Como usar os vetores quantizados do Cohere para criar aplicativos de AI econômicos com o MongoDB


Richmond Alake, Mihir Patil23 min read • Published Oct 02, 2024 • Updated Oct 03, 2024





Avalie esse Tutorial


A AI da geração funciona. Assim, o verdadeiro trabalho para os desenvolvedores começa.
Entramos em uma fase na era da AI generativa em que muitos projetos de prova de conceito estão sendo promovidos para ambientes de produção. Esses aplicativos, internos e externos, agora estão sendo usados por centenas, milhares e, em alguns casos, milhões de usuários. Como resultado, os desenvolvedores agora têm a tarefa de implementar estratégias operacionais para otimizar a computação e o armazenamento para os aplicativos de AI que desenvolvem.
Este tutorial se concentra em uma metodologia de custo operacional para fornecer uma solução melhor para armazenamento de dados. Apresento métodos mostrando como o MongoDB pode ajudar desenvolvedores a criar e manter aplicativos de AI econômicos e otimizados para escala na produção.
Agora que montamos o palco, podemos introduzir o tópico da quantização.
A quantização é uma técnica usada com destaque no processamento digital de sinais e no aprendizado de máquina. Ele é aproveitado como um método para reduzir o espaço de armazenamento necessário para um conjunto de valores numéricos, criando uma representação do conjunto original que exige menos memória e armazenamento.
No contexto da AI e do aprendizado de máquina, a criação de um subconjunto com eficiência de memória de um conjunto original de valores normalmente envolve a redução da precisão dos valores originais. Esse processo converte os valores numéricos, que geralmente são armazenados usando números de ponto flutuante 32bits, em valores de menor precisão armazenados com tipos de dados como inteiros 8bits.
Essa técnica permite uma redução significativa no uso do armazenamento de memória, preservando grande parte das informações dos dados originais. É particularmente útil em cenários em que os recursos computacionais ou de armazenamento são limitados e ao lidar com conjuntos de dados de grande escala que exigem o armazenamento de 1,000,000+ embeddings de vetores. A principal conclusão aqui é que a capacidade do MongoDB Atlas de oferecer suporte à ingestão de incorporações quantizadas oferece aos desenvolvedores maior flexibilidade, escalabilidade e eficiência de armazenamento.
Neste artigo, abordamos o seguinte: - O que é quantização e quantização vetorial? - Exemplo de quantização MongoDB- Ingestão32 eficiente de32 8 vetores qu aplicação de IA
Até agora, entendemos que a quantização é uma técnica que reduz o requisito de armazenamento de memória de valores numéricos, reduzindo a precisão do formato de dados usado para armazenar os valores numéricos. Em termos mais práticos, eis o que isso significa para calcular o uso de memória de incorporações dimensionais 1536 .
Dentro de uma incorporação com um tamanho de dimensão de 1536, há 1536 valores numéricos individuais, cada um representando uma funcionalidade ou aspecto distinto dos dados de entrada. Cada valor numérico é normalmente representado pelo formato de dados de ponto flutuante 32-bit (float32).
Flutuador32 pode armazenar muito grande (3.402823e+38) e pequeno (1.175494e-38) números. As características gerais do formato de dados float32 são:
1. Cada número usa 32 bits (4 bytes) de armazenamento de memória. 2. Os 32 bits são divididos em três partes:
- 1 bit para o sinal (positivo ou negativo)
- 8 bits para o expoente
- 23 bits para a fração (também chamada de mantisse ou significando)
3. Ele fornece cerca de sete casas decimais de precisão.
Para uma incorporação -dimensional 1536 , o uso de float32 para cada valor significa que o total de memória necessário é:
- 1536 * 4 bytes = 6,144 bytes ≈ 6 KB por incorporação
Vamos calcular isso em escala. Considere os requisitos de memória para armazenar 1,000 e 1,000,000 incorporações:
| Número de incorporações | Cálculo de memória | Requisitos totais de armazenamento |
| 1,000 | 6 KB * 1,000 = 6,000 KB | ≈ 5.86 MB |
| 1,000,000 | 6 KB * 1,000,000 = 6,000,000 KB | ≈ 5.72 GB |
1,000 incorporações, exigindo 5.86 kilobytes de armazenamento, podem ser facilmente geradas quando documentos como documentos de pesquisa autônoma de algumas páginas são processados e 1,000,000, exigindo quase 6Incorporação GB, pode ser gerado em casos de uso que envolvem a codificação de um amplo corpus de texto, como casos de uso de recuperação de documento e recomendações de produtos.
À medida que seu aplicação de AI é dimensionado, armazenar 1,000,000+ incorporações pode se tornar um requisito comum, o que faz com que o armazenamento de memória aumente diretamente, afetando o custo da infraestrutura, a latência do aplicação e o desempenho. Essa é a importância da quantização ao operar aplicativos de AI em escala.
A quantização vetorial é um algoritmo de compressão com perdas projetado para reduzir os requisitos de memória e a capacidade de armazenamento de dados vetoriais de alta dimensionamento. Ele consegue isso mapeando os elementos dos vetores originais para um conjunto reduzido de vetores representativos. Esse processo permite uma compressão significativa de dados e, ao mesmo tempo, preserva grande parte das informações essenciais contidas nos vetores originais. A técnica de quantização vetorial é particularmente útil em aplicativos de IA em que alguma perda de precisão é aceitável em troca de necessidades reduzidas de armazenamento e menor latência nas etapas de recuperação de dados.
Vamos demonstrar a quantização vetorial quantizando valores float32 e 8inteiros de bits, ou seja, int8. Para maior clareza, usaremos um exemplo simplificado com 1vetores D. Mais especificamente, a operação mostrada abaixo aproveita as técnicas de quantização escalar que envolvem a seleção dos valores mínimos e máximos em todos os vetores indexados para cada dimensão e a produção de compartimentos de tamanhos iguais entre eles. Os mapeamentos para cada uma destas dimensões para as caixas de categorização geram os novos valores quantizados (ou seja, os valores vetoriais flutuantes mapeados para caixas de categorização 255 se tornam valores vetoriais int8 ).

Etapa 1: Determine o intervalo de valores.
1 Min: 1.23 2 Max: 6.78
Etapa 2: Defina a escala de quantização.
1 Scale = (Max - Min) / 255 = (6.78 - 1.23) / 255 ≈ 0.0217
Etapa 3: Quantize para 8números inteiros usando a fórmula abaixo.
