대용량 파일 저장
이 페이지의 내용
개요
이 가이드 에서는 GridFS 를 사용하여 MongoDB 에 대용량 파일을 저장 하고 조회 하는 방법을 학습 수 있습니다. GridFS 는 C++ 운전자 에 의해 구현된 사양으로, 파일을 저장할 때 청크로 분할 하고 검색할 때 파일을 다시 조립하는 방법을 설명합니다. 드라이버의 GridFS 구현 은 파일 저장 의 운영 및 조직 을 관리하는 추상화입니다.
파일 크기가 BSON 문서 크기 제한인 16MB를 초과하는 경우 GridFS 를 사용하세요. GridFS 가 사용 사례 에 적합한지 여부에 대한 자세한 내용은 MongoDB Server 매뉴얼에서GridFS 를 참조하세요.
GridFS 작동 방식
GridFS는 파일 청크와 파일을 설명하는 정보가 들어 있는 MongoDB 컬렉션 그룹인 버킷에 파일을 구성합니다. 버킷에는 GridFS 사양에 정의된 규칙을 사용하여 명명된 다음 컬렉션이 포함되어 있습니다.
chunks바이너리 파일 청크를 저장하는 컬렉션files파일 메타데이터 를 저장하는 컬렉션
운전자 는 GridFS 버킷에 처음 데이터를 쓰기 (write) 때 GridFS 버킷을 생성합니다(존재하지 않는 경우). 버킷에는 다른 이름을 지정하지 않는 한 기본값 버킷 이름 fs 접두사가 붙은 앞의 collection이 포함되어 있습니다. 파일 및 관련 메타데이터 를 효율적으로 검색하기 위해 운전자 는 각 컬렉션 에 인덱스 를 생성합니다. 운전자 는 GridFS 버킷에서 읽기 및 쓰기 (write) 작업을 수행하기 전에 이러한 인덱스가 존재하는지 확인합니다.
GridFS 인덱스에 대한 자세한 내용은 MongoDB Server 매뉴얼에서 GridFS 인덱스를 참조하세요.
GridFS 를 사용하여 파일을 저장 때 운전자 는 파일을 작은 청크로 분할하며, 각 청크는 chunks 컬렉션 에서 별도의 문서 로 표시됩니다. 또한 files 컬렉션 에 파일 ID, 파일 이름 및 기타 파일 메타데이터 가 포함된 문서 를 만듭니다. 스트림 을 C++ 운전자 에 전달하여 소비하거나 새 스트림 을 생성하고 직접 작성하여 파일 을 업로드할 수 있습니다.
다음 다이어그램은 파일이 버킷에 업로드될 때 GridFS 가 파일을 분할하는 방법을 보여줍니다.

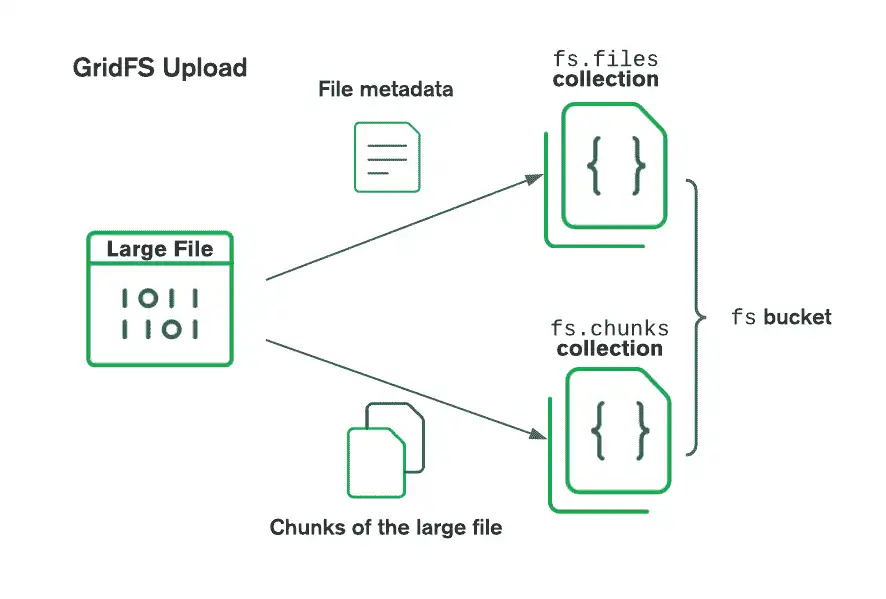
파일을 검색할 때 GridFS 는 지정된 버킷의 files 컬렉션 에서 메타데이터 를 가져오고 이 정보를 사용하여 chunks 컬렉션 의 문서에서 파일 을 재구성합니다. 기존 스트림 에 내용을 쓰거나 파일 을 가리키는 새 스트림 을 만들어 파일 을 읽을 수 있습니다.
