참고
클라우드의 MongoDB deployment를 위한 완전 관리형 서비스인 MongoDB Atlas와 관련된 용어는 Atlas 문서의 용어집을 참조하세요.
- $cmd
- MongoDB의 데이터베이스 명령을 노출하는 가상 컬렉션입니다. 데이터베이스 명령을 사용하려면 명령 실행을 참조하세요.
- _id
- 모든 MongoDB 문서에 필요한 필드입니다. _id 필드는 고유한 값을 가져야 합니다.
_id필드를 문서의 프라이머리키로 생각할 수 있습니다._id필드 없이 새 문서를 만드는 경우 MongoDB는 자동으로 필드를 만들고 필드에 고유한 BSON ObjectId를 할당합니다. - 축적자
- 집계 파이프라인의 문서 간 상태를 유지하는 집계 파이프라인 표현식입니다. 축적자 연산 목록은
$group을 참조하세요. - 조치
- 사용자가 리소스에 수행할 수 있는 작업입니다. 작업과 리소스가 결합되어 권한을 생성합니다. 작업를 참조하세요.
- 관리 데이터베이스
- 권한이 있는 데이터베이스입니다. 특정 관리 명령을 실행하려면 사용자에게
admin데이터베이스에 대한 액세스 권한이 있어야 합니다. 관리 명령 목록은 관리 명령을 참조하세요. - 집계
- 대규모 데이터를 줄이고 요약하는 작업입니다. 자세한 내용은 집계 연산을 참조하세요.
- 집계 파이프라인
- 문서를 프로세스 하나 이상의 단계로 구성됩니다. 집계 파이프라인은 복잡한 쿼리를 Express 위한 풍부한 구문을 제공합니다. 단계 목록은 애그리게이션 단계를 참조하세요.
- 중재자
- 선거에서 투표하기 위해 존재하는 복제본 세트 멤버입니다. 중재자는 데이터를 복제하지 않습니다. 중재자는 프라이머리 투표에 참여하지만 프라이머리가 될 수는 없습니다. 자세한 내용은 복제본 세트 중재자를 참조하세요.
- Atlas
- MongoDB Atlas는 클라우드에 호스팅되는 서비스형 데이터베이스입니다.
- 원자 조작
- 원자 조작은 완전히 완료되거나 전혀 완료되지 않는 쓰기 작업입니다. 여러 문서에 쓰기를 포함하는 분산 트랜잭션의 경우 트랜잭션이 성공하려면 각 문서에 대한 모든 쓰기가 성공해야 합니다. 원자 조작은 부분적으로 완료할 수 없습니다. 원자성과 트랜잭션을 참조하세요.
- 인증
- 사용자 ID를 확인합니다. 자체 관리형 배포에 대한 인증을 참조하세요.
- 권한 부여
- 데이터베이스 및 작업에 대한 액세스 프로비저닝입니다. 자체 관리 배포의 역할 기반 액세스 제어를 참조하세요.
- 자동 암호화
- 사용 중 암호화를 사용하는 경우 미리 구성된 암호화 스키마에 따라 자동으로 암호화 및 암호 해독을 수행합니다. 자동 암호화 공유 라이브러리는 MongoDB Query Language를 올바른 호출로 변환하므로 특정 암호화 및 암호 해독 호출을 위해 애플리케이션을 다시 작성할 필요가 없습니다.
- B-트리
- 데이터베이스 관리 시스템에서 인덱스를 저장하는 데 일반적으로 사용되는 데이터 구조입니다. MongoDB는 B-트리 인덱스를 사용합니다.
- 백업 커서
- 백업 파일 목록을 가리키는 테일 커서(tailable cursor)입니다. 백업 커서는 내부 전용입니다.
- 밸런서
- 샤딩된 클러스터의 컨텍스트에서 실행되고 청크 마이그레이션을 관리하는 내부 MongoDB 프로세스입니다. 관리자는 샤딩된 클러스터의 모든 유지 관리 작업에 대해 밸런서를 비활성화해야 합니다. 샤딩된 클러스터 밸런서를 참조하세요.
- 빅 엔디안
멀티바이트 데이터 값의 최상위 바이트(빅 엔드)가 최하위 메모리 주소에 저장되는 바이트 순서입니다.
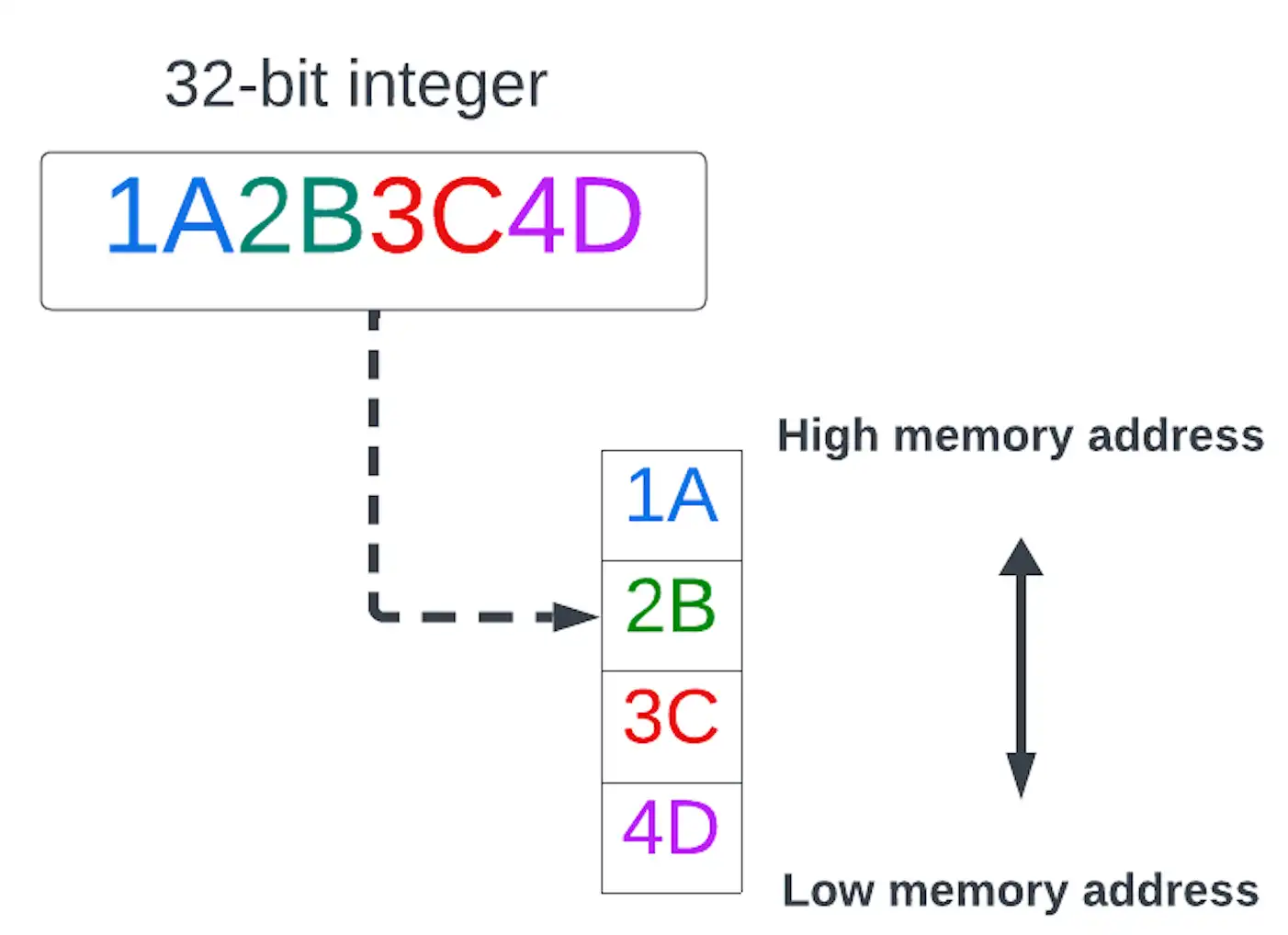 클릭하여 확대
클릭하여 확대- 차단 정렬
- 출력이 반환되기 전에 메모리에서 수행되어야 하는 정렬입니다. 메모리 내 정렬은 대규모 데이터 세트의 성능에 영향을 미칠 수 있습니다. 메모리 내 정렬을 피하려면 인덱스 정렬을 사용하세요.
- 제한된 컬렉션 스캔
- 특정 필드 값 범위를 가진 문서를 제외하는 쿼리 옵티마이저 도구에서 사용하는 계획입니다. 예를 들어 날짜 필드 값의 범위가 지정된 날짜 범위를 벗어나는 경우, 해당 범위의 문서는 쿼리 계획에서 제외됩니다. 컬렉션 스캔을 참조하세요.
- BSON
- MongoDB에서 문서를 저장하고 원격 프로시저 호출을 수행하는 데 사용되는 직렬화 형식입니다. "BSON" 은 "바이너리"와 "JSON"의 합성어입니다. BSON을 JSON(JavaScript Object Notation) 문서의 바이너리 표현으로 생각하세요. BSON types 및 MongoDB 확장 JSON(v2)을 참조하세요.
- BSON types
- BSON 직렬화 형식에서 지원하는 유형 세트입니다. BSON types 목록은 BSON types를 참조하세요.
- CAP 이론
- 컴퓨팅 시스템의 세 가지 속성, 즉 일관성, 가용성 및 파티션 허용 범위를 고려할 때 분산된 컴퓨팅 시스템은 이러한 기능 중 두 가지를 제공할 수 있지만 이 세 가지 기능을 모두 제공할 수는 없습니다.
