정의
$densify버전 5.1에 추가되었습니다.
필드의 특정 값이 누락된 문서 시퀀스에서 새 문서를 만듭니다.
$densify를 사용하여 다음을 수행할 수 있습니다.time series 데이터의 공백을 메웁니다.
데이터 그룹 간에 누락된 값을 추가합니다.
지정된 값 범위로 데이터를 채웁니다.
구문
$densify 단계의 구문은 다음과 같습니다.
{ $densify: { field: <fieldName>, partitionByFields: [ <field 1>, <field 2> ... <field n> ], range: { step: <number>, unit: <time unit>, bounds: < "full" || "partition" > || [ < lower bound >, < upper bound > ] } } }
$densify 단계는 다음 필드가 포함된 문서를 사용합니다.
필드 | 필요성 | 설명 |
|---|---|---|
필수 사항 | 밀도를 높일 필드입니다. 지정된 지정된 내장된 문서나 배열에 | |
옵션 | 문서를 그룹 위한 복합 키 역할을 하는 필드 설정하다 . 이 필드 생략하면 는 전체 컬렉션 에 대해 하나의 파티션을 예시는 파티션을 사용한 밀도화를 참조하세요. | |
필수 사항 | 데이터 밀도화 방법을 지정하는 객체입니다. | |
필수 사항 | 다음 중 하나로
| |
필수 사항 | ||
동작 및 제한 사항
field 제한 사항
지정된 필드가 포함된 문서의 경우 다음에서 $densify 오류가 발생합니다.
컬렉션의 문서에 날짜 유형의
field값이 있고 단위 필드가 지정되지 않았습니다.컬렉션의 문서에 숫자 유형의
field값이 있고 단위 필드가 지정되어 있습니다.field이름은$로 시작합니다. 필드를 밀도화하려면 필드 이름을 변경해야 합니다. 필드 이름을 바꾸려면$project를 사용합니다.버전 8.1의 새로운 기능:
field는partitionByFields배열의 모든 필드와 접두사를 공유합니다. 예시 들어field와partitionByFields의 다음 조합은 오류를 발생시킵니다.field: "timestamp",partitionByFields: ["timestamp"]field: "timestamp",partitionByFields: ["timestamp.hours"]field: "timestamp.hours",partitionByFields: ["timestamp"]
partitionByFields 제한 사항
partitionByFields $densify 배열에 필드 이름이 있는 경우 다음에서 오류가 발생합니다.
문자열이 아닌 값으로 평가합니다.
$로 시작합니다.
range.bounds 행동
range.bounds가 배열인 경우 다음과 같습니다.
출력 순서
$densify 출력하는 문서의 정렬 순서를 보장하지 않습니다.
정렬 순서를 보장하려면 정렬 기준으로 삼으려는 필드에 $sort를 사용합니다.
예시
time series 데이터 밀도화
4시간 간격으로 측정된 온도를 포함하는 weather 컬렉션을 만듭니다.
db.weather.insertMany( [ { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T00:00:00.000Z"), "temp": 12 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T04:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T08:00:00.000Z"), "temp": 11 }, { "metadata": { "sensorId": 5578, "type": "temperature" }, "timestamp": ISODate("2021-05-18T12:00:00.000Z"), "temp": 12 } ] )
이 예에서는 $densify 단계를 사용하여 4시간 간격 사이의 간격을 채워 데이터 요소에 대한 시간별 세분성을 달성합니다.
db.weather.aggregate( [ { $densify: { field: "timestamp", range: { step: 1, unit: "hour", bounds:[ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ] } } } ] )
예시:
$densify단계는 기록된 온도 사이의 시간 간격을 채웁니다.field: "timestamp"timestamp필드를 밀도화합니다.
range:step: 1timestamp필드를 1단위만큼 증가시킵니다.unit: hourtimestamp필드를 시간별로 밀도화합니다.bounds: [ ISODate("2021-05-18T00:00:00.000Z"), ISODate("2021-05-18T08:00:00.000Z") ]밀도화되는 시간 범위를 설정합니다.
다음 출력에서 $densify 단계는 00:00:00 및 08:00:00 시간 사이의 시간 간격을 채웁니다.
