Atlas Search Playground: Easy Experimentation
May 29, 2024 | Updated: July 21, 2025
What is Atlas Search and why a playground?
MongoDB Atlas Search adds powerful, relevant, full-text lexical search on top of your data. A simple click-click-click Atlas Search index on your collection will make all string fields searchable in full-text ways and can provide drastic user experience improvements in finding relevant content quickly.
So, while a dynamic=true index can handle most data types and especially string fields, there are many nuanced challenges of full-text search that can require some configuration tweaks, such as language-specific handling (singular/plural, diacritics, stop words, etc.), synonym management, domain-specific entities, terminology, and patterns. There is a never-ending refinement process for understanding how search is being used on your data and tuning the configuration and queries accordingly.
It’s always been a helpful and common practice for us developers to have a “playground” of sorts in order to have an isolated bit of test data and a manual interactive environment to try out one thing at a time. With Atlas Search, I often create a temporary test collection with only a document or three that I crafted through the Atlas UI. Then, I'll create an Atlas Search index for that test collection, and use the Search Tester or the aggregation pipeline tool in the Atlas UI and Compass to try out various queries to see what matches and what doesn’t. This involves tweaking both the queries and index configuration (and waiting for the index to rebuild!) to adjust as I evolve index time analysis and query time clause building. Then, I’ll add a handful more documents to the test collection to see how relevancy is playing out once matching on just a test doc works fine. From there, I’ll take what I’ve learned and copy/paste/adapt the configuration and query into my application.
Given that the above steps are tackled by all of us in the trenches of search implementation, it made sense to build an environment that takes out the friction of collection creation, data import, index definition, index build time, and query testing. The end result provides a free, easy-to-use sandbox to streamline the data/index/test process.
Introducing the Atlas Search Playground...
The Playground layout
Let’s just jump right in. Open the following link in another browser to go into a sandbox with the environment shown in the screenshot. This demonstrates one of the coolest features of Atlas Search Playground: shareable links. A shared link encompasses the data, configuration, and query shared by the creator.
https://search-playground.mongodb.com/snapshots/664738af4e0a3f240a5de9d9
Press Run to see the magic happen!
DISCLAIMER: The Atlas Search Playground is an active work in progress at the time of writing, and some big improvements to it are likely. The screenshots shown here may vary from your experience. It’s a playground, after all — who knows where the shovels and toy vehicles will be tomorrow?
Update: As stated earlier, the playground has evolved since this article was first published. It began as only the Code Sandbox, and has been joined by the Search Demo Builder. Learn more about this new playground equipment starting at the Search Demo Builder announcement.

First, note the Get Help drop-down in the top left, which currently includes links to the playground documentation, an interactive tutorial of the Code Sandbox, and a feedback link so you can help us improve the playground experience. And there's a “Select Template” button at the top too. Templates are built-in Code Sandbox examples that you can select and run to get an idea of how a few common use cases are tackled with Atlas Search.
Let’s now discuss each pane in detail, in the logical workflow order.
Data source
The Data Source pane contains a JSON array of documents. There’s a handy import button if you’ve got a small set of documents on file. Otherwise, craft your own by hand or paste some in.
An array of only a single document with a single field is a good start, to get the feel for running a query to see if that document matches. In the example shown above, the document has a string name field that contains the word “Playground.”
The Data Source pane also has a separate section for synonyms.
Check out the Catalog Search template for an example of how to wire synonyms into the index configuration and leverage them during queries. Select a template from the menu on the left, and pick the “Catalog Search” template.
Index
Atlas Search index definition lives in the Index pane. A good starting point is a dynamic definition that maps
most of the document fields. In the example shown above, the name field is mapped automatically to the underlying Atlas Search index using the default lucene.standard analyzer. This default analyzer will tokenize string values into their individual lowercased “words,” making string text values generally searchable by the word-like pieces in a case-insensitive manner.
Query
Provide an aggregation pipeline containing $search as the first stage in this pane. This is not a full MongoDB aggregation pipeline engine, though it supports the common ones you need to handle search results.