GridFS 버킷 만들기
GridFS 에서 파일 저장 또는 검색을 시작하려면 데이터베이스 에서 gridfs_bucket() 메서드를 호출합니다. 이 메서드는 기존 버킷에 액세스하거나 버킷이 없는 경우 새 버킷을 생성합니다.
다음 예시 에서는 db 데이터베이스 에서 gridfs_bucket() 메서드를 호출합니다.
auto bucket = db.gridfs_bucket();
버킷 사용자 지정
mongocxx::options::gridfs::bucket 클래스의 인스턴스 를 gridfs_bucket() 메서드에 선택적 인수로 전달하여 GridFS 버킷 구성을 사용자 지정할 수 있습니다. 다음 표에서는 mongocxx::options::gridfs::bucket 인스턴스 에서 설정하다 수 있는 필드에 대해 설명합니다.
필드 | 설명 |
|---|---|
| Specifies the bucket name to use as a prefix for the files and chunks collections.
The default value is "fs".Type: std::string |
| Specifies the chunk size that GridFS splits files into. The default value is 261120.Type: std::int32_t |
| Specifies the read concern to use for bucket operations. The default value is the
database's read concern. Type: mongocxx::read_concern |
| Specifies the read preference to use for bucket operations. The default value is the
database's read preference. Type: mongocxx::read_preference |
| Specifies the write concern to use for bucket operations. The default value is the
database's write concern. Type: mongocxx::write_concern |
다음 예시 에서는 mongocxx::options::gridfs::bucket 인스턴스 의 bucket_name 필드 를 설정하여 "myCustomBucket" 이라는 이름의 버킷을 만듭니다.
mongocxx::options::gridfs::bucket opts; opts.bucket_name("myCustomBucket"); auto bucket = db.gridfs_bucket(opts);
파일 업로드
다음 방법을 사용하여 GridFS 버킷에 파일을 업로드할 수 있습니다.
open_upload_stream(): 파일 콘텐츠를 쓰기 (write) 수 있는 새 업로드 스트림 을 엽니다.
upload_from_stream(): 기존 스트림 의 내용을 GridFS 파일 에 업로드합니다.
업로드 스트림에 쓰기
open_upload_stream() 메서드를 사용하여 지정된 파일 이름에 대한 업로드 스트림 을 만듭니다. open_upload_stream() 메서드를 사용하면 options::gridfs::upload 인스턴스 에서 구성 정보를 지정할 수 있으며, 이를 매개변수로 전달할 수 있습니다.
이 예시 에서는 업로드 스트림 을 사용하여 다음 조치를 수행합니다.
옵션 인스턴스 의
chunk_size_bytes필드 를 설정합니다.이름이
"my_file"인 새 GridFS 파일 에 대한 쓰기 가능한 스트림 을 열고chunk_size_bytes옵션을 적용합니다.write()메서드를 호출하여 스트림 이 가리키는my_file에 데이터를 쓰기 (write) .close()메서드를 호출하여my_file을(를) 가리키는 스트림 을 닫습니다.
mongocxx::options::gridfs::upload opts; opts.chunk_size_bytes(1048576); auto uploader = bucket.open_upload_stream("my_file", opts); // ASCII for "HelloWorld" std::uint8_t bytes[10] = {72, 101, 108, 108, 111, 87, 111, 114, 108, 100}; for (auto i = 0; i < 5; ++i) { uploader.write(bytes, 10); } uploader.close();
기존 스트림 업로드
upload_from_stream() 메서드를 사용하여 스트림 의 콘텐츠를 새 GridFS 파일 에 업로드합니다. upload_from_stream() 메서드를 사용하면 options::gridfs::upload 인스턴스 에서 구성 정보를 지정할 수 있으며, 이를 매개변수로 전달할 수 있습니다.
이 예에서는 다음 조치를 수행합니다.
바이너리 읽기 모드 에서
/path/to/input_file에 있는 파일 을 스트림 으로 엽니다.upload_from_stream()메서드를 호출하여 스트림 의 내용을"new_file"이라는 GridFS 파일 에 업로드합니다.
std::ifstream file("/path/to/input_file", std::ios::binary); bucket.upload_from_stream("new_file", &file);
파일 정보 검색
이 섹션에서는 GridFS 버킷의 files 컬렉션에 저장된 파일 메타데이터를 검색하는 방법을 알아볼 수 있습니다. 메타데이터에는 다음을 포함하여 참조하는 파일에 대한 정보가 포함됩니다.