1 quantized = round((original - Min) / Scale)
No código Python, podemos implementar as etapas acima em uma função 'quantize_vector':
1 def quantize_vector(vector, bits=8): 2 """Quantize a float32 vector to n-bit integers.""" 3 4 # Convert the vector to a numpy array 5 vector = np.array(vector, dtype=np.float32) 6 7 # Step 1: Determine the range of values. 8 min_val, max_val = vector.min(), vector.max() 9 10 # Step 2: Define the quantization scale 11 scale = (max_val - min_val) / (2**bits - 1) 12 13 # Step 3: Quantize to 8-bit integers using the formula below: quantized = round((original - Min) / Scale) 14 quantized = np.round((vector - min_val) / scale).astype(np.uint8) 15 16 return quantized, min_val, scale
A função acima implementa o processo de quantização convertendo primeiro o vetor em uma array numpy, o que é feito para aproveitar as operações de array e os recursos de transmissão eficientes do numpy. A próxima etapa encontra os elementos mínimos e máximos na array. Após determinar o intervalo de valores, a função calcula a escala de quantização. Essa escala representa o tamanho do passo entre cada valor quantizado e é crucial para mapear os valores de flutuação contínua32 para valores inteiros discretos.
A fórmula de quantização, `
quantized = round((original - Min) / Scale)`, é então aplicada a cada elemento do vetor.O restante do código deste processo e o resultado estão abaixo:\
1 def dequantize_vector(quantized, min_val, scale, bits=8): 2 """Dequantize the vector back to float32.""" 3 return (quantized.astype(np.float32) * scale) + min_val 4 5 # Original float32 vector 6 original = np.array([1.23, 4.56, 2.34, 5.67, 3.45, 6.78, 1.89, 4.90], dtype=np.float32) 7 8 # Run Quantize 9 quantized, min_val, scale = quantize_vector(original) 10 11 # Dequantize (reconstruct) 12 reconstructed = dequantize_vector(quantized, min_val, scale) 13 14 # Print results 15 print("Original (float32):") 16 print(original) 17 print("\nQuantized (uint8):") 18 print(quantized) 19 print(f"\nQuantization parameters - Min: {min_val}, Scale: {scale}") 20 print("\nReconstructed (float32):") 21 print(reconstructed) 22 print("\nMean Absolute Error:") 23 print(np.mean(np.abs(original - reconstructed))) 24 25 # Memory usage 26 print(f"\nOriginal memory usage: {original.nbytes} bytes") 27 print(f"Quantized memory usage: {quantized.nbytes} bytes") 28 print(f"Compression ratio: {original.nbytes / quantized.nbytes:.2f}x")
O resultado do processo de quantização é mostrado abaixo:

Existem três tipos comuns de quantização vetorial, como mostrado abaixo.
| Considerações | Quantização escalar | Quantização binária | Quantização do produto |
| tamanho de dados | Diminuído: reduz o tamanho dos dados originais mapeando valores para escalares menores; normalmente obtém compressão moderada | Minimizado: representa cada dimensão com um único bit, reduzindo drasticamente as necessidades de armazenamento; oferece compressão máxima em comparação com outros métodos | Diminuição ainda mais do que o escalar, mas menor que o binário: divide os vetores em subvetores e quantiza cada um separadamente, resultando em uma economia significativa de espaço em comparação com os métodos escalares |
| Precisão | Ligeiramente reduzido: introduz alguma perda de precisão devido a arredondamento ou truncamento de valores; geralmente mantém uma precisão razoável para muitas aplicações | Menos preciso: reduz cada dimensão para um valor binário, resultando na perda de informações mais significativa, mas ainda pode ser eficaz para tarefas com similaridade aproximada suficiente | Melhor que o escalar: preserva mais da estrutura original do vetor ao quantizar subespaços independentemente; geralmente oferece um bom equilíbrio entre compressão e precisão |
| Melhor caso de uso | Necessidades balanceadas de armazenamento e precisão: adequado para aplicativos com compactação moderada sem sacrificar muito a precisão | Dados de grande escala onde a direção é mais importante: ideal para conjuntos de dados extremamente grandes em aplicações como pesquisa semântica ou clustering, onde a direção geral dos vetores é mais importante do que magnitudes precisas | Otimização do armazenamento com alta precisão: ideal para pesquisa por similaridade em grande escala, recuperação de informações e sistemas de recomendações em que a eficiência e a precisão são cruciais |
Quando os desenvolvedores de AI devem considerar técnicas de quantização vetorial?
- Conjuntos de dados de grande escala: Considere a quantização ao lidar com conjuntos de dados massivos contendo milhões de incorporações vetoriais, como em sistemas de recuperação de documento ou recomendações de produtos. Por exemplo, armazenar 1 000000 incorporações,,, cada uma com 1536 tamanho de dimensão e em32 formato flutuante, requer 5 aproximadamente.72 GB.
- Ambientes com restrição de recursos : considere a quantização em situações em que os recursos de armazenamento ou computacionais sejam limitados, como dispositivos de borda ou aplicativos com restrições rigorosas de memória.
- Aplicativos em tempo real: para aplicativos de IA executados em tempo real que priorizam o desempenho ideal de baixa latência, vetores quantizados podem levar a uma transferência de dados mais rápida e cálculos potencialmente mais rápidos.
- Otimização de custos: use a quantização quando os custos operacionais de aplicativos de IA em produção precisarem ser reduzidos, especialmente para aplicativos que atendem centenas, milhares ou milhões de usuários.
- Quando a perda de precisão é aceitável: a quantização é apropriada em casos de uso em que uma leve perda de precisão não impacto significativamente a qualidade geral dos resultados. Como as seções posteriores deste tutorial demonstrarão, as8 incorporações int quantizadas mostram diferenças insignificantes nas pontuações de similaridade em comparação com as32 incorporações float.
Agora que exploramos o conceito de quantização vetorial, podemos aplicar esse conhecimento em um contexto prático. A próxima seção gera incorporações quantizadas usando a API Cohere e as armazena em um banco de banco de dados MongoDB . Esse processo nos permitirá comparar e contrastar os benefícios dos vetores quantizados em relação às suas contrapartes não quantizadas.