In the example shown above, the query is a text query on the name field for the term "pLaYgRoUnD", which does not match the original content unless the case is ignored.
Results
This starts empty. Press Run to execute the Query stages and display the results into this pane.
In the example shown above, the results include the input document, showing that it matches the $search operator specified; if it had not matched, an empty array [] would be returned.
The following animation demonstrates how the playground works: A single document data source (bottom-left pane) is indexed through the configuration (top-right pane) and queried (top-left pane) through the same configuration, producing the results (bottom-right pane).
Good Examples
Catalog Search Template
The “Catalog Search” template (from the Select Template link on the left side) covers several common use case examples: exact value match (token field type), numeric field support and range query example, and a string field search leveraging synonyms. There’s a lot going on here in this fairly small amount of configuration and query example. Don’t forget to press Run!
Plurals not matching
Here’s a playground that demonstrates working through a particular query challenge, again press Run after loaded:
https://search-playground.mongodb.com/snapshots/664739964e0a3f240a5de9db
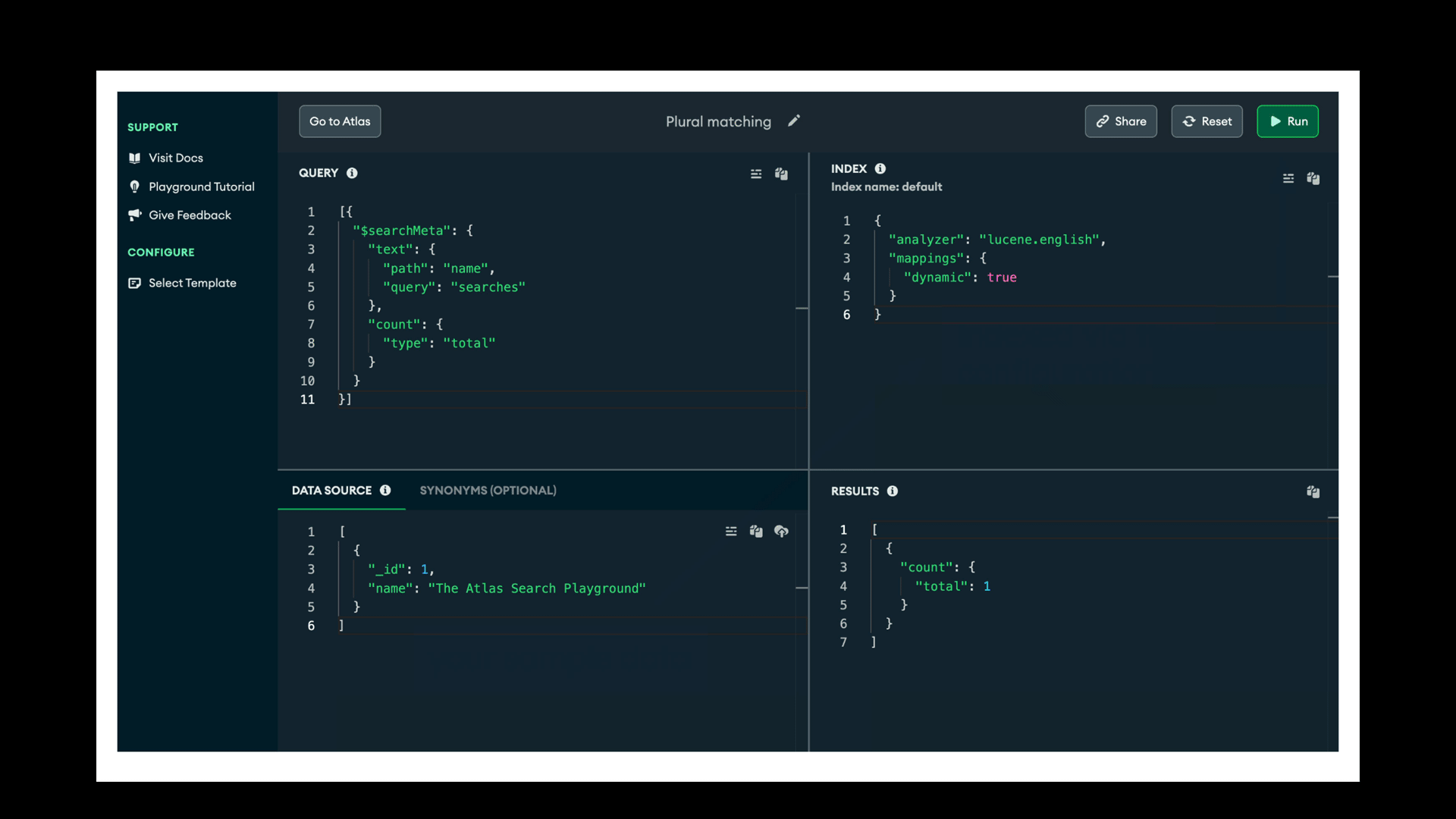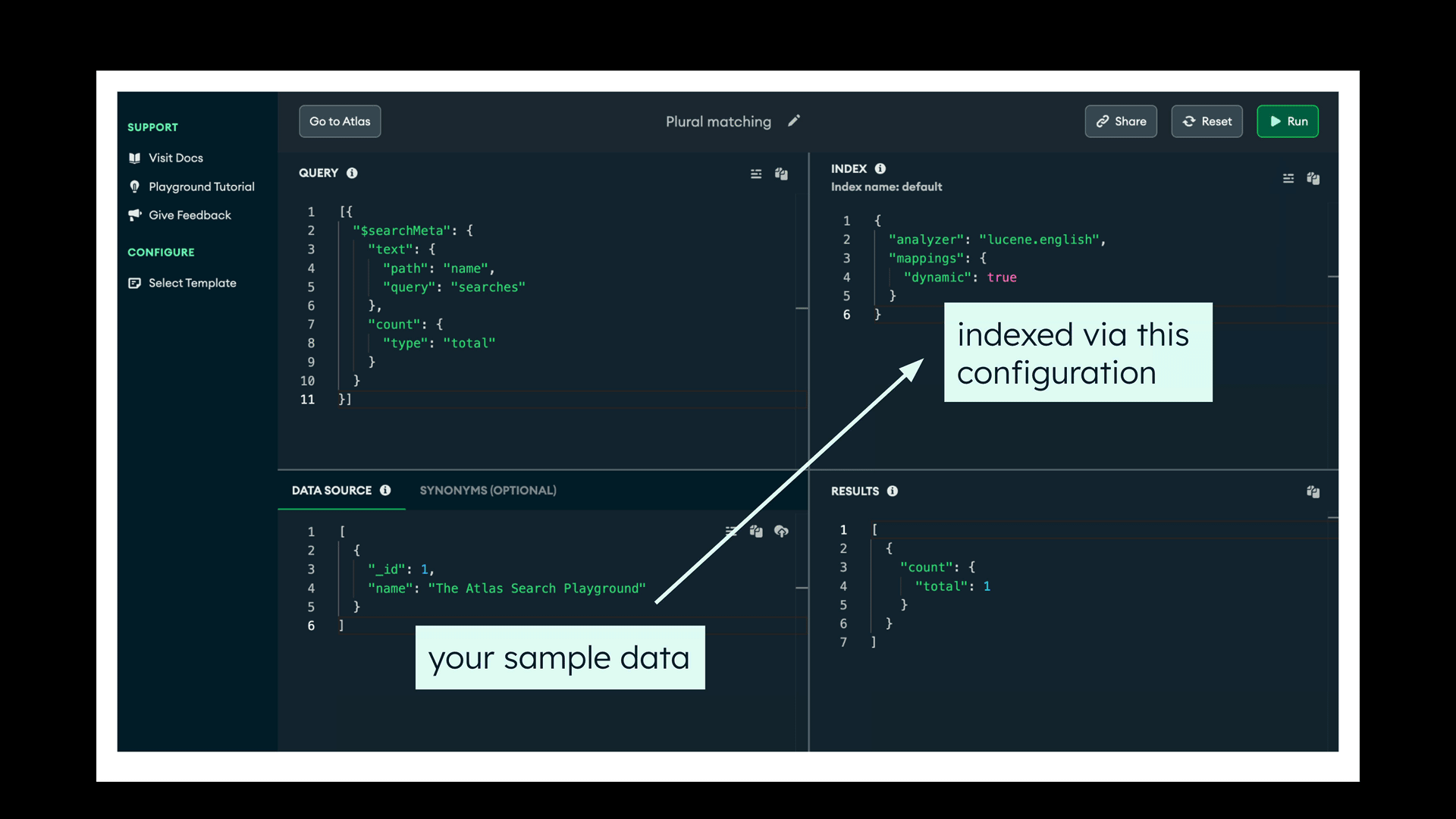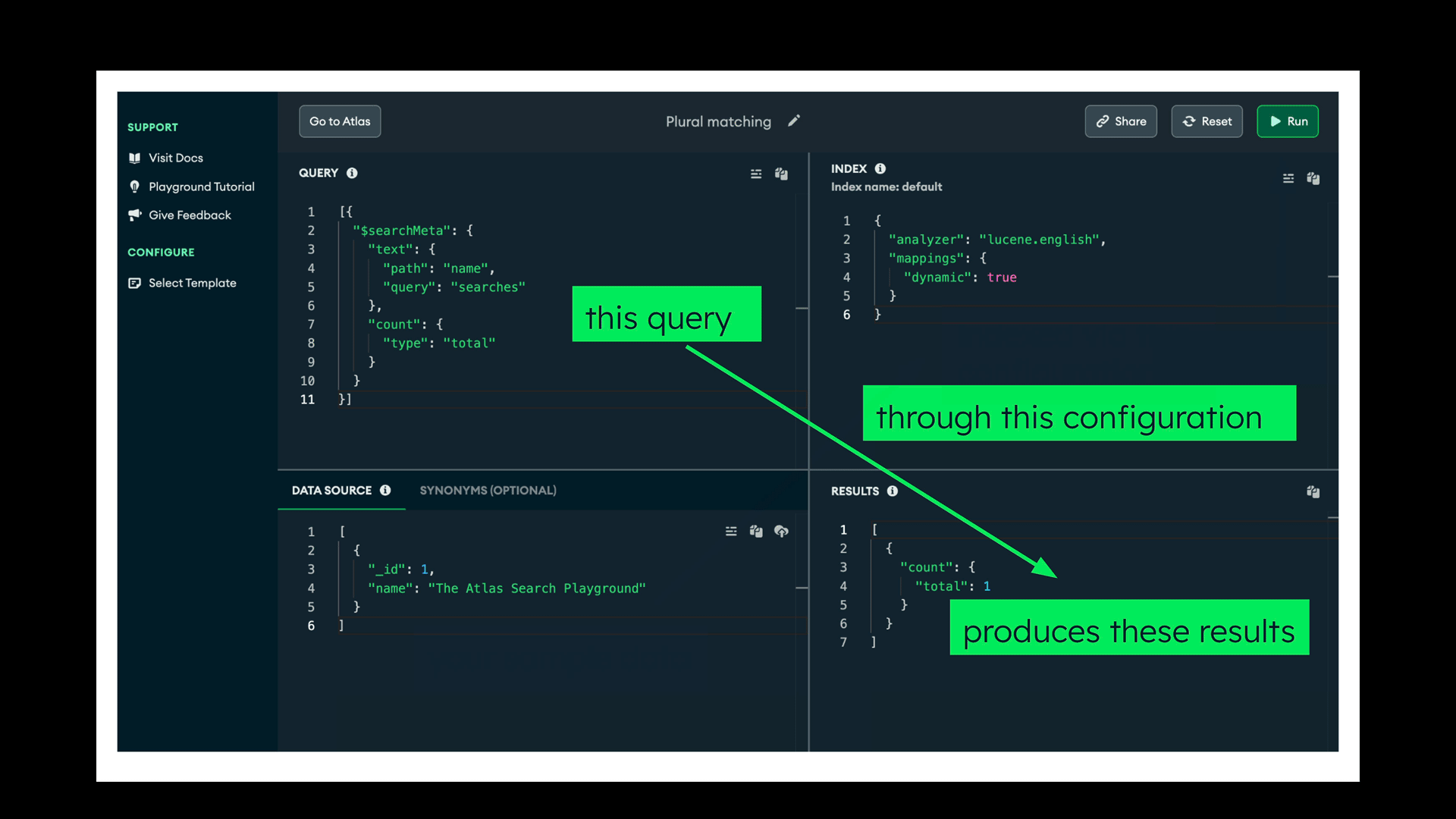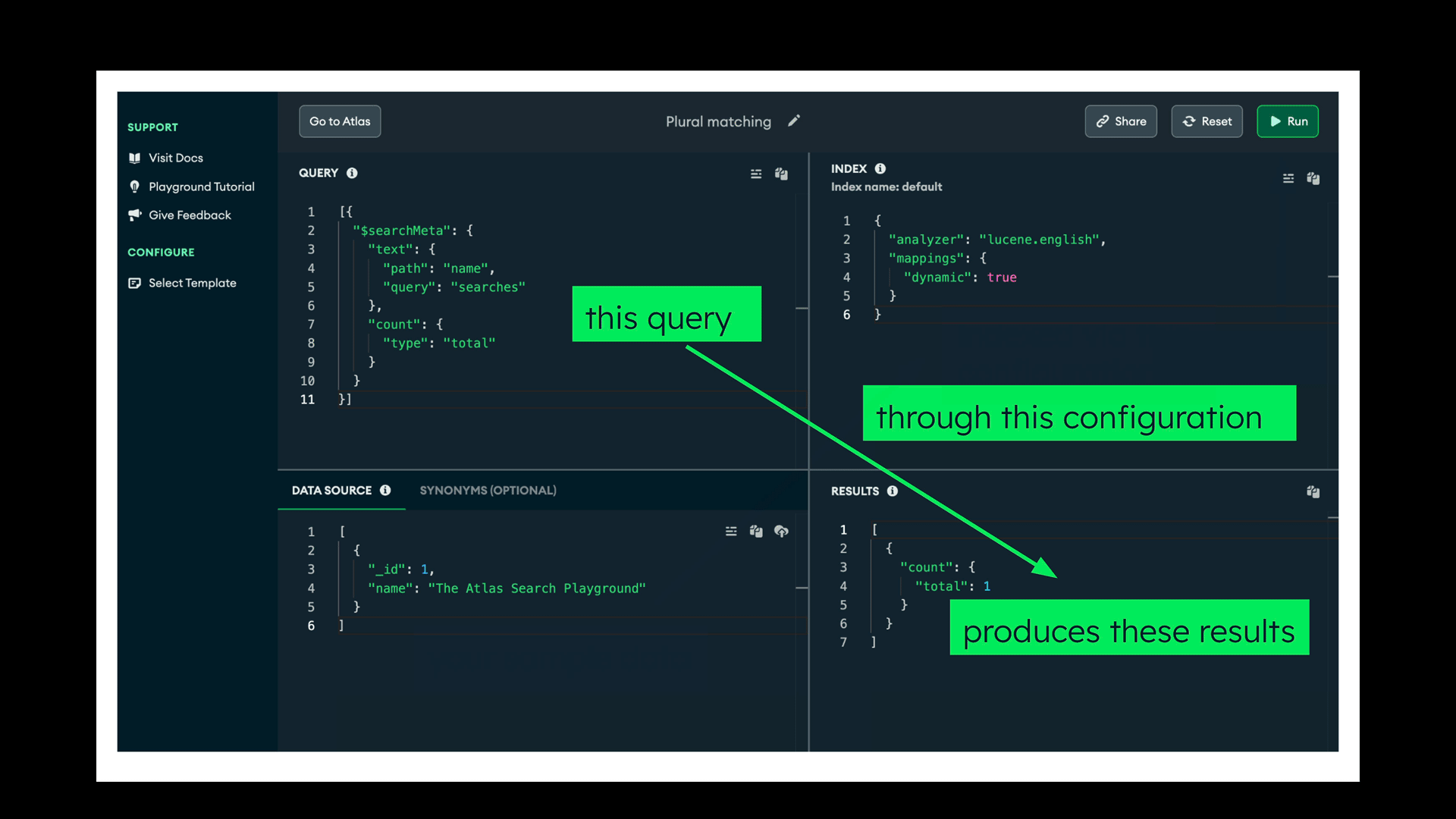
After running this playground, the results aren’t what we would expect.

