Raspador da web da bolsa de valores de Nairóbi





Avaliar este tutorial


Looking to build a web scraper using Python and MongoDB for the Nairobi Stock Exchange? Our comprehensive tutorial provides a step-by-step guide on how to set up the development environment, create a Scrapy spider, parse the website, and store the data in MongoDB.
We also cover best practices for working with MongoDB and tips for troubleshooting common issues. Plus, get a sneak peek at using MongoDB Atlas Charts for data visualization. Finally, enable text notifications using Africas Talking API (feel free to switch to your preferred provider). Get all the code on Github and streamline your workflow today!
The prerequisites below are verified to work on Linux. Implementation on other operating systems may differ. Kindly check installation instructions.
- What is web scraping?
- Project layout
- Configuração do projeto
- Starting a Scrapy project
- Creating a spider
- Running the scraper
- Enabling text alerts
- Data in MongoDB Atlas
- Charts in MongoDB Atlas
- CI/CD with GitHub Actions
- Conclusão
Web scraping is the process of extracting data from websites. It’s a form of data mining, which automates the retrieval of data from the web. Web scraping is a technique to automatically access and extract large amounts of information from a website or platform, which can save a huge amount of time and effort. You can save this data locally on your computer or to a database in the cloud.
Scrapy is a free and open-source web-crawling framework written in Python. It extracts the data you need from websites in a fast and simple yet extensible way. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
MongoDB Atlas is a fully managed cloud database platform that hosts your data on AWS, Google cloud, or Azure. It’s a fully managed database as a service (DBaaS) that provides a highly available, globally distributed, and scalable database infrastructure. Read our tutorial to get started with a free instance of MongoDB Atlas.
You can also head to our docs to learn about limiting access to your cluster to specified IP addresses. This step enhances security by following best practices.
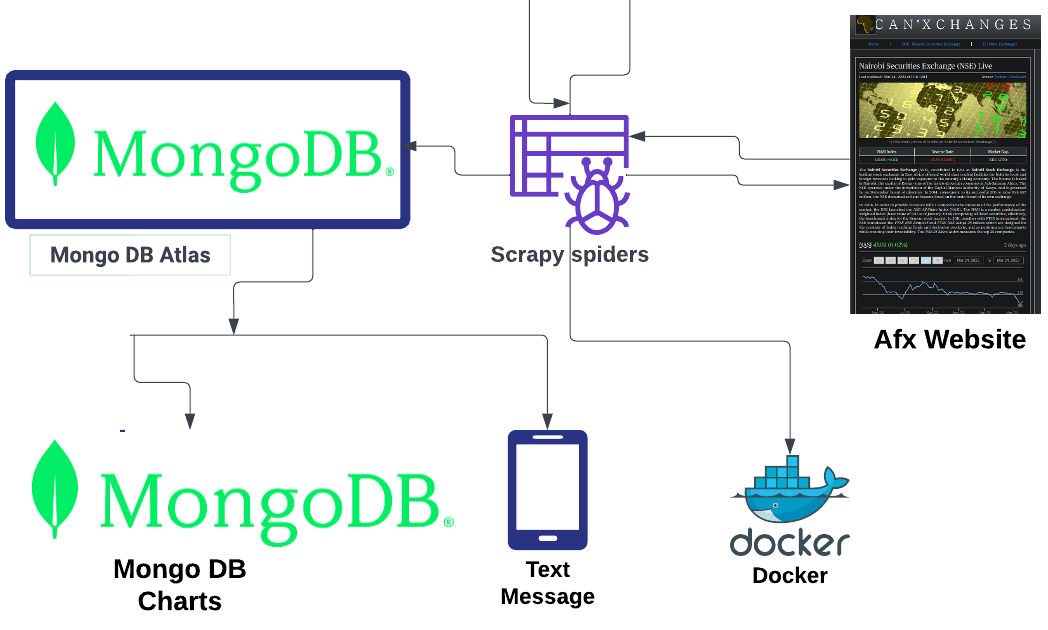
Below is a diagram that provides a high-level overview of the project.

