Criação de um agente de AI aprimorado para memória com o laudo do Aconnection no Amazon Cama do MongoDB Atlas

Igor Alekseev, Venkatesh Shanbhag, Mohammad Daoud Farooqi8 min read • Published Oct 02, 2024 • Updated Oct 29, 2024

Avaliar este tutorial

What if we could build a knowledge-based system designed to provide personalized information and answer user queries? And do this by leveraging a robust search architecture that efficiently handles both simple keyword-based queries and complex conversational inquiries? Consider a use case for a travel advisory service that offers personalized recommendations and answers questions related to travel itineraries and planning. By combining advanced search techniques with natural language understanding, this system would deliver accurate and informative responses tailored to individual user needs. Such a system can be seen as an agent—a computational entity capable of understanding its environment, perceiving input, taking actions through tool utilization, and using cognition supported by foundation models. These agents, equipped with short-term and long-term memory, are sophisticated AI entities that make intelligent decisions and execute actions based on environmental awareness. Let's have a look at some examples.

Figure 1: Conversation between Travel Agent Chatbot and User, utilizing keywords to perform an exact match search.
In this example, the large language model (LLM)—Anthropic’s Claude—leverages MongoDB Query Language (MQL) functions as specialized tools to directly search and retrieve results based on user queries. By utilizing MQL’s structured query capabilities, the LLM efficiently navigates databases, executing precise queries tailored to the user’s needs. This approach ensures contextually accurate responses while optimizing performance by reducing unnecessary processing time. The integration of MQL allows the LLM to handle complex queries and large datasets with precision, demonstrating the powerful synergy between AI-driven natural language understanding and advanced data retrieval techniques in MongoDB.

Figure 2: Conversation between Travel Agent Chatbot and User, utilizing MongoDB’s Vector Semantic Search without relying on specific keywords.
In this example interaction, the LLM utilizes MongoDB's Vector Search functionality, defined as a specialized tool, along with the user's conversation history, to extract all previously suggested locations to visit. By employing this advanced vector search, the LLM agent efficiently analyzes the data and retrieves the best-rated recommendation based on contextual relevance and user preferences.
MongoDB Vector Search enables the LLM to go beyond traditional keyword-based searching by leveraging embeddings and semantic understanding to evaluate the quality and relevance of the locations in the conversation history. This allows for more intelligent and nuanced data retrieval, ensuring that the response is not only accurate but also tailored to the user’s needs.
By combining the power of MongoDB's Vector Search with contextual data, the LLM agent demonstrates advanced capabilities in querying large datasets, identifying patterns, and ranking results. This approach showcases the power of integrating AI-driven natural language processing with modern database technologies like MongoDB Vector Search to provide users with more precise, contextually aware, and high-value responses with robust data processing.
Note: In this implementation, the AI agent is prompted to explain which tools were utilized to generate the final response. In a real-world application, the response would be concise and directly address the user's queries.
In the above scenario, user queries fall into two main types: simple match queries using specific keywords like location, country, or destination name, and conversational queries seeking more detailed information about a place. A retrieval-augmented generation (RAG) system, which combines information retrieval with generative models, can handle both types effectively. RAG retrieves relevant information from a database and then generates a coherent response. While building a RAG, embedding the entire user query can be redundant or inefficient in some scenarios where the data is in structured format. For simple keyword-based queries, direct matches are sufficient. While more complex conversational queries are better served by semantic search, providing deeper contextual understanding.
The application stack is built on AWS. The core logic runs on AWS Lambda, connecting to Amazon Bedrock and MongoDB Atlas. Lambda uses Anthropic’s Claude in Amazon Bedrock to generate embeddings and make decisions about whether to use direct lookups or semantic search in MongoDB Atlas. Users interact with our application through Amazon Lex, which provides a natural language interface.
