Guia de configuração do Atlas Stream Processing para usuários do Kafka Connector

Robert Walters15 min read • Published Aug 23, 2024 • Updated Aug 23, 2024





Avalie esse Tutorial


MongoDB O oferece duas interfaces principais — o conector MongoDB connector do Kafka (Kafka Connector) e Atlas Stream Processingo —para integrar seus dados operacionais MongoDB no com dados de streaming Apache Kafka do . Isso cria uma combinação poderosa ao criar aplicativos modernos orientados a eventos.
Esta postagem abordará:
- Noções básicas de configuração do Atlas Stream Processing
- Como se conectar a um tópico do Kafka e transmitir dados usando o Atlas Stream Processing
- Como transformar dados com o Atlas Stream Processing
- Como transmitir dados para o MongoDB Atlas
- Uma análise detalhada do ecossistema Kafka
- Componentes do núcleo
- Parâmetros de configuração equivalentes do Kafka Connector disponíveis para você no Atlas Stream Processing
- Limitações atuais do Atlas Stream Processing
Pré-requisitos:
- Conta do MongoDB Atlas
- Uma fonte Apache Kafka (neste exemplo, usaremos Redpanda)
- An Atlas Database
Observação: este artigo será atualizado com frequência à medida que continuamos o desenvolvimento do Atlas Stream Processing.
O Apache Kafka Connect é um componente de servidor opcional em um sistema do Apache Kafka. Esse componente facilita o streaming de dados entre Apache Kafka o e outros sistemas de dados, fornecendo conectores específicos da fonte de dados, como o MongoDB connector do para o Apache Kafka. Esses conectores podem se conectar às suas respectivas fontes de dados e ler/gravar dados em um tópico do Apache Kafka por meio da framework do Kafka Connect.
A implantação do Kafka Connect pode ser complicada e cara, pois envolve vários servidores com suporte a um modo distribuído que permite a escalabilidade e a disponibilidade dos trabalhadores de connector . Os fornecedores de nuvem facilitam a hospedagem dessa infraestrutura fornecendo o Kafka Connect como um serviço. Isso simplifica o gerenciamento de connector , mas também significa um alto custo por hora para executar a infraestrutura.
Em muitos cenários, com o MongoDB Atlas Stream Processing, você não precisa mais aproveitar o Kafka Connect ao mover dados de e para o Apache Kafka e MongoDB. O Atlas Stream Processing é um recurso do MongoDB Atlas que permite o processamento, a validação e a mesclagem contínuos de dados de streaming de fontes como o Apache Kafka e o MongoDB Change Streams. Atlas Stream Processing também simplifica a leitura e a gravação de dados Apache Kafka MongoDB entre Kafka o e MongoDB connector o Apache Kafka, sem precisar do Connect ou do para o .
Neste artigo, compararemos e contrastaremos os métodos para mover dados entre o Kafka e o MongoDB usando um fluxo de dados de exemplo. Começaremos com dados de origem no Apache Kafka e os processaremos usando uma função de janela. Então, vamos pousar os dados no MongoDB.
Primeiro, vamos usar o para o MongoDB connector Apache Kafka. Em seguida, definiremos as coisas no Atlas Stream Processing sem depender do Kafka Connect ou de qualquer infraestrutura extra, economizando custos de infraestrutura e tempo de gerenciamento.
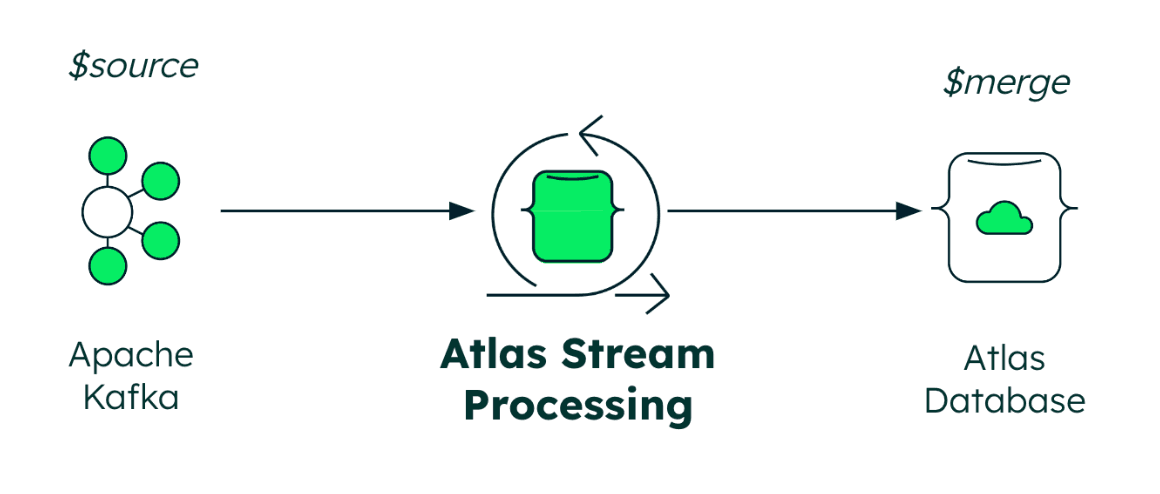
Você precisará acessar um Apache Kafka tópico Apache Kafka do com o Connect e o MongoDB connector para o Apache Kafka instalados. Observação: se você não tiver acesso a um ambiente, poderá usar o Docker script de composição disponível no MongoDB Kafka Connector Github repositório do de origem do . Como os dados residem no Kafka tópico , definimos o MongoDB connector para Apache Kafka como um coletor com a seguinte definição:
1 { 2 "name": "mongo-tutorial-sink", 3 "config": { 4 "connector.class": "com.mongodb.kafka.connect.MongoSinkConnector", 5 "topics": "Stocks", 6 "connection.uri": "mongodb://mongo1", 7 "key.converter": "org.apache.kafka.connect.storage.StringConverter", 8 "value.converter": "org.apache.kafka.connect.json.JsonConverter", 9 "value.converter.schemas.enable": false, 10 "database": "Stocks", 11 "collection": "StockData", 12 "mongo.errors.tolerance":"data", 13 "errors.tolerance":"all", 14 "errors.deadletterqueue.topic.name":"mongoerror", 15 "errors.deadletterqueue.topic.replication.factor":1 16 } 17 }
Para transformar seus dados, você precisará usar outro serviço, como o Apache Flink, para transmitir a saída da função de janela para outro tópico. Configurar isso e configurar a infraestrutura necessária está fora do escopo deste artigo. No entanto, você pode imaginar que há muitas partes móveis para fazer isso funcionar.
