스키마를 설계할 때는 애플리케이션에서 관련 데이터를 쿼리하고 반환하는 방법을 고려하세요. 데이터 엔터티 간의 관계를 매핑하는 방식은 애플리케이션의 성능과 확장성에 영향을 미칩니다.
관련 데이터를 처리하다 하는 데 권장되는 방법은 해당 데이터를 하위 문서에 포함하는 것입니다. 관련 데이터를 포함하면 애플리케이션 에서 한 번의 읽기 작업으로 필요한 데이터를 쿼리 할 수 있으며 느린 $lookup 작업을 방지할 수 있습니다.
일부 사용 사례의 경우 참조를 사용하여 별도의 컬렉션에 있는 관련 데이터를 가리킬 수 있습니다.
이 작업에 대하여
관련 데이터를 포함할지 참고를 사용할지 결정하려면 애플리케이션에 대한 다음 목표의 상대적 중요성을 고려하세요.
- 관련 데이터에 대한 쿼리 개선
- 애플리케이션에서 한 엔티티를 자주 쿼리하여 다른 엔티티에 대한 데이터를 반환하는 경우
$lookup작업을 자주 수행할 필요가 없도록 데이터를 임베드하세요. - 다양한 엔티티에서 반환되는 데이터 개선
- 애플리케이션에서 관련 엔티티의 데이터를 함께 반환하는 경우 데이터를 단일 컬렉션에 포함하세요.
- 업데이트 성능 향상
- 애플리케이션에서 관련 데이터를 자주 업데이트하는 경우 데이터를 자체 컬렉션에 저장하고 참고를 사용하여 데이터에 액세스하는 것을 고려하세요. 참고를 사용하면 한 곳에서 데이터를 업데이트하기만 하면 되므로 애플리케이션의 쓰기 워크로드가 줄어듭니다.
포함된 데이터 및 참조의 이점에 대해 자세히 학습 관련 데이터 연결을 참조하세요.
시작하기 전에
관계 매핑은 스키마 설계 프로세스의 두 번째 단계입니다. 관계를 매핑하기 전에 애플리케이션의 워크로드를 식별하여 필요한 데이터를 결정합니다.
단계
관련 데이터에 대한 스키마 맵 만들기
스키마 맵에는 관련 데이터 필드와 해당 필드 간의 관계 유형(일대일, 일대다, 다대다)이 표시되어야 합니다.
스키마 맵은 엔터티-관계 모델과 유사할 수 있습니다.
관련 데이터 삽입 또는 참조 사용 여부 선택
데이터를 포함할지 아니면 참조를 사용할지는 애플리케이션의 일반적인 쿼리에 따라 결정됩니다. 애플리케이션 워크로드 식별 단계에서 식별한 쿼리를 검토하고 이 페이지 앞부분에서 언급한 지침을 사용하여 빈번하고 중요한 쿼리를 지원하도록 스키마를 설계하세요.
선택한 접근 방식에 맞게 데이터베이스, 컬렉션, 애플리케이션 로직을 구성합니다.
예시
블로그 애플리케이션에 대한 다음 스키마 맵을 고려하세요.

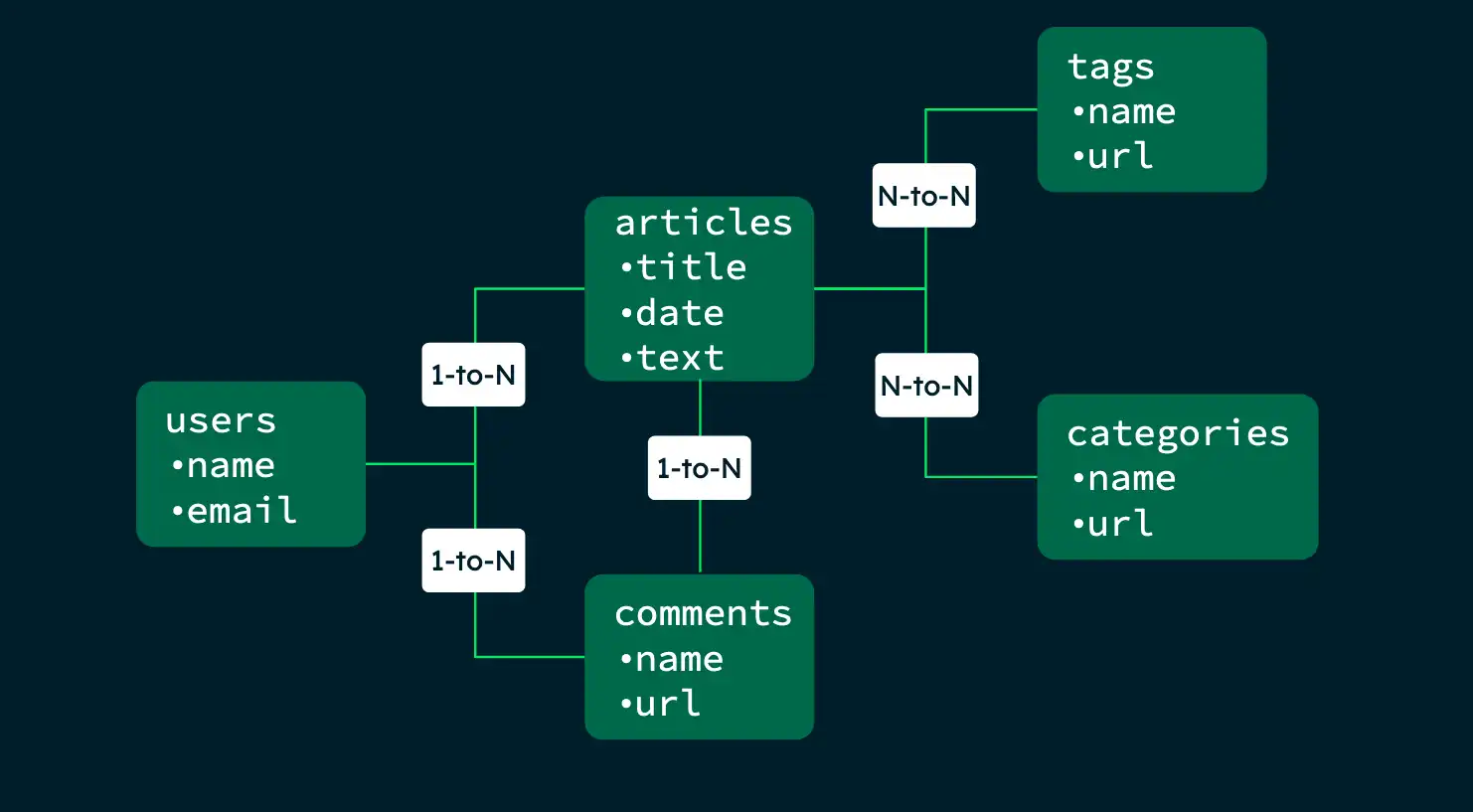
다음 예사에서는 애플리케이션의 필요에 따라 다양한 쿼리에 맞게 스키마를 최적화하는 방법을 보여줍니다.