[ { _id: ObjectId("618c207c63056cfad0ca4309"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T00:00:00.000Z"), temp: 12 }, { timestamp: ISODate("2021-05-18T01:00:00.000Z") }, { timestamp: ISODate("2021-05-18T02:00:00.000Z") }, { timestamp: ISODate("2021-05-18T03:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430a"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T04:00:00.000Z"), temp: 11 }, { timestamp: ISODate("2021-05-18T05:00:00.000Z") }, { timestamp: ISODate("2021-05-18T06:00:00.000Z") }, { timestamp: ISODate("2021-05-18T07:00:00.000Z") }, { _id: ObjectId("618c207c63056cfad0ca430b"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T08:00:00.000Z"), temp: 11 } { _id: ObjectId("618c207c63056cfad0ca430c"), metadata: { sensorId: 5578, type: 'temperature' }, timestamp: ISODate("2021-05-18T12:00:00.000Z"), temp: 12 } ]
파티션을 사용한 밀도화
두 가지 종류의 커피 원두에 대한 데이터가 포함된 coffee 컬렉션을 만듭니다.
db.coffee.insertMany( [ { "altitude": 600, "variety": "Arabica Typica", "score": 68.3 }, { "altitude": 750, "variety": "Arabica Typica", "score": 69.5 }, { "altitude": 950, "variety": "Arabica Typica", "score": 70.5 }, { "altitude": 1250, "variety": "Gesha", "score": 88.15 }, { "altitude": 1700, "variety": "Gesha", "score": 95.5, "price": 1029 } ] )
전체 값 범위의 밀도화
이 예에서는 $densify를 사용하여 각 커피 variety에 대해 altitude필드를 밀도화합니다.
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "full", step: 200 } } } ] )
집계 예시:
variety로 문서를 분할하여Arabica Typica커피에 대한 그룹과Gesha커피에 대한 그룹을 하나씩 만듭니다.full범위를 지정합니다. 즉, 각 파티션에 대한 기존 문서의 전체 범위에 걸쳐 데이터가 밀도화됩니다.step을200으로 지정합니다. 이는 새 문서가200의altitude간격으로 생성됨을 의미합니다.
집계는 다음 문서를 반환합니다.
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { variety: 'Gesha', altitude: 600 }, { variety: 'Gesha', altitude: 800 }, { variety: 'Gesha', altitude: 1000 }, { variety: 'Gesha', altitude: 1200 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1400 }, { variety: 'Gesha', altitude: 1600 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 }, { variety: 'Arabica Typica', altitude: 1000 }, { variety: 'Arabica Typica', altitude: 1200 }, { variety: 'Arabica Typica', altitude: 1400 }, { variety: 'Arabica Typica', altitude: 1600 } ]
이 이미지는 $densify로 만든 문서를 시각화한 것입니다.

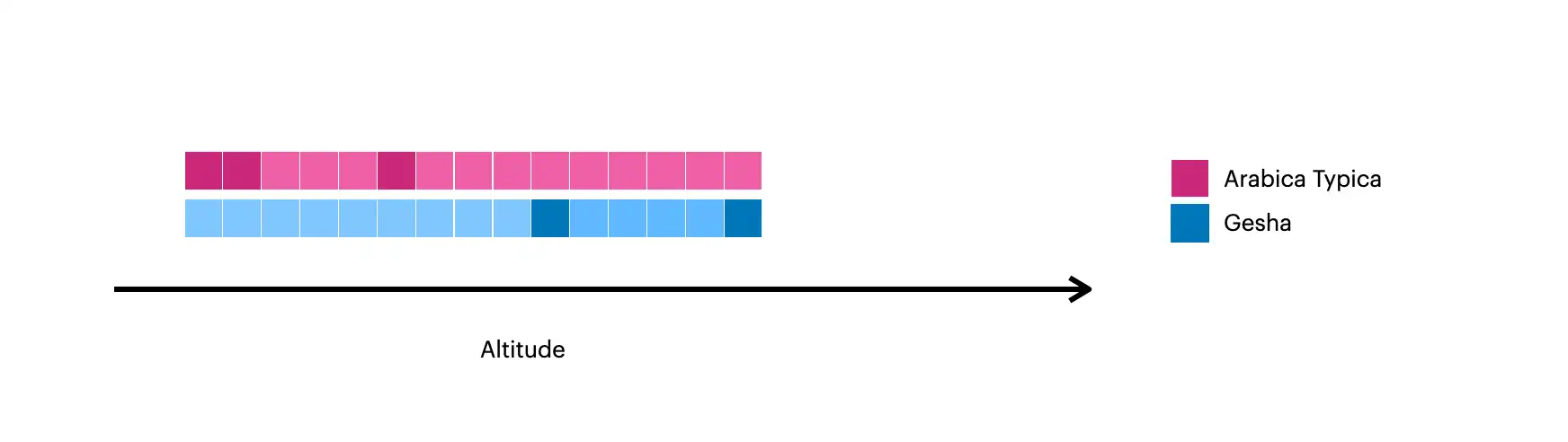
더 어두운 사각형은 컬렉션에 있는 원본 문서를 나타냅니다.