Em seguida, vamos dar uma olhada no Processamento de Stream do MongoDB Atlas Stream Processing.
Esta configuração é intencionalmente de alto nível. Para obter um tutorial passo a passo que inclui detalhes adicionais, como configuração de segurança, consulte o tutorialIntrodução ao Atlas Stream Processing em nossa documentação.
Usando a interface do usuário do MongoDB Atlas, faça login no seu projeto, clique em "Stream Processing " no menu de serviços e clique no botão "Create Instance ". Forneça um nome, "KafkaTestSPI, " e clique no botão "Create ".
Observação: para este passo a passo, você pode escolher qualquer camada disponível do Atlas Stream Processing Instance (SPI). A cobrança começa quando você executa trabalhos de processador de fluxo, não ao criar SPIs. Consulte a documentação para obter mais informações.
Depois de criar um SPI, clique em "Configure " e depois em "Connection Registry. ". Aqui, você definirá as conexões que o Atlas Stream Processing usará, como conexões com corretors Kafka ou outros clusters Atlas dentro de seu projeto Atlas.
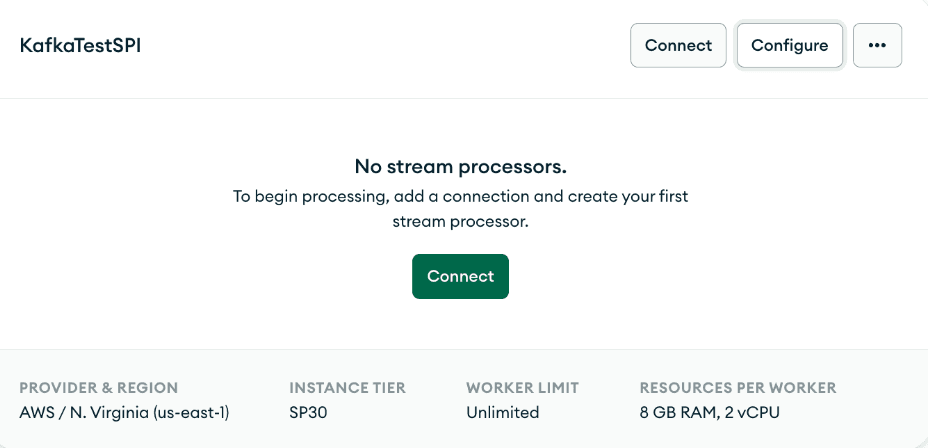
Em seguida, clique em "Create Connection " e selecione "Kafka. "
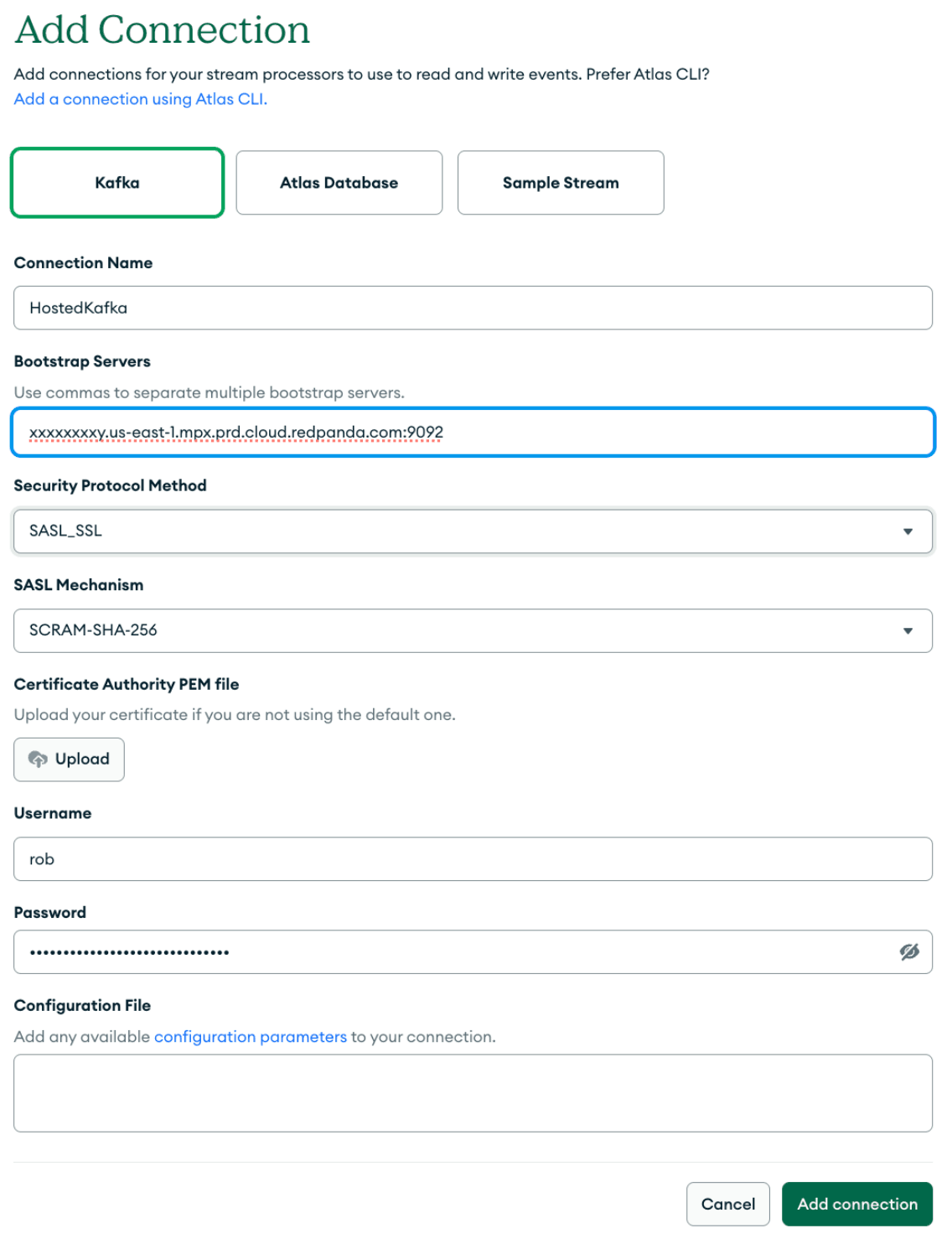
Atlas Stream Processing usa o Kafka Wire Protocol e pode se conectar a qualquer serviço compatível com Kafka , como Confluent Cloud, Redpanda Cloud, Amazon Web Services MSK ou Azure Event Hubs. Aceitamos configurações de segurança SASL_PLAINText e SASL_SSL.
Depois de adicionar a conexão ao Kafka, crie outra conexão e selecione "Atlas Database. " Dê um nome à conexão e selecione qualquer cluster do Atlas disponível em seu projeto atual.
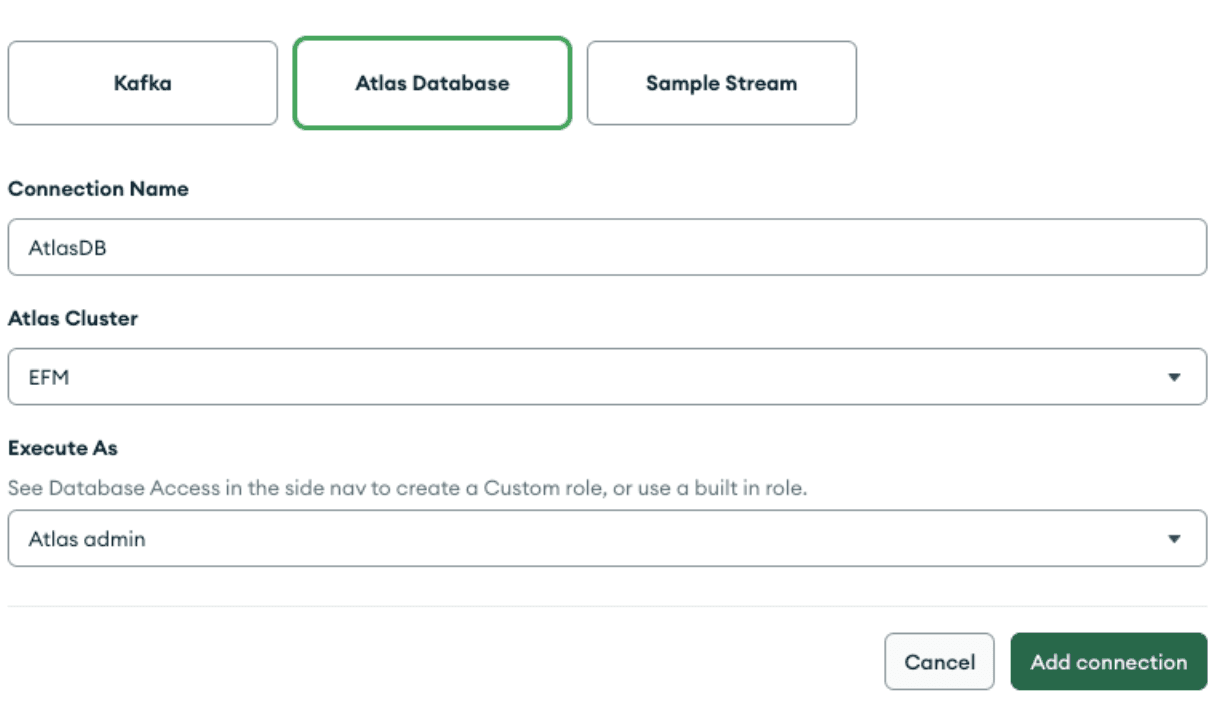
Agora que definimos uma conexão com nossa implantação do Kafka e uma conexão com nosso Atlas cluster, podemos nos conectar à instância de Processamento de Stream do Atlas e criar processadores de fluxo.
