개요
이 가이드에서는 GridFS 를 사용하여 MongoDB에 대용량 파일을 저장하고 조회하는 방법에 대해 설명합니다. GridFS는 저장 중에 파일을 청크로 분할하고 검색 중에 다시 어셈블하는 방법을 설명합니다. GridFS의 Rust 드라이버 구현은 파일 스토리지의 운영 및 조직을 관리합니다.
파일 크기가 BSON 문서 크기 제한인 16 MB를 초과하는 경우 GridFS를 사용하세요. 또한 GridFS를 사용하면 전체 파일을 메모리에 로드하지 않고도 파일에 액세스할 수 있습니다. GridFS가 해당 사용 사례에 적합한지 여부에 대한 자세한 내용은 MongoDB Server 매뉴얼의 GridFS 페이지를 참조하세요.
GridFS에 대해 자세히 알아보려면 이 가이드의 다음 섹션으로 이동하세요.
GridFS 작동 방식
GridFS는 파일 청크와 설명 정보가 포함된 MongoDB 컬렉션 그룹인 버킷 에 파일을 구성합니다. 버킷에는 GridFS 사양에 정의된 규칙에 따라 이름이 지정된 다음 collection이 포함되어 있습니다.
chunks바이너리 파일 청크를 저장합니다.files파일 메타데이터를 저장합니다.
Rust 드라이버는 새 GridFS 버킷을 만들 때 다음 작업을 수행합니다.
다른 이름을 지정하지 않는 한 기본 버킷 이름
fs접두사가 붙은chunks및filescollection을 생성합니다.파일 및 관련 메타데이터를 효율적으로 조회할 수 있도록 각 collection에 인덱스를 생성합니다.
이 페이지 의 GridFS 버킷 참조 섹션에 있는 단계에 따라 GridFS 버킷에 대한 참조를 생성할 수 있습니다. 그러나 드라이버는 첫 번째 쓰기 작업까지 새 GridFS 버킷과 해당 인덱스를 생성하지 않습니다. GridFS 인덱스에 대한 자세한 내용은 MongoDB Server 매뉴얼의 GridFS 인덱스 페이지를 참조하세요.
파일을 GridFS 버킷에 저장할 때 Rust 드라이버는 다음과 같은 문서를 생성합니다.
고유한 파일 ID, 파일 이름, 기타 파일 메타데이터를 저장하는
files컬렉션의 문서 1개드라이버가 작은 조각으로 분할하는 파일의 내용을 저장하는
chunks컬렉션 내 하나 이상의 문서
다음 다이어그램은 버킷에 업로드할 때 GridFS가 파일을 분할하는 방법을 설명합니다:

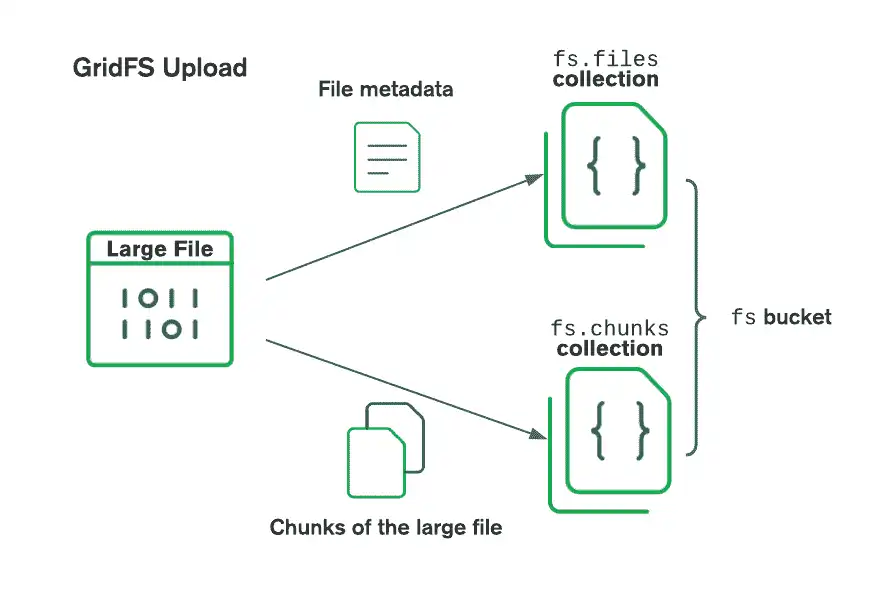
파일을 검색할 때 GridFS는 지정된 버킷의 files 컬렉션에서 메타데이터를 가져와서 이 정보를 사용하여 chunks 컬렉션의 문서에서 파일을 재구성합니다. 파일을 메모리로 읽거나 스트림으로 출력할 수 있습니다.