- 고정 사이즈 컬렉션.
- 컬렉션이 최대 크기에 도달하면 가장 오래된 항목을 자동으로 덮어쓰는 크기가 고정된 컬렉션입니다. 복제에 사용되는 MongoDB oplog는 고정 사이즈 컬렉션입니다. 자세한 내용은 고정 사이즈 컬렉션을 참조하세요.
- 카디널리티
- 값 세트 내 요소 수의 측정값입니다. 예를 들어
A = { 2, 4, 6 }세트는 3개의 요소를 포함하며, 카디널리티는 3입니다. 샤드 키 카디널리티를 참조하세요. - 데카르트 곱
- 두 데이터 세트를 결합한 결과, 결합된 세트에 가능한 모든 값 조합이 포함됩니다.
- cfq
- 완전한 공정성 대기열(cfq)은 들어오는 요청 프로세스에 대역폭을 할당하는 I/O 작업 스케줄러입니다.
- 체크섬
- 데이터 무결성을 보장하기 위해 사용되는 계산된 값입니다. md5 알고리즘은 체크섬으로 사용되기도 합니다.
- 청크
- 샤드 내의 연속적인 샤드 키 값 범위 . 청크 범위에는 하한선이 포함되고 상한선은 제외됩니다. MongoDB 클러스터 내부에서 데이터의 균형을 맞춰야 할 때 청크를 분할합니다. 기본값 청크 크기는 128 메가바이트이지만 자동 분할 트리거하지 않고도 청크가 기본값 크기보다 커질 수 있습니다. 청크 분할은 클러스터 전체에 데이터를 균등하게 분산하기 위한 밸런싱 프로세스 의 일부로 발생합니다. 자세한 내용은 청크를 사용한 데이터 분할, 클러스터 밸런서, 및 클러스터 밸런서 관리를 참조하세요.
- 고객
데이터 지속성 및 저장을 위해 데이터베이스를 사용하는 애플리케이션 계층입니다. 드라이버는 애플리케이션 계층과 데이터베이스 서버 간의 인터페이스 수준을 제공합니다.
클라이언트는 단일 스레드 또는 프로세스가 될 수도 있습니다.
- 클라이언트 선호도
- 지정된 데이터 소스에 대한 일관된 클라이언트 연결입니다.
- cluster
- 자세한 내용은 샤딩된 클러스터를 참조하세요.
- Cluster-to-Cluster Sync
- 샤딩된 클러스터 간에 데이터를 동기화합니다. C2C 동기화라고도 합니다.
- 클러스터형 컬렉션
- 클러스터형 인덱스 키로 순서가 지정된 문서를 저장하는 컬렉션입니다. 클러스터형 컬렉션을 참조하세요.
- CMK
- 고객 마스터 키의 약자입니다. 고객 마스터 키를 참조하세요.
- 컬렉션
- MongoDB 문서의 그룹화입니다. 컬렉션은 RDBMS 테이블과 동일합니다. 컬렉션은 하나의 데이터베이스에 있습니다. 컬렉션은 스키마를 적용하지 않습니다. 컬렉션의 문서에는 다양한 필드가 있을 수 있습니다. 일반적으로 컬렉션에 있는 문서들은 용도가 비슷하거나 관련되어 있습니다. 네임스페이스를 참조하세요.
- 컬렉션 스캔
- 컬렉션 스캔은 MongoDB가 컬렉션의 모든 문서를 검사하여 쿼리 기준과 일치하는지 확인해야 하는 쿼리 실행 전략입니다. 이러한 쿼리는 매우 비효율적이며 인덱스를 사용하지 않습니다. 쿼리 실행 전략에 대한 자세한 내용은 쿼리 최적화를 참조하세요.
- 커밋
startSession명령 시작 후 변경된 데이터를 저장합니다. 트랜잭션 내의 작업은commitTransaction명령으로 커밋될 때까지 영구적으로 유지되지 않습니다.- 쿼럼 커밋
- 인덱스 빌드 중에 쿼럼 커밋은 프라이머리 노드가 커밋을 수행하기 전에 얼마나 많은 세컨더리 노드가 로컬 인덱스 빌드를 커밋할 준비가 되어 있어야 하는지를 지정합니다.
- 복합 인덱스
- 두 개 이상의 키로 구성된 인덱스입니다. 자세한 내용은 복합 인덱스를 참조하세요.
- 동시성 제어
- 동시성 제어는 정확성을 손상시키지 않고 데이터베이스 작업을 동시에 실행할 수 있도록 보장합니다. 잠금 기능이 있는 시스템에서 사용되는 것과 같은 비관적 동시성 제어는 충돌하지 않더라도 잠재적으로 충돌할 수 있는 모든 작업을 차단합니다. WiredTiger 에서 사용하는 접근 방식인 낙관적 동시성 제어는 충돌이 발생할 때까지 검사를 지연하여 쓰기 충돌에서 작업 중 하나를 종료하고 다시 시도합니다.
- config database
- 샤딩된 클러스터에 대한 메타데이터가 포함된 내부 데이터베이스입니다. 일반적으로
config데이터베이스를 수정하지 않습니다.config데이터베이스에 대한 자세한 내용은 config 데이터베이스를 참조하세요. - config server
- 샤딩된 클러스터와 연결된 모든 메타데이터를 저장하는
mongod인스턴스입니다. config 서버를 참조하세요. - 연결 풀
- 드라이버가 유지 관리하는 데이터베이스 연결 캐시입니다. 캐시된 연결은 새 연결을 여는 대신 데이터베이스에 대한 연결이 필요할 때 다시 사용됩니다.
- 연결 폭풍
- 드라이버가 해당 배포서버가 처리할 수 있는 것보다 더 많은 연결을 배포에 열려고 시도하는 시나리오입니다. 새 연결 요청이 실패하면 드라이버는 배포서버 속도가 느려지거나 새 연결을 열지 못하는 것에 대응하여 더 많은 연결을 설정하도록 요청합니다. 이러한 지속적인 요청은 배포서버에 과부하를 일으켜 장애가 발생할 수 있습니다.
- container
- 컴퓨팅 환경 간 전송을 용이하게 하기 위해 함께 패키징되는 소프트웨어 및 종속 라이브러리의 컬렉션 세트입니다. Container는 운영 체제에서 구획화된 프로세스로 실행되며 자체 리소스 제약이 적용될 수 있습니다. 일반적인 컨테이너 기술로는 Docker와 Kubernetes가 있습니다.
- 경합 요인
- 문서 필드 등에서 동일한 리소스를 수정하려는 다중 작업이 발생하면 충돌이 발생해 작업이 지연됩니다. 경합 요인은 암호화된 필드/값 쌍을 내부적으로 분할하고 작업을 최적화하기 위해 Queryable Encryption과 함께 사용되는 설정입니다. 경합을 참조하세요.
- CRUD
- 데이터베이스의 기본 작업인 생성(Create), 읽기(Read), 업데이트(Update) 및 삭제(Delete)에 대한 약어입니다. MongoDB CRUD 작업을 참조하세요.
- CSV
- 쉼표로 구분된 값을 포함하는 텍스트 데이터 형식입니다. CSV 파일에는 표 형식의 데이터가 있으므로 관계형 데이터베이스 간에 데이터를 교환하는 데 CSV 파일을 사용할 수 있습니다.
mongoimport를 사용하여 CSV 파일을 가져올 수 있습니다. - cursor
- 쿼리 결과 설정하다 에 대한 포인터입니다. 클라이언트는 커서 반복하여 결과를 조회 할 수 있습니다. 기본값 으로 세션 내에서 열리지 않은 커서는 10 분 동안 사용하지 않으면 자동으로 시간 초과됩니다. 세션에서 열린 커서는 세션이 종료되거나 시간 초과되면 닫힙니다. 커서를 참조하세요.
- 고객 마스터 키
- 데이터 암호화 키를 암호화하는 키입니다. 고객 마스터 키는 원격 키 제공자에서 호스팅되어야 합니다.
- 데몬
- 비대화형 백그라운드 프로세스입니다.
- 데이터 디렉토리
mongod가 데이터 파일을 저장하는 파일 시스템 위치입니다.dbPath는 데이터 디렉토리를 지정합니다.- 데이터 암호화 키
- MongoDB 문서의 필드를 암호화하는 데 사용하는 키입니다. 암호화된 데이터 암호화 키는 키 볼트 컬렉션에 저장됩니다. 데이터 암호화 키는 고객 마스터 키로 암호화됩니다.
- 데이터 파일
- 문서 데이터와 인덱스를 저장합니다.
dbPath옵션은 데이터 파일의 파일 시스템 위치를 지정합니다. - 데이터 파티션
- 데이터를 범위로 분할하는 분산된 시스템 아키텍처입니다. 샤딩은 분할을 사용합니다. 청크를 사용한 데이터 분할을 참조하세요.
- 데이터 센터 인식
- 클라이언트가 위치를 기반으로 시스템 멤버의 주소를 지정할 수 있도록 하는 속성입니다. 복제본 세트는 태그 지정 기능을 사용해 데이터 센터 인식을 구현합니다. 자세한 내용은 데이터 센터 인식을 참조하세요.
- database
- 컬렉션을 보관하는 컨테이너입니다. 각 데이터베이스에는 파일 시스템에 여러 파일이 있습니다. 하나의 MongoDB Server에는 일반적으로 여러 데이터베이스가 있습니다.