The diagram above shows how the project runs as well as the overall structure. Let's break it down:
- Since Scrapy is a full framework, we use it to extract and clean the data.
- The data is sent to MongoDB Atlas for storage.
- From here, we can easily connect it to MongoDB Charts for visualizations.
- We package our web scraper using Docker for easy deployment to the cloud.
- The code is hosted on GitHub and we create a CI/CD pipeline using GitHub Actions.
- Finally, we have a text notification script that runs once the set conditions are met.
Let's set up our project. First, we'll create a new directory for our project. Open your terminal and navigate to the directory where you want to create the project. Then, run the following command to create a new directory and change into it .
1 mkdir nse-stock-scraper && cd nse-stock-scraper
Next, we'll create a virtual environment for our project. This will help us isolate our project dependencies from the rest of our system. Run the following command to create a virtual environment. We are using the inbuilt Ppython module
venv to create the virtual environment. Activate the virtual environment by running the activate script in the bin directory.1 python3 -m venv venv 2 source venv/bin/activate
Now, we'll install the required dependencies. We'll use
pip to install the dependencies. Run the following command to install the required dependencies:1 pip install scrapy pymongo[srv] dnspython python-dotenv beautifulsoup4 2 pip freeze > requirements.txt
Scrapy is a full framework. Thus, it has an opinionated view on the structure of its projects. It comes with a CLI tool to get started quickly. Now, we'll start a new Scrapy project. Run the following command.
1 scrapy startproject nse_scraper .
This will create a new directory with the name
nse_scraper and a few files. The nse_scraper directory is the actual Python package for our project. The files are as follows:items.py— This file contains the definition of the items that we will be scraping.middlewares.py— This file contains the definition of the middlewares that we will be using.pipelines.py— This contains the definition of the pipelines that we will be using.settings.py— This contains the definition of the settings that we will be using.spiders— This directory contains the spiders that we will be using.scrapy.cfg— This file contains the configuration of the project.
A spider is a class that defines how a certain site will be scraped. It must subclass
scrapy.Spider and define the initial requests to make — and optionally, how to follow links in the pages and parse the downloaded page content to extract data.We'll create a spider to scrape the afx website. Run the following command to create a spider. Change into the
nse_scraper folder that is inside our root folder.1 cd nse_scraper 2 scrapy genspider afx_scraper afx.kwayisi.org
This will create a new file
afx_scraper.py in the spiders directory. Open the file and replace the contents with the following code:1 from scrapy.settings.default_settings import CLOSESPIDER_PAGECOUNT, DEPTH_LIMIT 2 from scrapy.spiders import CrawlSpider, Rule 3 from bs4 import BeautifulSoup 4 from scrapy.linkextractors import LinkExtractor 5 6 7 class AfxScraperSpider(CrawlSpider): 8 name = 'afx_scraper' 9 allowed_domains = ['afx.kwayisi.org'] 10 start_urls = ['https://afx.kwayisi.org/nse/'] 11 user_agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36' 12 custom_settings = { 13 DEPTH_LIMIT: 1, 14 CLOSESPIDER_PAGECOUNT: 1 15 } 16 17 rules = ( 18 Rule(LinkExtractor(deny='.html', ), callback='parse_item', follow=False), 19 Rule(callback='parse_item'), 20 ) 21 22 def parse_item(self, response, **kwargs): 23 print("Processing: " + response.url) 24 # Extract data using css selectors 25 row = response.css('table tbody tr ') 26 # use XPath and regular expressions to extract stock name and price 27 raw_ticker_symbol = row.xpath('td[1]').re('[A-Z].*') 28 raw_stock_name = row.xpath('td[2]').re('[A-Z].*') 29 raw_stock_price = row.xpath('td[4]').re('[0-9].*') 30 raw_stock_change = row.xpath('td[5]').re('[0-9].