Ao contrário do MongoDB connector para Apache Kafka, nenhum arquivo de configuração define a origem e o coletor especificamente. Atlas Stream Processing usa conexões de registro de conexões para ambos os casos. O comportamento depende se a conexão é usada em um operador de pipeline Atlas Stream Processing $source ou$merge . Se a conexão for usada como $source, ela lerá os dados da conexão para o pipeline. Se o estiver gravando dados na conexão, ele usará $emit ou $merge dependendo se estiver gravando no Kafka ou MongoDB, respectivamente. Para demonstrar isso, vamos continuar o exemplo, criando um processador de fluxo que lerá dados de ($source) nosso Kafka tópico hospedado no e gravará dados ($merge) em nosso Atlas cluster.
Use o botão Conectar para se conectar à SPI "KafkaTestSPI " que criamos anteriormente. Isso iniciará uma caixa de diálogo de conexão familiar, como mostrado abaixo.
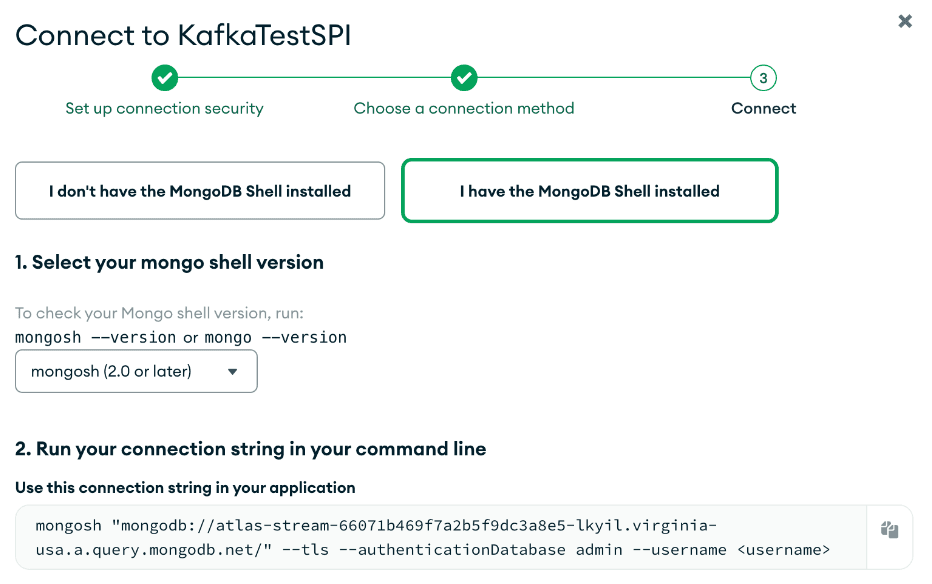
Usando uma conta de usuário de banco de dados, use o MongoDB Shell (mongosh) para se conectar ao SPI. Uma vez conectado, podemos construir o processador de fluxo definindo variáveis para cada estágio do pipeline e, por fim, combinando-as quando estivermos prontos para criar o processador de fluxo. Nosso tópico Kafka será preenchido com dados de estoque fictícios na forma do seguinte valor:
1 { 2 "exchange":"NASDAQ" 3 "company_symbol":"AHL" 4 "company_name":"AMUSED HAWK LABS" 5 "price":8.41 6 "tx_time":"2024-04-03T14:51:40Z" 7 }
Vamos criar a variável $source para nossa conexão HostedKafka.
1 s_kafka = { $source: { connectionName: "HostedKafka", "topic": "Stocks" } }
Em seguida, vamos criar uma janela em cascata a cada cinco segundos de dados.
1 tw = { $tumblingWindow: { interval: { size: 5, unit: "second" }, pipeline: [{ $group: { _id: "$company_symbol", max: { $max: "$price" }, avg: { $avg: "$price" } } }] } }
Observação: para ter uma ideia de como seria o fluxo de dados, podemos usar o arquivo .process comando, passando por cada estágio do pipeline e exibindo os resultados no console.
1 sp.process([s_kafka,tw])
Em seguida, vamos escrever esse fluxo de dados no Atlas cluster que definimos no registro de conexão.
1 m={$merge: { into: { connectionName: "AtlasSource",db: "Stock",coll: "StockReport" }}}
Por fim, vamos criar o processador de stream usando o comando createStreamProcessor.