- 데이터베이스 명령
- 삽입, 업데이트, 제거 또는 쿼리 이외의 MongoDB 작업입니다. 데이터베이스 명령어 목록은 데이터베이스 명령어를 참조하세요. 데이터베이스 명령을 사용하려면 명령 실행을 참조하세요.
- database profiler
- 활성화 시 데이터베이스의
system.profile컬렉션에 있는 모든 장기 실행 작업에 대한 기록을 유지하는 도구입니다. 프로파일러는 느린 쿼리를 진단하는 데 가장 자주 사용됩니다. 데이터베이스 프로파일러를 참조하세요. - dbpath
- MongoDB의 데이터 파일 스토리지 위치입니다.
dbPath를 참조하세요. - DDL(데이터 정의 언어)
- DDL에는 collection과 인덱스를 만들고 수정하는 명령이 포함되어 있습니다.
- 데드 레터 큐
- 데드 레터 큐는 수집 중 오류가 발생하는 문서를 저장하는 Atlas 데이터베이스 내의 collection입니다.
- DEK
- 데이터 암호화 키입니다. 자세한 내용은 데이터 암호화 키를 참조하세요.
- 지연 멤버
- 프라이머리가 될 수 없으며 지정된 지연 시 연산을 적용하는 복제본 세트 노드입니다. 지연은 사람의 실수(의도치 않게 삭제된 데이터베이스)나 프로덕션 데이터베이스에 예상치 못한 영향을 미치는 업데이트로부터 데이터를 보호하는 데 유용합니다. 지연된 복제본 세트 노드를 참조하세요.
- 문서
- MongoDB 컬렉션 기록이자 MongoDB의 기본 데이터 단위입니다. 문서는 JSON 객체와 유사하지만 BSON이라는 보다 다양한 형식으로 데이터베이스에 존재합니다. 문서를 참조하세요.
- 점 표기법
- MongoDB는 점 표기법을 사용하여 배열의 요소에 액세스하고 내장된 문서의 필드에 액세스합니다. 점 표기법을 참조하세요.
- 배출
- 한 샤드에서 다른 샤드로 청크를 흘리거나 제거하는 프로세스입니다. 관리자는 클러스터에서 샤드를 제거하기 전에 샤드를 비워야 합니다. 기존 샤딩된 클러스터에서 샤드 제거를 참조하세요.
- 드라이버
- 특정 컴퓨터 언어로 MongoDB와 상호 작용하기 위한 클라이언트 라이브러리입니다. 드라이버를 참조하세요.
- 지속형
- 하나 이상의 서버 프로세스가 종료(또는 충돌)되고 다시 시작된 후에도 지속되는 쓰기 연산은 지속형입니다. 단일
mongod서버의 경우 쓰기 연산은 서버의 저널 파일에 기록되면 지속형인 것으로 간주됩니다. 복제본 세트의 경우 쓰기 연산은 과반수 투표 노드에서 지속성을 달성하고 과반수 투표 노드의 저널에 기록되면 지속형인 것으로 간주됩니다. - 투표
- 복제본 세트의 노드가 시작 시 및 오류 발생 시 프라이머리를 선택하는 프로세스입니다. 복제본 세트 투표를 참조하세요.
- 엔디안
- 컴퓨팅에서 엔디안은 바이트가 배열되는 순서를 의미합니다. 이러한 순서는 통신 매체를 통한 전송을 의미하거나, 더 일반적으로는 바이트가 중요도와 위치에 따라 컴퓨터 메모리에 정렬되는 방식을 의미합니다. 자세한 내용은 빅 엔디안 및 리틀 엔디안을 참조하세요.
- 봉투 암호화
- 데이터 암호화 키를 사용하여 데이터를 암호화하고 데이터 암호화 키를 고객 마스터 키라는 다른 키로 암호화하는 암호화 절차입니다. 암호화된 키는 키 볼트라는 MongoDB 컬렉션에 BSON 문서로 저장됩니다.
- 궁극적 일관성
- 시스템에 대한 변경 사항이 점진적으로 전파되도록 허용하는 분산된 시스템의 속성입니다. 데이터베이스 시스템에서 이는 읽기 가능 멤버가 최신 업데이트를 가질 필요가 없음을 의미합니다.
- 명시적 암호화
- 사용 중 암호화를 사용하는 경우, 암호화된 데이터로 작업할 때 암호화 또는 복호화 작업, keyID, 쿼리 유형(Queryable Encryption의 경우)이나 알고리즘(클라이언트 사이드 필드 레벨 암호화의 경우)을 명시적으로 지정합니다. 자동 암호화와 비교하세요.
- 표현식
값으로 확인되는 쿼리의 구성 요소입니다. 표현식은 상태를 저장하지 않습니다. 즉 표현식을 작성하는 데 사용되는 값을 변경하지 않고 값을 반환합니다.
MongoDB 쿼리 언어에서는 다음 구성 요소에서 표현식을 빌드할 수 있습니다.
구성 요소예시상수
3연산자
필드 경로 표현식
"$<path.to.field>"예시 를 들어
{ $add: [ 3, "$inventory.total" ] }은$add연산자 와 두 개의 피연산자로 구성된 표현식 입니다.상수
3필드 경로 표현식
"$inventory.total"
표현식은 입력 문서의 경로
inventory.total에 있는 값에 3을 더한 결과를 반환합니다.- 장애 조치
- 오류가 발생할 경우 복제본 세트의 세컨더리 노드가 프라이머리가 될 수 있도록 하는 프로세스입니다. 자동 페일오버를 참조하세요.
- 필드
- 문서의 이름-값 쌍입니다. 문서에 필드가 0개 이상 있습니다. 필드는 관계형 데이터베이스의 열과 유사합니다. 문서 구조를 참조하세요.
- 필드 경로
- 문서 내 필드의 경로입니다. 필드 경로를 지정하려면 필드 이름 앞에 달러 기호(
$)를 붙이는 문자열을 사용합니다. - 방화벽
- IP 주소 및 기타 매개 변수를 기반으로 액세스를 제한하는 시스템 수준 네트워크 필터입니다. 방화벽은 보안 네트워크의 일부입니다. 방화벽을 참조하세요.
- 무료 및 flex 클러스터
Free(프리 티어) 계층 클러스터를 포함하는 클러스터 카테고리입니다. 무료 및 Flex 클러스터는 일반적으로 개발 및 소규모 프로덕션 워크로드에 사용됩니다.- 프리 티어
- 데이터를 호스팅하다 소규모 개발 환경을 제공하는 무료 클러스터 계층 . 무료 클러스터는 만료되지 않으며, Atlas 의 하위 집합 에 대한 액세스 제공합니다.
- fsync
모든 더티 인메모리 페이지를 스토리지로 플러시하는 시스템 호출입니다. 애플리케이션이 데이터를 쓰면 MongoDB는 스토리지 계층에 데이터를 기록합니다.
지속형 데이터를 제공하려면 WiredTiger는 체크포인트를 사용합니다. 자세한 내용은 저널링 및 WiredTiger 스토리지 엔진을 참조하세요.
- geohash
- geohash 값은 좌표 격자상의 위치를 이진법으로 표현한 것입니다. geohash 값을 참조하세요.
- GeoJSON
- JavaScript Object Notation (JSON)을 기반으로 하는 지리 공간적 데이터 교환 형식입니다. GeoJSON은 지리 공간적 쿼리에 사용됩니다. 지원되는 GeoJSON 객체는 지리 공간적 데이터를 참조하세요. GeoJSON 형식 사양은 https://tools.ietf.org/html/rfc7946#section-31을 참조하세요. .
- 지리 공간
- 지리적 위치와 관련됩니다. 지리 공간전 쿼리를 참조하세요.
- GridFS.
- 대용량 파일을 MongoDB 데이터베이스에 저장하기 위한 규칙입니다. 모든 공식 MongoDB 드라이버는
mongofiles프로그램과 마찬가지로 GridFS 규칙을 지원합니다. 자체 관리형 배포용 GridFS를 참조하세요. - 해시 샤드 키
- 샤드 키 필드에 있는 값의 해시를 사용하여 샤딩된 클러스터의 노드 간에 문서를 배포하는 샤드 키 유형입니다. 해시된 인덱스를 참조하세요.
- 상태 관리자
- 상태 관리자는 지정된 강도 수준에서 상태 관리자 패싯에 대한 상태 확인을 실행합니다. 상태 관리자 검사는 지정된 시간 간격으로 실행됩니다. 실패한 mongos를 클러스터 밖으로 자동으로 이동하도록 상태 관리자를 구성할 수 있습니다.
- 상태 관리자 패싯
- 상태 관리자가 상태 확인을 실행하도록 구성할 수 있는 기능 집합입니다. 예를 들어 DNS 또는 LDAP 클러스터 상태 문제를 자동으로 모니터링하고 관리하도록 상태 관리자를 구성할 수 있습니다. 자세한 내용은 상태 관리자 패싯을 참조하세요.
- 숨겨진 멤버
- 프라이머리가 될 수 없고 클라이언트 애플리케이션에 표시되지 않는 복제본 세트 구성원입니다. 숨겨진 복제본 세트 구성원을 참조하세요.
- 고가용성
고가용성은 지속성, 중복성 및 자동 페일오버를 위해 설계된 시스템을 나타냅니다. 시스템에서 지원하는 애플리케이션은 오랫동안 다운타임 없이 작동할 수 있습니다. MongoDB 복제본 세트는 모범 사례에 따라 배포할 때 고가용성을 지원합니다.