*') 31 32 # create a function to remove html tags from the returned list 33 def clean_stock_symbol(raw_symbol): 34 clean_symbol = BeautifulSoup(raw_symbol, "lxml").text 35 clean_symbol = clean_symbol.split('>') 36 if len(clean_symbol) > 1: 37 return clean_symbol[1] 38 else: 39 return None 40 41 def clean_stock_name(raw_name): 42 clean_name = BeautifulSoup(raw_name, "lxml").text 43 clean_name = clean_name.split('>') 44 if len(clean_name[0]) > 2: 45 return clean_name[0] 46 else: 47 return None 48 49 def clean_stock_price(raw_price): 50 clean_price = BeautifulSoup(raw_price, "lxml").text 51 return clean_price 52 53 # Use list comprehension to unpack required values 54 stock_name = [clean_stock_name(r_name) for r_name in raw_stock_name] 55 stock_price = [clean_stock_price(r_price) for r_price in raw_stock_price] 56 ticker_symbol = [clean_stock_symbol(r_symbol) for r_symbol in raw_ticker_symbol] 57 stock_change = [clean_stock_price(raw_change) for raw_change in raw_stock_change] 58 if ticker_symbol is not None: 59 cleaned_data = zip(ticker_symbol, stock_name, stock_price) 60 for item in cleaned_data: 61 scraped_data= { 62 'ticker_symbol': item[0], 63 'stock_name': item[1], 64 'stock_price': item[2], 65 'stock_change': stock_change } 66 # yield info to scrapy 67 yield scraped_data
Let's break down the code above. First, we import the required modules and classes. In our case, we'll be using _CrawlSpider _and Rule from scrapy.spiders and LinkExtractor from scrapy.linkextractors. We'll also be using BeautifulSoup from bs4 to clean the scraped data.
The
AfxScraperSpider class inherits from CrawlSpider, which is a subclass of Spider. The Spider class is the core of Scrapy. It defines how a certain site (or a group of sites) will be scraped. It contains an initial list of URLs to download, and rules to follow links in the pages and extract data from them. In this case, we'll be using CrawlSpider to crawl the website and follow links to the next page.The name attribute defines the name of the spider. This name must be unique within a project — that is, you can’t set the same name for different spiders. It will be used to identify the spider when you run it from the command line.
The allowed_domains attribute is a list of domains that this spider is allowed to crawl. If it isn’t specified, no domain restrictions will be in place. This is useful if you want to restrict the crawling to a particular domain (or subdomain) while scraping multiple domains in the same project. You can also use it to avoid crawling the same domain multiple times when using multiple spiders.
The start_urls attribute is a list of URLs where the spider will begin to crawl from. When no start_urls are defined, the start URLs are read from the sitemap.xml file (if it exists) of the first domain in the allowed_domains list. If you don’t want to start from a sitemap, you can define an initial URL in this attribute. This attribute is optional and can be omitted.
The user_agent attribute is used to set the user agent for the spider. This is useful when you want to scrape a website that blocks spiders that don't have a user agent. In this case, we'll be using a user agent for Chrome. We can also set the user agent in the settings.py file. This is key to giving the target website the illusion that we are a real browser.
The custom_settings attribute is used to set custom settings for the spider. In this case, we'll be setting the DEPTH_LIMIT to 1 and CLOSESPIDER_PAGECOUNT to 1. The DEPTH_LIMIT attribute limits the maximum depth that will be allowed to crawl for any site. Depth refers to the number of page(s) the spider is allowed to crawl. The CLOSESPIDER_PAGECOUNT attribute is used to close the spider after crawling the specified number of pages.
The rules attribute defines the rules for the spider. We'll be using the Rule class to define the rules for extracting links from a page and processing them with a callback, or following them and scraping them using another spider.
The Rule class takes a LinkExtractor object as its first argument. The LinkExtractor class is used to extract links from web pages. It can extract links matching specific regular expressions or using specific attributes, such as href or src.
The deny argument is used to deniesy the extraction of links that match the specified regular expression. The callback argument specifiesis used to specify the callback function to be called on the response of the extracted links.
The follow argument specifies whether the links extracted should be followed or not. We'll be using the callback argument to specify the callback function to be called on the response of the extracted links. We'll also be using the follow argument to specify whether the links extracted should be followed or not.