밝은 사각형은
$densify로 만든 문서를 나타냅니다.
각 파티션 내 값 밀도화
이 예시에서는 $densify를 사용하여 각 variety 내의 altitude 필드의 간격만 밀도화합니다.
db.coffee.aggregate( [ { $densify: { field: "altitude", partitionByFields: [ "variety" ], range: { bounds: "partition", step: 200 } } } ] )
집계 예시:
variety로 문서를 분할하여Arabica Typica커피에 대한 그룹과Gesha커피에 대한 그룹을 하나씩 만듭니다.partition범위를 지정합니다. 즉, 각 파티션 내에서 데이터가 밀도화됩니다.Arabica Typica파티션의 경우 범위는600-950입니다.Gesha파티션의 경우 범위는1250-1700입니다.
step을200으로 지정합니다. 이는 새 문서가200의altitude간격으로 생성됨을 의미합니다.
집계는 다음 문서를 반환합니다.
[ { _id: ObjectId("618c031814fbe03334480475"), altitude: 600, variety: 'Arabica Typica', score: 68.3 }, { _id: ObjectId("618c031814fbe03334480476"), altitude: 750, variety: 'Arabica Typica', score: 69.5 }, { variety: 'Arabica Typica', altitude: 800 }, { _id: ObjectId("618c031814fbe03334480477"), altitude: 950, variety: 'Arabica Typica', score: 70.5 }, { _id: ObjectId("618c031814fbe03334480478"), altitude: 1250, variety: 'Gesha', score: 88.15 }, { variety: 'Gesha', altitude: 1450 }, { variety: 'Gesha', altitude: 1650 }, { _id: ObjectId("618c031814fbe03334480479"), altitude: 1700, variety: 'Gesha', score: 95.5, price: 1029 } ]
이 이미지는 $densify로 만든 문서를 시각화한 것입니다.

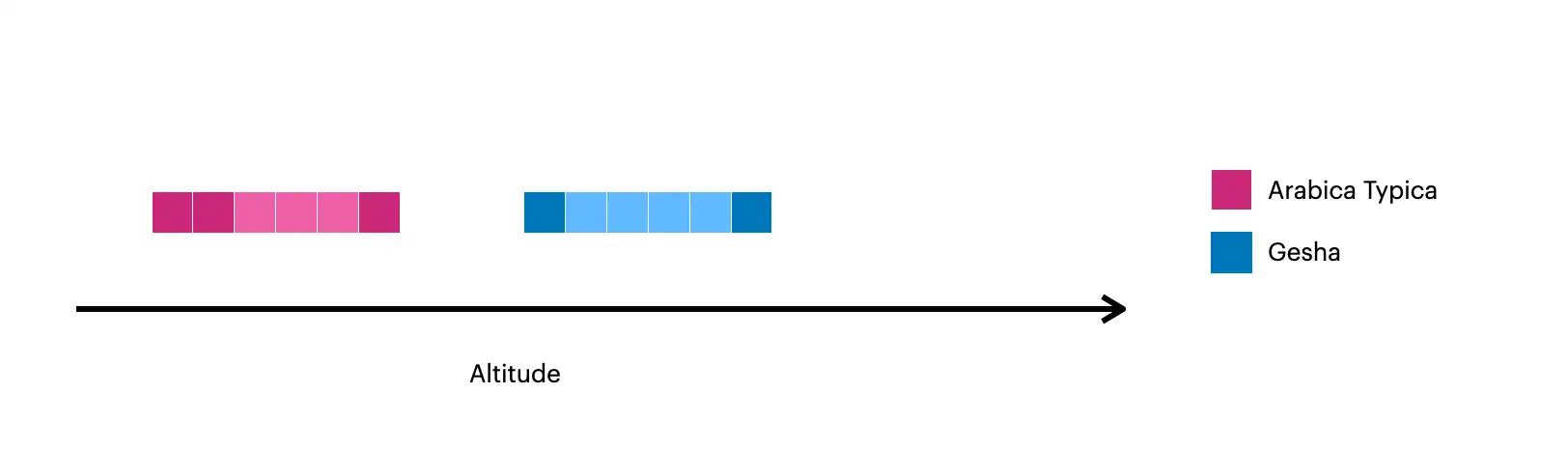
더 어두운 사각형은 컬렉션에 있는 원본 문서를 나타냅니다.