복제본 세트 배포 아키텍처에 대한 지침은 복제본 세트 배포 아키텍처를 참조하세요.
- idempotent
- 한 연산을 여러 번 실행하면 동일한 입력으로 동일한 결과를 생성합니다.
- 메모리 내 정렬
출력이 반환되기 전에 메모리에서 수행되어야 하는 정렬입니다. 메모리 내 정렬은 대규모 데이터 세트의 성능에 영향을 미칠 수 있습니다. 메모리 내 정렬을 피하려면 인덱스 정렬을 사용하세요.
인덱스 정렬 작업에 대한 자세한 내용은 정렬 및 인덱스 사용을 참조하세요.
- 사용 중 암호화
- 전송, 저장, 처리될 때 데이터를 보호하고 암호화된 데이터에 대해 지원되는 쿼리를 활성화하는 암호화입니다. MongoDB는 사용 중 암호화에 대한 두 가지 접근 방식으로 Queryable Encryption과 클라이언트 사이드 필드 레벨 암호화를 제공합니다.
- index
- 쿼리를 최적화하는 데이터 구조입니다. 인덱스를 참조하세요.
- 인덱스 바운드
- 인덱스를 사용하여 쿼리를 실행할 때 MongoDB가 검색하는 인덱스 값의 범위입니다. 자세한 내용은 멀티키 인덱스 바운드를 참조하세요.
- 인덱스 서명
- 인덱스 고유하게 식별하는 매개변수의 조합입니다.
- 인덱스 정렬
- 인덱스가 정렬된 결과를 제공하는 정렬입니다. 인덱스를 사용하는 정렬 작업은 메모리 내 정렬보다 성능이 더 좋은 경우가 많습니다. 자세한 내용은 인덱스를 사용하여 쿼리 결과 정렬을 참조하세요.
- init script
- Linux 플랫폼의 init 시스템에서 데몬 프로세스를 시작, 재시작 또는 중지하는 데 사용하는 셸 스크립트입니다. 패키지 관리자를 사용하여 MongoDB를 설치한 경우 설치의 일부로 시스템에 init 스크립트가 제공됩니다. 운영 체제의 해당 설치 가이드를 참조하세요.
- init 시스템
- init 시스템은 커널이 시작된 후 Linux 플랫폼에서 가장 먼저 시작되는 프로세스로, 시스템의 다른 모든 프로세스를 관리합니다. init 시스템은 init 스크립트를 사용하여
mongod또는mongos와 같은 데몬 프로세스를 시작, 재시작 또는 중지합니다. 최신 Linux 버전은 일반적으로 systemd init 시스템과systemctl명령을 사용합니다. 이전 Linux 버전에서는 일반적으로 System V init 시스템과service명령을 사용합니다. 자세한 내용은 사용 중인 운영 체제의 설치 가이드를 참조하세요. - 초기 동기화
- 기존 복제본 세트 멤버의 데이터를 새 복제본 세트 멤버로 복제하는 복제본 세트 작업입니다. 초기 동기화를 참조하세요.
- 의도 락
- 잠금 보유자가 동시성 제어 사용하여 의도 잠금이 있는 리소스보다 더 세밀하게 리소스에서 읽기(의도 공유) 또는 쓰기(의도 배타) 할 것임을 나타내는 리소스에 대한 잠금입니다. 의도 잠금을 사용하면 리소스를 동시에 읽고 쓸 수 있습니다. MongoDB는 어떤 유형의 잠금을 사용하나요?를 참조하세요.
- 중단 지점
- 작업을 안전하게 종료할 수 있는 점입니다. MongoDB는 지정된 중단 지점에서만 작업을 종료합니다. 실행 중인 작업 종료를 참조하세요.
- IPv6
- 인터넷 호스트를 지원하기 위해 큰 주소 공간을 갖춘 IP(인터넷 프로토콜) 표준의 개정판입니다.
- ISODate
mongosh에서 날짜를 표시하는 데 사용하는 국제 날짜 형식입니다. 형식은YYYY-MM-DD HH:MM.SS.millis입니다.- JavaScript
- 스크립트 언어입니다. mongosh, 레거시
mongoshell 및 특정 서버 기능은 JavaScript 인터프리터를 사용합니다. 자세한 내용은 서버 측 JavaScript 를 참조하세요. - journal
- 강제 종료 시 데이터베이스를 유효한 상태로 만드는 데 사용되는 순차적인 바이너리 트랜잭션 로그입니다. 저널링은 먼저 데이터를 저널에 쓴 다음 핵심 데이터 파일에 기록합니다. 저널 파일은 미리 할당되어 데이터 디렉토리에 파일로 존재합니다. 저널링을 참조하세요.
- JSON
- JavaScript 객체 표기법. 다양한 프로그래밍 언어에서 지원 되는 구조화된 데이터를 표현하기 위한 일반 텍스트 형식입니다. 자세한 내용은 http://www.json.org를 참조하세요. 특정 MongoDB 도구는 대략적인 MongoDB BSON 문서를 JSON 형식으로 렌더링합니다. MongoDB 확장 JSON (v2)을 참조하세요.
- JSON 문서
- JSON 문서 구조화된 형식의 필드와 값의 컬렉션 입니다. 샘플 JSON 문서는 http://json.org/예시.html을 참조하세요.
- JSONP
- 패딩이 있는 JSON입니다. 애플리케이션에 JSON을 삽입하는 메서드를 나타냅니다. 잠재적인 보안 문제를 나타냅니다.
- 점보 청크
- 지정된 청크 사이즈 이상으로 커져서 더 작은 청크로 분할할 수 없는 청크를 말합니다. 자세한 내용은 분할 불가능/점보 청크를 참조하세요.
- 주 자료
- 데이터를 암호화하고 해독하기 위해 암호화 알고리즘에서 사용하는 임의의 비트 문자열입니다.
- 키 볼트 컬렉션
- 암호화된 데이터 암호화 키를 BSON 문서로 저장하는 MongoDB collection입니다.
- 최소 권한
- 사용자의 작업에 필수적인 액세스 권한만 사용자에게 부여하는 권한 부여 정책입니다.
- 레거시 좌표 쌍
- MongoDB 버전 2.4 이전의 지리 공간적 데이터에 사용되는 형식입니다. 이 형식은 지리 공간적 데이터를 평면 좌표계의 점으로 저장합니다(예시:
[ x, y ]). 지리 공간적 쿼리를 참조하세요. - 라인스트링
- 라인스트링 두 개 이상의 위치로 배열 입니다. 위치가 4개 이상인 닫힌 라인스트링 GeoJSON 라인스트링 사양( https://tools.ietf.org/html/rfc7946#section-3.1.4)에 설명된 대로 LinearRing이라고 합니다. MongoDB 에서 라인스트링 사용하려면 GeoJSON 객체를 참조하세요.
- little-endian
멀티바이트 데이터 값의 최하위 바이트(little end)가 최하위 메모리 주소 에 저장되는 바이트 순서입니다.
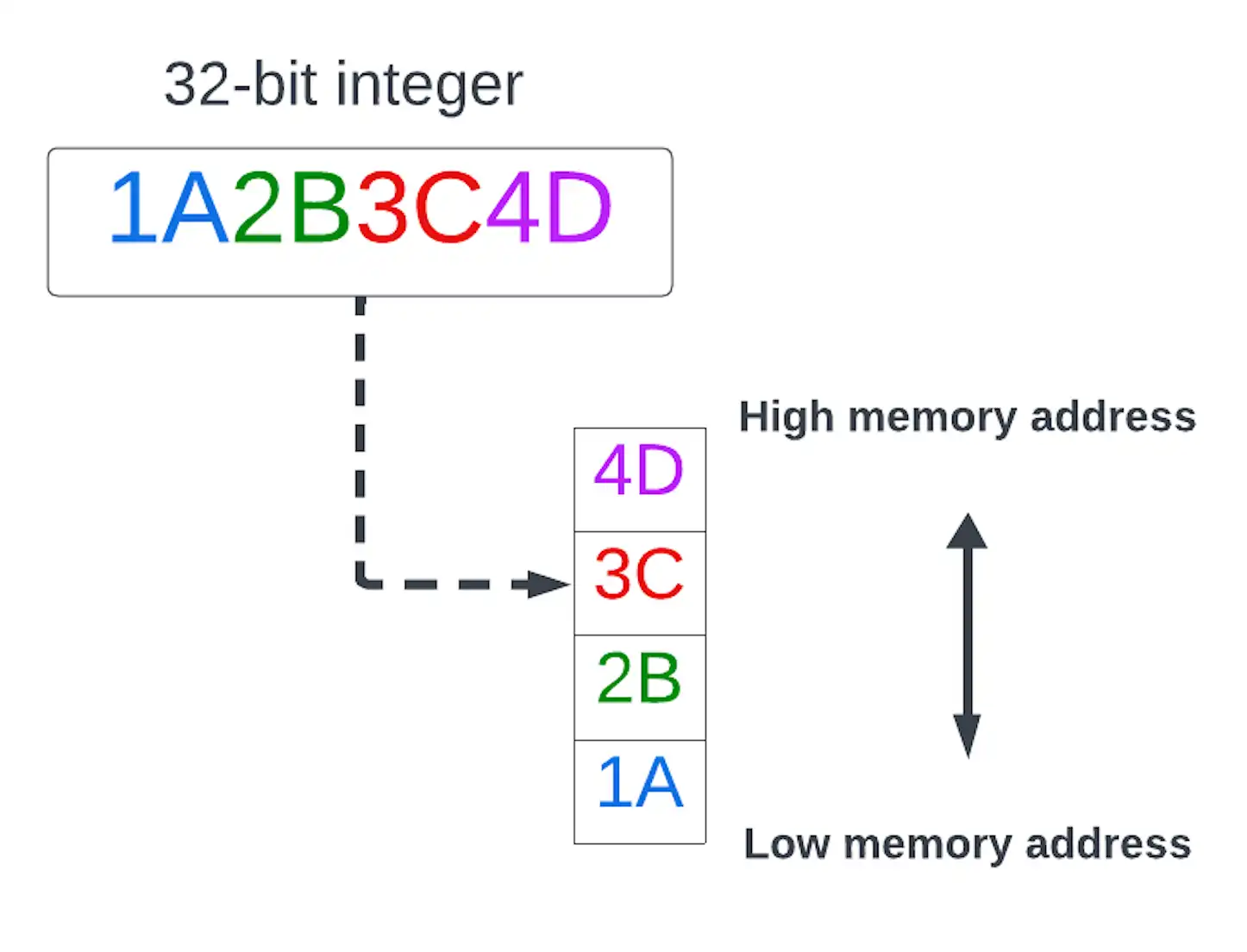 클릭하여 확대
클릭하여 확대- 락
- MongoDB는 잠금을 사용하여 동시성이 정확성에 영향을 미치지 않도록 합니다. MongoDB는 읽기 잠금, 쓰기 잠금 및 의도 잠금을 사용합니다. 자세한내용은 MongoDB가 사용하는 잠금 유형은 무엇인가요? 를 참조하세요.