GridFS 버킷 참조
GridFS 버킷에 파일을 저장하기 전에 버킷 참조를 생성하거나 기존 버킷에 대한 참조를 가져오세요.
다음 예시에서는 데이터베이스 인스턴스에서 gridfs_bucket() 메서드를 호출하여 새 GridFS 버킷 또는 기존 GridFS 버킷에 대한 참고를 생성합니다.
let bucket = my_db.gridfs_bucket(None);
GridFsBucketOptions 구조체의 bucket_name 필드 를 설정하여 사용자 지정 버킷 이름을 지정할 수 있습니다.
참고
구조체 인스턴스화
Rust 운전자 는 GridFsBucketOptions 을(를) 포함한 일부 구조체 유형 생성을 위한 빌더 디자인 패턴 을 구현합니다. builder() 메서드를 사용하여 옵션 빌더 메서드를 연결하여 각 유형의 인스턴스 를 구성할 수 있습니다.
다음 표에서는 GridFsBucketOptions 필드를 설정하다 하는 데 사용할 수 있는 메서드에 대해 설명합니다.
메서드 | Possible Values | 설명 |
|---|---|---|
bucket_name() | Any String value | Specifies a bucket name, which is set to fs by default |
| 모든 | 파일을 청크로 나누는 데 사용되는 청크 크기를 지정하며(기본적으로 255KB) |
write_concern() | WriteConcern::w(),WriteConcern::w_timeout(),WriteConcern::journal(),WriteConcern::majority() | Specifies the bucket's write concern, which is set to the database's write concern by default |
|
| 기본적으로 데이터베이스의 읽기 고려 (read concern)로 설정되는 버킷의 읽기 고려 (read concern)를 지정합니다. |
selection_criteria() | SelectionCriteria::ReadPreference,SelectionCriteria::Predicate | Specifies which servers are suitable for a bucket operation, which is set to the database's selection criteria by default |
다음 예에서는 GridFsBucketOptions 인스턴스의 옵션을 지정하여 쓰기 작업에 대한 사용자 지정 버킷 이름과 5초의 시간 제한을 구성합니다.
let wc = WriteConcern::builder().w_timeout(Duration::new(5, 0)).build(); let opts = GridFsBucketOptions::builder() .bucket_name("my_bucket".to_string()) .write_concern(wc) .build(); let bucket_with_opts = my_db.gridfs_bucket(opts);
파일 업로드
업로드 스트림을 열고 파일을 스트림에 작성하여 GridFS 버킷에 파일을 업로드할 수 있습니다. 버킷 인스턴스에서 open_upload_stream() 메서드를 호출하여 스트림을 엽니다. 이 메서드는 파일 콘텐츠를 쓸 수 있는 GridFsUploadStream 인스턴스를 반환합니다. 파일 콘텐츠를 GridFsUploadStream 에 업로드하려면 write_all() 메서드를 호출하고 파일 바이트를 매개변수로 전달합니다.
팁
필수 모듈 가져오기
GridFsUploadStream 구조체는 futures_io::AsyncWrite 특성을 구현합니다. AsyncWrite write 메서드(예: write_all())를 사용하려면 다음 use 선언을 사용하여 AsyncWriteExt 모듈을 애플리케이션 파일로 가져옵니다.
use futures_util::io::AsyncWriteExt;
다음 예시에서는 업로드 스트림을 사용하여 "example.txt" 파일을 GridFS 버킷에 업로드합니다.
let bucket = my_db.gridfs_bucket(None); let file_bytes = fs::read("example.txt").await?; let mut upload_stream = bucket.open_upload_stream("example").await?; upload_stream.write_all(&file_bytes[..]).await?; println!("Document uploaded with ID: {}", upload_stream.id()); upload_stream.close().await?;
파일 다운로드
다운로드 스트림을 열고 스트림에서 읽어 GridFS 버킷에서 파일을 다운로드할 수 있습니다. 버킷 인스턴스에서 open_download_stream() 메서드를 호출하고 원하는 파일의 _id 값을 매개 변수로 지정합니다. 이 메서드는 파일에 액세스할 수 있는 인스턴스 GridFsDownloadStream 을(를) 반환합니다. GridFsDownloadStream 에서 파일을 읽으려면 read_to_end() 메서드를 호출하고 벡터를 매개 변수로 전달합니다.