We then define a
parse_item function that takes response as an argument. The parse_item function is used to parses the response and extracts the required data. We'll use the xpath method to extract the required data. The xpath method extracts data using XPath expressions.We get xpath expressions by inspecting the target website. Basically, we right-click on the element we want to extract data from and click on
inspect. This will open the developer tools. We then click on the copy button and select copy xpath. Paste the xpath expression in the xpath method.The
re method extracts data using regular expressions. We then use the clean_stock_symbol, clean_stock_name, e clean_stock_price functions to clean the extracted data. Use the zip function to combine the extracted data into a single list. Then, use a for loop to iterate through the list and yield the data to Scrapy.The clean_stock_symbol, clean_stock_name, and clean_stock_price functions are used to clean the extracted data. The clean_stock_symbol function takes the raw symbol as an argument. BeautifulSoup class cleans the raw symbol. It then uses the split method to split the cleaned symbol into a list. An if statement checks if the length of the list is greater than 1. If it is, it returns the second item in the list. If it isn't, it returns None.
The clean_stock_name function takes the raw name as an argument. It uses the BeautifulSoup class to clean the raw name. It then uses the split method to split the cleaned name into a list. Again, an if statement will check if the length of the list is greater than 1. If it is, it returns the first item in the list. If it isn't, it returns None. The clean_stock_price function takes the raw price as an argument. It then uses the BeautifulSoup class to clean the raw price and return the cleaned price.
The clean_stock_change function takes the raw change as an argument. It uses the BeautifulSoup class to clean the raw change and return the cleaned data.
Inside the root of our project, we have the
items.py file. An item is a container which will be loaded with the scraped data. It works similarly to a dictionary with additional features like declaring its fields and customizing its export. We'll be using the Item class to create our items. The Item class is the base class for all items. It provides the general mechanisms for handling data from scraped pages. It’s an abstract class and cannot be instantiated directly. We'll be using the Field class to create our fields.Add the following code to the nse_scraper/items.py file:
1 from scrapy.item import Item, Field 2 3 4 class NseScraperItem(Item): 5 # define the fields for your item here like: 6 ticker_symbol = Field() 7 stock_name = Field() 8 stock_price = Field() 9 stock_change = Field()
The NseScraperItem class is creates our item. The ticker_symbol, stock_name, stock_price, and stock_change fields store the ticker symbol, stock name, stock price, and stock change respectively. Read more on items Aqui.
Inside the root of our project, we have the
pipelines.py file. A pipeline is a component which processes the items scraped from the spiders. It can clean, validate, and store the scraped data in a database. We'll use the Pipeline class to create our pipelines. The Pipeline class is the base class for all pipelines. It provides the general methods and properties that the pipeline will use.Add the following code to the
pipelines.py file:1 # pipelines.py 2 # useful for handling different item types with a single interface 3 import pymongo 4 from scrapy.exceptions import DropItem 5 6 from .items import NseScraperItem 7 8 9 class NseScraperPipeline: 10 collection = "stock_data" 11 12 def __init__(self, mongodb_uri, mongo_db): 13 self.db = None 14 self.client = None 15 self.mongodb_uri = mongodb_uri 16 self.mongo_db = mongo_db 17 if not self.mongodb_uri: 18 raise ValueError("MongoDB URI not set") 19 if not self.mongo_db: 20 raise ValueError("Mongo DB not set") 21 22 @classmethod 23 def from_crawler(cls, crawler): 24 return cls( 25 mongodb_uri=crawler.settings.get("MONGODB_URI"), 26 mongo_db=crawler.settings.get('MONGO_DATABASE', 'nse_data') 27 ) 28 29 def open_spider(self, spider): 30 self.client = pymongo.MongoClient(self.mongodb_uri) 31 self.db = self.client[self.mongo_db] 32 33 def close_spider(self, spider): 34 self.client.close() 35 36 def clean_stock_data(self,item): 37 if item['ticker_symbol'] is None: 38 raise DropItem('Missing ticker symbol in %s' % item) 39 elif item['stock_name'] == 'None': 40 raise DropItem('Missing stock name in %s' % item) 41 elif item['stock_price'] == 'None': 42 raise DropItem('Missing stock price in %s' % item) 43 else: 44 return item 45 46 def process_item(self, item, spider): 47 """ 48 process item and store to database 49 """ 50 51 clean_stock_data = self.clean_stock_data(item) 52 data = dict(NseScraperItem(clean_stock_data)) 53 print(data) 54 # print(self.db[self.collection].insert_one(data).inserted_id) 55 self.db[self.collection].insert_one(data) 56 57 return item
First, we import the pymongo module. We then import the DropItem class from the scrapy.exceptions module. Next, import the NseScraperItem class from the items module.