1 sp.createStreamProcessor(‘mytestsp’,[s_kafka,tw,m])
Em seguida, iniciaremos o processador de fluxo emitindo o arquivo .start comando.
1 mytestsp.start()
Você pode visualizar estatísticas sobre seu processador de stream usando o .stats comando.
1 mytestsp.stats()
Aqui está um exemplo do resultado de retorno:
1 { 2 ok: 1, 3 ns: '66744a49d8619c0695a7e5e9.5e98cd46cd7309236ceaab3c.testsp', 4 stats: { 5 name: 'mytestsp', 6 processorId: '66780d901f7c0b19f89f559f', 7 status: 'running', 8 scaleFactor: Long('1'), 9 inputMessageCount: Long('633972'), 10 inputMessageSize: 280913520, 11 outputMessageCount: Long('296963'), 12 outputMessageSize: 475437763, 13 dlqMessageCount: Long('0'), 14 dlqMessageSize: 0, 15 stateSize: 3328, 16 memoryTrackerBytes: 33554432, 17 watermark: ISODate('2024-08-07T20:49:43.047Z'), 18 ok: 1 19 }, 20 pipeline: [ 21 { 22 '$source': { 23 connectionName: ‘HostedKafka’, 24 Topic: ‘Stocks’ 25 } 26 }, 27 { 28 '$tumblingWindow': { 29 interval: { size: 5, unit: 'second' }, 30 pipeline: [ 31 { 32 '$group': { 33 _id: [Object], 34 max: [Object], 35 avg: [Object] 36 } 37 } 38 ] 39 } 40 }, 41 { 42 '$merge': { 43 into: { 44 connectionName: 'AtlasSource', 45 db: 'Stock', 46 coll: 'StockReport' 47 } 48 } 49 } 50 ] 51 }
É isso para mover dados do Kafka para o MongoDB! Mover dados do MongoDB para o Kafka é igualmente simples. Basta definir um $source para seu cluster do Atlas e usar $emit para sua conexão do Kafka para transmitir rapidamente dados sem nenhum sistema ou configuração complexa do Kafka Connect e reduzir os custos.
Em seguida, abordaremos considerações detalhadas e opções disponíveis para você em configurações mais avançadas do Kafka. Vamos começar com algum contexto sobre o ecossistema Apache Kafka.
Esta seção destaca alguns dos principais componentes do Kafka a serem lembrados ao configurar uma integração entre o Kafka e o MongoDB, mas não se destina a fornecer uma lista abrangente de componentes. Incluímos componentes mais relevantes nos casos de uso do Atlas Stream Processing, mas consultar uma lista completa está além do escopo deste artigo. Consulte a documentação doKafka e/ou Kafka Connect para qualquer coisa que não abordamos.
O Registro de Esquema é um componente opcional do Apache Kafka que fornece um repositório centralizado para gerenciar e validar esquemas usados no processamento e serialização de dados. Como tudo no Apache Kafka é binário, os desenvolvedores usam o registro de esquema para garantir a conformidade da estrutura de dados, validação de dados, verificação de compatibilidade, controle de versão e evolução, todos os quais são úteis para aplicativos downstream. O Atlas Stream Processing não interage com o Schema Registry no momento em que este artigo foi escrito. Informe-nos por meio doUserVoice se você tiver uma grande necessidade disso.
O Kafka Connect oferece um método para integrar dados entre o Kafka e sistemas externos, como o MongoDB. O MongoDB connector para Apache Kafka é construído sobre este método de integração. Com o Atlas Stream Processing, não é necessário usar o Kafka Connect para mover dados entre o Kafka e o MongoDB.
No momento em que este artigo foi escrito, o Atlas Stream Processing aceitava apenas o formato de dados JSON. Quando formatos adicionais estiverem disponíveis, este artigo será atualizado adequadamente. Se você tiver uma necessidade urgente, informe-nos por meio da UserVoice.
O Kafka Connector tem configurações para determinar como lidar com erros. Parâmetros de configuração, como
mongo.errors.tolerance e errors.tolerance, podem ser usados junto com seus parâmetros de configuração dead letter queue (DLQ) correspondentes errors.deadletterqueue.topic.name e errors.deadletterqueue.topic.replication.factor. Isso dá aos desenvolvedores a capacidade de interromper o processamento quando ocorre um erro, tolerar erros sem interromper o processamento de mensagens ou escrever erros em um DLQ (um tópico do Kafka ou uma collection do Atlas , dependendo se é um connector de origem ou coletor). Da mesma forma, o Atlas Stream Processing suporta erros de gravação em um DLQ utilizando uma coleção MongoDB Atlas . Para fazer isso, os usuários simplesmente usam o estágio$validate para enviar eventos que não estão em conformidade com um esquema específico para o DLQ.Os SMTs fazem parte do Kafka Connect e transformam as mensagens de entrada depois que um connector de origem as produz e antes de serem gravadas no Kafka. Os SMTs também são usados no coletor, transformando as mensagens de saída antes de enviá-las ao Kafka Connector. Em vez de usar SMTs, o Atlas Stream Processing usa a API de query do MongoDB e a estrutura de agregação para transformar documentos. Ao configurar um processador de stream, observe que o Atlas Stream Processing ainda não oferece suporte a funções personalizadas para transformar mensagens. A tabela abaixo descreve o operador de pipeline de agregação equivalente ou procedimento a ser usado para cada uma das SMTs integradas.