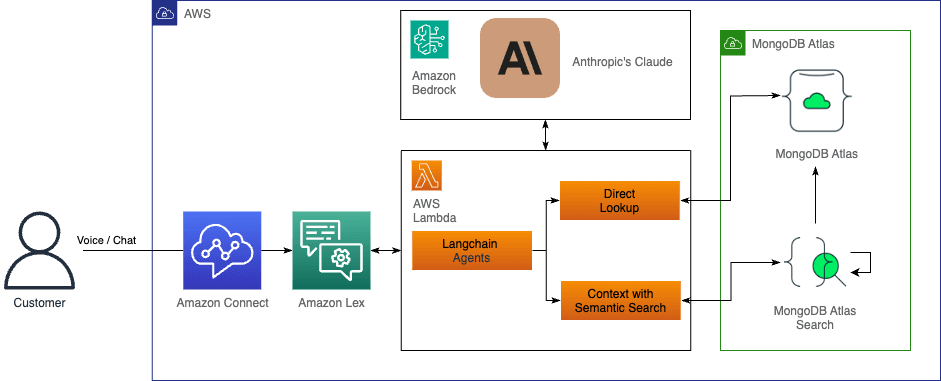
Figure 3: Architecture diagram illustrating the integration of AWS, Anthropic, and MongoDB for building an AI-enhanced, end-to-end application.
- AWS Bedrock (Model hosting)AWS Bedrock will play a critical role in hosting and orchestrating the Anthropic models and Titan embedding models, providing a robust foundation for model management and execution. Bedrock's scalable infrastructure will ensure the seamless operation of the AI models, allowing for quick processing of large datasets and ensuring the responsiveness of the system under varying workloads. Its managed services approach simplifies the integration and operational complexities of running Anthropic models at scale.
- Anthropic’s Claude (large language model)
Anthropic's Claude models enhance the quality and richness of the data stored in MongoDB Atlas. Claude will provide deeper insights and smarter recommendations by analyzing patterns within the trip data and the stored embeddings. By augmenting the database with AI-driven enhancements, Claude models ensure more accurate and contextually relevant results for users.
- MongoDB Atlas (Data store)