- 로그 파일
- 수신 연결, 명령 실행, 발생한 문제 등의 서버 이벤트를 포함합니다. 자세한 내용은 로그 메시지를 참조하세요.
- LVM
- 논리 볼륨 관리자. LVM은 물리적 장치의 디스크 이미지를 추상화하고 시스템 관리에 유용한 여러 원시 디스크 조작 및 스냅샷 기능을 제공하는 프로그램입니다. LVM 및 MongoDB에 대한 자세한 내용은 Linux에서 LVM을 사용하여 백업 및 복원을 참조하세요.
- 맵 축소
- 데이터를 선택하는 '맵' 단계와 데이터를 변환하는 '리듀스' 단계로 구성된 집계 프로세스입니다. MongoDB에서는 맵 리듀스를 사용하여 데이터에 대한 임의의 집계를 실행할 수 있습니다. 맵 리듀스 구현에 대한 자세한 내용은 Map-Reduce를 참조하십시오. 집계에 대한 모든 접근 방식은 집계 작업을 참조하세요.
- 매핑 유형
- 키를 값과 연결하는 프로그래밍 언어의 구조입니다. 키에는 키와 값의 내장된 쌍이 포함될 수 있습니다(예시: 사전, 해시, 맵 및 연관 배열). 이러한 구조의 속성은 언어 사양 및 구현에 따라 달라집니다. 일반적으로 매핑 유형의 키 순서는 임의적이며 보장되지 않습니다.
- md5
- 제공된 데이터의 체크섬을 계산하는 해싱 알고리즘입니다. 알고리즘은 데이터를 식별하기 위해 고유한 값을 반환합니다. MongoDB는 md5를 사용하여 GridFS의 데이터 청크를 식별합니다. filemd5(데이터베이스 명령)를 참조하세요.
- MEAN
- 숫자 세트의 평균입니다.
- 중앙값
- 데이터세트에서 중앙값은 데이터의 50%가 해당 값 이하인 백분위 값입니다.
- 멤버
- 개별 Mongo 프로세스입니다. 복제본 세트에는 여러 멤버가 있습니다. 멤버를 노드라고도 합니다.
- metadata collection
- Queryable Encryption에서는 MongoDB가 암호화된 필드에 대한 쿼리를 활성화하기 위해 사용하는 내부 컬렉션입니다. 메타데이터 컬렉션을 참조하세요.
- MIME
- 다목적 인터넷 메일 확장 프로그램입니다. 여러 데이터 스토리지, 전송 및 이메일 컨텍스트에서 데이터의 인코딩 및 유형을 설정하는 데 사용되는 유형 및 인코딩 정의의 표준 세트입니다.
mongofiles도구는 GridFS 스토리지에 삽입된 파일을 설명하기 위해 MIME 유형을 지정하는 옵션을 제공합니다. - 모드
- 숫자 세트에서 가장 자주 발생하는 숫자입니다.
- mongo
레거시 MongoDB shell입니다.
mongo프로세스는mongod또는mongos인스턴스에 연결된 데몬으로 레거시 shell을 시작합니다. shell에는 JavaScript 인터페이스가 있습니다.MongoDB v5.0부터
mongo는 더 이상 사용되지 않으며 mongosh가mongo를 클라이언트 셸로 대체합니다. mongosh를 참조하세요.- mongod
- MongoDB database 서버입니다.
mongod프로세스는 MongoDB 서버를 데몬 으로 시작합니다. MongoDB Server는 데이터 요청과 백그라운드 작업을 관리합니다.mongod를 참조하세요. - mongos
- MongoDB 샤딩된 클러스터 쿼리 라우터입니다.
mongos프로세스는 MongoDB 라우터를 데몬으로 시작합니다. MongoDB 라우터는 애플리케이션과 MongoDB 샤딩된 클러스터 간의 인터페이스 역할을 하며 클러스터 전반에서 모든 라우팅 및 로드 밸런싱을 처리합니다.mongos인스턴스를 참조하세요. - mongosh
MongoDB Shell입니다. mongosh 는
mongod또는mongos인스턴스에 shell 인터페이스를 제공합니다.- namespace
- 네임스페이스는 데이터베이스 이름과 컬렉션 또는 인덱스 이름의 조합입니다(
<database-name>.<collection-or-index-name>). 모든 문서는 네임스페이스에 속합니다. 네임스페이스를 참조하세요. - 기본 순서
recordIds주문이 생성되어 WiredTiger 인덱스에 저장됩니다. 단일 인스턴스에서 실행되는 컬렉션 스캔의 정렬 순서 기본값은 기본 순서입니다.복제본 세트에서 기본 순서는 일관성을 보장하지 않으며 노드마다 다를 수 있습니다.
샤딩된 컬렉션에서는 기본 순서가 정의되지 않습니다. 그러나
$natural을 사용하면 각 샤드가 컬렉션 스캔을 수행하도록 할 수 있습니다.자세한 내용은 기본 순서로 반환을 참조하세요.
- 네트워크 파티션
분산된 시스템을 파티션으로 분리하여 한 파티션의 노드가 다른 파티션의 노드와 통신할 수 없도록 하는 네트워크 오류입니다.
파티션이 부분적이거나 비대칭인 경우도 있습니다. 부분 파티션의 예로는 네트워크의 노드를 세 개의 세트로 나누어 첫 번째 세트의 구성원은 두 번째 세트의 멤버와 통신할 수 없고, 그 반대로 모든 노드는 세 번째 세트의 멤버와 통신할 수 있는 경우를 들 수 있습니다.
비대칭 파티션에서는 특정 노드에서 시작되는 경우에만 통신이 가능할 수 있습니다. 예를 들어 파티션의 한 쪽에 있는 노드는 통신 채널을 생성한 경우에만 다른 쪽과 통신할 수 있습니다.
- node
- 개별 Mongo 프로세스입니다. 복제본 세트에는 여러 노드가 있습니다. 노드를 멤버라고도 합니다.
- 눕
- No Operation(눕)은 선입선출 대기열을 기반으로 수신 프로세스에 입출력 대역폭을 할당하는 I/O 작업 스케줄러입니다.
- NVMe
- NVMe(Non-Volatile Memory Express)는 고속 스토리지 미디어에 액세스하기 위한 프로토콜입니다.
- 객체 ID
- ObjectId를 참조하세요.
- ObjectId
- 컬렉션 내에서 고유한 12 바이트 BSON 유형입니다. ObjectId는 타임스탬프, 컴퓨터 ID, 프로세스 ID 및 일정한 값으로 증가하는 로컬 프로세스 카운터를 사용하여 생성됩니다. MongoDB는 _id 필드의 기본값으로 ObjectId 값을 사용합니다.
- 작업 로그
- oplog를 참조하세요.
- 작업 시간
- optime을 참조하세요.
- 연산자
$(으)로 시작하는 키워드는 쿼리 조건자, 표현식 및 집계 단계와 같은 MQL 구성 요소를 Express 데 사용됩니다. 예시 들어$gt는 MQL '보다 큰(greater than)' 연산자 입니다. 사용 가능한 연산자는 MongoDB 쿼리 언어 참조를 참조하세요.- oplog
- MongoDB 데이터베이스에 대한 논리적 쓰기의 순서가 지정된 기록을 저장하는 고정 사이즈 컬렉션입니다. oplog는 MongoDB에서 복제를 가능하게 하는 기본 메커니즘입니다. 복제본 세트 Oplog를 참조하세요.
- oplog 버퍼 컬렉션
리샤딩 작업 중에 생성되어 기증자 샤드의 oplog 항목을 저장하는 임시 컬렉션입니다.
oplog 버퍼 컬렉션은 기증자 샤드에서 oplog 항목이 삭제될 때 수신자 샤드가 해당 항목에 액세스할 수 있도록 보장합니다. 리샤딩이 완료되면 oplog 버퍼 컬렉션이 제거됩니다.
