운로드
GridFSBucket에서 openDownloadStreamByName() 메서드를 사용하여 다운로드 스트림을 생성하면 MongoDB 데이터베이스에서 파일을 다운로드할 수 있습니다.
다음 예시에서는 filename 필드에 저장된 파일 이름을 레퍼런스로 활용하는 파일을 작업 디렉토리로 다운로드하는 방법을 보여줍니다.
bucket.openDownloadStreamByName('myFile'). pipe(fs.createWriteStream('./outputFile'));
참고
동일한 filename 값을 가진 문서가 여러 개 있는 경우 GridFS는 지정된 이름(uploadDate 필드에 의해 결정됨)의 가장 최근 파일을 스트리밍합니다.
또는 파일의 _id 필드를 매개변수로 사용하는 openDownloadStream() 메서드를 사용할 수 있습니다.
bucket.openDownloadStream(ObjectId("60edece5e06275bf0463aaf3")). pipe(fs.createWriteStream('./outputFile'));
참고
GridFS 스트리밍 API는 부분 청크를 로드할 수 없습니다. 다운로드 스트림은 MongoDB에서 청크를 가져와야 하는 경우 청크 전체를 메모리로 가져옵니다. 기본 청크 크기인 255kB를 가져와도 일반적으로 메모리가 충분하긴 하지만, 메모리의 오버헤드를 줄이고 싶은 경우 청크 크기를 줄일 수 있습니다.
openDownloadStreamByName() 메서드에 대한 자세한 내용은 해당 API 설명서를 참조하세요.
파일 이름 바꾸기
rename() 메서드를 사용하여 버킷에 있는 GridFS 파일의 이름을 업데이트합니다. 파일 이름이 아닌 _id 필드로 이름을 바꾸도록 파일을 지정해야 합니다.
참고
rename() 메서드는 한 번에 하나의 파일 이름 업데이트만 지원합니다. 여러 파일의 이름을 바꾸려면 버킷에서 파일 이름과 일치하는 파일 목록을 검색하고, 이름을 바꾸려는 파일에서 _id 필드를 추출한 다음 rename() 메서드에 각 값을 개별적으로 호출하여 전달합니다.
다음 예시에서는 문서의 _id 필드를 참고하여 filename 필드를 "newFileName"으로 업데이트하는 방법을 보여 줍니다.
bucket.rename(ObjectId("60edece5e06275bf0463aaf3"), "newFileName");
이 메서드에 대한 자세한 내용은 rename() API 문서를 참조하세요.
파일 삭제
delete() 메서드를 사용하여 버킷에서 파일을 제거하세요. 파일 이름이 아닌 _id 필드로 파일을 지정해야 합니다.
참고
delete() 메서드는 한 번에 하나의 파일 삭제만 지원합니다. 여러 파일을 삭제하려면 버킷에서 파일을 검색하고 삭제하려는 파일에서 _id 필드를 추출한 다음 delete() 메서드에 각 값을 개별적으로 호출하여 전달합니다.
다음 예시에서는 _id 필드를 참고하여 파일을 삭제하는 방법을 보여 줍니다.
bucket.delete(ObjectId("60edece5e06275bf0463aaf3"));
이 메서드에 대한 자세한 내용은 delete() API 설명서를 참조하세요.
GridFS 버킷 삭제
drop() 메서드로 버킷의 files 및 chunks 컬렉션을 제거하여 버킷을 효과적으로 삭제합니다. 다음 코드 예시에서는 GridFS 버킷을 삭제하는 방법을 보여줍니다.
bucket.drop();
이 메서드에 대한 자세한 내용은 drop() API 문서를 참조하세요.