| transformação, transformação | Descrição | Suporte ao Atlas Stream Processing |
|---|---|---|
| Transmitir | Converter campos ou toda a chave ou valor para um tipo específico | Suporte em breve via $convert. |
| descartar | Solte uma chave ou um valor de um registro e defina-o como nulo. | Use o operador$set :{ $set: { _stream.meta.key: null } }, |
| DropHeaders | Solte um ou mais cabeçalhos de cada registro. | Use o operador$pull :{ $pull: { _stream.meta.headers: { k: 'header2' } } } |
| EventRouter | Direcione eventos de saída do Debezium usando uma opção de configuração regex. | Não suportado. |
| Extrair campo | Extrair o campo especificado de uma estrutura quando o esquema estiver presente ou de um mapa no caso de dados sem esquema. Quaisquer valores nulos são passados sem modificações. | O Atlas Stream Processing pode extrair apenas o valor de um campo usando $project, mas ele ainda estará no formato JSON com um nome de campo. |
| Extrair tópico | Substitua o tópico do registro por um novo tópico derivado de sua chave ou valor. | Suporte limitado. Você pode atribuir um tópico ao escrever de volta no Kafka por meio do operador de pipeline$emit . O $emit permite um nome de tópico explícito, uma referência a um valor no documento ou uma expressão. |
| Filter (Apache Kafka) | Solte todos os registros. Projetado para ser usado em conjunto com um predicado. | Use $match e $project para filtrar valores do fluxo. |
| Achatar | Nivelar uma estrutura de dados aninhada. Isso gera nomes para cada campo concatenando os nomes de campo em cada nível com um caractere delimitador configurável. | Use $addFields com referências ao campo aninhado que você deseja nivelar. Se você deseja usar um delimitador como um período, basta concatenar usando $concat da seguinte forma: { $addFields: { fullName: { $concat: ["$name", ".", "$lastname"] } } } |
| GzipDecompress | Descompacte com Gzip toda a entrada de valor ou chave byteArray. | Não suportado. |
| HeaderFrom | Move ou copia campos em uma chave ou valor de registro para o cabeçalho do registro. | Use $emit.config.headers para especificar o cabeçalho Kafka. Observação: você pode fazer referência a chaves ou valores de registro usando o símbolo$ . Isso é usado para indicar caminhos de campo e expressões dentro de estágios e consultas do pipeline de agregação. Exemplo: $emit.config.headers = "$foo" |
| HoistField | Envolve os dados usando o nome do campo especificado em uma estrutura quando o esquema estiver presente ou em um mapa no caso de dados sem esquema. | Atualmente, os dados de eventos devem estar no formato JSON. |
| Inserir campo | Insira o campo usando atributos dos metadados do registro ou um valor estático configurado. | Utilize $addFields ou $project para criar um novo campo. |
| InsertHeader | Insira um valor literal como cabeçalho de registro. | Use $emit.config.headers. O valor deve resultar em um documento ou array estruturado como [{k': .., 'v': …}, {'k': …, 'v': …}]. |
| MaskField | Mascarar campos especificados com um valor nulo válido para o tipo de campo. | Use $set para fornecer um valor nulo ou qualquer valor arbitrário para um campo. |
| messageTimeStampRouter | Atualize o campo de tópico do registro como uma função do valor do tópico original e o campo de carimbo de data/hora do registro. | Não suportado. |
| RegexRouter | Atualize o tópico do registro usando a expressão regular configurada e a string de substituição. | Você pode modificar os nomes dos tópicos especificando o nome do tópico por string ou regex no operador$emit . |
| Substituir campo | Filtre ou renomeie campos. | Para soltar um campo, utilize $unset ou $project. Para renomear um campo, use $project. |
| SetSchemaMetadata | Defina o nome do esquema, a versão ou ambos no esquema de chave ou valor do registro. | Não suportado. |
| TimestampConverter | Converta carimbos de data/hora entre diferentes formatos, como época do Unix, cadeias de caracteres e tipos de Connect Date e Timestamp. | Converta data e hora usando operadores de agregação $dateFromString e Timestamp. |
| TimestampRouter | Atualize o campo de tópico do registro como uma função do valor original do tópico e o carimbo de data/hora do registro. | Não suportado. |
| TopicRegexRouter | Atualize o tópico do registro usando a expressão regular configurada e a string de substituição. | Você pode modificar os nomes dos tópicos especificando o nome do tópico por string ou regex no operador$emit . |
| ValueToKey | Substitua a chave de registro por uma nova chave formada a partir de um subconjunto de campos no valor de registro. | Especifique a chave atribuindo-a em $emit. Por exemplo: $emit.config.key: "$foo" |
Em seguida, vamos resumir brevemente as propriedades de origem e coletor, pós-processadores e estratégias de modelo de escrita.