The NseScraperPipeline class creates our pipeline. The collection variable store the name of the collection we'll be using. The init method initializes the pipeline. It takes the mongodb_uri and mongo_db as arguments. It then uses an if statement to check if the mongodb_uri is set. If it isn't, it raises a ValueError. Next, it uses an if statement to check if the mongo_db is set. If it isn't, it raises a ValueError.
The from_crawler method creates an instance of the pipeline. It takes the crawler as an argument. It then returns an instance of the pipeline. The open_spider method opens the spider. It takes the spider as an argument. It then creates a MongoClient instance and stores it in the client variable. It uses the client instance to connect to the database and stores it in the db variable.
The close_spider method closes the spider. It takes the spider as an argument. It then closes the client instance. The clean_stock_data method cleans the scraped data. It takes the item as an argument. It then uses an if statement to check if the ticker_symbol is None. If it is, it raises a DropItem. Next, it uses an if statement to check if the stock_name is None. If it is, it raises a DropItem. It then uses an if statement to check if the stock_price is None. If it is, it raises a DropItem. If none of the if statements are true, it returns the item.
The process_item method processes the scraped data. It takes the item and spider as arguments. It then uses the clean_stock_data method to clean the scraped data. It uses the dict function to convert the item to a dictionary. Next, it prints the data to the console. It then uses the db instance to insert the data into the database. It returns the item.
Inside the root of our project, we have the
settings.py file. This file is used to stores our project settings. Add the following code to the settings.py file:1 # settings.py 2 import os 3 from dotenv import load_dotenv 4 5 load_dotenv() 6 BOT_NAME = 'nse_scraper' 7 8 SPIDER_MODULES = ['nse_scraper.spiders'] 9 NEWSPIDER_MODULE = 'nse_scraper.spiders' 10 11 # MONGODB SETTINGS 12 MONGODB_URI = os.getenv("MONGODB_URI") 13 MONGO_DATABASE = os.getenv("MONGO_DATABASE") 14 15 ITEM_PIPELINES = { 16 'nse_scraper.pipelines.NseScraperPipeline': 300, 17 } 18 LOG_LEVEL = "INFO" 19 20 # USER_AGENT = 'nse_scraper (+http://www.yourdomain.com)' 21 22 # Obey robots.txt rules 23 ROBOTSTXT_OBEY = False 24 25 26 # Override the default request headers: 27 DEFAULT_REQUEST_HEADERS = { 28 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 29 'Accept-Language': 'en', 30 } 31 32 # Enable and configure HTTP caching (disabled by default) 33 # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings 34 HTTPCACHE_ENABLED = True 35 HTTPCACHE_EXPIRATION_SECS = 360 36 HTTPCACHE_DIR = 'httpcache' 37 # HTTPCACHE_IGNORE_HTTP_CODES = [] 38 HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
First, we import the
os and load_dotenv modules. We then call the load_dotenv function. It takes no arguments. This function loads the environment variables from the .env file.nse_scraper.spiders. We append the MONGODB_URI variable and set it to the MONGODB_URI environment variable. Next, we create the MONGODB_DATABASE variable and set it to the MONGO_DATABASE environment variable.After, we create the
ITEM_PIPELINES variable and set it to nse_scraper.pipelines.NseScraperPipeline. We then create the LOG_LEVEL variable and set it to INFO. The DEFAULT_REQUEST_HEADERS variable is set to a dictionary. Next, we create the HTTPCACHE_ENABLED variable and set it to True.Change the
HTTPCACHE_EXPIRATION_SECS variable and set it to 360. Create the HTTPCACHE_DIR variable and set it to httpcache. Finally, create the HTTPCACHE_STORAGE variable and set it to scrapy.extensions.httpcache.FilesystemCacheStorage.The project structure is as follows:
1 ├ nse_stock_scraper 2 ├ nse_scraper 3 ├── __init__.py 4 │ ├── items.py 5 │ ├── middlewares.py 6 │ ├── pipelines.py 7 │ ├── settings.py 8 ├─ stock_notification.py 9 │ └── spiders 10 │ ├── __init__.py 11 │ └── afx_scraper.py 12 ├── README.md 13 ├── LICENSE 14 ├── requirements.txt 15 └── scrapy.cfg 16 ├── .gitignore 17 ├── .env