MongoDB Atlas will serve as the primary database, responsible for securely storing structured and unstructured trip recommendation data. Additionally, it will house embeddings and chat history that are essential for advanced search and recommendation features, enabling more relevant and personalized travel suggestions. With its cloud-native design, Atlas ensures scalability, high availability, and seamless integration with other components in the architecture.
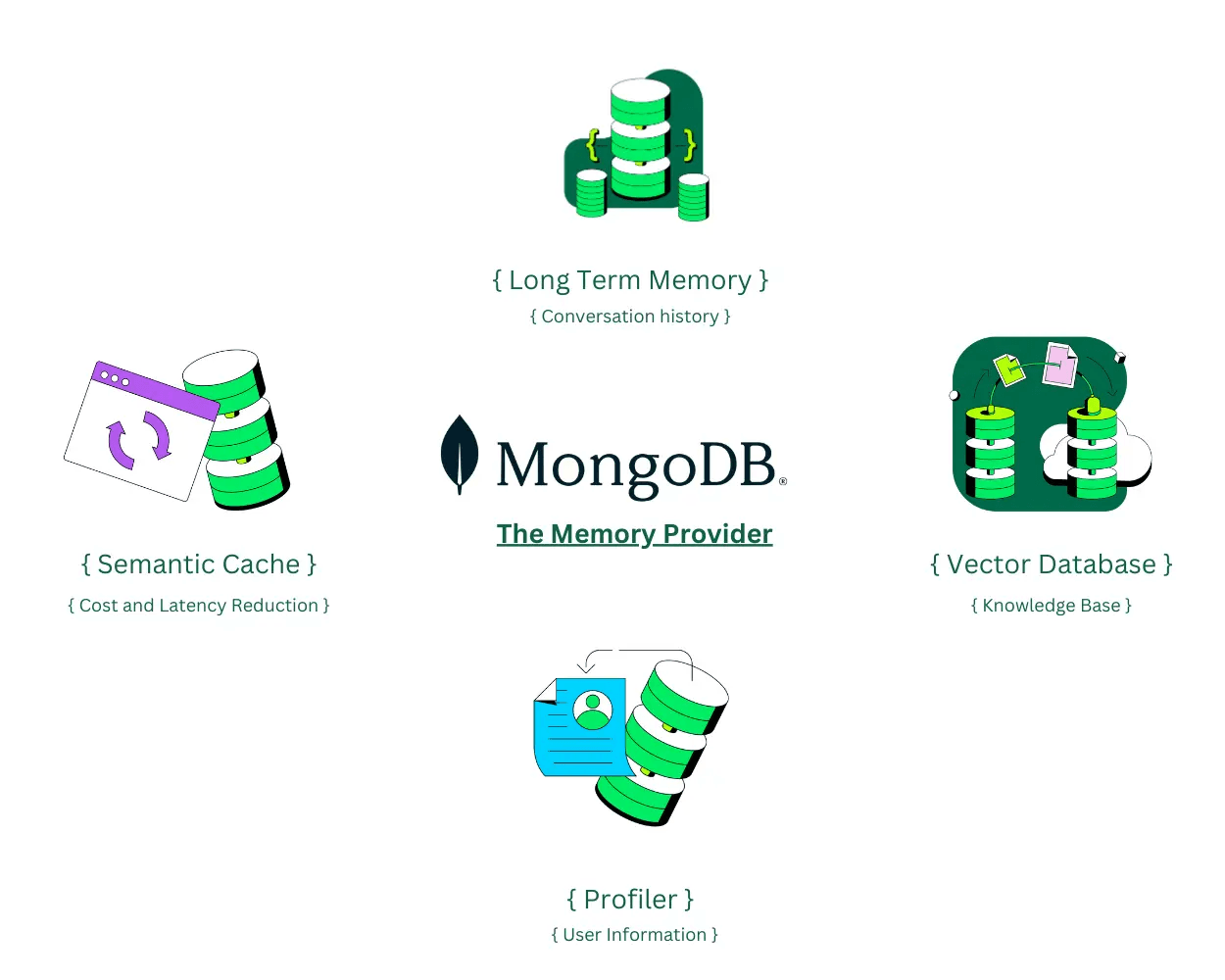
Figure 4: MongoDB Atlas provides long-term memory, vector embedding retrieval, and semantic search capabilities, enabling the agent to efficiently manage and retrieve conversational data.
- Lambda (Application back end)
AWS Lambda will be utilized to deploy and run the backend application, offering a serverless architecture that automatically scales based on demand. The back end will handle various business logic, from processing requests to interacting with MongoDB Atlas and AWS Bedrock. Lambda's event-driven model reduces infrastructure management overhead, enabling efficient, cost-effective, and flexible application deployment.
- Lex (Conversational user Interface)
AWS Lex will be employed to create an intuitive user interface, offering natural language processing capabilities to enhance user interaction.