A document with "name": "The Atlas Search Playground" is indexed through a basic dynamic index configuration. The search for searches in the name field...
"text": {
"path": "name",
"query": "searches"
}
...fails to match the indexed document. Why is that? The default (lucene.standard) analyzer tokenizes at basic word boundaries and lowercases the terms indexed or queried — and that’s it. Thus, search was one of the words indexed from that document's name field. The query of searches does not match any indexed term exactly.
Here’s a nice trick when testing queries out: Use $searchMeta to get the total count, giving a quick visual check of matching expectation — yes (1) the sample document matched, or no (0), it did not match. I find this more convincing than looking at [] empty results, especially if there’s more than a pane’s worth of matching results and you’re not sure how many there are.
Let’s play around and do better with this query that should match given rudimentary English semantics and practically identical terms, lexically. Let’s change our configuration to use the lucene.english analyzer, which stems the suffix off of words using a few English-centric rules such as removing trailing s and es suffixes as they, usually, indicate plurals. Among a few other heuristics, it will also make searching for “country” and “countries” match as one would generally expect.
Analysis and query construction are the crux of text matching, and there are many tricks to get queries to match fields in looser and more interesting ways, from handling text in a multitude of languages to partial substring pattern matching to even phonetic matching.
And here’s our adjusted playground, showing that the test document now matches the same initially failing query, thanks to an adjustment to the text analyzer used.
https://search-playground.mongodb.com/snapshots/66473aa64e0a3f240a5de9dd

Facets
The sandbox is a great place to learn about and experiment with facets. Facets, in the $search sense, provide additional search results context consisting of counts per bucket, where a bucket is a string value or a numeric or date range. This is similar to $group, though much more performant over large $search result sets.
https://search-playground.mongodb.com/snapshots/66473b064e0a3f240a5de9df
We index documents representing a couple of fruits and a vegetable through a configuration specifying the document type field to be a stringFacet:
[
{
"_id": 1,
"name": "Apple",
"type": "fruit"
},
{
"_id": 2,
"name": "Asparagus",
"type": "vegetable"
},
{
"_id": 3,
"name": "Banana",
"type": "fruit"
}
]
Now, using $searchMeta without an operator (which matches all documents), we facet across the entire three-document collection on the type field and get the counts per type bucket:
[
{
"count": {
"lowerBound": 3
},
"facet": {
"type_facet": {
"buckets": [
{
"_id": "fruit",
"count": 2
},
{
"_id": "vegetable",
"count": 1
}
]
}
}
}
]
A search operator could be provided to $searchMeta, in which case that would constrain the result set and the facet values would adjust to be accurate across the constrained result set.
Relevancy
Our final example demonstrates an as-you-type suggest scenario to experiment with nuanced matching and relevancy tuning.
https://search-playground.mongodb.com/snapshots/66473b744e0a3f240a5de9e1
The data is a sample of 500 documents from the Relevant As-You-Type Suggestions Search Solution example. After running this playground, the results are the 10 best, most relevant matches for the query “matr” (as if someone were in the process of typing, say, “matrix”).
Note in this playground there are a couple of sections commented out in the query. Being able to comment out blocks of the query helps in experimenting with various options. In this case, score details and highlighting responses are omitted but easily incorporated by uncommenting those blocks.

Let’s get serious
Playtime is over. It’s time to get real with this search business. Go to MongoDB Atlas to log in or create a new account if you don’t already have one, and take what you’ve learned and honed in the playground over to a persistent, production-ready Atlas environment.
Come back to the playground as needed to work through search challenges, experiment with various features, or create an example to share with others.
Happy playing!