- oplog hole
- oplog 쓰기가 순서대로 이루어지지 않기 때문에 oplog에 일시적인 공백이 발생합니다. 복제본 세트 프라이머리는 배치 작업으로 oplog 항목을 병렬로 적용합니다. 그 결과, 배치에서 아직 작성되지 않은 항목으로 인해 oplog에 일시적인 공백이 발생할 수 있습니다.
- oplog window
- oplog 항목에는 타임스탬프가 기록되어 있습니다. oplog window는
oplog에서 가장 최근의 타임스탬프와 가장 오래된 타임스탬프 사이의 시간 차이입니다. 세컨더리 노드가 프라이머리 노드와의 연결이 끊어지는 경우 oplog 윈도우(oplog window) 내에서 연결이 복원된 경우에만 복제를 사용하여 다시 동기화할 수 있습니다. - optime
복제 oplog 위치에 대한 참조입니다. optime 값은 다음을 포함하는 문서입니다.
- 순서가 지정된 쿼리 계획
sort()순서와 일치하는 순서로 결과를 반환하는 쿼리 계획입니다. 쿼리 계획을 참조하세요.- 고아 커서
- 애플리케이션 코드에서 올바르게 닫히지 않거나 반복되지 않은 커서입니다. 고아 커서는 MongoDB deployment에서 성능 문제를 일으킬 수 있습니다.
- 고아 문서
샤딩된 클러스터에서 고아 문서는 다른 샤드의 청크로도 존재하는 샤드의 문서입니다. 이는 마이그레이션이 실패했거나 비정상적 종료로 인해 마이그레이션 정리가 완료되지 않았기 때문에 발생합니다.
청크 마이그레이션이 완료된 후 고아 문서는 자동으로 정리됩니다. 더 이상 고아 문서를 삭제하기 위해
cleanupOrphaned를 실행할 필요가 없습니다.- 수동형 멤버
members[n].priority가0이라서 프라이머리가 될 수 없는 복제본 세트의 멤버입니다. 우선순위 0 복제본 세트 멤버를 참조하세요.- 백분위
- 데이터 세트에서 백분위는 데이터의 해당 비율이 지정된 값 이하인 값입니다. 자세한 내용은 계산 고려 사항을 참조하세요.
- PID
- 프로세스 식별자입니다. UNIX와 유사한 시스템은 실행 중인 각 프로세스에 고유한 정수의 PID를 할당합니다. PID를 사용하여 실행 중인 프로세스를 검사하고 해당 프로세스에 신호를 보낼 수 있습니다.
/proc파일 시스템을 참조하세요. - 파이프
- 독립적인 프로세스가 데이터를 보내고 받을 수 있도록 하는 UNIX 유사 시스템의 통신 채널입니다. UNIX 셸에서 파이프 작업을 사용하면 사용자가 한 명령의 출력을 다른 명령의 입력으로 보낼 수 있습니다.
- 파이프라인
- 집계에 포함된 일련의 작업입니다. 집계 파이프라인을 참조하세요.
- 계획 캐시 쿼리 형태
- 쿼리 조건자, 정렬, 프로젝션 및 데이터 정렬의 조합입니다. MongoDB는 계획 캐시 쿼리 형태를 통해 동일한 쿼리를 식별하고 성능을 분석할 수 있습니다.
- 점
- GeoJSON 포인트 사양에 설명된 단일 좌표 쌍: https://tools.ietf.org/html/rfc7946#section-3.1.2. MongoDB 에서 포인트를 사용하려면 GeoJSON 객체를 참조하세요.
- 다각형
GeoJSON 다각형 사양에 설명된 LinearRing좌표 배열의 배열: https://tools.ietf.org/html/rfc7946#section-3.1.6입니다. 여러 개의 링이 있는 다각형의 경우 첫 번째는 외부 링이어야 하고 다른 하나는 내부 링 또는 구멍이어야 합니다.
MongoDB는 외부 링이 자체 교차하는 것을 허용하지 않습니다. 내부 링은 외부 루프 내에 완전히 포함되어야 하며 서로 교차하거나 겹칠 수 없습니다. GeoJSON 객체를 참조하세요.
- 후 이미지 문서 (post-image document)
- 삽입, 교체 또는 업데이트된 이후의 문서입니다. 전후 이미지를 포함하는 문서의 Change Streams 항목을 참조하세요.
- powerOf2Sizes
- 스토리지 재사용을 극대화하고 파편화를 줄이기 위해 각 문서에 공간을 할당하는 각 컬렉션에 대한 설정입니다.
powerOf2Sizes는 TTL 컬렉션의 기본값입니다. 컬렉션 설정을 변경하려면collMod를 참조하세요. - 전 이미지 문서(pre-image document)
- 문서가 교체, 업데이트 또는 삭제되기 전의 문서입니다. 전후 이미지를 포함하는 문서의 Change Streams 항목을 참조하세요.
- 사전 분할
- 데이터를 삽입하기 전에 수행하는 작업으로, 가능한 샤드 키 값의 범위를 청크로 분할하여 삽입이 용이하고 쓰기 처리량이 높습니다. 경우에 따라 사전 분할은 MongoDB 밸런서가 수행할 때까지 기다리지 않고 컬렉션을 수동으로 분할하여 샤딩된 클러스터에서 문서의 초기 배포를 신속하게 처리합니다. 샤딩된 클러스터에서 범위 생성을 참조하세요.
- 접두사 압축
- 동일한 인덱스 키 접두사를 메모리 페이지당 한 번만 저장하여 메모리 및 디스크 소비를 줄입니다. WiredTiger의 압축 동작에 대한 자세한 내용은 압축을 참조하세요.
- 기본
- 복제본 세트에서 프라이머리는 모든 쓰기 작업을 수신하는 멤버입니다. 프라이머리를 참조하세요.
- 기본 키
- 기록 고유한 불변 식별자입니다. RDBMS 소프트웨어에서 기본 키는 보통 각 행의
id필드에 저장된 정수입니다. MongoDB에서 _id 필드는 문서의 기본 키(일반적으로 BSON ObjectId)를 저장합니다. - 프라이머리 샤드
- 샤딩되지 않은 모든 컬렉션을 저장하는 샤드입니다. 프라이머리 샤드를 참조하세요.
- 우선 순위
- 복제본 세트에서 프라이머리가 될 가능성이 가장 높은 멤버를 결정하는 데 도움이 되는 구성 가능한 값입니다.
members[n].priority를 참조하세요. - 권한
- 지정된 리소스와 리소스에 허용된 조치의 조합입니다. 권한을 참조하세요.
- 프로젝션
- MongoDB 결과 설정하다 에서 반환하는 필드를 지정하는 쿼리 에 제공되는 문서 . 프로젝션에 대한 자세한 내용은 쿼리에서 반환할 프로젝트 필드를 참조하세요.
- 쿼리
- 읽기 요청입니다. MongoDB는
$문자로 시작하는 이름을 가진 쿼리 연산자를 포함하는 JSON 형식의 쿼리 언어를 사용합니다.mongosh에서는db.collection.find()및db.collection.findOne()메서드를 사용하여 쿼리를 실행할 수 있습니다. 쿼리 문서를 참조하세요. - 쿼리 프레임워크
- 작업을 처리하는 쿼리 옵티마이저와 쿼리 실행 엔진의 조합입니다.
- 쿼리 연산자
- 쿼리에서
$로 시작하는 키워드입니다. 예를 들어$gt는 '보다 큰(greater than)' 연산자입니다. 쿼리 연산자 목록은 쿼리 연산자를 참조하세요. - 쿼리 옵티마이저
- 쿼리 계획을 생성하는 프로세스입니다. 각 쿼리에 대해 옵티마이저는 쿼리를 가능한 한 효율적으로 결과를 반환하는 인덱스와 일치시키는 계획을 생성합니다. 옵티마이저는 쿼리가 실행될 때마다 쿼리 계획을 재사용합니다. 컬렉션이 크게 변경되면 옵티마이저는 새 쿼리 계획을 만듭니다. 쿼리 계획을 참조하세요.
- 쿼리 계획
- 쿼리 플래너가 선택한 가장 효율적인 실행 계획입니다. 자세한 내용은 쿼리 계획을 참조하세요.
- 쿼리 조건자
문서가 지정된 쿼리와 일치하는지를 나타내는 부울 값을 반환하는 표현식입니다. 예를 들어
{ name: { $eq: "Alice" } }는"name"필드의 값이 string"Alice"인 문서를 반환합니다.쿼리 조건자에는 더 복잡한 일치를 위한 하위 표현식과 연산자가 포함될 수 있습니다. 사용 가능한 쿼리 연산자를 보려면 쿼리 조건자를 참조하세요.
- 쿼리 형태
쿼리 조건자, 정렬, 프로젝션 및 데이터 정렬의 조합입니다. MongoDB는 쿼리 형태를 통해 논리적으로 동일한 쿼리를 식별하고 성능을 분석할 수 있습니다.
쿼리 조건자의 경우 필드 이름을 포함한 조건자의 구조만 중요합니다. 쿼리 조건자의 값은 중요하지 않습니다. 따라서 쿼리 조건자
{ type: 'food' }은(는) 쿼리 형태에 대한 쿼리 조건자{ type: 'utensil' }와(과) 동일합니다.동일한 쿼리 형태를 가진 느린 쿼리를 식별하는 데 도움이 되도록 각 쿼리 형태는 queryHash와 연결됩니다.
queryHash쿼리 형태의 해시를 나타내며 쿼리 형태에만 의존하는 16진수 문자열입니다.참고
다른 해시 함수와 마찬가지로, 두 개의 다른 쿼리 형태가 동일한 해시 값을 생성할 수 있습니다. 그러나 서로 다른 쿼리 형태 간에 해시 충돌이 발생할 가능성은 거의 없습니다.