Esta seção fornece um guia abrangente para implementar a ingestão e pesquisa vetoriais quantizadas eficientes usando Cohere e MongoDB. Percorreremos todo o processo, desde a geração de incorporações quantizadas e não quantizadas com a API do Cohere até a conversão para o formato BSON, a ingestão no MongoDB e a realização de pesquisas vetoriais nas incorporações armazenadas.
O resultado final desta seção é um sistema totalmente funcional que demonstra a implementação prática do armazenamento e recuperação de vetores quantizados. Essa configuração permitirá comparar o desempenho e a precisão de diferentes tipos de incorporação (float32, BSON float32 e BSON int8) em operações de pesquisa vetorial.
Para a implementação de código neste tutorial, as seguintes bibliotecas são utilizadas:
pandas: uma biblioteca de manipulação de dados para o tratamento eficiente de dados estruturados. É usado para carregar, limpar, transformar e analisar dados em vários formatos.cohere: A biblioteca oficial Cohere Python. Ele fornecerá acesso a modelos avançados de linguagem, geração de incorporação e geração de texto.pymongo: O driver oficial do Python para o MongoDB. Embora comentado na instalação, ele sugere o uso potencial para interagir com bancos de dados MongoDB , permitindo o armazenamento e a recuperação de dados.
1 !pip install --quiet pandas cohere pymongo
Lembre-se de obter uma chave de API do Cohere antes de executar o bloco de código abaixo. O trecho de código abaixo define a chave API Cohere no ambiente local.
1 import os 2 import cohere 3 import getpass 4 5 COHERE_API_KEY = getpass.getpass("Enter Cohere API Key: ") 6 os.environ["COHERE_API_KEY"] = COHERE_API_KEY
Esta etapa envolve a geração de um pequeno conjunto de dados estruturado de frases com campos de espaço reservado para vários tipos de incorporação. O conjunto de dados foi projetado para facilitar a demonstração e comparação de diferentes técnicas de incorporação no processamento de linguagem natural e no armazenamento de banco de dados de dados.
Os dados são estruturados como uma lista de dicionários, onde cada dicionário representa uma frase e seus atributos de incorporação associados. Cada entrada contém uma chave
sentence com uma declaração fatura como seu valor, juntamente com quatro chaves relacionadas à incorporação: float32_embedding, int8_embedding, bson_float32_embeddinge bson_int8_embedding. Essas chaves são inicialmente definidas como None.1 sentences = [ 2 { 3 "sentence": "Water boils at 100 degrees Celsius at standard atmospheric pressure.", 4 "float32_embedding": None, 5 "int8_embedding": None, 6 "bson_float32_embedding": None, 7 "bson_int8_embedding": None 8 }, 9 { 10 "sentence": "The Great Wall of China is visible from space.", 11 "float32_embedding": None, 12 "int8_embedding": None, 13 "bson_float32_embedding": None, 14 "bson_int8_embedding": None 15 }, 16 { 17 "sentence": "Photosynthesis converts light energy into chemical energy in plants.", 18 "float32_embedding": None, 19 "int8_embedding": None, 20 "bson_float32_embedding": None, 21 "bson_int8_embedding": None 22 }, 23 { 24 "sentence": "DNA contains the genetic instructions for all living organisms.", 25 "float32_embedding": None, 26 "int8_embedding": None, 27 "bson_float32_embedding": None, 28 "bson_int8_embedding": None 29 }, 30 { 31 "sentence": "Jupiter is the largest planet in our solar system.", 32 "float32_embedding": None, 33 "int8_embedding": None, 34 "bson_float32_embedding": None, 35 "bson_int8_embedding": None 36 }, 37 { 38 "sentence": "The Eiffel Tower was completed in Paris in 1889.", 39 "float32_embedding": None, 40 "int8_embedding": None, 41 "bson_float32_embedding": None, 42 "bson_int8_embedding": None 43 }, 44 { 45 "sentence": "Honey never spoils due to its unique chemical properties.", 46 "float32_embedding": None, 47 "int8_embedding": None, 48 "bson_float32_embedding": None, 49 "bson_int8_embedding": None 50 }, 51 { 52 "sentence": "The human body contains approximately 206 bones in adulthood.", 53 "float32_embedding": None, 54 "int8_embedding": None, 55 "bson_float32_embedding": None, 56 "bson_int8_embedding": None 57 }, 58 { 59 "sentence": "Mount Everest is the highest peak on Earth at 8,848m.", 60 "float32_embedding": None, 61 "int8_embedding": None, 62 "bson_float32_embedding": None, 63 "bson_int8_embedding": None 64 }, 65 { 66 "sentence": "Shakespeare wrote 37 plays and 154 sonnets during his lifetime.", 67 "float32_embedding": None, 68 "int8_embedding": None, 69 "bson_float32_embedding": None, 70 "bson_int8_embedding": None 71 }, 72 { 73 "sentence": "The speed of light in vacuum is 299,792,458 meters/second.", 74 "float32_embedding": None, 75 "int8_embedding": None, 76 "bson_float32_embedding": None, 77 "bson_int8_embedding": None 78 }, 79 { 80 "sentence": "Penguins are flightless birds found primarily in the Southern Hemisphere.", 81 "float32_embedding": None, 82 "int8_embedding": None, 83 "bson_float32_embedding": None, 84 "bson_int8_embedding": None 85 }, 86 { 87 "sentence": "The Mona Lisa was painted by Leonardo da Vinci.", 88 "float32_embedding": None, 89 "int8_embedding": None, 90 "bson_float32_embedding": None, 91 "bson_int8_embedding": None 92 }, 93 { 94 "sentence": "Oxygen makes up about 21% of Earth's atmosphere by volume.", 95 "float32_embedding": None, 96 "int8_embedding": None, 97 "bson_float32_embedding": None, 98 "bson_int8_embedding": None 99 }, 100 { 101 "sentence": "The American Civil War lasted from 1861 to 1865.", 102 "float32_embedding": None, 103 "int8_embedding": None, 104 "bson_float32_embedding": None, 105 "bson_int8_embedding": None 106 }, 107 { 108 "sentence": "Antibiotics are ineffective against viral infections like the common cold.", 109 "float32_embedding": None, 110 "int8_embedding": None, 111 "bson_float32_embedding": None, 112 "bson_int8_embedding": None 113 }, 114 { 115 "sentence": "The human heart beats approximately 100,000 times per day.", 116 "float32_embedding": None, 117 "int8_embedding": None, 118 "bson_float32_embedding": None, 119 "bson_int8_embedding": None 120 }, 121 { 122 "sentence": "Gold is one of the least reactive chemical elements.", 123 "float32_embedding": None, 124 "int8_embedding": None, 125 "bson_float32_embedding": None, 126 "bson_int8_embedding": None 127 }, 128 { 129 "sentence": "The first successful powered aircraft flew in 1903.", 130 "float32_embedding": None, 131 "int8_embedding": None, 132 "bson_float32_embedding": None, 133 "bson_int8_embedding": None 134 }, 135 { 136 "sentence": "There are 118 elements in the periodic table.", 137 "float32_embedding": None, 138 "int8_embedding": None, 139 "bson_float32_embedding": None, 140 "bson_int8_embedding": None 141 } 142 ]
A etapa final é converter a lista de dicionários de frases em Pandas DataFrame para visualização, manipulação e análise de dados mais eficientes.