파일의
_id입니다.파일 이름
파일의 길이/크기
업로드 날짜 및 시간
다른 정보를 저장 수 있는
metadata문서 입니다.
GridFS 버킷에서 파일을 조회 하려면 버킷에서 mongocxx::gridfs::bucket::find() 메서드를 호출합니다. 이 메서드는 결과에 액세스 할 수 있는 mongocxx::cursor 인스턴스 를 반환합니다. 커서에 학습 보려면 커서에서 데이터 액세스 가이드 를 참조하세요.
예시
다음 코드 예시 는 GridFS 버킷의 파일에서 파일 메타데이터 를 조회 하고 인쇄하는 방법을 보여줍니다. 루프를 사용하여 반환된 커서 를 for 반복하고 파일 업로드 예제에 업로드된 파일의 내용을 표시합니다.
auto cursor = bucket.find({}); for (auto&& doc : cursor) { std::cout << bsoncxx::to_json(doc) << std::endl; }
{ "_id" : { "$oid" : "..." }, "length" : 13, "chunkSize" : 261120, "uploadDate" : { "$date" : ... }, "filename" : "new_file" } { "_id" : { "$oid" : "..." }, "length" : 50, "chunkSize" : 1048576, "uploadDate" : { "$date" : ... }, "filename" : "my_file" }
find() 메서드는 다양한 쿼리 사양을 허용합니다. mongocxx::options::find 매개변수를 사용하여 정렬 순서, 반환할 최대 문서 수, 반환하기 전에 건너뛸 문서 수를 지정할 수 있습니다. 사용 가능한 옵션 목록을 보려면 API 설명서를 참조하세요.
파일 다운로드
다음 방법을 사용하여 GridFS 버킷에서 파일을 다운로드 할 수 있습니다.
open_download_stream(): 파일 내용을 읽을 수 있는 새 다운로드 스트림 을 엽니다.
download_to_stream(): 전체 파일 을 기존 다운로드 스트림 에 씁니다.
다운로드 스트림에서 읽기
open_download_stream() 메서드를 사용하여 다운로드 스트림 을 생성하여 MongoDB database 에서 파일을 다운로드 할 수 있습니다.
이 예시 에서는 다운로드 스트림 을 사용하여 다음 작업을 수행합니다.
이름이
"new_file"인 GridFS 파일 의_id값을 검색합니다._id값을open_download_stream()메서드에 전달하여 파일 을 읽기 가능한 스트림 으로 엽니다.파일 내용을 저장
buffer벡터를 만듭니다.read()메서드를 호출하여downloader스트림 에서 벡터로 파일 내용을 읽습니다.
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); auto downloader = bucket.open_download_stream(id); std::vector<uint8_t> buffer(downloader.file_length()); downloader.read(buffer.data(), buffer.size());
기존 스트림에 다운로드
버킷에서 download_to_stream() 메서드를 호출하여 GridFS 파일 의 콘텐츠를 기존 스트림 에 다운로드 할 수 있습니다.
이 예에서는 다음 조치를 수행합니다.
바이너리 쓰기 (write) 모드 에서
/path/to/output_file에 있는 파일 을 스트림 으로 엽니다.이름이
"new_file"인 GridFS 파일 의_id값을 검색합니다._id값을download_to_stream()에 전달하여 파일 을 스트림 에 다운로드 합니다.
std::ofstream output_file("/path/to/output_file", std::ios::binary); auto doc = db["fs.files"].find_one(make_document(kvp("filename", "new_file"))); auto id = doc->view()["_id"].get_value(); bucket.download_to_stream(id, &output_file);
파일 삭제
버킷에서 파일의 컬렉션 문서와 관련 청크를 제거하려면 delete_file() 메서드를 사용합니다. 이렇게 하면 파일이 효과적으로 삭제됩니다. 파일 이름이 아닌 _id 필드로 파일을 지정해야 합니다.
다음 예시 에서는 _id 값을 delete_file()에 전달하여 "my_file" 이라는 파일 을 삭제 하는 방법을 보여 줍니다.
auto doc = db["fs.files"].find_one(make_document(kvp("filename", "my_file"))); auto id = doc->view()["_id"].get_value(); bucket.delete_file(id);
참고
파일 수정본
delete_file() 메서드는 한 번에 하나의 파일 삭제만 지원합니다. 각 파일 수정본을 삭제 하거나 동일한 파일 이름을 주식 하는 업로드 시간이 다른 파일을 삭제하려면 각 수정본의 _id 값을 수집합니다. 그런 다음 delete_file() 메서드에 대한 개별 호출로 각 _id 값을 전달합니다.
API 문서
C++ 운전자 를 사용하여 대용량 파일을 저장 하고 조회 하는 방법에 학습 보려면 다음 API 설명서를 참조하세요.