MongoDB com agente Bedrock: tutorial rápido






Classifique este início rápido


MongoDB Atlas and Amazon Bedrock have joined forces to streamline the development of generative AI applications through their seamless integration. MongoDB Atlas, a robust cloud-based database service, now offers native support for Amazon Bedrock, AWS's managed service for generative AI. This integration leverages Atlas's vector search capabilities, enabling the effective utilization of enterprise data to augment the foundational models provided by Bedrock, such as Anthropic's Claude and Amazon's Titan. The combination ensures that the generative AI models have access to the most relevant and up-to-date data, significantly improving the accuracy and reliability of AI-driven applications with MongoDB.
This integration simplifies the workflow for developers aiming to implement retrieval-augmented generation (RAG). RAG helps mitigate the issue of hallucinations in AI models by allowing them to fetch and utilize specific data from a predefined knowledge base. In this case, MongoDB Atlas developers can easily set up this workflow by creating a vector search index in Atlas, which stores the vector embeddings and metadata of the text data. This setup not only enhances the performance and reliability of AI applications but also ensures data privacy and security through features like AWS PrivateLink.
This notebook demonstrates how to interact with a predefined agent using AWS Bedrock in a Google Colab environment. It utilizes the
boto3 library to communicate with the AWS Bedrock service and allows you to input prompts and receive responses directly within the notebook.- Secure handling of AWS credentials: The
getpassmodule is used to securely enter your AWS Access Key and Secret Key. - Session management: Each session is assigned a random session ID to maintain continuity in conversations.
- Agent invocation: The notebook sends user prompts to a predefined agent and streams the responses back to the user.
- AWS Access Key and Secret Key with appropriate permissions
- Boto3 and Requests libraries for interacting with AWS services and fetching data from URLs
- Follow the getting started with Atlas guide and set up your cluster with
0.0.0.0/0allowed connection for this notebook. - Predefine an Atlas vector index. on database
