Colocando o RAG em produção com o chatbot de IA da documentação do MongoDB





Classifique este artigo


At MongoDB, we have a tagline: "Love your developers." One way that we show love to our developers is by providing them with excellent technical documentation for our products. Given the rise of generative AI technologies like ChatGPT, we wanted to use generative AI to help developers learn about our products using natural language. This led us to create an AI chatbot that lets users talk directly to our documentation. With the documentation AI chatbot, users can ask questions and then get answers and related content more efficiently and intuitively than previously possible.
This post provides a technical overview of how we built the documentation AI chatbot. It covers:
- The chatbot’s retrieval augmented generation (RAG) architecture.
- The challenges in building a RAG chatbot for the MongoDB documentation.
- How we built the chatbot to overcome these challenges.
- How we used MongoDB Atlas in the application.
- Next steps for building your own production RAG application using MongoDB Atlas.
We built our chatbot using the retrieval augmented generation (RAG) architecture. RAG augments the knowledge of large language models (LLMs) by retrieving relevant information for users' queries and using that information in the LLM-generated response. We used MongoDB's public documentation as the information source for our chatbot's generated answers.
To retrieve relevant information based on user queries, we used Atlas Vector Search do MongoDB Atlas. We used the Azure OpenAI ChatGPT API to generate answers in response to user questions based on the information returned from Atlas Vector Search. We used the Azure OpenAI embeddings API to convert MongoDB documentation and user queries into vector embeddings, which help us find the most relevant content for queries using Atlas Vector Search.
Here's a high-level diagram of the chatbot's RAG architecture:

Over the past few months, a lot of tools and reference architectures have come out for building RAG applications. We decided it would make the most sense to start simple, and then iterate with our design once we had a functional minimal viable product (MVP).
Our first iteration was what Jerry Liu, creator of RAG framework LlamaIndex, calls "naive RAG". This is the simplest form of RAG. Our naive RAG implementation had the following flow:
- Data ingestion: Ingesting source data into MongoDB Atlas, breaking documents into smaller chunks, and storing each chunk with its vector embedding. Index the vector embeddings using MongoDB Atlas Vector Search.
- Chat: Generating an answer by creating an embedding for the user's question, finding matching chunks with MongoDB Atlas Vector Search, and then summarizing an answer using these chunks.
We got a reasonably functional naive RAG prototype up and running with a small team in under two months. To assess the quality of generated responses and links, we had MongoDB employees volunteer to test out the chatbot in a red teaming exercise.
The red teaming exercise revealed that the naive RAG chatbot provided satisfactory answers roughly 60% of the time.
For the 40% of answers that were unsatisfactory, we noticed a few common themes:
- The chatbot was not aware of previous messages in the conversation.