1 import pandas as pd 2 3 # Convert the list of dictionaries into a pandas DataFrame 4 sentences_df = pd.DataFrame(sentences) 5 6 sentences_df.head()

Esta etapa demonstra o processo de geração de incorporações para nosso conjunto de dados de frases usando a API Cohere. Definiremos uma função personalizada,
get_cohere_embeddings, para geração de incorporação eficiente.1 import cohere 2 from typing import List, Tuple 3 4 # Initialize Cohere Client 5 co = cohere.Client(COHERE_API_KEY) 6 7 def get_cohere_embeddings(sentences: List[str]) -> Tuple[List[float], List[int]]: 8 """ 9 Generates embeddings for the provided sentences using Cohere's embedding model. 10 11 Args: 12 sentences (list of str): List of sentences to generate embeddings for. 13 14 Returns: 15 Tuple[List[float], List[int]]: A tuple containing two lists of embeddings (float and int8). 16 """ 17 generated_embedding = co.embed( 18 texts=sentences, 19 model="embed-english-v3.0", 20 input_type="search_document", 21 embedding_types=["float", "int8"] 22 ).embeddings 23 24 return generated_embedding.float, generated_embedding.int8
O trecho de código acima começa importando os módulos necessários:
cohere para acessar a API Cohere e List e Tuple do módulotyping para indicação de tipo.Em seguida, inicializamos o cliente Cohere usando a chave de API definida anteriormente. Esse objeto de cliente inicializado
co será usado para interagir com os serviços da Cohere.O
get_cohere_embeddings pega uma lista de frases e retorna uma tupla contendo duas listas de incorporações (tipos float e int8 ). Estes são os dois tipos de dados de incorporações que exigimos para este tutorial.Principais aspectos da função:
- Ele usa o método
embeddo Cohere para gerar incorporações. - O
embed-english-v3.0, um dos modelos poderosos do Cohere, é usado para incorporar a geração. - O parâmetro
input_typeé definido comosearch_document, que especifica o uso do modelo de geração de incorporação do Cohere otimizado para tarefas relacionadas à pesquisa. Essa configuração é particularmente eficaz para gerar incorporações de passagens de texto que serão usadas em aplicativos de recuperação de informações ou pesquisa de documento . - Os tipos de incorporação float e int8 são solicitados, permitindo a flexibilidade dos tipos de dados de incorporações em processos downstream.
A operação final nesta etapa é chamar a função
get_cohere_embeddings em cada ponto de dados no conjunto de dados para gerar as incorporações.1 # Iterate through each row in the DataFrame 2 for index, row in sentences_df.iterrows(): 3 # Fetch the embeddings for the sentence 4 embeddings = get_cohere_embeddings([row["sentence"]]) 5 6 # Assign the embeddings to the corresponding columns in the DataFrame 7 sentences_df.at[index, "float32_embedding"] = embeddings[0][0] # float32_embedding 8 sentences_df.at[index, "int8_embedding"] = embeddings[1][0] # int8_embedding
O trecho de código acima itera por cada linha no
sentence_df utilizando o métodoiterrows(). Os principais aspectos desta operação são iterar, gerar incorporações e atribuir.
- Iteração: o
iterrows()método nos permite processar cada linha individualmente, acessando o índice e o conteúdo da linha. - Geração de incorporação: para cada frase, chamamos a
get_cohere_embeddingsfunção . Observe que passamos a frase como uma lista de elemento único para corresponder ao formato de entrada esperado da função. - Atribuição de dados: Usamos
ato acessador dos Pandas para atribuir com eficiência as incorporações geradas a suas respectivas colunas no DataFrame.embeddings[0][0]refere-se à primeira (e única) incorporação de32 flutuante.embeddings[1][0]refere-se à primeira (e única) incorporação int8 . Após concluir a operação acima, a etapa final é visualizar um segmento dosentences_dfcom os embeddings gerados.
1 sentences_df.head()

Essa etapa introduz um processo crucial de transformação de dados que, embora potencialmente desconhecido para alguns desenvolvedores, é essencial para a criação de aplicativos de AI de alto desempenho. Ao otimizar os sistemas de AI para escala e eficiência, certas técnicas e formatos de dados se tornam essenciais para o desenvolvimento de aplicação . As operações demonstradas aqui são fundamentais para mostrar os benefícios de otimização de memória dos recursos de armazenamento BSON (Binary JSON) e MongoDB.
As operações demonstradas aqui são fundamentais para mostrar os benefícios de otimização de memória dos recursos de armazenamento BSON (Binary JSON) e MongoDB. Ao converter nossas incorporações para o formato BSON, podemos comparar a eficiência de armazenamento do formato de dados BSON em relação ao formato de dados não BSON.
1 from bson.binary import Binary, BinaryVectorDtype 2 import numpy as np 3 def generate_bson_vector(array, data_type): 4 return Binary.from_vector(array, BinaryVectorDtype(data_type)) 5 6 # For all data points in the sentences_df generate BSON vectors for float32 and int8 embeddings 7 sentences_df["bson_float32_embedding"] = sentences_df["float32_embedding"].apply(lambda x: generate_bson_vector(np.array(x, dtype=np.float32), BinaryVectorDtype.FLOAT32)) 8 sentences_df["bson_int8_embedding"] = sentences_df["int8_embedding"].apply(lambda x: generate_bson_vector(np.array(x, dtype=np.int8), BinaryVectorDtype.INT8))
O trecho de código acima define uma função,
generate_bson_vector, que receberá uma array NumPy de uma incorporação vetorial de formato de dados float32 ou int8 e a converterá em BSON. Algo a observar é que BSON (Binary JSON) é a serialização codificada binariamente do MongoDB de documentos semelhantes a JSON, e o uso de BSON oferece vários benefícios, especialmente no contexto do MongoDB:
- Eficiência: o BSON foi projetado para armazenamento e travessia eficientes, tornando-o mais rápido de processar do que o JSON em muitos casos.