bedrockcollectionagenda. This collection will host the data for the AWS summit agenda and will serve as a context store for the agent:
Index name:
vector_index:1 { 2 "fields": [ 3 { 4 "type": "vector", 5 "path": "embedding", 6 "numDimensions": 1024, 7 "similarity": "cosine" 8 }, 9 { 10 "type" : "filter", 11 "path" : "metadata" 12 }, 13 { 14 "type" : "filter", 15 "path" : "text" 16 }, 17 ] 18 }
We will use US-EAST-1 AWS region for this notebook.
Follow our official tutorial to enable a Bedrock knowledge base against the created database and collection in MongoDB Atlas. This guide highlights the steps to build the knowledge base and agent.
For this notebook, we will perform the following tasks according to the guide:
Go to the Bedrock console and enable:
- Amazon Titan Text Embedding model (
amazon.titan-embed-text-v2:0) - Claude 3 Sonnet Model (The LLM)
Upload the following source data about the AWS Summit agenda to your S3 bucket:
This will be our source data listing the events happening at the Summit.
Go to Secrets Manager on the AWS console and create credentials to our Atlas cluster via "Other type of secret"
- key : username , value :
<ATLAS_USERNAME> - key : password , value :
<ATLAS_PASSWORD>
Follow the setup of the knowledge base wizard to connect Bedrock models with Atlas:
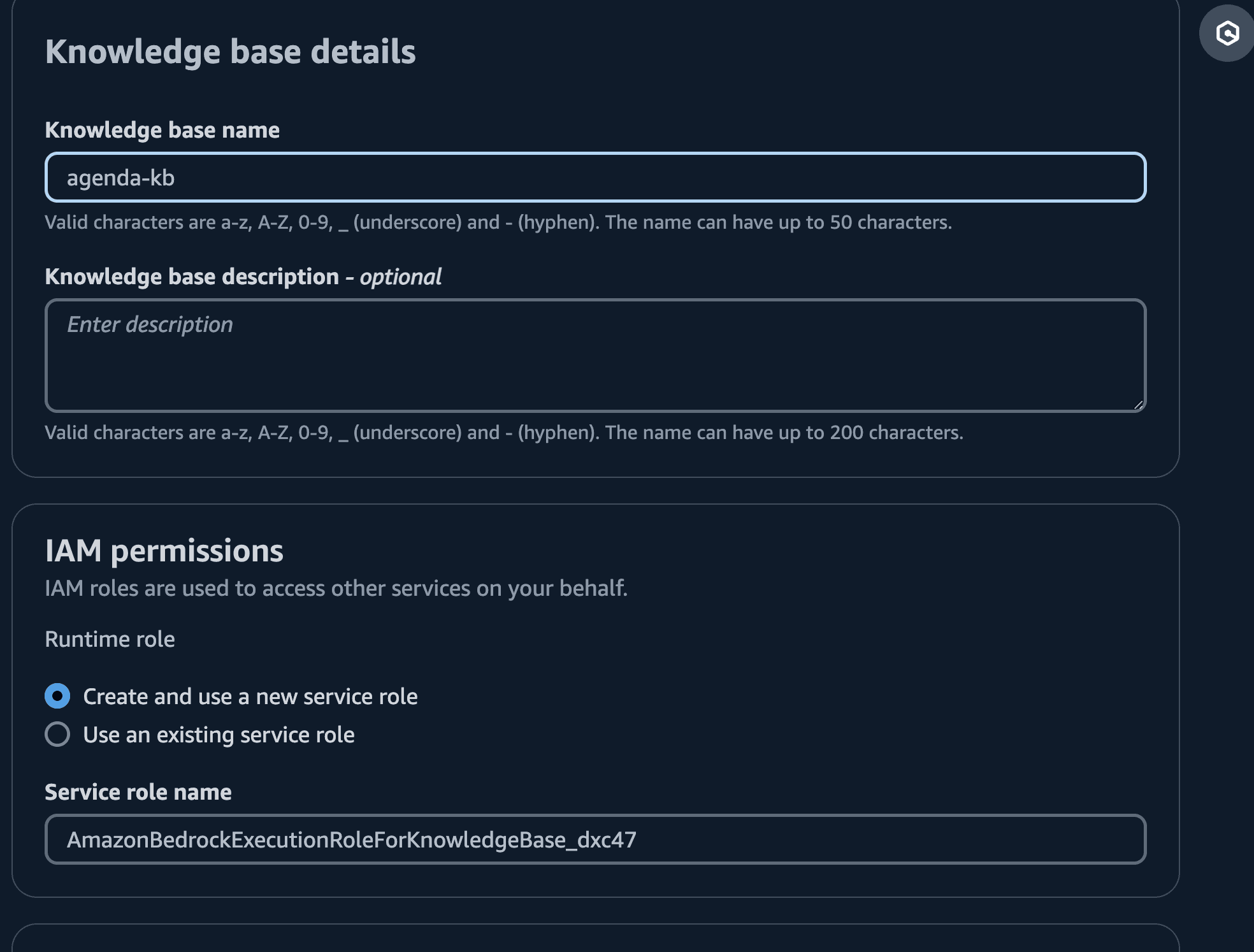
- Click "Create Knowledge Base" and input:
| input | value |
|---|---|
| Name | <NAME> |
| Chose | Create and use a new service role |
| Data source name | <NAME> |
| S3 URI | Browse for the S3 bucket hosting the 2 uploaded source files |
| Embedding Model | Titan Text Embeddings v2 |
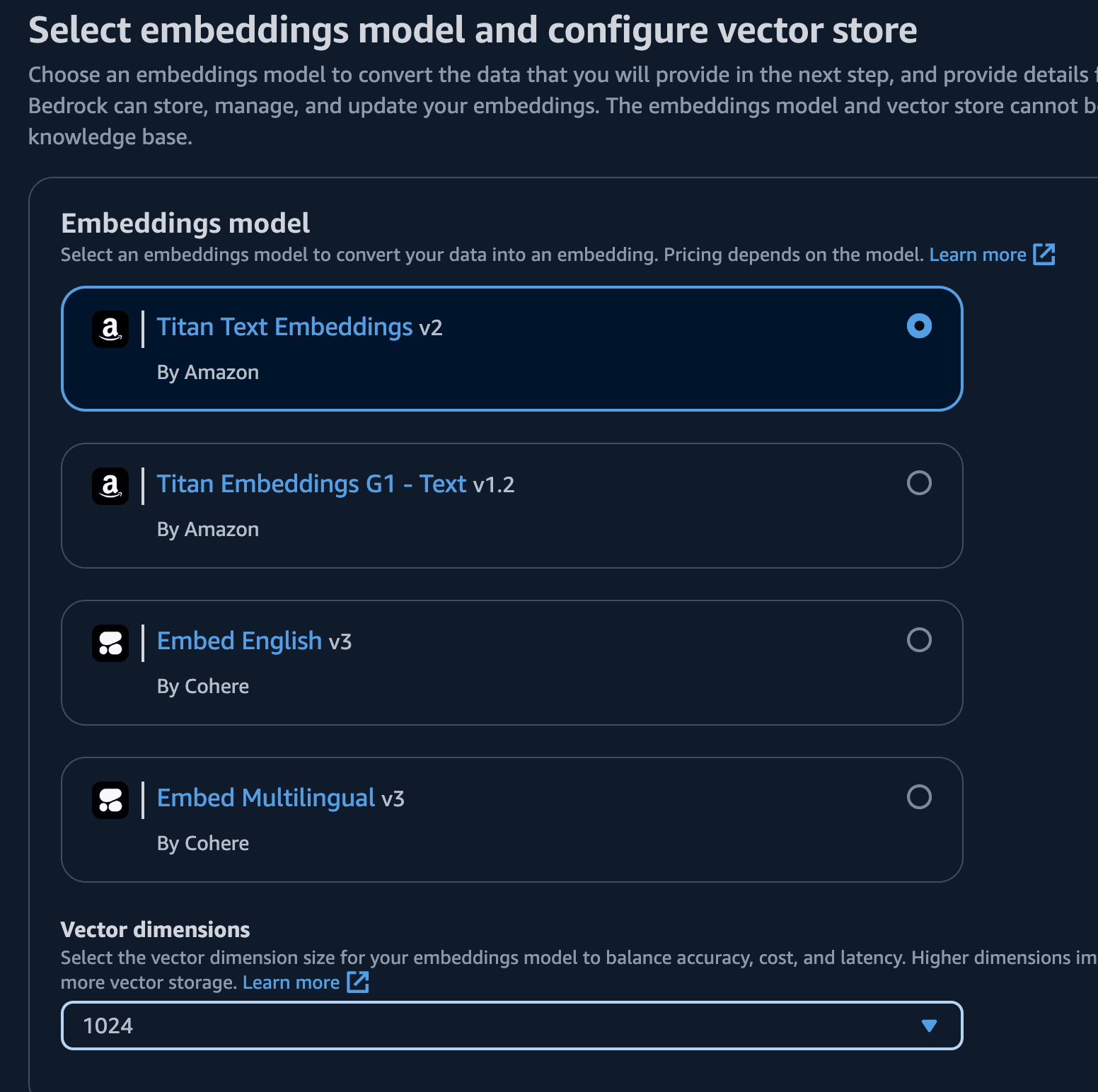
- Let's choose MongoDB Atlas in the "Vector Database." Select the "Choose a vector store you have created" section:
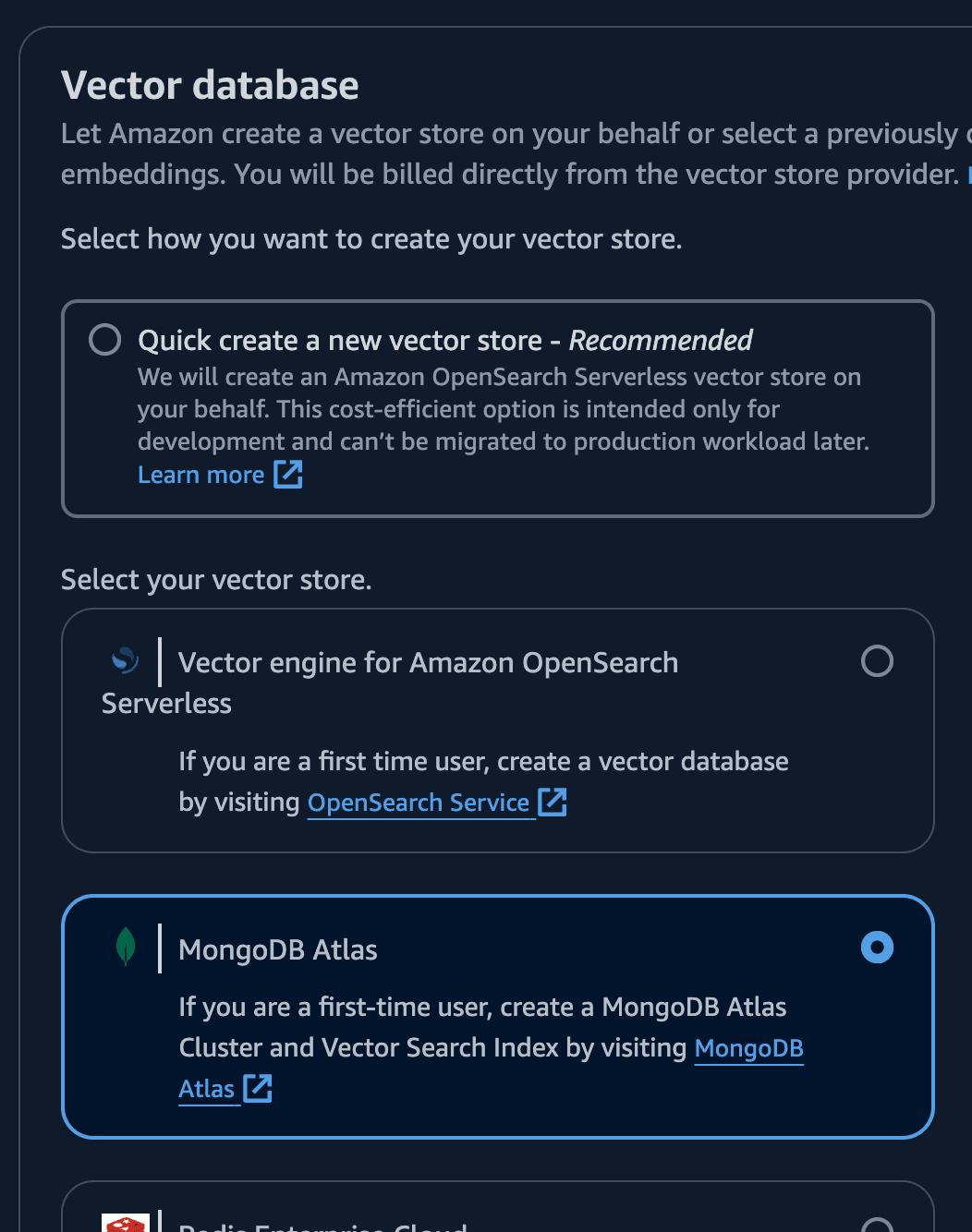
| input | value |
|---|---|
| Select your vector store | MongoDB Atlas |
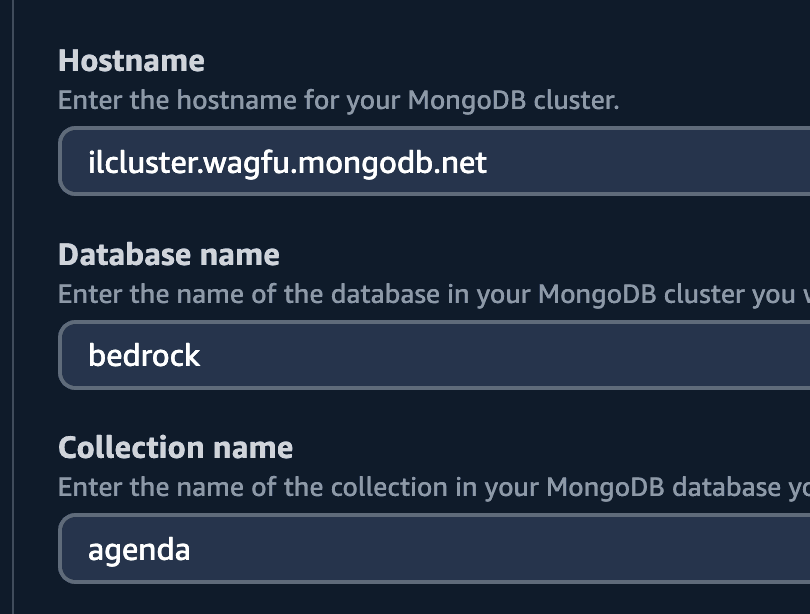
| Hostname | Your atlas srv hostname eg. cluster0.abcd.mongodb.net |
| Database name | bedrock |
| Collection name | agenda |
| Credentials secret ARN | Copy the created credentials from the "Secrets manager" |
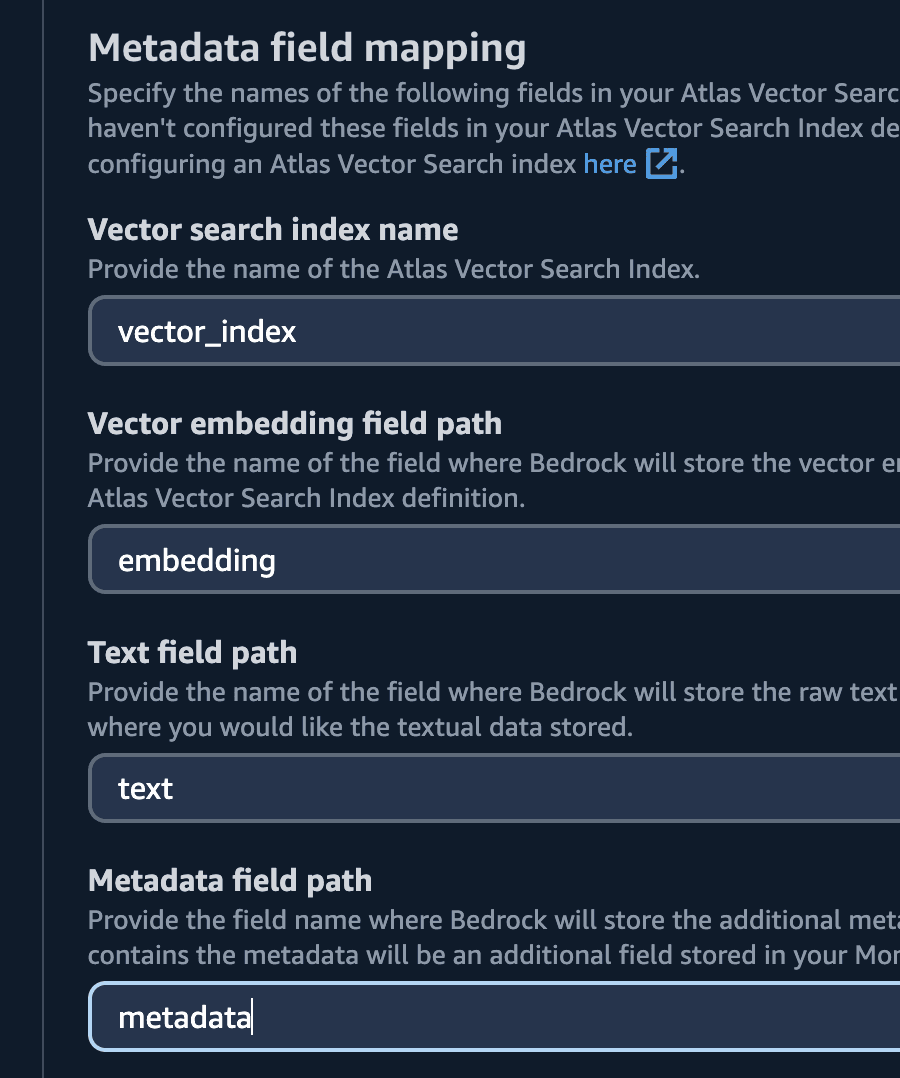
| Vector search index name | vector_index |
| Vector embedding field path | embedding |
| Text field path | text |
| Metadata field path | metadata |
Click “Next” and review the details and "Create Knowledge Base."
Once the knowledge base is marked with "Status : Ready," go to the “Data source” section, choose the one datasource we have, and click "Sync" in the right upper corner. This operation should load the data to Atlas if everything was set up correctly.
We can now set up our agent, who will work with a set of instructions and our knowledge base.
- Go to the "Agents" tab in the bedrock UI.
- Click "Create Agent" and give it a meaningful name (e.g., agenda_assistant).
- Input the following data in the agent builder:
| input | value |
|---|---|
| Agent Name | agenda_assistant |
| Agent resource role | Create and use a new service role |
| Select model | Anthropic - Claude 3 Sonnet |
| Instructions for the Agent | You are a friendly AI chatbot that helps users find and build agenda Items for AWS Summit Tel Aviv. elaborate as much as possible on the response. |
| Agent Name | agenda_assistant |
| Knowledge bases | Choose your Knowledge Base |
| Aliases | Create a new Alias |
And now, we have a functioning agent that can be tested via the console.
Let's move to the notebook.