For example, the conversation might go like:
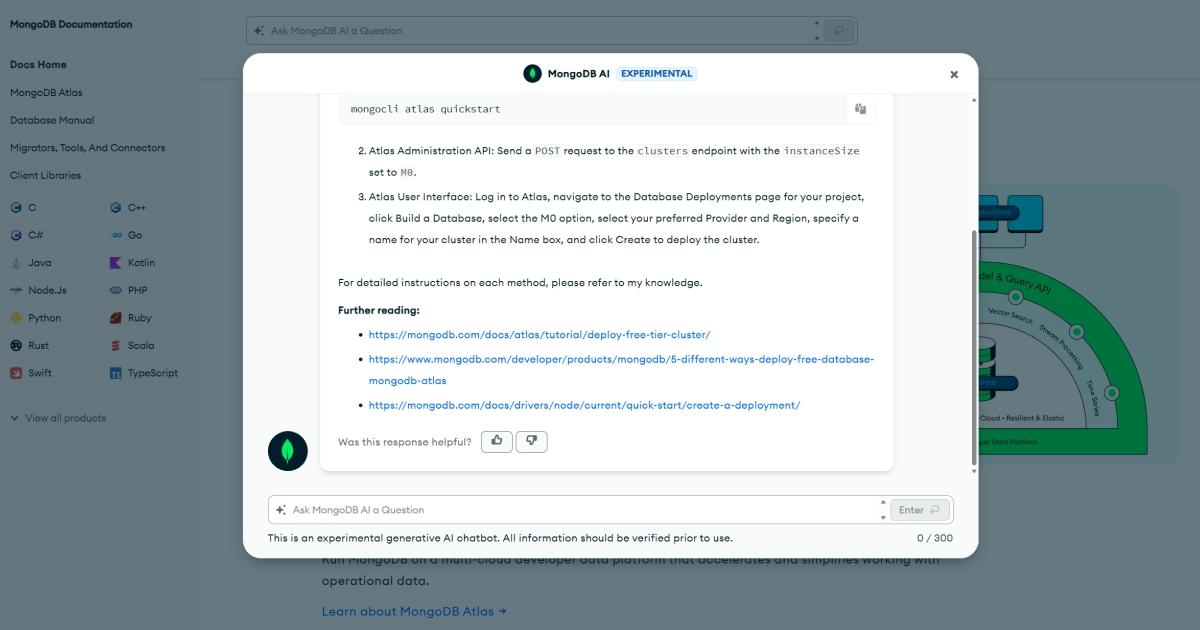
1 User: how to create a cluster atlas 2 Chatbot: To create a MongoDB Atlas cluster using the CLI, you can use the `mongocli atlas quickstart` command... 3 User: how to with UI 4 Chatbot: I'm sorry, I don't know what you mean...
- The chatbot sometimes gave niche or overly specific solutions when a more general answer would have been useful. MongoDB has many products with overlapping functionality (database drivers in multiple languages, MongoDB on Atlas and self-hosted, etc.) and without a clear priority, it could seemingly choose one at random.
For example, the conversation might go like:
1 User: how to connect to mongodb 2 Chatbot: To connect to MongoDB you can use the Java Driver...
- The chatbot’s further reading links were not consistently relevant.
For example the conversation might go like:
1 User: write data to mongodb node.js 2 Chatbot: /* Reasonable generated answer */ 3 4 Further reading: 5 - https://www.mongodb.com/pt-br/docs/drivers/node/current/usage-examples/insertOne/ (👍) 6 - https://www.mongodb.com/pt-br/developer/languages/javascript/node-connect-mongodb/ (👍) 7 - https://www.mongodb.com/pt-br/developer/products/realm/realm-meetup-javascript-react-native/ (🤷)
To get the chatbot to a place where we felt comfortable putting it out into the world, we needed to address these limitations.
This section covers how we built the documentation AI chatbot to address the previously mentioned limitations of naive RAG to build a not-so-naive chatbot that better responds to user questions.
Using the approach described in this section, we got the chatbot to over 80% satisfactory responses in a subsequent red teaming exercise.
We set up a CLI for data ingestion, pulling content from MongoDB's documentation and the Developer Center. A nightly cron job ensures the chatbot's information remains current.
Our ingestion pipeline involves two primary stages:
We created a
pages CLI command that pulls raw content from data sources into Markdown for the chatbot to use. This stage handles varied content formats, including abstract syntax trees, HTML, and Markdown. We stored this raw data in a pages collection in MongoDB.Exemplo
pages command:1 ingest pages --source docs-atlas
An
embed CLI command takes the data from the pages collection and transforms it into a form that the chatbot can use in addition to generating vector embeddings for the content. We stored the transformed content in the embedded_content collection, indexed using MongoDB Atlas Vector Search.Exemplo
embed command:1 ingest embed --source docs-atlas \ 2 --since 2023-11-07 # only update documentation changed since this time
To transform our
pages documents into embedded_content documents, we used the following strategy:
Break each page into one or more chunks using the LangChain RecursiveCharacterTextSplitter. We used the RecursiveCharacterTextSplitter to split the text into logical chunks, such as by keeping page sections (as denoted by headers) and code examples together.