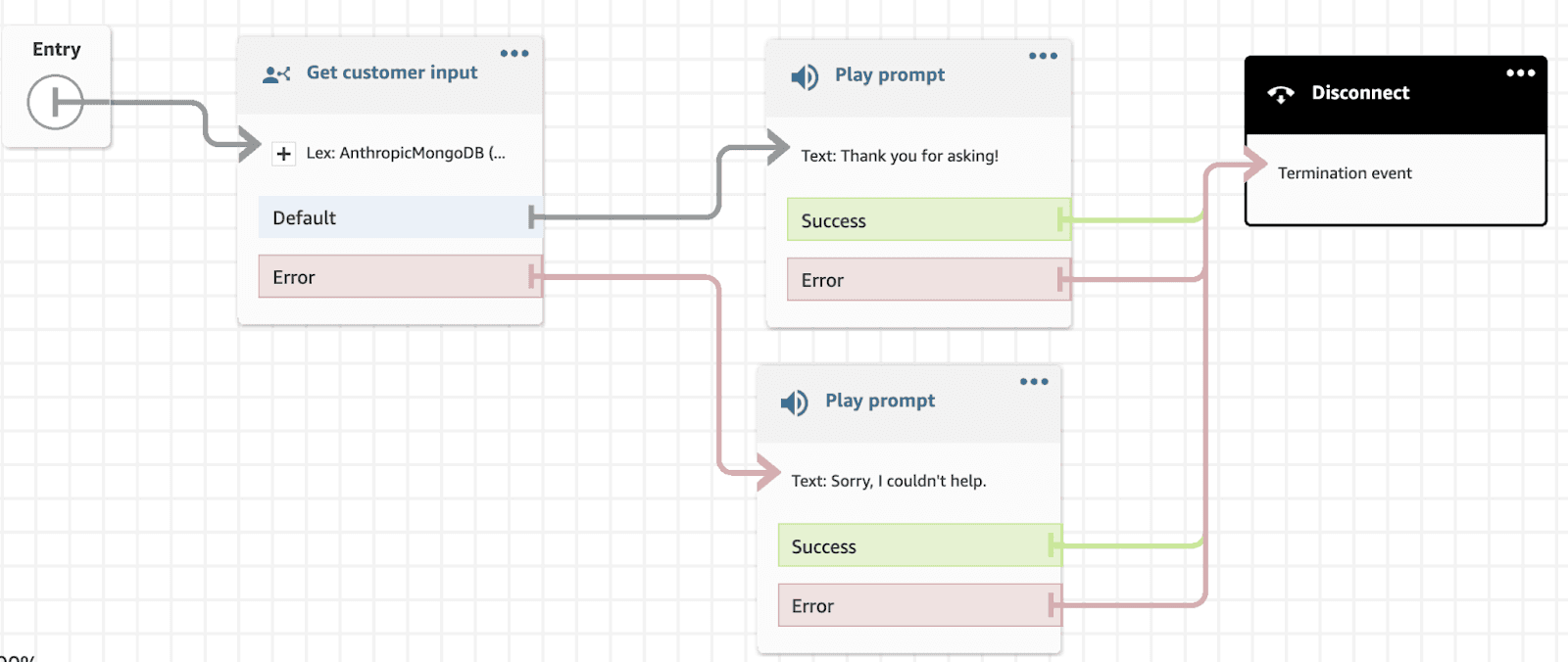
Figure 5: User journey on lex for the application flow.
Let us look at how this application architecture has been implemented for this exercise. In order to perform a match query against MongoDB, the Langchain Agent uses the following functions as tools. LangChain agents are AI components that use language models to choose a sequence of actions to take. MongoDB integrates the operational database and vector search in a single, unified, fully managed platform with full vector database capabilities. It stores users' operational data, metadata, and vector embeddings on Atlas while using Atlas Vector Search to build intelligent gen AI-powered applications.
For this article, we showcase only a few sample snippets to illustrate the user journey through the application. The whole code is available in the Repositório do GitHub.
A user wants to interact with a travel agent and search for a specific place by name. The following function can perform a basic MongoDB search on a travel dataset. It retrieves place names by matching a provided country name, using a case-insensitive regular expression ($regex) to search for documents where the "Country" field matches the query_str. The function then returns the "Place Name" field from the matched documents.
1 def mongodb_place_lookup_by_country(query_str: str) -> str: 2 """Retrieve place by Country Name""" 3 res = "" 4 res = collection.aggregate( 5 [ 6 {"$match": {"Country": {"$regex": query_str, "$options": "i"}}}, 7 {"$project": {"Place Name": 1}}, 8 ] 9 ) 10 places = [] 11 for place in res: 12 places.append(place["Place Name"]) 13 return str(places)
We’ve created two additional functions that work similarly for retrieving specific fields like "Place Name" and "Best Time To Visit" or get complete place details based on your search criteria. All these functions use case-insensitive regular expressions for flexible matching.