- Preservação de tipo: o BSON mantém os tipos de dados, garantindo que os números, as strings e os dados binários sejam armazenados e recuperados corretamente.
- Compatibilidade com o MongoDB : como o MongoDB usa o BSON internamente, o armazenamento de dados nesse formato permite uma integração perfeita e um desempenho ideal. A função
generate_bson_vectorconverte arrays NumPy em formato binário BSON. Esta função usa o métodoBinary.from_vector, projetado especificamente para dados vetoriais.
O trecho de código acima inclui uma operação que aplica esta função a cada incorporação no DataFrame usando ométodo
applydos Pandas. Esta operação é executada para incorporações float32 e int8 e cria novas colunas com os dados formatados em BSON.Os benefícios de usar o BSON em relação a outros tipos de dados incluem:
- Eficiência de espaço: o BSON pode ser mais eficiente em termos de espaço do que o armazenamento de arrays brutos, especialmente para grandes conjuntos de dados.
- Desempenho da query: o MongoDB pode executar query mais rápidas em dados binários BSON, especialmente para operações vetoriais como pesquisas de similaridade.
- Integridade dos dados: o BSON garante que os dados binários sejam armazenados e recuperados corretamente, mantendo a precisão das incorporações originais.
- Suporte à indexação: o MongoDB oferece recursos especiais de indexação para dados binários BSON, permitindo pesquisas eficientes de similaridade em incorporações vetoriais.
Removeremos a coluna int8_emebdding do conjunto de dados, pois agora temos uma versão BSON otimizada que será usada para processos downstream, como operações de pesquisa vetorial.
1 # remove the coloumn int8_embedding from the dataframe 2 sentences_df = sentences_df.drop(columns=["int8_embedding"])
A última operação nesta etapa é visualizar um segmento do conjunto de dados.
1 sentences_df.head()

Para esta etapa, você precisará de uma conta MongoDB para recuperar uma string de conexão para um cluster.
Criar um banco de dados de dados e uma coleção dentro do MongoDB é simples com o MongoDB Atlas.
- Primeiro, registre-se para obter uma conta do MongoDB Atlas. Usuários existentes podem entrar no MongoDB Atlas.
- Siga as instruções. Selecione Atlas UI como o procedimento para implantar seu primeiro cluster.
- Siga as etapas do MongoDB para obter a string de conexão a partir da UI do Atlas . Armazene o URI com segurança em seu ambiente de desenvolvimento depois de configurar o banco de dados de dados e obter o URI de conexão do Atlas cluster.
1 MONGO_URI = getpass.getpass("Enter MongoDB URI: ") 2 os.environ["MONGO_URI"] = MONGO_URI
A próxima etapa é criar uma função simples,
get_mongo_client, que se conecta ao nosso cluster MongoDB e retorna um objeto da classeMongoClient. Esta função estabelece uma conexão com o MongoDB usando o URI fornecido e valida a conexão com um comando ping . Se for bem-sucedido, ele retornará o objeto do cliente , permitindo outras operações do banco de dados de dados.1 import pymongo 2 3 def get_mongo_client(mongo_uri): 4 """Establish and validate connection to the MongoDB.""" 5 6 client = pymongo.MongoClient(mongo_uri, appname="devrel.showcase.quantized_cohere.python") 7 8 # Validate the connection 9 ping_result = client.admin.command('ping') 10 if ping_result.get('ok') == 1.0: 11 # Connection successful 12 print("Connection to MongoDB successful") 13 return client 14 else: 15 print("Connection to MongoDB failed") 16 return None 17 18 if not MONGO_URI: 19 print("MONGO_URI not set in environment variables")
Em seguida, criaremos um banco de dados de dados
quantized e uma coleção denominada data.1 mongo_client = get_mongo_client(MONGO_URI) 2 3 db = mongo_client["quantized"] 4 col = db["data"]
Para concluir esta etapa, ingestão do conteúdo
sentence_dfna coleçãodata.1 # Delete existing collection 2 col.delete_many({})
Após esta etapa, agora temos um novo banco de dados de dados em nosso cluster MongoDB que contém uma coleção com vários documentos ingeridos das linhas em nosso
sentences_df DataFrame. Cada documento nesta coleção representa uma frase do nosso conjunto de dados original, juntamente com suas incorporações correspondentes no formato float32 e nos formatos float32 e int8 BSON. Essa configuração nos permite comparar a eficiência do armazenamento e o desempenho da consulta entre o formato float padrão32 e as versões codificadas por BSON (float32 e int8).