Allow max chunk size of 650 tokens. This led to an average chunk size of 450 tokens, which aligns with emerging best practices.
Remove all chunks that are less than 15 tokens in length. These would sometimes show up in vector search results because they'd closely match the user query even though they provided little value for informing the answer generated by the ChatGPT API.
Add metadata to the beginning of each chunk before creating the embedding. This gives the chunk greater semantic meaning to create the embedding with. See the following section for more information about how adding metadata greatly improved the quality of our vector search results.The most important improvement that we made to the chunking and embedding was to prepend chunks with metadata. For example, say you have this chunk of text about using MongoDB Atlas Vector Search:
1 ### Procedure 2 3 <Tabs> 4 5 <Tab name="MongoDB Atlas"> 6 7 #### Go to the Search Tester. 8 9 - Click the cluster name to view the cluster details. 10 11 - Click the Search tab. 12 13 - Click the Query button to the right of the index to query. 14 15 #### View and edit the query syntax. 16 17 Click Edit $search Query to view a default query syntax sample in JSON (Javascript Object Notation) format.
This chunk itself has relevant information about performing a semantic search on Atlas data, but it lacks context data that makes it more likely to be found in the search results.
Before creating the vector embedding for the content, we add metadata to the top of the chunk to change it to:
1 --- 2 tags: 3 - atlas 4 - docs 5 productName: MongoDB Atlas 6 version: null 7 pageTitle: How to Perform Semantic Search Against Data in Your Atlas Cluster 8 hasCodeBlock: false 9 --- 10 11 ### Procedure 12 13 <Tabs> 14 15 <Tab name="MongoDB Atlas"> 16 17 #### Go to the Search Tester. 18 19 - Click the cluster name to view the cluster details. 20 21 - Click the Search tab. 22 23 - Click the Query button to the right of the index to query. 24 25 #### View and edit the query syntax. 26 27 Click Edit $search Query to view a default query syntax sample in JSON (Javascript Object Notation) format.
Adding this metadata to the chunk greatly improved the quality of our search results, especially when combined with adding metadata to the user's query on the server before using it in vector search, as discussed in the “Chat Server” section.
Here’s an example document from the
embedded_content collection. The embedding field is indexed with MongoDB Atlas Vector Search.1 { 2 _id: new ObjectId("65448eb04ef194092777bcf6") 3 chunkIndex: 4, 4 sourceName: "docs-atlas", 5 url: "https://mongodb.com/pt-br/docs/atlas/atlas-vector-search/vector-search-tutorial/", 6 text: '---\ntags:\n - atlas\n - docs\nproductName: MongoDB Atlas\nversion: null\npageTitle: How to Perform Semantic Search Against Data in Your Atlas Cluster\nhasCodeBlock: false\n---\n\n### Procedure\n\n<Tabs>\n\n<Tab name="MongoDB Atlas">\n\n#### Go to the Search Tester.\n\n- Click the cluster name to view the cluster details.\n\n- Click the Search tab.\n\n- Click the Query button to the right of the index to query.\n\n#### View and edit the query syntax.\n\nClick Edit $search Query to view a default query syntax sample in JSON (Javascript Object Notation) format.', 7 tokenCount: 151, 8 metadata: { 9 tags: ["atlas", "docs"], 10 productName: "MongoDB Atlas", 11 version: null, 12 pageTitle: "How to Perform Semantic Search Against Data in Your Atlas Cluster", 13 hasCodeBlock: false, 14 }, 15 embedding: [0.002525234, 0.038020607, 0.021626275 /* ... */], 16 updated: new Date() 17 };

We built an Express.js server to coordinate RAG between the user, MongoDB documentation, and ChatGPT API. We used MongoDB Atlas Vector Search to perform a vector search on the ingested content in the
embedded_content collection. We persist conversation information, including user and chatbot messages, to a conversations collection in the same MongoDB database.The Express.js server is a fairly straightforward RESTful API with three routes:
POST /conversations: Create a new conversation.POST /conversations/:conversationId/messages: Add a user message to a conversation and get back a RAG response to the user message. This route has the optional parameterstreamto stream back a response or send it as a JSON object.POST /conversations/:conversationId/messages/:messageId/rating: Rate a message.