To run the scraper, we'll need to open a terminal and navigate to the project directory. We'll then need to activate the virtual environment if it's not already activated. We can do this by running the following command:
1 source venv/bin/activate
Create a
.env file in the root of the project (in /nse_scraper/). Add the following code to the .env file:1 MONGODB_URI=mongodb+srv:// 2 MONGODB_DATABASE= 3 at_username= 4 at_api_key= 5 mobile_number=
Add your MongoDB URI, database name, Africas Talking username, API key, and mobile number to the
.env file for your MongoDB URI. You can use the free tier of MongoDB Atlas. Get your URI over on the Atlas dashboard, under the connect button. It should look something like this:1 mongodb+srv://<username>:<password>@<cluster-name>.mongodb.net/<database-name>?retryWrites=true&w=majority
We need to run the following command to run the scraper while in the project folder:
(/nse_scraper /):
1 scrapy crawl afx_scraper
Install the
africastalking module by running the following command in the terminal:1 pip install africastalking
Create a new file called
stock_notification.py in the nse_scraper directory. Add the following code to the stock_notification.py file:
1 # stock_notification.py 2 import africastalking as at 3 import os 4 from dotenv import load_dotenv 5 import pymongo 6 7 load_dotenv() 8 9 at_username = os.getenv("at_username") 10 at_api_key = os.getenv("at_api_key") 11 mobile_number = os.getenv("mobile_number") 12 mongo_uri = os.getenv("MONGODB_URI") 13 14 # Initialize the Africas sdk py passing the api key and username from the .env file 15 at.initialize(at_username, at_api_key) 16 sms = at.SMS 17 account = at.Application 18 19 20 ticker_data = [] 21 22 # Create a function to send a message containing the stock ticker and price 23 def stock_notification(message: str, number: int): 24 try: 25 response = sms.send(message, [number]) 26 print(account.fetch_application_data()) 27 print(response) 28 except Exception as e: 29 print(f" Houston we have a problem: {e}") 30 31 # create a function to query mongodb for the stock price of Safaricom 32 def stock_query(): 33 client = pymongo.MongoClient(mongo_uri) 34 db = client["nse_data"] 35 collection = db["stock_data"] 36 # print(collection.find_one()) 37 ticker_data = collection.find_one({"ticker": "BAT"}) 38 print(ticker_data) 39 stock_name = ticker_data["name"] 40 stock_price = ticker_data["price"] 41 sms_data = { "stock_name": stock_name, "stock_price": stock_price } 42 print(sms_data) 43 44 message = f"Hello the current stock price of {stock_name} is {stock_price}" 45 # check if Safaricom share price is more than Kes 39 and send a notification. 46 if int(float(stock_price)) >= 38: 47 # Call the function passing the message and mobile_number as a arguments 48 print(message) 49 stock_notification(message, mobile_number) 50 else: 51 print("No notification sent") 52 53 client.close() 54 55 return sms_data 56 57 stock_query()
The code above imports the
africastalking module. Import the os and load_dotenv modules. We proceed to call the load_dotenv function. It takes no arguments. This function loads the environment variables from the .env file.- We create the
at_usernamevariable and set it to theat_usernameenvironment variable. We then create theat_api_keyvariable and set it to theat_api_keyenvironment variable. Create themobile_numbervariable and set it to themobile_numberenvironment variable. And create themongo_urivariable and set it to theMONGODB_URIenvironment variable. - We initialize the
africastalkingmodule by passing theat_usernameandat_api_keyvariables as arguments. Create thesmsvariable and set it toat.SMS. Create theaccountvariable and set it toat.Application. - Create the
ticker_datavariable and set it to an empty list. Create thestock_notificationfunction. It takes two arguments:messageandnumber. We then try to send the message to the number and print the response. Look for any exceptions and display them. - We created the
stock_queryfunction. We then create theclientvariable and set it to apymongo.MongoClientobject. Create thedbvariable and set it to thense_datadatabase. Then, create thecollectionvariable and set it to thestock_datacollection, and create theticker_datavariable and set it to thecollection.find_onemethod. It takes a dictionary as an argument.
