Kafka 및 Kafka Connect
이 페이지의 내용
개요
이 가이드에서는 Apache Kafka 및 Kafka Connect에 대한 다음과 같은 기본 정보를 알아볼 수 있습니다.
Apache Kafka와 Kafka Connect란?
Apache Kafka와 Kafka Connect로 해결할 수 있는 문제
Apache Kafka와 Kafka Connect가 유용한 이유
Apache Kafka 및 Kafka Connect 파이프라인을 통해 데이터가 이동하는 방법
Apache Kafka
Apache Kafka는 오픈 소스 게시/구독 메시징 시스템입니다. 유연하고 내결함성이 있으며 수평적으로 확장 가능한 시스템을 제공하여 데이터 저장소와 애플리케이션 전체에서 데이터를 이동할 수 있습니다. 시스템의 특정 구성 요소가 작동을 멈추더라도 시스템이 계속 작동할 수 있다면 내결함성이 있는 것입니다. 시스템의 hardware를 개선하는 대신 더 많은 시스템을 추가하여 더 큰 워크로드를 처리하도록 시스템을 확장할 수 있다면 시스템은 수평적으로 확장 가능한 것입니다.
Apache Kafka에 대한 자세한 내용은 다음 리소스를 참조하세요.
Kafka Connect
Kafka Connect는 Apache Kafka의 구성 요소로, Apache Kafka를 MongoDB와 같은 데이터스토어에 연결하는 문제를 해결합니다. Kafka Connect는 다음 리소스를 제공하여 이 문제를 해결합니다.
데이터 저장소 간에 데이터를 전송하기 위한 내결함성 런타임입니다.
Apache Kafka 커뮤니티를 위한 프레임워크로서, Apache Kafka를 다양한 데이터 저장소에 연결하는 솔루션을 공유하는 데 사용됩니다.
Kafka Connect 프레임워크는 개발자가 재사용 가능한 커넥터를 작성할 수 있는 API를 정의합니다. 커넥터를 사용하면 Kafka Connect 배포가 데이터 소스 또는 데이터 싱크로서 특정 데이터 저장소와 상호 작용할 수 있습니다. MongoDB Kafka 커넥터는 이러한 커넥터 중 하나입니다.
Kafka Connect에 대한 자세한 내용은 다음 리소스를 참조하세요.
connector Kafka Connect용 첫 번째 Apache 빌드 Software Foundation에서
팁
데이터스토어에 연결할 때 생산자/소비자 클라이언트 대신 Kafka Connect 사용
생산자 및 소비자 클라이언트를 사용하여 Apache Kafka를 특정 데이터 저장소에 연결하는 자체 애플리케이션을 작성할 수도 있지만 Kafka Connect가 더 적합할 수 있습니다. Kafka Connect를 사용하는 몇 가지 이유는 다음과 같습니다.
Kafka Connect는 안정적인 파이프라인을 보장하기 위해 분산된 내결함성 아키텍처를 갖추고 있습니다.
Apache Kafka를 MongoDB, PostgreSQL, MySQL과 같은 인기 있는 데이터 저장소에 연결하기 위해 Kafka Connect 프레임워크를 사용하여 커뮤니티에서 유지 관리되는 많은 커넥터가 있습니다. 이를 통해 데이터베이스 연결, 오류 처리, 데드 레터 큐 통합 및 데이터스토어와 Apache Kafka 연결과 관련된 기타 문제를 관리하기 위해 작성하고 유지 관리해야 하는 상용구 코드의 양이 줄어듭니다.
Confluent에서 관리형 Kafka Connect 클러스터를 사용할 수 있는 옵션이 있습니다.
다이어그램
다음 다이어그램은 Apache Kafka와 Kafka Connect로 구축된 예시 데이터 파이프라인을 통해 정보가 어떻게 흐르는지 보여줍니다. 예시 파이프라인은 MongoDB 클러스터를 데이터 소스로 사용하고 MongoDB 클러스터를 데이터 싱크로 사용합니다.

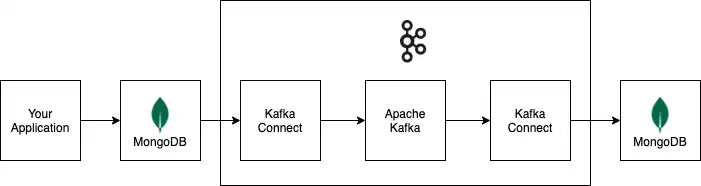
예시 파이프라인 의 모든 커넥터와 데이터 저장소는 선택 사항입니다. 배포서버 에 필요한 커넥터 및 데이터 저장소로 교체할 수 있습니다.