If the query does not have any keywords to perform a direct match, the LangChain agent will perform MongoDB vector search.
The LangChain agent performs MongoDB vector search when the user's query lacks a specific keyword for conducting a direct search on MongoDB.
1 # filter the data using the criteria and do a Schematic search 2 def mongodb_search(query: str) -> str: 3 """Retrieve results from MongoDB related to the user input by performing vector search. Pass text input only.""" 4 embeddings = BedrockEmbeddings( 5 client=bedrock_runtime, 6 model_id=embedding_model_id, 7 ) 8 text_as_embeddings = embeddings.embed_documents([query]) 9 embedding_value = text_as_embeddings[0] 10 11 12 # get the vector search results based on the filter conditions. 13 response = collection.aggregate( 14 [ 15 { 16 "$vectorSearch": { 17 "index": "awsanthropic_vector_index", 18 "path": "details_embedding", 19 "queryVector": embedding_value, 20 "numCandidates": 200, 21 "limit": 10, 22 } 23 }, 24 { 25 "$project": { 26 "score": {"$meta": "searchScore"}, 27 field_name_to_be_vectorized: 1, 28 "_id": 0, 29 } 30 }, 31 ] 32 ) 33 34 35 # Result is a list of docs with the array fields 36 docs = list(response) 37 38 39 # Extract an array field from the docs 40 array_field = [doc[field_name_to_be_vectorized] for doc in docs] 41 42 43 # Join array elements into a string 44 llm_input_text = "\n \n".join(str(elem) for elem in array_field) 45 46 47 # utility 48 newline, bold, unbold = "\n", "\033[1m", "\033[0m" 49 logging.info( 50 newline 51 + bold 52 + "Given Input From MongoDB Vector Search: " 53 + unbold 54 + newline 55 + llm_input_text 56 + newline 57 ) 58 59 60 return llm_input_text
Anthropic’s Claude hosted in Amazon Bedrock glues it together by choosing the best matching tools to perform search on MongoDB Atlas based on the user query. It improves the experience by presenting the output in a human-friendly format. The following functions initialize the LLM and add the MongoDB python functions as tools to the agent. It also stores the conversation history to MongoDB Atlas.
1 def get_session_history(session_id: str) -> MongoDBChatMessageHistory: 2 return MongoDBChatMessageHistory( 3 utils.get_MongoDB_Uri(), 4 session_id, 5 database_name="anthropic-travel-agency", 6 collection_name="chat_history", 7 ) 8 9 10 11 12 def interact_with_agent(sessionId, input_query, chat_history): 13 """Interact with the agent and store chat history. Return the response.""" 14 15 16 # Initialize bedrock and llm 17 bedrock_runtime = setup_bedrock() 18 llm = initialize_llm(bedrock_runtime) 19 20 21 # Initialize tools 22 tool_mongodb_search = StructuredTool.from_function(mongodb_search) 23 tool_mongodb_place_lookup_by_country = StructuredTool.from_function( 24 mongodb_place_lookup_by_country 25 ) 26 tool_mongodb_place_lookup_by_name = StructuredTool.from_function( 27 mongodb_place_lookup_by_name 28 ) 29 tool_mongodb_place_lookup_by_best_time_to_visit = StructuredTool.from_function( 30 mongodb_place_lookup_by_best_time_to_visit 31 ) 32 33 34 tools = [ 35 tool_mongodb_search, 36 tool_mongodb_place_lookup_by_country, 37 tool_mongodb_place_lookup_by_name, 38 tool_mongodb_place_lookup_by_best_time_to_visit, 39 ] 40 41 42 chat_message_int = MessagesPlaceholder(variable_name="chat_history") 43 44 45 memory = ConversationBufferMemory( 46 memory_key="chat_history", 47 chat_memory=get_session_history(sessionId), 48 return_messages=True, 49 ) 50 51 52 PREFIX = """You are a helpful and polite Travel recommendations assistant. Answer the following questions as best you can using only the provided tools and chat history. You have access to the following tools:""" 53 FORMAT_INSTRUCTIONS = """Always return only the final answer to the original input question in human readable format as text only without any extra special characters. Also tell all the tools you used to reach to this answer in brief.""" 54 SUFFIX = """Begin!""" 55 56 57 agent_executor = initialize_agent( 58 tools, 59 llm, 60 agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, 61 agent_kwargs={ 62 "memory_prompts": [chat_message_int], 63 "input_variables": ["input", "agent_scratchpad", "chat_history"], 64 "prefix":PREFIX, 65 "format_instructions":FORMAT_INSTRUCTIONS, 66 "suffix":SUFFIX 67 }, 68 memory=memory, 69 verbose=True, 70 max_iterations=3 71 ) 72 result = agent_executor.invoke( 73 { 74 "input": input_query, 75 "chat_history": chat_history, 76 } 77 ) 78 chat_history.append(HumanMessage(content=input_query)) 79 chat_history.append(AIMessage(content="Assistant: " + result["output"])) 80 return result
We can deploy the travel agency chatbot app on AWS Lambda using SAM CLI. The application can be tested by creating a bot on Amazon Lex. To add the bot to the Amazon Connect, navigate to your Amazon Connect Instance and then navigate to Flows. Select the Lex bot that you want to use.
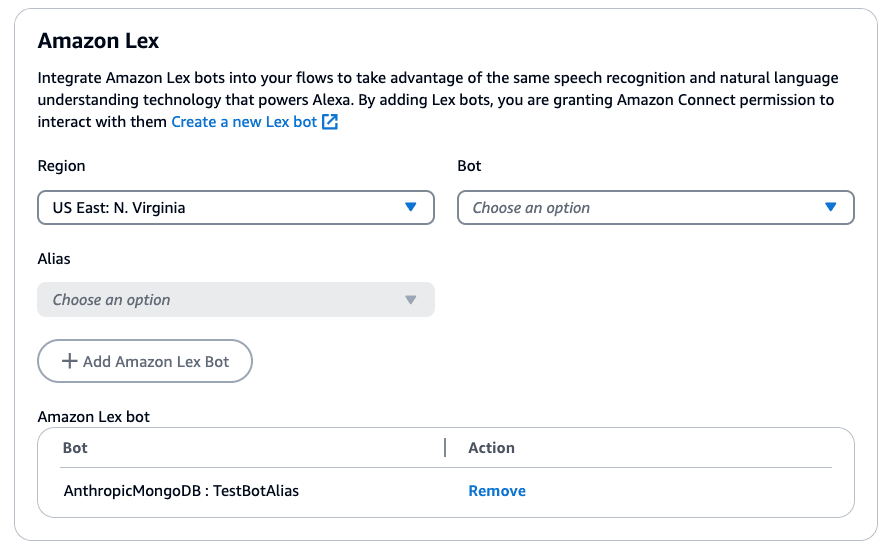
To use the bot in an Amazon Connect flow, add Get User Input Block. In the Block details, add Select Amazon Lex Bot:
For more information on adding Amazon Lex bots to Amazon Connect, refer to the documentation. To learn more about how to set up the application and test out the functionalities, refer to Github.
In this article, we explored how Anthropic's Claude in Amazon Bedrock with MongoDB Atlas can be leveraged to build and deploy an agentic RAG application. The resulting application is a memory-enhanced AI agent that provides personalized travel recommendations. This architecture efficiently manages both simple and complex queries, delivering accurate, user-friendly responses while ensuring a smooth and seamless conversational experience.
- The MongoDB AI Applications Program (MAAP) helps organizations rapidly build and deploy modern applications enriched with AI technology at enterprise scale.
Principais comentários nos fóruns
Ainda não há comentários sobre este artigo.