The
stock_name variable is set to the name key in the ticker_data dictionary. Create the stock_price variable and set it to the price key in the ticker_data dictionary. Create the sms_data variable and set it to a dictionary. It contains the stock_name and stock_price variables.The
message variable is set to a string containing the stock name and price. We check if the stock price is greater than or equal to 38. If it is, we call the stock_notification function and pass the message and mobile_number variables as arguments. If it isn't, we print a message to the console.Close the connection to the database and return the
sms_data variable. Call the stock_query function.We need to add the following code to the
afx_scraper.py file:1 # afx_scraper.py 2 from nse_scraper.stock_notification import stock_query 3 4 # ... 5 6 # Add the following code to the end of the file 7 stock_query()
If everything is set up correctly, you should something like this:
We need to create a new cluster in MongoDB Atlas. We can do this by:
- Clicking on the
Build a Clusterbutton. - Selecting the
Shared Clustersoption. - Selecting the
Free Tieroption. - Selecting the
Cloud Provider & Regionoption. - Selecting the
AWSoption. (I selected the AWS Cape Town option.) - Selecting the
Cluster Nameoption. - Giving the cluster a name. (We can call it
nse_data.)
Let’s configure a user to access the cluster by following the steps below:
- Select the
Database Accessoption. - Click on the
Add New Useroption. - Give the user a username. (I used
nse_user.). - Give the user a password. (I used
nse_password). - Select the
Network Accessoption. - Select the
Add IP Addressoption. - Select the
Allow Access from Anywhereoption. - Select the
Clusteroption. We'll then need to select theCreate Clusteroption.
Click on the
Collections option and then on the + Create Database button. Give the database a name. We can call it nse_data. Click on the + Create Collection button. Give the collection a name. We can call it stock_data. If everything is set up correctly, you should see something like this:
If you see an empty collection, rerun the project in the terminal to populate the values in MongoDB. Incase of an error, read through the terminal output. Common issues could be:
- The IP aAddress was not added in the dashboard.
- A lLack of/iIncorrect credentials in your .env file.
- A sSyntax error in your code.
- A poorCheck your internet connection.
- A lLack of appropriate permissions for your user.
Let's go through how to view metrics related to our database(s).
- Click on the **
Metricsoption. - Click on the
+ Add Metricbutton. - Select the
Databaseoption. - Select the
nse_dataoption. - Select the
Collectionoption. - Select the
stock_dataoption. - Select the
Metricoption. - Select the
Documentsoption. - Select the
Time Rangeoption. - Select the
Last 24 Hoursoption. - Select the
Granularityoption. - Select the
1 Houroption. - Click on the
Add Metricbutton.
If everything is set up correctly, it will look like this:

MongoDB Atlas offers charts that can be used to visualize the data in the database. Click on the
Charts option. Then, click on the + Add Chart button. Select the Database option. Below is a screenshot of sample charts for NSE data:
Run the following command in your terminal to initialize a git repository:
1 git init
Create a
.gitignore file. We can do this by running the following command in our terminal:1 touch .gitignore
Let’s add the .env file to the .gitignore file. Add the following code to the
.gitignore file:1 # .gitignore 2 .env
Add the files to the staging area by running the following command in our terminal:
1 git add .