- 범위
- 청크 내의 연속적인 샤드 키 값 범위입니다. 데이터 범위는 하한선을 포함하며 상한선은 제외합니다. MongoDB는 샤드가 다른 샤드에 비해 너무 많은 컬렉션 데이터가 포함된 경우 데이터를 마이그레이션합니다. 청크로 데이터 분할 및 샤드 클러스터 밸런서를 참조하세요.
- RDBMS
- 관계형 데이터베이스 관리 시스템입니다. 관계형 모델을 기반으로 하는 데이터베이스 관리 시스템으로, 일반적으로 SQL을 쿼리 언어로 사용합니다.
- readConcern
- 읽기 작업에 대한 격리 수준을 지정합니다. 예를 들어 읽기 고려를 사용하여 복제본 세트의 대다수 노드에 전파된 데이터만 읽을 수 있습니다. 읽기 고려를 참조하세요.
- 읽기 락
- 컬렉션이나 데이터베이스와 같은 리소스에 대한 공유 잠금은 보유하는 동안 동시 읽기만 허용하고 쓰기는 허용하지 않습니다. MongoDB는 어떤 유형의 잠금을 사용하나요?를 참조하세요.
- readPreference
- 클라이언트가 읽기 작업을 지시하는 방법을 결정하는 설정입니다. 읽기 설정은 샤드 복제본 세트를 포함한 모든 복제본 세트에 영향을 줍니다. 기본적으로 MongoDB는 읽기를 프라이머리로 보냅니다. 그러나 궁극적으로 일관된 읽기를 위해 읽기를 세컨더리로 보낼 수도 있습니다. 읽기 설정을 참조하세요.
- 복구
- 복제본 세트 멤버 상태는 멤버가 세컨더리 또는 프라이머리 활동을 시작할 준비가 되지 않았음을 나타냅니다. 복구 중인 멤버는 읽을 수 없습니다.
- replicaSet
- 복제 및 자동 페일오버를 구현하는 MongoDB Server의 클러스터입니다. MongoDB의 권장 복제 전략. 복제를 참조하세요.
- 복제
- 여러 데이터베이스 서버가 동일한 데이터를 공유할 수 있는 기능입니다. 복제는 데이터 중복성을 보장하고 로드 밸런싱을 가능하게 합니다. 복제를 참조하세요.
- 복제 지연
- 프라이머리 oplog의 마지막 작업과 특정 세컨더리에 적용된 마지막 작업 사이의 기간입니다. 일반적으로 복제 지연 시간을 가능한 한 짧게 유지하려고 합니다. 복제 지연을 참조하세요.
- 상주 메모리
- 현재 물리적 RAM에 저장되어 있는 애플리케이션 메모리의 하위 집합입니다. 상주 메모리는 가상 메모리의 하위 집합으로, 물리적 RAM 및 스토리지에 매핑된 메모리를 포함합니다.
- resource
- 데이터베이스, 컬렉션, 컬렉션 세트 또는 클러스터입니다. 권한은 지정된 리소스에 대한 조치를 허용합니다. 리소스를 참조하세요.
- 역할
- 지정된 리소스에 대한 조치를 허용하는 권한 집합입니다. 사용자에게 할당된 역할에 따라 리소스 및 작업에 대한 사용자의 액세스 권한이 결정됩니다. 보안을 참조하세요.
- rollback
- 모든 복제본 세트 멤버의 일관성을 보장하기 위해 쓰기 작업을 되돌리는 프로세스입니다. 복제본 세트 페일오버 중 롤백을 참조하세요.
- 보조
- 마스터 데이터베이스의 콘텐츠를 복제하는 복제본 세트 멤버입니다. 세컨더리 멤버는 읽기 요청을 실행할 수 있지만, 프라이머리 멤버만 쓰기 작업을 실행할 수 있습니다. 세컨더리를 참조하세요.
- 보조 인덱스
- 쿼리 엔진이 쿼리를 실행하기 위해 수행해야 하는 작업량을 최소화하여 쿼리 성능을 개선하는 데이터베이스 인덱스입니다. 인덱스를 참조하세요.
- 세컨더리 멤버
- 세컨더리를 참조하세요. 이는 세컨더리 노드라고도 합니다.
- 시드 목록
- 시드 목록은 드라이버와 클라이언트(예:
mongosh)에서 복제본 세트 구성의 초기 검색에 사용됩니다. 시드 목록은host:port쌍의 목록으로 제공될 수 있습니다(표준 연결 문자열 형식 또는 DNS 항목 참조). 자세한 내용은 SRV 연결 형식을 참조하세요. - 자체 관리
- 외부 관리 또는 타사 서비스가 아닌 개인 또는 조직이 설정 및 유지 관리하는 MongoDB 인스턴스입니다(예: MongoDB Atlas).
- 세트 이름
- 복제본 세트에 지정된 임의의 이름입니다. 복제본 세트의 모든 멤버는
replSetName설정 또는--replSet옵션으로 지정된 동일한 이름을 가져야 합니다. - 샤드
- 샤딩된 클러스터의 전체 데이터 세트 중 일부를 저장하는 단일
mongod인스턴스 또는 복제본 세트입니다. 일반적으로 프로덕션 배포서버에서는 모든 샤드가 복제본 세트의 일부인지 확인합니다. 샤드를 참조하세요. - 샤드 키
- MongoDB가 샤딩된 클러스터의 노드 간에 문서를 배포하는 데 사용하는 필드입니다. 샤드 키를 참조하세요.
- 샤딩된 클러스터
- 샤드 MongoDB 배포서버를 구성하는 노드 세트입니다. 샤딩된 클러스터는 config 서버, 샤드, 하나 이상의
mongos라우팅 프로세스로 구성됩니다. 샤딩된 클러스터 구성 요소를 참조하세요. - 샤딩
- 키 범위별로 데이터를 분할하고 둘 이상의 데이터베이스 인스턴스에 데이터를 분산하는 데이터베이스 아키텍처입니다. 샤딩을 통해 수평적 확장이 가능합니다. 샤딩을 참조하세요.
- 셸 헬퍼
- 데이터베이스 명령에 대한 간결한 구문이 있는
mongosh의 메서드입니다. 셸 헬퍼는 대화형 환경을 개선합니다.mongosh메서드를 참조하세요. - 단일 마스터 복제
- 단일 데이터베이스 인스턴스만 쓰기를 허용하는 복제 토폴로지입니다. 단일 마스터 복제는 일관성을 보장하며 MongoDB에서 사용하는 복제 토폴로지입니다. 복제본 세트 프라이머리 를 참조하세요.
- 스내피
- 효율적인 계산 요구 사항과 합리적인 압축률의 균형을 맞추는 압축/압축 해제 라이브러리입니다. 스내피는 MongoDB가 WiredTiger를 사용하기 위한 기본 압축 라이브러리입니다. 자세한 내용은 Snappy 및 WiredTiger 압축 문서를 참조하세요.
- 스냅샷
- 스냅샷은 특정 시점의
mongod인스턴스의 데이터의 복사본입니다. 전체 클러스터 또는 복제본 세트 또는 클러스터의 단일 config 서버에 대한 스냅샷 메타데이터를 조회할 수 있습니다. - 정렬 키
- 필드를 정렬할 때 비교되는 값입니다. MongoDB가 숫자가 아닌 필드에 대한 정렬 키를 결정하는 방법을 알아보려면 비교/정렬 순서를 참조하세요.
- split
- 샤딩된 클러스터의 청크 간 구분입니다. 청크를 사용한 데이터 분할을 참조하세요.
- SQL
- SQL(구조화된 쿼리 언어)은 관계형 데이터베이스와의 상호 작용에 사용됩니다.
- SSD
- 솔리드 스테이트 디스크. 기계식 하드 드라이브에 사용되는 회전식 플래터와 이동식 읽기/쓰기 헤드 대신 영구성을 위해 솔리드 스테이트 전자 장치를 사용하는 고성능 스토리지입니다.
- 오래된 읽기
- 오래된 읽기는 트랜잭션이 다른 트랜잭션에 의해 수정되었지만 아직 데이터베이스에 커밋되지 않은 오래된(부실한) 데이터를 읽는 경우를 말합니다.
- 독립형
mongod인스턴스는 단일 서버로 실행되며 복제본 세트의 일부로 작동하지 않습니다. 독립형 인스턴스를 복제본 세트로 변환하려면 독립형 자체 관리형 mongod를 복제본 세트로 변환을 참조하세요.참고
독립형 인스턴스는 노드가 하나뿐인 복제본 세트가 아닙니다.
- 스태시 컬렉션
리샤딩 작업 중 각 기증자 샤드에 대해 수신자 샤드에 생성되는 임시 컬렉션입니다.
스태시 컬렉션은 작업 충돌로 인해 즉시 삽입할 수 없는 문서를 임시로 보관합니다. 예를 들어, 문서의 샤드 키가 업데이트된 경우 이제 다른 샤드에 속하게 되며, 이 문서에 적용되는 작업 순서가 모호해질 수 있습니다. 수신자는 올바른 순서로 작업을 적용할 수 있을 때까지 이러한 문서를 스태시 컬렉션에 저장합니다.
- 단계 중단
복제본 세트의 프라이머리 멤버가 자신을 프라이머리 멤버에서 제거하고 세컨더리 멤버가 됩니다.