Most of the complexity of the server was in the
POST /conversations/:conversationId/messages route, as this handles the whole RAG flow.We were able to make dramatic improvements over our initial naive RAG implementation by adding what we call a query preprocessor.
A query preprocessor mutates the original user query to something that is more conversationally relevant and gets better vector search results.
For example, say the user inputs the following query to the chatbot:
1 $filter
On its own, this query has little inherent semantic meaning and doesn't present a clear question for the ChatGPT API to answer.
However, using a query preprocessor, we transform this query into:
1 --- 2 programmingLanguages: 3 - shell 4 mongoDbProducts: 5 - MongoDB Server 6 - Aggregation Framework 7 --- 8 What is the syntax for filtering data in MongoDB?
The application server then sends this transformed query in MongoDB Atlas Vector Search. It yields much better search results than the original query. The search query has more semantic meaning itself and also aligns with the metadata that we prepend during content ingestion to create a higher degree of semantic similarity for vector search.
Adding the
programmingLanguage and mongoDbProducts information to the query focuses the vector search to create a response grounded in a specific subset of the total surface area of the MongoDB product suite. For example, here we would not want the chatbot to return results for using the PHP driver to perform $filter aggregations, but vector search would be more likely to return that if we didn't specify that we're looking for examples that use the shell.Also, telling the ChatGPT API to answer the question "What is the syntax for filtering data in MongoDB?" provides a clearer answer than telling it to answer the original "$filter".
To create a preprocessor that transforms the query like this, we used the library TypeChat. TypeChat takes a string input and transforms it into a JSON object using the ChatGPT API. TypeChat uses TypeScript types to describe the shape of the output data.
The TypeScript type that we use in our application is as follows:
1 /** 2 You are an AI-powered API that helps developers find answers to their MongoDB 3 questions. You are a MongoDB expert. Process the user query in the context of 4 the conversation into the following data type. 5 */ 6 export interface MongoDbUserQueryPreprocessorResponse { 7 /** 8 One or more programming languages present in the content ordered by 9 relevancy. If no programming language is present and the user is asking for 10 a code example, include "shell". 11 @example ["shell", "javascript", "typescript", "python", "java", "csharp", 12 "cpp", "ruby", "kotlin", "c", "dart", "php", "rust", "scala", "swift" 13 ...other popular programming languages ] 14 */ 15 programmingLanguages: string[]; 16 17 /** 18 One or more MongoDB products present in the content. Which MongoDB products 19 is the user interested in? Order by relevancy. Include "Driver" if the user 20 is asking about a programming language with a MongoDB driver. 21 @example ["MongoDB Atlas", "Atlas Charts", "Atlas Search", "Aggregation 22 Framework", "MongoDB Server", "Compass", "MongoDB Connector for BI", "Realm 23 SDK", "Driver", "Atlas App Services", ...other MongoDB products] 24 */ 25 mongoDbProducts: string[]; 26 27 /** 28 Using your knowledge of MongoDB and the conversational context, rephrase the 29 latest user query to make it more meaningful. Rephrase the query into a 30 question if it's not already one. The query generated here is passed to 31 semantic search. If you do not know how to rephrase the query, leave this 32 field undefined. 33 */ 34 query?: string; 35 36 /** 37 Set to true if and only if the query is hostile, offensive, or disparages 38 MongoDB or its products. 39 */ 40 rejectQuery: boolean; 41 }
In our app, TypeChat uses the
MongoDbUserQueryPreprocessorResponse schema and description to create an object structured on this schema.Then, using a simple JavaScript function, we transform the
MongoDbUserQueryPreprocessorResponse object into a query to send to embed and then send to MongoDB Atlas Vector Search.We also have the
rejectQuery field to flag if a query is inappropriate. When the rejectQuery: true, the server returns a static response to the user, asking them to try a different query.