Commit the files to the repository by running the following command in our terminal:
1 git commit -m "Initial commit"
Create a new repository on GitHub by clicking on the
+ icon on the top right of the page and selecting New repository. Give the repository a name. We can call it nse-stock-scraper. Select Public as the repository visibility. Select Add a README file and Add .gitignore and select Python from the dropdown. Click on the Create repository button.Add the remote repository to our local repository by running the following command in your terminal:
1 git remote add origin
Push the files to the remote repositor by running the following command in your terminal:
1 git push -u origin master
Create a new folder —
.github — and a workflows folder inside, in the root directory of the project. We can do this by running the following command in our terminal. Inside the workflows file, we'll need to create a new file called scraper-test.yml. We can do this by running the following command in our terminal:1 touch .github/workflows/scraper-test.yml
Inside the
scraper-test.yml file, we'll need to add the following code:
1 name: Scraper test with MongoDB 2 3 on: [push] 4 5 jobs: 6 build: 7 8 runs-on: ubuntu-latest 9 strategy: 10 matrix: 11 python-version: [3.8, 3.9, "3.10"] 12 mongodb-version: ['4.4', '5.0', '6.0'] 13 14 steps: 15 - uses: actions/checkout@v2 16 - name: Set up Python ${{ matrix.python-version }} 17 uses: actions/setup-python@v1 18 with: 19 python-version: ${{ matrix.python-version }} 20 - name: Set up MongoDB ${{ matrix.mongodb-version }} 21 uses: supercharge/mongodb-github-action@1.8.0 22 with: 23 mongodb-version: ${{ matrix.mongodb-version }} 24 - name: Install dependencies 25 run: | 26 python -m pip install --upgrade pip 27 pip install -r requirements.txt 28 - name: Lint with flake8 29 run: | 30 pip install flake8 31 # stop the build if there are Python syntax errors or undefined names 32 flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics 33 # exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide 34 flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics 35 - name: scraper-test 36 run: | 37 cd nse_scraper 38 export MONGODB_URI=mongodb://localhost:27017 39 export MONGO_DATABASE=nse_data 40 scrapy crawl afx_scraper -a output_format=csv -a output_file=afx.csv 41 scrapy crawl afx_scraper -a output_format=json -a output_file=afx.json
Let's break down the code above. We create a new workflow called
Scraper test with MongoDB. We then set the on event to push. Create a new job called build. Set the runs-on to ubuntu-latest. Set the strategy to a matrix. It contains the python-version and mongodb-version variables. Set the python-version to 3.8, 3.9, e 3.10. Set the mongodb-version to 4.4, 5.0, e 6.0.Create a new step called
Checkout. Set the uses to actions/checkout@v2. Create a new step called Set up Python ${{ matrix.python-version }} and set the uses to actions/setup-python@v1. Set the python-version to ${{ matrix.python-version }}. Create a new step called Set up MongoDB ${{ matrix.mongodb-version }}. This sets up different Python versions and MongoDB versions for testing.The
Install dependencies step installs the dependencies. Create a new step called Lint with flake8. This step lints the code. Create a new step called scraper-test. This step runs the scraper and tests it.Commit the changes to the repository by running the following command in your terminal:
1 git add . 2 git commit -m "Add GitHub Actions" 3 git push
Go to the
Actions tab on your repository. You should see something like this:
In this tutorial, we built a stock price scraper using Python and Scrapy. We then used MongoDB to store the scraped data. We used Africas Talking to send SMS notifications. Finally, we implemented a CI/CD pipeline using GitHub Actions.
There are definite improvements that can be made to this projeto, projeto. For example, we can add more stock exchanges. We can also add more notification channels. This project should serve as a good starting point.
Thank you for reading through this far., I hope you have gained insight or inspiration for your next project with MongoDB Atlas. Feel free to comment below or reach out for further improvements. We’d love to hear from you! This project is oOpen sSource and available on GitHub —, clone or fork it!, I’m excited to see what you build.
Avaliar este tutorial
Relacionado
Artigo
Capturando e armazenando óptica do mundo real com o MongoDB Atlas, o GPT-4 da OpenAI e o PyMongo
Sep 04, 2024 | 7 min read
Tutorial
Como distribuir um aplicativo no Kubernetes com o MongoDB Atlas Operator
Mar 13, 2025 | 9 min read