Nesta etapa, criaremos um componente crítico que facilita as operações de pesquisa vetorial, um índice vetorial. A função
setup_vector_search_index cria um índice de vetor, uma estrutura especializada que melhora significativamente o desempenho das pesquisas de similaridade entre os vetores de incorporação.1 # Programmatically create vector search index for both colelctions 2 import time 3 from pymongo.operations import SearchIndexModel 4 5 def setup_vector_search_index(collection, index_definition, index_name="vector_index"): 6 """ 7 Setup a vector search index for a MongoDB collection and wait for 30 seconds. 8 9 Args: 10 collection: MongoDB collection object 11 index_definition: Dictionary containing the index definition 12 index_name: Name of the index (default: "vector_index") 13 """ 14 new_vector_search_index_model = SearchIndexModel( 15 definition=index_definition, 16 name=index_name, 17 type="vectorSearch" 18 ) 19 20 # Create the new index 21 try: 22 result = collection.create_search_index(model=new_vector_search_index_model) 23 print(f"Creating index '{index_name}'...") 24 25 # Sleep for 30 seconds 26 print(f"Waiting for 30 seconds to allow index '{index_name}' to be created...") 27 time.sleep(30) 28 29 print(f"30-second wait completed for index '{index_name}'.") 30 return result 31 32 except Exception as e: 33 print(f"Error creating new vector search index '{index_name}': {str(e)}") 34 return None
O trecho de código acima utiliza o
SearchIndexModeldo MongoDB para definir um índice de pesquisa vetorial. Uma operação a ser destacada é o período de espera 30segundos após a criação do índice. Isso garante que o índice esteja totalmente criado e otimizado, evitando possíveis condições de corrida em operações de query subsequentes.A próxima etapa é inicializar a variável
vector_search_index_definition que é atribuída ao índice de vetor real, que é configurado para vários campos de vetor, cada um correspondendo a diferentes formatos de incorporação (float32, BSON float32 e BSON int8). Ao configurar esse índice, habilitamos pesquisas eficientes de similaridade de cosseno em nosso espaço de incorporação dimensional 1024 . 1024 são as dimensões de saída das incorporações geradas pelo modelo de incorporação
embed-english-v3.0do Cohere.1 dimensions = 1024 # Output dimensions for vectors generated by Cohere's embed-english-v3.0 embedding model 2 3 vector_search_index_definition = { 4 "fields": [ 5 { 6 "type": "vector", 7 "path": "float32_embedding", 8 "numDimensions": dimensions, 9 "similarity": "cosine" 10 }, 11 { 12 "type": "vector", 13 "path": "bson_float32_embedding", 14 "numDimensions": dimensions, 15 "similarity": "cosine" 16 }, 17 { 18 "type": "vector", 19 "path": "bson_int8_embedding", 20 "numDimensions": dimensions, 21 "similarity": "cosine" 22 } 23 ] 24 }
A operação final nesta etapa é criar o índice do vetor utilizando a definição no
vector_search_index_definition e na função setup_vector_search_index.1 setup_vector_search_index(col, vector_search_index_definition, index_name="vector_index")
Abaixo está um exemplo da saída da operação acima após a execução.
1 Creating index 'vector_index'... 2 Waiting for 30 seconds to allow index 'vector_index' to be created... 3 30-second wait completed for index 'vector_index'. 4 vector_index
Nesta etapa, definiremos a função
vector_searchque aproveita a poderosa framework de agregação do MongoDB para executar operações de pesquisa vetorial eficientes. Essa função é a camada intermediária entre as queries do usuário e nosso banco de dados de dados de incorporações de frases, permitindo a pesquisa semântica ou recursos RAG em seus aplicativos de AI .A função
vector_search aceita diferentes tipos de incorporações e estratégias de pesquisa. Ele pega a query de entrada de um usuário, geralmente uma frase da camada do aplicação , e a transforma em uma representação vetorial usando nossa funçãoget_cohere_embeddingsdefinida anteriormente. Essa incorporação, armazenada na variávelquery_embedding, se torna a base para nossa pesquisa de similaridade.Uma funcionalidade chave desta função é a sua capacidade de lidar com incorporações quantizadas e não quantizadas. Ao incorporar uma verificação para o tipo de incorporação, podemos ajustar dinamicamente nossos parâmetros de pesquisa para utilizar as incorporações quantidadedas com eficiência de espaço (int8) ou as incorporações não quantizadas de maior precisão (float32).
Ao aproveitar o pipeline de agregação do MongoDB, construiremos uma série de estágios que processam nossos dados, realizarão a pesquisa de similaridade vetorial e retornarão os resultados mais relevantes.
1 def vector_search(user_query, collection, quantized=False, use_bson=True): 2 """ 3 Perform a vector search in the MongoDB collection based on the user query. 4 5 Args: 6 user_query (str): The user's query string. 7 collection (MongoCollection): The MongoDB collection to search. 8 9 Returns: 10 list: A list of matching documents. 11 """ 12 13 path = None 14 query_embedding = None 15 16 # Generate embedding for the user query 17 query_embedding = get_cohere_embeddings([user_query]) 18 19 if query_embedding is None: 20 return "Invalid query or embedding generation failed." 21 22 if quantized: 23 query_embedding = query_embedding[1][0] 24 path = "int8_embedding" 25 else: 26 query_embedding = query_embedding[0][0] 27 path = "float32_embedding" 28 29 30 # Adjust path and convert vectors to BSON vectors if use_bson is True 31 if use_bson: 32 path = "bson_" + path 33 if quantized: 34 query_embedding = generate_bson_vector(query_embedding, BinaryVectorDtype.INT8) 35 else: 36 query_embedding = generate_bson_vector(query_embedding, BinaryVectorDtype.FLOAT32) 37 38 39 # Define the vector search pipeline 40 vector_search_stage = { 41 "$vectorSearch": { 42 "index": "vector_index", 43 "queryVector": query_embedding, 44 "path": path, 45 "numCandidates": 150, # Number of candidate matches to consider 46 "limit": 5 # Return top 5 matches 47 } 48 } 49 50 project_stage = { 51 "$project": { 52 "_id": 0, # Exclude the _id field 53 "sentence": 1, # Include the sentence field 54 "similarityScore": { 55 "$meta": "vectorSearchScore" # Include the search score 56 } 57 } 58 } 59 60 pipeline = [vector_search_stage, project_stage] 61 62 # Execute the search 63 results = collection.aggregate(pipeline) 64 return list(results)
As principais operações do trecho de código acima e da função
vector_search são as seguintes:- Geração de incorporação: A função
get_cohere_embeddingsconverte a query do usuário em uma representação vetorial. - Seleção do tipo de incorporação: com base no sinalizador
quantized, ele escolhe entre as incorporações float32 e int8 , ajustando o caminho da pesquisa adequadamente. - Conversão deBSON : se
use_bsonfor true, a incorporação será convertida para o formato BSON usando a funçãogenerate_bson_vector, otimizando o armazenamento e a recuperação do MongoDB . - Construção de pipeline de pesquisa: a função constrói um agregação pipeline do MongoDB com dois estágios:
$vectorSearch: utiliza o índice vetorial pré-criado para pesquisa eficiente de similaridade. Esse operador usa a incorporação de query de pesquisa como entrada, o caminho para o local dos dados de incorporação localizados na coleção, o número de candidatos a serem considerados por similaridade e o número de documentos a serem recuperados pelo estágio vetorial. -$project: molda a saída, incluindo a frase original e uma pontuação de similaridade.