Our front end is a React component built with the LeafyGreen Design System. The component regulates the interaction with the chat server's RESTful API.
Currently, the component is only on the MongoDB docs homepage, but we built it in a way that it could be extended to be used on other MongoDB properties.
Here you can see what the chatbot looks like in action:

Building the chatbot on MongoDB Atlas was a great accelerant for our developer productivity and helped us simplify our infrastructure.
Setting up MongoDB Atlas Vector Search on our cluster took just a few clicks in the UI and adding the following Atlas Vector Search index to the
embedding field of the embedded_content collection:1 { 2 "type": "vectorSearch, 3 "fields": [{ 4 "path": "embedding", 5 "dimensions": 1536, 6 "similarity": "cosine", 7 "type": "vector" 8 }] 9 }
To run queries using the MongoDB Atlas Vector Search index, it's a simple aggregation operation with the
$vectorSearch operator using the Node.js driver:1 export async function getVectorSearchResults( 2 collection: Collection, 3 vectorEmbedding: number[], 4 filterQuery: Filter<any> 5 ) { 6 return collection 7 .aggregate<WithScore<EmbeddedContents>>([ 8 { 9 $vectorSearch: { 10 index: "default", 11 vector: vectorEmbedding, 12 path: "embedding", 13 filter: filterQuery, 14 limit: 3, 15 numCandidates: 30 16 }, 17 }, 18 { 19 $addFields: { 20 score: { 21 $meta: "vectorSearchScore", 22 }, 23 }, 24 }, 25 { $match: { score: { $gte: 0.8 } } }, 26 ]) 27 .toArray(); 28 }
Using MongoDB to store the
conversations data simplified the development experience, as we did not have to think about using a data store for the embeddings that is separate from the rest of the application data.Using MongoDB Atlas for vector search and as our application data store streamlined our application development process so that we were able to focus on the core RAG application logic, and not have to think very much about managing additional infrastructure or learning new domain-specific query languages.
The MongoDB documentation AI chatbot has now been live for over a month and works pretty well (try it out!). It's still under active development, and we're going to roll it to other locations in the MongoDB product suite over the coming months.
Here are a couple of our key learnings from taking the chatbot to production:
- Naive RAG is not enough. However, starting with a naive RAG prototype is a great way for you to figure out how you need to extend RAG to meet the needs of your use case.
- Red teaming is incredibly useful for identifying issues. Red team early in the RAG application development process, and red team often.
- Add metadata to the content before creating embeddings to improve search quality.
- Preprocess user queries with an LLM (like the ChatGPT API and TypeChat) before sending them to vector search and having the LLM respond to the user. The preprocessor should:
- Make the query more conversationally and semantically relevant.
- Include metadata to use in vector search.
- Catch any scenarios, like inappropriate queries, that you want to handle outside the normal RAG flow.
- MongoDB Atlas is a great database for building production RAG apps.
Want to build your own RAG application? We've made our source code publicly available as a reference architecture. Check it out on Github.
We're also working on releasing an open-source framework to simplify the creation of RAG applications using MongoDB. Stay tuned for more updates on this RAG framework.
Principais comentários nos fóruns

Classifique este artigo
Hi,
I’m curious about how you handle updating embeddings. Do you replace them entirely when content changes? If so, how do you manage the cost impact of doing so?
Additionally, what criteria do you use to determine when an update is necessary? For example, would a minor typo warrant an update, or are there more significant changes that trigger this process?
Thanks for sharing your insights with us!
Does this look good to you?