Ao configurar o Kafka Connector como uma origem, ele lê dados de um cluster MongoDB e os grava em um tópico Apache Kafka . Semelhante ao Kafka Connector, ao usar o Atlas Stream Processing, os desenvolvedores primeiro definem uma conexão de registro de conexão com um MongoDB Atlas cluster e outra conexão de registro de conexão com seu tópico Kafka . Em seguida, eles usam
$source para ler os dados do cluster MongoDB e executar quaisquer transformações ou agregações opcionais nos dados, antes de usar $emit para gravar os dados em seu tópico Kafka .Usando o Kafka Connector como coletor, os desenvolvedores definem especificamente a conexão como um coletor usando a classe de connector
com.mongodb.kafka.connect.MongoSinkConnector. Com o Atlas Stream Processing, você define uma origem no registro de conexão para uso em fontes e sinks. Ao escrever em um tópico do Kafka “sink,” você usa $emite ao escrever em um MongoDB “sink," você usa $merge.Os pós-processadores são usados no Kafka Connector para modificar o documento antes de gravá-lo em um coletor de cluster MongoDB . No Atlas Stream Processing, você pode modificar o documento usando os estágios do pipeline de agregação do MongoDB antes de gravá-lo em um MongoDB Atlas. Não é necessário escrever seu próprio código Java para realizar transformações específicas da empresa.
Por exemplo, suponha que o seguinte evento esteja sobre o tópico Kafka:
1 { 2 device_id: 'device_0', 3 group_id: 8, 4 timestamp: '2024-04-04T14:49:52.943+00:00', 5 max_watts: 250, 6 event_type: 0, 7 obs: { 8 watts: 75, 9 temp: 5 10 }, 11 _ts: ISODate('2024-04-04T14:49:52.943Z') 12 }
Quando você usa o projetor de lista de permissões no Kafka Connector, o pós-processador só gera dados dos campos especificados.
1 post.processor.chain=com.mongodb.kafka.connect.sink.processor.AllowListValueProjector 2 value.projection.type=AllowList 3 value.projection.list=device_id,obs.watts,obs.temp
Neste exemplo, a saída seria a seguinte:
1 { 2 device_id: 'device_0', 3 obs: { 4 watts: 75, 5 temp: 5 6 } 7 }
Usando o Atlas Stream Processing, basta adicionar um estágio $project em sua query para incluir/excluir campos.
1 {$project:{"device_id":1,"obs.watts":1, "obs.temp":1}}
A saída seria a seguinte:
1 { 2 device_id: 'device_1', 3 obs: { 4 Watts: 50, 5 temp: 10 6 } 7 }
O Kafka Connector contém pós-processadores e processadores integrados que determinam como lidar com o campo _id no MongoDB de destino. _id é determinado pelo pós-processador DocumentIdAddr.
com.mongodb.kafka.connect.sink.processor.DocumentIdAdder
Este pós-processador insere um campo _id determinado pela estratégia configurada. A estratégia padrão é BsonOidStrategy. Por padrão, um _id será adicionado ao documento se ainda não existir um.
Estratégias do DocumentIdAddr
As estratégias DocumentId são definidas em document.id.strategy. Estas são as configurações possíveis e o equivalente do Atlas Stream Processing. Observe que, com o Atlas Stream Processing, para adicionar ou alterar o campo _id, basta usar o operador de pipeline $addFields para adicionar um novo campo "_id " com o valor especificado na tabela abaixo.
| Nome da estratégia | Descrição | Equivalente Atlas Stream Processing |
|---|---|---|
| Estratégia BSONoid com.mongodb.kafka.connect.sink.processor.id.strategy.BsonOidStrategy | Padrão | Um campo_idespecífico não precisa existir no documento, pois um novo _id com um ObjectId será incluído por padrão. |
| KafkaMetaDataStrategy com.mongodb.kafka.connect.sink.processor.id.strategy.KafkaMetaDataStrategy | Constrói uma string composta pela concatenação de tópico, partição e deslocamento do Kafka. | { $addFields: { "_id": "$_stream_meta.source.topic"}} |
| FullKeyStrategy com.mongodb.kafka.connect.sink.processor.id.strategy.FullKeyStrategy | Utiliza a estrutura de chave completa para gerar o valor para o campo_id. | { $addFields: { "_id": "$_stream_meta.source.key"}} |
| FornecidoInKeyEstratégia com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy | Utiliza o campo_id especificado na estrutura de chave. | { $addFields: { "_id": "$_stream_meta.source.key._id"}} |
| ProvidedInValueStrategy com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInValueStrategy | Usa o campo_id especificado na estrutura de valores do documento coletor. | Não aplicável, pois quando os dados do Kafka são originados no Atlas Stream Processing, o valor é o próprio documento. Assim, seria utilizadoum_iddentro do documento. |
| PartialKeyStrategy com.mongodb.kafka.connect.sink.processor.id.strategy.PartialKeyStrategy | Usa uma lista de bloqueios ou permite a projeção da lista da estrutura da chave do documento coletor. | Para usar um nome de campo diferente para o _id que faz referência originalmente à chave, use $addFields da seguinte forma: { $addFields: { "_id": "$_stream_meta.source.key.$your_desired_id_field"}} |
| PartialValueStrategy com.mongodb.kafka.connect.sink.processor.id.strategy.PartialValueStrategy | Usa uma lista de bloqueios ou uma projeção de lista de permissões da estrutura de valor do documento coletor. | Para usar um nome de campo diferente para o _id, use $addFields da seguinte forma: { $addFields: { "_id": "$your_desired_id_field"}} |
| UuidProvidedInKeyStrategy com.mongodb.kafka.connect.sink.processor.id.strategy.UuidProvidedInKeyStrategy | Converte o campo-chave_id em um UUID. O valor deve ser do tipo string ou binário e deve estar em conformidade com o formato UUID. | Não suportado. |
| UuidProvidedInValueStrategy com.mongodb.kafka.connect.sink.processor.id.strategy.UuidProvidedInValueStrategy | Converte o campo de valor_id para um UUID. O valor deve ser do tipo string ou binário e deve estar em conformidade com o formato UUID. | Não suportado. |
| UuidStrategy com.mongodb.kafka.connect.sink.processor.id.strategy.UuidStrategy | Utiliza um UUID gerado aleatoriamente no formato de string. | Não suportado. |
Estratégias de ID personalizadas definidas pelo usuário não são aceitas.