밝은 사각형은
$densify로 만든 문서를 나타냅니다.
이 페이지의 C# 예제에서는 Atlas 샘플 데이터 세트의 sample_weatherdata.data 컬렉션 사용합니다. 무료 MongoDB Atlas cluster 생성하고 샘플 데이터 세트를 로드하는 방법을 학습하려면 MongoDB .NET/ C# 드라이버 문서에서 시작하기 를 참조하세요.
다음 Weather 및 Point 클래스는 sample_weatherdata.data 컬렉션 의 문서를 모델링합니다.
public class Weather { public Guid Id { get; set; } public Point Position { get; set; } [] public DateTime Timestamp { get; set; } } public class Point { public float[] Coordinates { get; set; } }
sample_weatherdata.data 컬렉션 에는 1시간 간격으로 동일한 position 필드 에 대한 측정값이 포함된 다음 문서가 포함되어 있습니다.
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
MongoDB .NET/ C# 운전자 사용하여 $densify 집계 파이프라인 에 단계를 추가하려면 PipelineDefinition 객체 에서 Densify() 메서드를 호출합니다.
다음 예시 이전 두 문서 사이에 15분 간격으로 문서 추가하는 파이프라인 단계를 만듭니다. 그런 다음 코드는 이러한 문서를 Position.Coordinates 필드 의 값을 기준으로 그룹화합니다.
var densifyTimeRange = new DensifyDateTimeRange( new DensifyLowerUpperDateTimeBounds( lowerBound: new DateTime(1984, 3, 5, 8, 0, 0), upperBound: new DateTime(1984, 3, 5, 9, 0, 0) ), step: 15, unit: DensifyDateTimeUnit.Minutes ); var pipeline = new EmptyPipelineDefinition<Weather>() .Densify( field: w => w.Timestamp, range: densifyTimeRange, partitionByFields: [w => w.Position.Coordinates]);
이전 집계 단계에서는 컬렉션 에 다음과 같이 강조 표시된 문서가 생성됩니다.
Document{{ _id=5553a..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:00:00 EST 1984, ... }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:15:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:30:00 EST 1984 }} Document{{ position=Document{{coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 08:45:00 EST 1984 }} Document{{ _id=5553b..., position=Document{{type=Point, coordinates=[-47.9, 47.6]}}, ts=Mon Mar 05 09:00:00 EST 1984, ... }}
이 페이지의 Node.js 예시에서는 Atlas 샘플 데이터 세트의 sample_weatherdata.data 컬렉션을 사용합니다. 무료 MongoDB Atlas 클러스터를 생성하고 샘플 데이터 세트를 로드하는 방법을 학습하려면 MongoDB Node.js 드라이버 문서의 시작하기를 참조하세요.
sample_weatherdata.data 컬렉션 에는 1시간 간격으로 동일한 position 필드 에 대한 측정값이 포함된 다음 문서가 포함되어 있습니다.
{_id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, {_id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }
MongoDB Node.js 운전자 사용하여 집계 파이프라인 에 $densify 단계를 추가하려면 파이프라인 객체 에서 $densify 연산자 사용합니다.
다음 예시 이전 두 문서 사이에 15분 간격으로 문서 추가하는 파이프라인 단계를 만듭니다. 그런 다음 이 코드는 position.coordinates 필드 의 값을 기준으로 이러한 문서를 그룹화합니다. 그런 다음 이 예시 에서는 집계 파이프라인 실행합니다.
const pipeline = [ { $densify: { field: "ts", partitionByFields: ["position.coordinates"], range: { step: 15, unit: "minute", bounds: [new Date(1984, 3, 5, 8, 0, 0), new Date(1984, 3, 5, 9, 0, 0)] } } } ]; const cursor = collection.aggregate(pipeline); return cursor;
이전 집계 단계에서는 컬렉션 에 다음과 같이 강조 표시된 문서가 생성됩니다.
{ _id: new ObjectId(...), ts: 1984-03-05T13:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:15:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:30:00.000Z }, { position: { coordinates: [-47.9, 47.6] }, ts: 1984-03-05T13:45:00.000Z }, { _id: new ObjectId(...), ts: 1984-03-05T14:00:00.000Z, position: {type: 'Point', coordinates: [-47.9, 47.6]}, ... }