Nesta etapa, usaremos a função
vector_search em diferentes configurações de incorporação. Esta comparação nos permite avaliar o desempenho e a precisão de várias representações vetoriais em tarefas de pesquisa semântica.1 results_bson_float = vector_search("what is the speed of light?", col, quantized=False, use_bson=True) 2 results_bson_int8 = vector_search("what is the speed of light?", col, quantized=True, use_bson=True) 3 results_float = vector_search("what is the speed of light?", col, quantized=False, use_bson=False)
No trecho de código acima, executamos três pesquisas de vetores distintos usando a consulta "qual é a velocidade da luz?" cada um segmentando um formato de incorporação diferente:
results_bson_float: Usa incorporações float32 codificadas por BSON, combinando a precisão dos números de ponto flutuante com a eficiência do armazenamento BSONresults_bson_int8: Utiliza incorporações quantizadas codificadas em BSON (int8), oferecendo uma representação mais compacta que pode trocar alguma precisão para melhorar o armazenamento e a eficiência da consulta`results_float`: usa incorporações float32 padrão sem codificação BSON, servindo como linha de base para comparação
Esses resultados fornecerão insights sobre como diferentes representações de incorporação afetam os resultados da pesquisa semântica, ajudá-lo a escolher a abordagem mais adequada para seus casos de uso específicos; os fatores típicos a serem considerados são otimização de armazenamento, velocidade de pesquisa e precisão de resultados.
1 import pprint 2 3 print("Float32 Results") 4 pprint.pprint(results_float) 5 print("-----------------") 6 print() 7 print("BSON Float32 Results") 8 pprint.pprint(results_bson_float) 9 print("-----------------") 10 print() 11 print("BSON Int8 Results") 12 pprint.pprint(results_bson_int8) 13 print("-----------------")
O trecho de código acima fornecerá uma saída que exibe os resultados de nossas pesquisas vetoriais em um formato mais legível. A saída é organizada em três seções, cada uma correspondendo a uma representação de incorporação diferente:
- Resultados do float32 : estes são os resultados do uso de incorporações padrão do float32 sem codificação BSON.
- Resultados do BSON float32 : mostra os resultados do uso de incorporações de float32 codificadas por BSON.
- Resultados BSON Int8 : Estes são os resultados do uso de incorporações quantizadas codificadas por BSON (int8).
Ao apresentar os resultados lado a lado, podemos comparar facilmente o desempenho e a precisão de cada tipo de incorporação. Essa comparação é crucial por vários motivos:
- Ela permite uma avaliação direta de como a codificação BSON afeta os resultados da pesquisa em comparação com as representações padrão de float32 .
- Ele mostra o impacto da quantização (int8) na precisão da pesquisa e, potencialmente, no desempenho.
- Ele fornece insights sobre as trocas entre precisão (float32) e eficiência (int8) em operações de pesquisa vetorial.
A saída do trecho de código anterior é como mostrado abaixo:
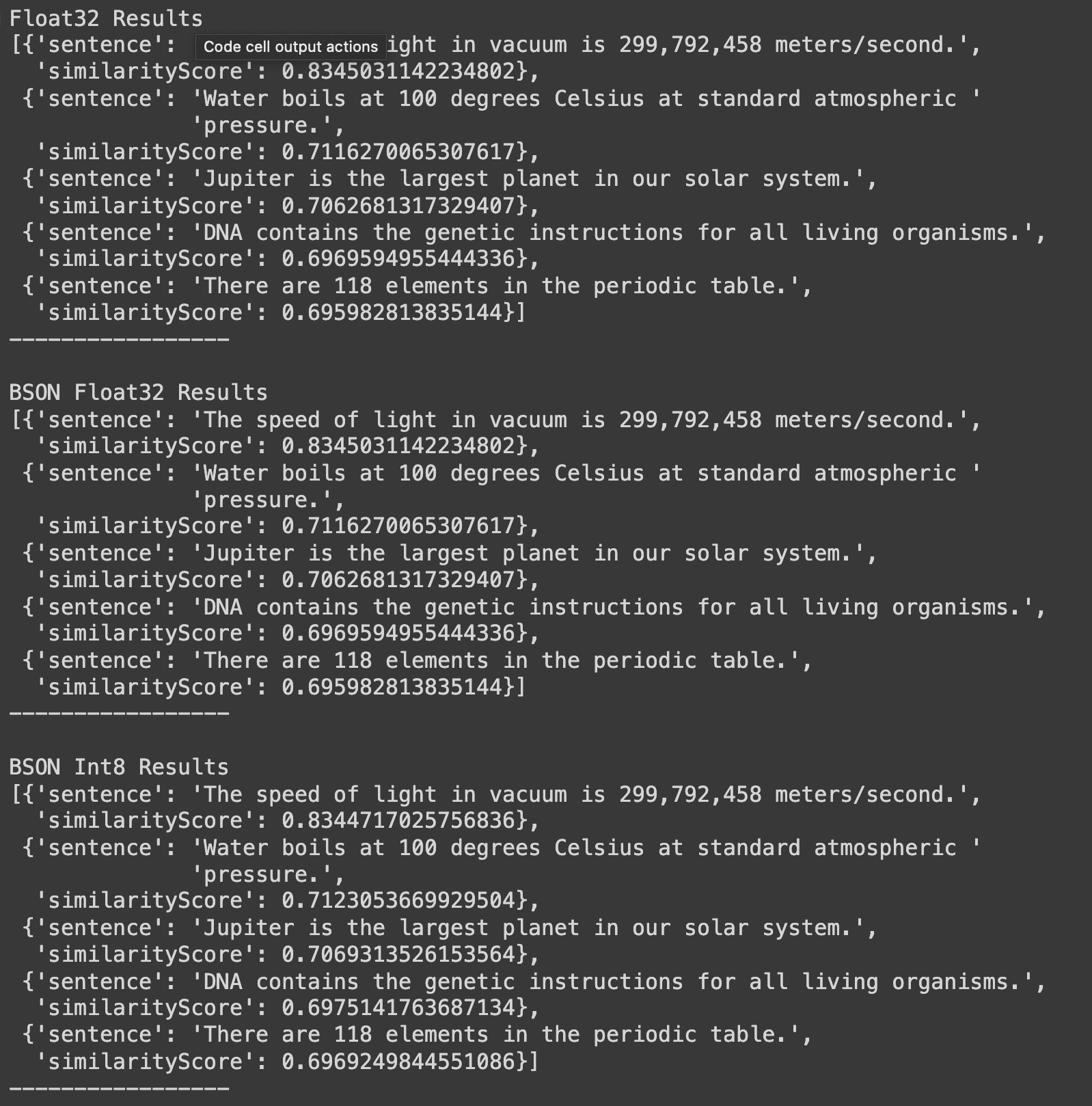
Com base nesses resultados, podemos tirar várias Conclusões importantes sobre os benefícios da quantização e codificação BSON em operações de pesquisa vetorial:
Começaremos com uma consideração importante, que é a preservação da precisão . Os resultados demonstram que o suporte nativo do MongoDB para vetores em BSON e quantização mantêm um alto grau de precisão na pesquisa semântica. O resultado superior para todos os três métodos é idêntico, identificando corretamente a frase sobre a velocidade da luz, com pontuações de similaridade muito semelhantes (0.8345 para float32 e BSON float,.32 08344 para BSON int).8
Outro fator a considerar é a consistência entre formatos. A ordem dos resultados e as pontuações de similaridade são extraordinariamente consistentes em todos os três formatos. Isso sugere que o uso da codificação BSON e até mesmo a quantização para int8 não comprometem significativamente a qualidade dos resultados da pesquisa. Com base nisso, vamos recapitular os benefícios do BSON e dos vetores quantizados para aplicativos de IA.