Veja a seguir uma lista de pós-processadores integrados do Kafka Connector e seus equivalentes do Atlas Stream Processing:
| Nome do pós-processador | Descrição | Equivalente Atlas Stream Processing |
|---|---|---|
| BlockListKeyProjetor com.mongodb.kafka.connect.sink.processor.BlockListKeyProjector | Remove campos-chave correspondentes do registro do coletor. | Modifique o $_stream_meta.source.key diretamente utilizando $set. |
| BlockListValueProjector com.mongodb.kafka.connect.sink.processor.BlockListValueProjector | Remove os campos de valores correspondentes do registro do coletor. | Use $project para remover quaisquer campos do documento. |
| AllowListKeyProjetor com.mongodb.kafka.connect.sink.processor.AllowListKeyProjector | Inclui somente os campos-chave correspondentes do registro do coletor. | Modifique o $_stream_meta.source.key diretamente utilizando $set. |
| AllowListValueProjetor com.mongodb.kafka.connect.sink.processor.AllowListValueProjector | Inclui apenas campos de valor correspondentes do registro do coletor. | Use $project para mostrar quaisquer campos do documento. |
| KafkaMetaAdder com.mongodb.kafka.connect.sink.processor.KafkaMetaAdder | Adiciona um campo denominado "topic-partition-offset" e define o valor como a concatenação do tópico, da partição e do deslocamento do Kafka no documento. | Use $set para adicionar o campo: { $set: { "topic-partition-offset": { $concat: ["$_stream_meta.source.topic", "#", "$_stream_meta.source.partition", "#", "$_stream_meta.source.offset"] } } } |
| RenameByMapping com.mongodb.kafka.connect.sink.processor.field.reaming.RenameByMapping | Renomeia campos que correspondem exatamente a um nome de campo especificado na chave ou no documento de valor. | Use $project para renomear campos. Faça referência aos nomes dos campos usando o operador $. |
| RenameByRegex com.mongodb.kafka.connect.sink.processor.field.reaming.RenameByRegex | Renomeia campos que correspondem a uma expressão regular na chave ou no documento de valor. | Use $project para renomear campos. |
Uma estratégia de modelo de gravação no MongoDB Kafka Connector é uma classe Java personalizada que define como um connector de pia grava dados usando modelos de gravação. Há três estratégias disponíveis prontas para uso com o Kafka Connector: ReplaceOne BusinessKeyStrategy, DeleteOne BusinessKeyStrategy e UpdateOne BusinessKeyTimestampStrategy. Os detalhes do uso dessas estratégias são os seguintes:
| Estratégia de escrita | Descrição | Equivalente Atlas Stream Processing |
|---|---|---|
| UpdateOne BusinessKeyTimestamp | Adiciona campos_insertedTS e _modifiedTS ao coletor. | Use $set para adicionar uma data a _insertedTS ou _modifiedTS Exemplo: { $set: { _modifiedTS: new Date() } } |
| Excluir uma estratégia de chave de negócios | Exclui o documento com base em um valor no evento. | Não suportado. |
| Substituir uma estratégia-chave de negócio | Substitui documentos que correspondem ao valor da chave de negócios. | Não suportado. |
Neste artigo, abordamos tudo, desde uma comparação do Kafka Connector com o Atlas Stream Processing até os fundamentos da configuração do Atlas Stream Processing usando uma fonte Kafka (neste caso, Redpanda), fechando com algumas das nuances e detalhes para manter em mente ao integrar Apache Kafka e o MongoDB. O Apache Kafka e o ecossistema ao seu redor oferecem muito, por isso esperam que este artigo o ajude a implementar a solução que funciona melhor para seu caso de uso e necessidades. O Atlas Stream Processing é um serviço totalmente gerenciado integrado ao MongoDB Atlas que criamos para priorizar a facilidade de uso, o custo e o desempenho ao processar dados entre o Kafka e o MongoDB. Embora não tenha a intenção de substituir diretamente o Kafka Connector, o Atlas Stream Processing está se mostrando uma alternativa valiosa para os clientes, e estamos investindo fortemente em mais recursos e funcionalidades para dar suporte aos seus volumes de trabalho.
Pronto para começar? Faça login hoje mesmo! Não consegue encontrar um parâmetro de configuração ou recurso de que você precisa? Informe-nos no UserVoice.
Principais comentários nos fóruns
Ainda não há comentários sobre este artigo.