Take note of the Agent ID and create an Agent Alias ID for the notebook.
To interact with the agent, we need to install the AWS Python SDK:
1 !pip install boto3
Let's place the credentials for our AWS account.
1 import boto3 2 from botocore.exceptions import ClientError 3 import os 4 import random 5 import getpass 6 7 8 # Get AWS credentials from user 9 aws_access_key = getpass.getpass("Enter your AWS Access Key: ") 10 aws_secret_key = getpass.getpass("Enter your AWS Secret Key: ")
Now, we need to initialise the boto3 client and get the Agent ID and Alias ID input.
1 bedrock_agent_runtime = boto3.client('bedrock-agent-runtime', 2 aws_access_key_id=aws_access_key, 3 aws_secret_access_key=aws_secret_key, 4 region_name="us-east-1") 5 6 7 # Define agent IDs (replace these with your actual agent IDs) 8 agent_id = getpass.getpass("Enter your agent ID") 9 agent_alias_id = getpass.getpass("Enter your agent Alias ID")
Let's build the helper function to interact with the agent.
1 def randomise_session_id(): 2 """ 3 Generate a random session ID. 4 5 6 Returns: 7 str: A random session ID. 8 """ 9 return str(random.randint(1000, 9999)) 10 11 12 def data_stream_generator(response): 13 """ 14 Generator to yield data chunks from the response. 15 16 17 Args: 18 response (dict): The response dictionary. 19 20 21 Yields: 22 str: The next chunk of data. 23 """ 24 for event in response["completion"]: 25 chunk = event.get("chunk", {}) 26 if "bytes" in chunk: 27 yield chunk["bytes"].decode() 28 29 30 def invoke_agent(bedrock_agent_runtime, agent_id, agent_alias_id, session_id, prompt): 31 """ 32 Sends a prompt for the agent to process and respond to, streaming the response data. 33 34 35 Args: 36 bedrock_agent_runtime (boto3 client): The runtime client to invoke the agent. 37 agent_id (str): The unique identifier of the agent to use. 38 agent_alias_id (str): The alias of the agent to use. 39 session_id (str): The unique identifier of the session. Use the same value across requests to continue the same conversation. 40 prompt (str): The prompt that you want the agent to complete. 41 42 43 Returns: 44 str: The response from the agent. 45 """ 46 try: 47 response = bedrock_agent_runtime.invoke_agent( 48 agentId=agent_id, 49 agentAliasId=agent_alias_id, 50 sessionId=session_id, 51 inputText=prompt, 52 ) 53 54 55 # Use the data stream generator to stream the response 56 ret_response = ''.join(data_stream_generator(response)) 57 58 59 return ret_response 60 61 62 except Exception as e: 63 return f"Error invoking agent: {e}"
We can now interact with the agent using the application code.
1 # Initialize chat history and session ID 2 session_id = randomise_session_id() 3 4 5 while True: 6 prompt = input("Enter your prompt (or type 'exit' to quit): ") 7 8 9 if prompt.lower() == 'exit': 10 break 11 12 13 response = invoke_agent(bedrock_agent_runtime, agent_id, agent_alias_id, session_id, prompt) 14 15 16 print("Agent Response:") 17 print(response)
Here you go! You have a powerful Bedrock agent with MongoDB Atlas. You can run this code via the following interactive notebook.
The integration of MongoDB Atlas with Amazon Bedrock represents a significant advancement in the development and deployment of generative AI applications. By leveraging Atlas's vector search capabilities and the powerful foundational models available through Bedrock, developers can create applications that are both highly accurate and deeply informed by enterprise data. This seamless integration facilitates the retrieval-augmented generation (RAG) workflow, enabling AI models to access and utilize the most relevant data, thereby reducing the likelihood of hallucinations and improving overall performance.
The benefits of this integration extend beyond just technical enhancements. It also simplifies the generative AI stack, allowing companies to rapidly deploy scalable AI solutions with enhanced privacy and security features, such as those provided by AWS PrivateLink. This makes it an ideal solution for enterprises with stringent data security requirements. Overall, the combination of MongoDB Atlas and Amazon Bedrock provides a robust, efficient, and secure platform for building next-generation AI applications.
If you have questions or want to share your work with other developers, visit us in the MongoDB Developer Community.
Principais comentários nos fóruns
Ainda não há comentários sobre este artigo.
Classifique este início rápido