팁
필수 모듈 가져오기
GridFsDownloadStream 구조체는 futures_io::AsyncRead 특성을 구현합니다. read_to_end() 와 같은 AsyncRead 읽기 메서드를 사용하려면 다음 사용 선언을 사용하여 AsyncReadExt 모듈을 애플리케이션 파일로 가져옵니다.
use futures_util::io::AsyncReadExt;
다음 예시에서는 다운로드 스트림을 사용하여 GridFS 버킷에서 _id 값이 3289 인 파일을 다운로드합니다.
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let mut buf = Vec::new(); let mut download_stream = bucket.open_download_stream(Bson::ObjectId(id)).await?; let result = download_stream.read_to_end(&mut buf).await?; println!("{:?}", result);
참고
GridFS 스트리밍 API는 부분 청크를 로드할 수 없습니다. 다운로드 스트림은 MongoDB에서 청크를 가져와야 하는 경우 청크 전체를 메모리로 가져옵니다. 기본 청크 크기인 255KB도 일반적으로 충분하지만, 청크 크기를 줄여 메모리 오버헤드를 줄일 수 있습니다.
파일 정보 검색
GridFS 버킷의 files 컬렉션에 저장된 파일에 대한 정보를 조회할 수 있습니다. 각 파일은 파일 정보를 나타내는 다음 필드를 포함하는 FilesCollectionDocument 유형의 인스턴스로 저장됩니다.
_id: 파일 IDlength: 파일 크기chunk_size_bytes: 파일 청크의 크기upload_date: 파일의 업로드 날짜 및 시간filename: 파일 이름metadata: 사용자 지정 메타데이터를 저장하는 문서
GridFS 버킷 인스턴스에서 find() 메서드를 호출하여 버킷에서 파일을 검색합니다. 이 메서드는 결과에 액세스할 수 있는 커서 인스턴스를 반환합니다.
다음 예시에서는 GridFS 버킷에서 각 파일의 길이를 조회하고 출력합니다.
let bucket = my_db.gridfs_bucket(None); let filter = doc! {}; let mut cursor = bucket.find(filter).await?; while let Some(result) = cursor.try_next().await? { println!("File length: {}\n", result.length); };
팁
find() 메서드에 학습 보려면 데이터 조회 가이드 를 참조하세요. 커서에서 데이터를 검색하는 방법에 학습 보려면 커서 를 사용하여 데이터 액세스 가이드 를 참조하세요.
파일 이름 바꾸기
버킷 인스턴스에서 rename() 메서드를 호출하여 버킷에 있는 GridFS 파일의 이름을 업데이트할 수 있습니다. 대상 파일의 _id 값과 새 파일 이름을 rename() 메서드에 매개변수로 전달합니다.
참고
rename() 메서드는 한 번에 하나의 파일 이름 업데이트만 지원합니다. 여러 파일의 이름을 바꾸려면 버킷에서 파일 이름과 일치하는 파일 목록을 검색하고, 이름을 바꾸려는 파일에서 _id 필드를 추출한 다음 rename() 메서드에 각 값을 개별적으로 호출하여 전달합니다.
다음 예시에서는 _id 값이 포함된 파일의 filename 필드를 3289 "new_file_name" 로 업데이트합니다.
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); let new_name = "new_file_name"; bucket.rename(Bson::ObjectId(id), new_name).await?;
파일 삭제
delete() 메서드를 사용하여 버킷에서 파일을 제거할 수 있습니다. 파일을 제거하려면 버킷 인스턴스에서 delete() 를 호출하고 파일의 _id 값을 매개 변수로 전달합니다.
참고
delete() 메서드는 한 번에 하나의 파일 삭제만 지원합니다. 여러 파일을 삭제하려면 버킷에서 파일을 검색하고 삭제하려는 파일에서 _id 필드를 추출한 다음 {2 delete() 메서드에 개별적으로 호출하여 각 _id 값을 전달합니다.
다음 예에서는 _id 필드의 값이 3289 인 파일을 삭제합니다.
let bucket = my_db.gridfs_bucket(None); let id = ObjectId::from_str("3289").expect("Could not convert to ObjectId"); bucket.delete(Bson::ObjectId(id)).await?;
GridFS 버킷 삭제
drop() 메서드를 사용하여 버킷을 삭제하면 버킷의 files 및 chunks collection이 제거됩니다. 버킷을 삭제하려면 버킷 인스턴스에서 drop() 를 호출합니다.
다음 예시에서는 GridFS 버킷을 삭제합니다.
let bucket = my_db.gridfs_bucket(None); bucket.drop().await?;
추가 정보
API 문서
이 가이드에 언급된 메서드나 유형에 대해 자세히 알아보려면 다음 API 설명서를 참조하세요.