복제본 세트가 프라이머리와 연결이 끊어지면 보조 세트가 새로운 프라이머리를 선택합니다. 이전 프라이머리가 해당 선택을 알게 되면 단계를 중단하거나 복제본 세트에 세컨더리로 다시 연결합니다.
사용자가
replSetStepDown명령을 실행하면 프라이머리가 단계적으로 중단되어 복제본 세트가 새로운 프라이머리를 선택하게 됩니다.
- 스토리지 엔진
- 메모리와 디스크 모두에서 데이터가 저장되고 액세스되는 방식을 관리하는 데이터베이스의 일부입니다. 다양한 스토리지 엔진은 특정 작업에 대해 더 나은 성능을 발휘합니다. MongoDB에 내장된 스토리지 엔진에 대한 자세한 내용은 자체 관리형 배포를 위한 스토리지 엔진을 참조하세요.
- 저장 순서
- 기본 순서를 참조하세요.
- 엄격한 일관성
- 모든 노드가 시스템에 대한 최신 변경 사항을 포함하도록 요구하는 분산된 시스템의 속성입니다. 데이터베이스 시스템에서 이는 데이터를 제공할 수 있는 모든 시스템에 최신 쓰기가 포함되어야 함을 의미합니다.
- 주체 대체 이름
- 주체 대체 이름(SAN)은 X.509 인증서의 확장으로, 단일 보안 인증서가 보호할 수 있는 리소스를 지정하는 값 배열(예: IP 주소, 도메인 이름)을 허용합니다.
- 동기화
- 멤버가 프라이머리에서 데이터를 복제하는 복제본 세트 작업입니다. 동기화는 MongoDB가 멤버를 생성하거나 복원할 때 처음 발생하며, 이를 초기 동기화라고 합니다. 그런 다음 동기화가 지속적으로 발생하여 복제본 세트의 데이터에 대한 변경 내용으로 멤버를 업데이트합니다. 복제본 세트 데이터 동기화를 참조하세요.
- syslog
- UNIX 계열 시스템에서 로깅 정보를 제출하는 서버 및 프로세스에 대한 통일된 표준을 제공하는 로깅 프로세스입니다. MongoDB는 호스트의 시스템 로그 시스템으로 출력을 전송하는 옵션을 제공합니다.
syslogFacility를 참조하세요. - tag
복제본 세트 멤버에 적용되고 클라이언트가 데이터 센터 인식 작업을 실행하는 데 사용하는 라벨입니다. 복제본 세트와 함께 태그를 지정하는 방법에 대한 자세한 내용은 읽기 설정 태그 세트 목록을 참조하세요.
- tag set
- 0개 이상의 태그를 포함하는 문서입니다.
- 테일 커서(tailable cursor)
- 고정 사이즈 컬렉션의 경우 테일 커서(tailable cursor)는 클라이언트가 초기 커서의 결과를 모두 사용한 후에도 열린 상태로 유지되는 커서입니다. 클라이언트가 고정 사이즈 컬렉션에 새 문서를 삽입한 후에는 테일 커서(tailable cursor)가 계속해서 문서를 조회합니다.
- 텀
- 복제본 세트 멤버의 경우 투표 시도에 해당하는 단조롭게 증가하는 숫자입니다.
- Time Series 컬렉션
- 일정 기간 동안의 측정 시퀀스를 효율적으로 저장하는 컬렉션입니다. Time Series를 참조하세요.
- 토폴로지
MongoDB 인스턴스 배포 상태입니다. 다음을 포함합니다.
- 트랜잭션
- 읽기 또는 쓰기 작업 그룹입니다. 자세한 내용은 트랜잭션을 참조하세요.
- 트랜잭션 코디네이터
- 복제본 세트 또는 샤딩된 클러스터에서 트랜잭션을 관리하는 MongoDB 구성 요소입니다. 노드 간 다중 문서 트랜잭션의 실행과 완료를 조정하고 복잡한 작업을 원자 조작으로 처리할 수 있습니다.
- TSV
- 탭으로 구분된 값으로 구성된 텍스트 기반 데이터 형식입니다. 이 형식은 표 형식의 데이터에 적합하기 때문에, 일반적으로 관계형 데이터베이스 간에 데이터를 교환하는 데 사용됩니다.
mongoimport를 사용하여 TSV 파일을 가져올 수 있습니다. - TTL
- TTL(Time-to-Live)은 시스템이 정보를 삭제하거나 에이징하기 전에 지정된 정보가 캐시 또는 기타 임시 스토리지에 남아 있는 만료 시간 또는 기간입니다. MongoDB에는 TTL 컬렉션 기능이 있습니다. TTL을 설정하여 컬렉션에서 데이터 만료하기를 참조하세요.
- 바인딩되지 않은 배열
- 시간이 지남에 따라 지속적으로 커지는 배열입니다. 문서 필드 값이 무제한 배열인 경우 배열이 성능에 부정적인 영향을 미칠 수 있습니다. 일반적으로 무제한 배열을 피하도록 스키마를 설계하는 것이 좋습니다.
- 고유 인덱스
- 단일 컬렉션에서 특정 필드에 대한 고유성을 시행하는 인덱스입니다. 고유 인덱스를 참조하세요.
- unix epoch
- 1970년 1월 1일 00:00:00 UTC. 일반적으로 시간을 표현할 때 사용되며, 이 시점 이후의 시간(초 또는 밀리초)이 계산됩니다.
- 언오더드 쿼리 계획
sort()순서와 일치하지 않는 순서로 결과를 반환하는 쿼리 계획입니다. 쿼리 계획을 참조하세요.- 업그레이드
- MongoDB 의 한 버전에서 최신 버전으로 클러스터 변경하는 프로세스 입니다.
- 업서트
업데이트 작업을 위한 옵션입니다. 예를 들어
db.collection.updateOne(),db.collection.findAndModify()입니다. 업서트true인 경우 업데이트 작업은 다음 중 하나를 수행합니다.쿼리와 일치하는 문서를 업데이트합니다.
또는 일치하는 문서가 없는 경우 새 문서를 삽입합니다. 새 문서에는 업데이트 작업에 지정된 필드 값이 있습니다.
업서트에 대한 자세한 내용은 일치하는 문서가 없는 경우 새 문서 삽입(
Upsert)을 참조하세요.- 가상 메모리
- 애플리케이션의 작업 메모리로, 일반적으로 디스크와 물리적 RAM에 모두 존재합니다.
- 벽시계 시간
- 컴퓨터 프로그램 또는 계산이 시작되고 완료될 때까지의 시간입니다.
- WGS84
- MongoDB GeoJSON 객체에 대한 지리 공간적 쿼리를 위해 지구와 같은 구의 기하학을 계산하는 데 사용하는 기본값 참조 시스템 및 측지 데이텀입니다. "EPSG:4326: WGS 84" 사양( http://spatialreference.org/ref/epsg/4326/)을 참조하세요.
- 창 연산자
- 컬렉션의 문서 범위에서 값을 반환합니다. 창 연산자를 참조하세요.
- 작업 세트
- MongoDB가 가장 자주 사용하는 데이터입니다.
- 쓰기 고려
- 쓰기 작업이 성공했는지를 지정합니다. 쓰기 고려를 사용하면 애플리케이션에서 삽입 오류 또는 사용할 수 없는
mongod인스턴스를 감지할 수 있습니다. 복제본 세트의 경우 지정한 수의 구성원에 대한 복제를 확인하도록 쓰기 고려를 설정할 수 있습니다. 쓰기 고려를 참조하세요. - 쓰기 충돌
- 두 개의 동시 작업(그 중 하나 이상이 쓰기)이 낙관적 동시성 제어를 사용하는 스토리지 엔진에 대한 제약 조건을 위반하는 리소스를 사용하려고 하는 상황입니다. MongoDB는 충돌하는 쓰기 작업 중 하나를 자동으로 종료하고 다시 시도합니다.
- 쓰기 락
- 컬렉션이나 데이터베이스와 같은 리소스에 대한 배타적 잠금입니다. 프로세스가 리소스에 쓸 때 다른 프로세스가 해당 리소스에 쓰거나 읽지 못하도록 배타적 쓰기 잠금을 사용합니다. 잠금에 대한 자세한 내용은 FAQ: 동시성을 참조하세요.
- writeBacks
- 관련 청크를 담당하지 않는 샤드로 전송된 쓰기가 올바른 샤드에 적용되도록 보장하는 샤딩 시스템의 프로세스입니다. 자세한 내용은 로그에서
writebacklisten(이)가 무엇을 의미하나요? 및 writeBacksQueued를 참조하세요. - zlib
- MongoDB가 snappy를 사용하는 것에 비해 더 많은 CPU 비용으로 더 높은 압축률을 제공하는 데이터 압축 라이브러리입니다. 압축 라이브러리로 zlib를 사용하도록 WiredTiger를 구성할 수 있습니다. 자세한 내용은 http://www.zlib.net 및 WiredTiger 압축 설명서를 참조하세요.
- 영역
주어진 샤드 컬렉션에 대한 샤드 키 값의 범위를 기반으로 한 문서 그룹입니다. 샤딩된 클러스터의 각 샤드는 하나 이상의 구역에 있을 수 있습니다. 균형 잡힌 클러스트에서 MongoDB는 구역에 대한 읽기 및 쓰기를 해당 구역 내의 샤드에만 전달합니다. 자세한 내용은 구역 매뉴얼 페이지를 참조하세요.
구역은 MongoDB 3.2의 태그에 설명된 기능을 대체합니다.
- zstd
- zlib에 비해 더 높은 압축률과 낮은 CPU 사용량을 제공하는 데이터 압축 라이브러리입니다.