1. Benefícios do tipo BSON de vetor nativo:
- Eficiência do armazenamento: embora não esteja diretamente visível nos resultados deste tutorial, a codificação BSON normalmente oferece armazenamento mais compacto em comparação com os valores flutuantes brutos32 , reduzindo potencialmente o tamanho do banco de dados de dados. Siga o bloco deanotações avançado para obter uma visão geral da eficiência do armazenamento do BSON.
- Desempenho da query: o formato binário do BSON pode levar a serialização/deserialização mais rápida, potencialmente melhorando as velocidades de query em aplicativos de grande escala.
2. Vantagens da quantização (int8):
- Eficiência do espaço: a representação do Int8 requer significativamente menos espaço de armazenamento em comparação com o float32, que pode ser crucial para grandes conjuntos de dados.
- Possíveis ganhos de desempenho: o tamanho reduzido dos dados pode levar a uma transferência de dados mais rápida e a cálculos potencialmente mais rápidos, o que é especialmente benéfico para ambientes com restrição de recursos.
3. Perda mínima de precisão: As pequenas variações nas pontuações de similaridade para os resultados BSON int8 (por exemplo, 0.8344 vs 0.8345 para o resultado superior) indicam que a perda de precisão da quantização é mínima e não afeta a classificação geral de resultados.
Os resultados deste tutorial demonstram que você pode aproveitar os benefícios da codificação e da quantização BSON sem comprometer significativamente a precisão da pesquisa.
Em um experimento interno, comparamos a eficiência de armazenamento de diferentes representações para incorporação de vetores: flutuantes e vetores BSON usando precisão de flutuação32 . O conjunto de dados de teste consistia em três milhões de documentos, cada um contendo incorporações geradas pelo coere-embed-multilingual-v3.0 modelo com dimensões 1024 , como este tutorial. Os resultados foram os seguintes:
| 3M Docs, coere-embed-multilingual-v3.0@1024d | Tamanho do armazenamento MongoDB (GB) |
|---|---|
| Array de flutuações | 41 |
| Os vetores BSON flutuam32 | 14 |
Essa comparação demonstra uma redução significativa nos requisitos de armazenamento ao usar vetores BSON com precisão32 flutuante. A representação BSON exigiu apenas cerca 34% do espaço de armazenamento necessário para a representação de array de flutuações, resultando em aproximadamente 66% de economia de espaço. Essa diferença substancial na eficiência do armazenamento tem implicações importantes para bancos de dados de vetores de grande escala.
A codificação BSON oferece armazenamento aprimorado e possíveis benefícios de desempenho, enquanto a quantização adicional para int8 a partir de incorporações float32 , como neste tutorial, pode fornecer economia adicional de espaço com impacto insignificante na qualidade do resultado.
A escolha entre esses formatos (array de flutuações, vetores BSON ou representações quantizadas) deve ser baseada nas necessidades específicas do aplicação , equilibrando restrições de armazenamento, requisitos de velocidade de processamento e o nível de precisão necessário para o caso de uso específico.
Uma conclusão importante é que o MongoDB Atlas aprimora sua pilha de AI ao fornecer suporte robusto de indexação para resultados quantizados de modelos de incorporação de fornecedores como a Cohere. Esse recurso melhora significativamente a escalabilidade dos volumes de trabalho de AI , especialmente aqueles que envolvem pesquisa vetorial, permitindo que eles lide com volumes instantaneamente mais altos. O menor espaço ocupado pela memória das incorporações quantizadas resulta em utilização mais eficiente do armazenamento e em relação ao custo. Esses recursos fazem do MongoDB Atlas uma ótima opção para organizações que buscam otimizar seus aplicativos de AI , especialmente aquelas que envolvem operações de pesquisa vetorial em grande escala.
Este tutorial aborda uma abordagem introdutória para avaliar os benefícios das incorporações quantizadas. Para uma análise mais detalhada e avançada dos benefícios de otimização de memória de vetores quantizados e formato de dados BSON , confira o bloco de anotações doGithub .
1. O que é quantização vetorial e como ela melhora o desempenho em aplicativos de AI , como pipelines RAG ?
A quantização vetorial é uma técnica de compressão com perdas que reduz os requisitos de dimensionamento e memória dos dados vetoriais de alta dimensionamento. Ele mapeia vetores originais para um conjunto menor de vetores representativos, permitindo uma compressão significativa de dados e preservando grande parte das informações essenciais. Em aplicativos de AI , isso melhora o desempenho por:
- Reduzir os requisitos de armazenamento, especialmente para conjuntos de dados de grande escala.
- Diminuição dos tempos de transferência de dados devido a tamanhos de dados menores.
- Potencialmente acelerando cálculos e queries, particularmente benéficos em ambientes com restrição de recursos.
2. Quais são as trocas entre as incorporações float32 e int8 em aplicativos de pesquisa vetorial?
As principais desvantagens entre as incorporações float32 e int8 são: Flutuante32:
- Maior precisão
- Maiores requisitos de armazenamento
- Desempenho da query potencialmente mais lento devido ao tamanho de dados maior
Int8 (quantizado):
- Espaço de armazenamento significativamente reduzido
- transferência de dados mais rápida e cálculos potencialmente mais rápidos
- Ligeira perda de precisão, mas muitas vezes insignificante na prática
Principais comentários nos fóruns
Ainda não há comentários sobre este artigo.