아티클 쿼리 최적화
애플리케이션에서 주로 제목과 같은 정보를 아티클에 쿼리하는 경우 articles 컬렉션에 관련 정보를 포함하여 애플리케이션에 필요한 모든 데이터를 한 번의 작업으로 반환합니다.
다음 문서는 문서에 대한 쿼리에 최적화되어 있습니다.
db.articles.insertOne( { title: "My Favorite Vacation", date: ISODate("2023-06-02"), text: "We spent seven days in Italy...", tags: [ { name: "travel", url: "<blog-site>/tags/travel" }, { name: "adventure", url: "<blog-site>/tags/adventure" } ], comments: [ { name: "pedro123", text: "Great article!" } ], author: { name: "alice123", email: "alice@mycompany.com", avatar: "photo1.jpg" } } )
기사 및 저자에 대한 쿼리 최적화
애플리케이션에서 문서 정보와 작성자 정보를 별도로 반환하는 경우 문서와 작성자를 별도의 컬렉션에 저장하는 것이 좋습니다. 이 스키마 설계는 작성자 정보를 반환하는 데 필요한 작업을 줄이고 불필요한 필드를 포함하지 않으며 작성자 정보만 반환할 수 있도록 합니다.
다음 스키마에서 articles 컬렉션에는 authors 컬렉션에 대한 참조인 authorId 필드가 포함되어 있습니다.
아티클 모음
db.articles.insertOne( { title: "My Favorite Vacation", date: ISODate("2023-06-02"), text: "We spent seven days in Italy...", authorId: 987, tags: [ { name: "travel", url: "<blog-site>/tags/travel" }, { name: "adventure", url: "<blog-site>/tags/adventure" } ], comments: [ { name: "pedro345", text: "Great article!" } ] } )
저자 컬렉션
db.authors.insertOne( { _id: 987, name: "alice123", email: "alice@mycompany.com", avatar: "photo1.jpg" } )
다음 단계
애플리케이션 데이터의 관계를 매핑한 후 스키마 설계 프로세스의 다음 단계는 디자인 패턴을 적용하여 스키마를 최적화하는 것입니다. 디자인 패턴 적용을 참조하세요.